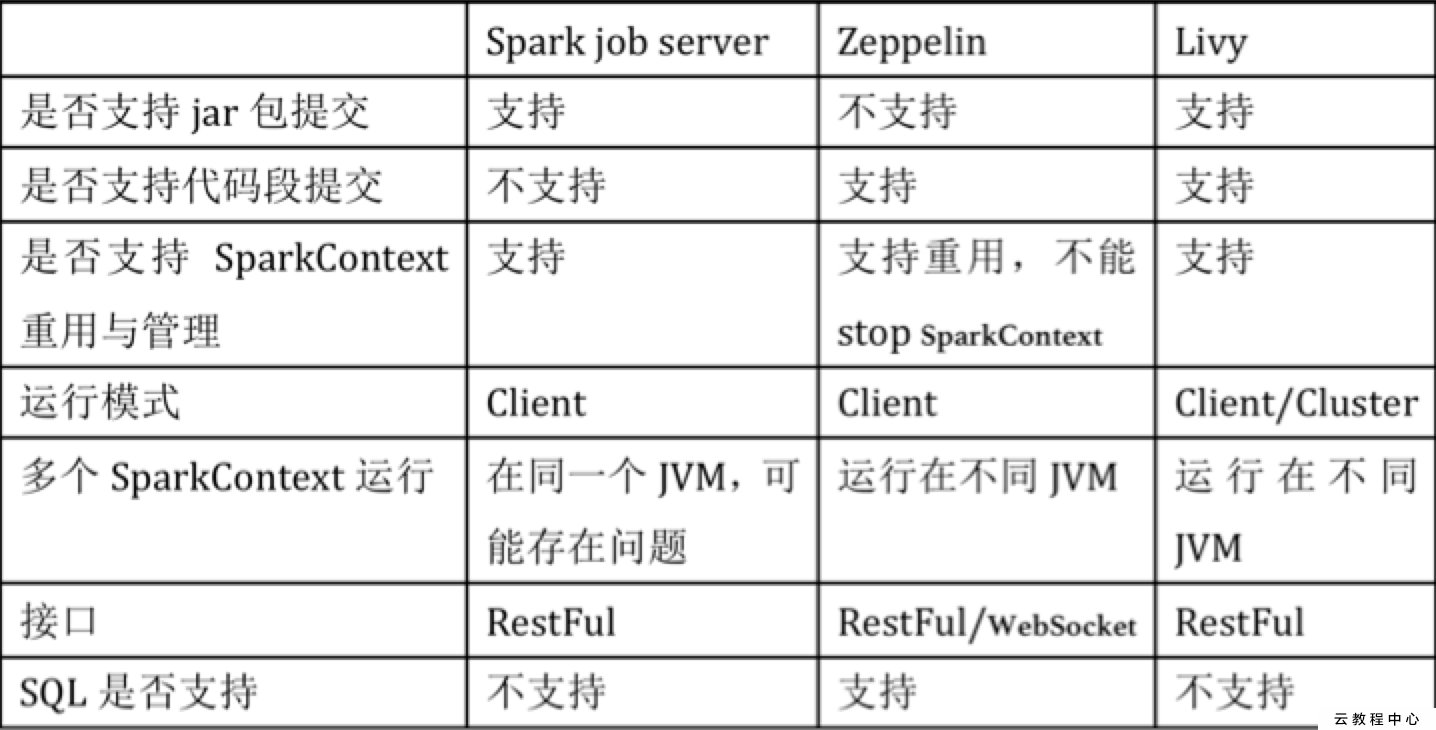
Livy的安装使用
Livy介绍(apache 孵化项目)
官网:https://livy.incubator.apache.org/
Livy是一个提供rest接口和spark集群交互的服务。它可以提交spark job或者spark一段代码,同步或者异步的返回结果;也提供sparkcontext的管理,通过restfull接口或RPC客户端库。Livy也简化了与spark与应用服务的交互,这允许通过web/mobile与spark的使用交互。其他特点还包含:
- 长时间运行的SparkContext,允许多个spark job和多个client使用。
- 在多个spark job和客户端之间共享RDD和Dataframe
- 多个sparkcontext可以简单的管理,并运行在集群中而不是Livy Server,以此获取更好的容错性和并行度。
- 作业可以通过重新编译的jar、片段代码、或Java/Scala的客户端API提交。
Livy结合了spark job server和Zeppelin的优点,并解决了spark job server和Zeppelin的缺点。
- 支持jar和snippet code
- 支持SparkContext和Job的管理
- 支持不同SparkContext运行在不同进程,同一个进程只能运行一个SparkContext
- 支持Yarn cluster模式
- 提供restful接口,暴露SparkContext
Livy安装
下载
下载地址:https://livy.incubator.apache.org/download/
必要条件
1.首先要安装Spark1.6+
2.Scala版本2.10和2.11版本+
配置环境变量
vi .bash_profileexport SPARK_HOME=/wangqingguo/bigdata/spark-2.4.6-bin-hadoop2.6export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoopsource .bash_profile
livy.conf(进行一些配置,一般默认就好)
#默认使用hiveContextlivy.repl.enableHiveContext = true#开启用户代理livy.impersonation.enabled = true#设置session空闲过期时间livy.server.session.timeout = 1h#yarn/local本地模式或者yarn模式livy.server.session.factory = yarn
运行Livy(http://localhost:8998/)
bin/livy-server &
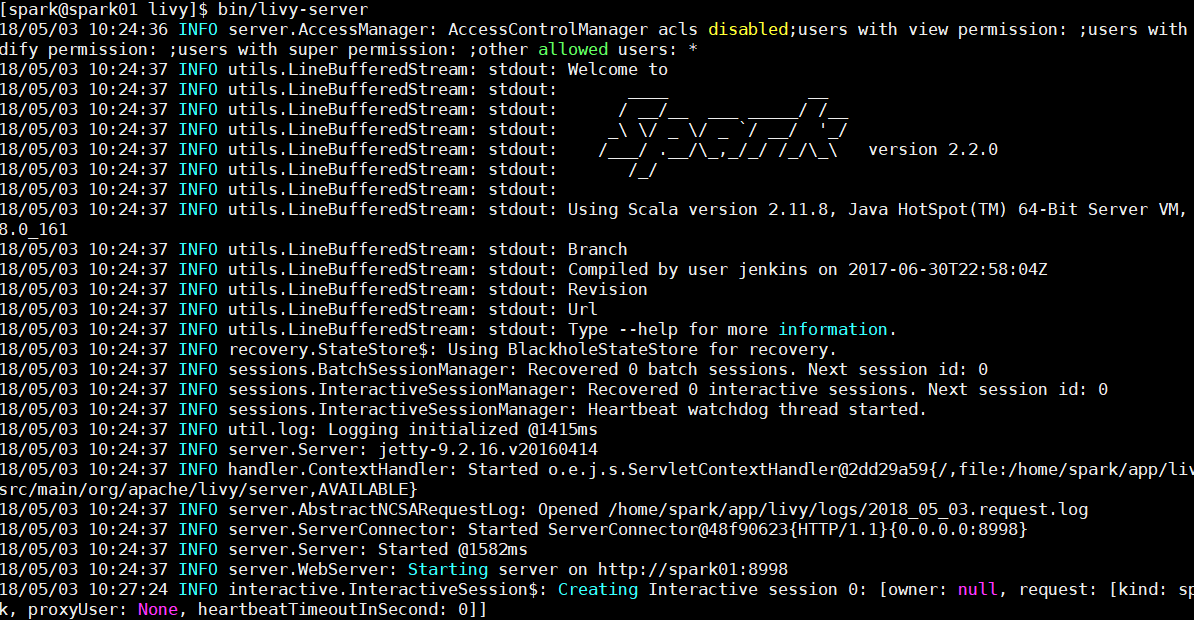
启动成功:

Livy使用
livy提供了不少的api,可以参考官方文档
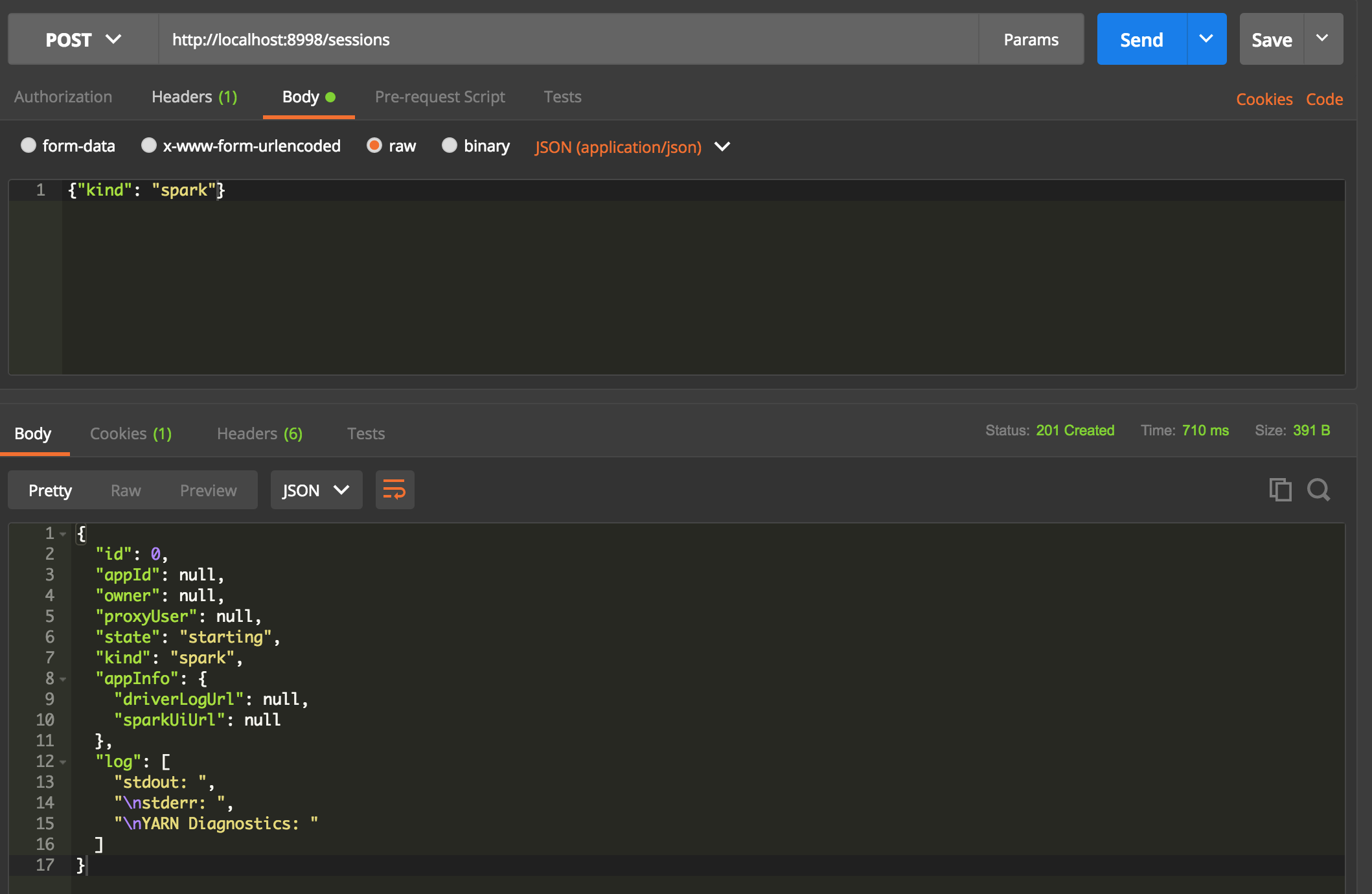
新建session
post http://localhost:8998/sessions
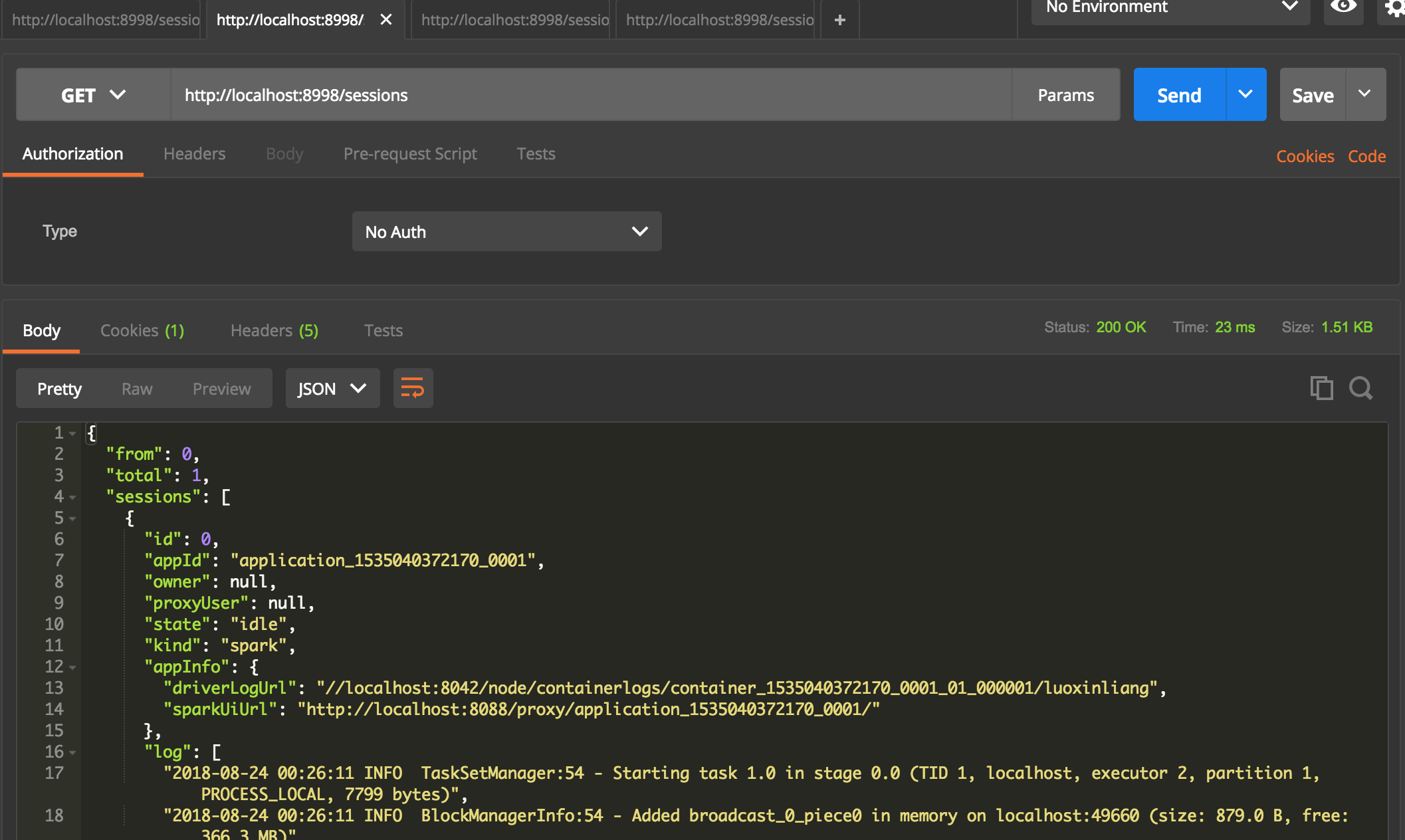
查看session状态
get http://localhost:8998/sessions
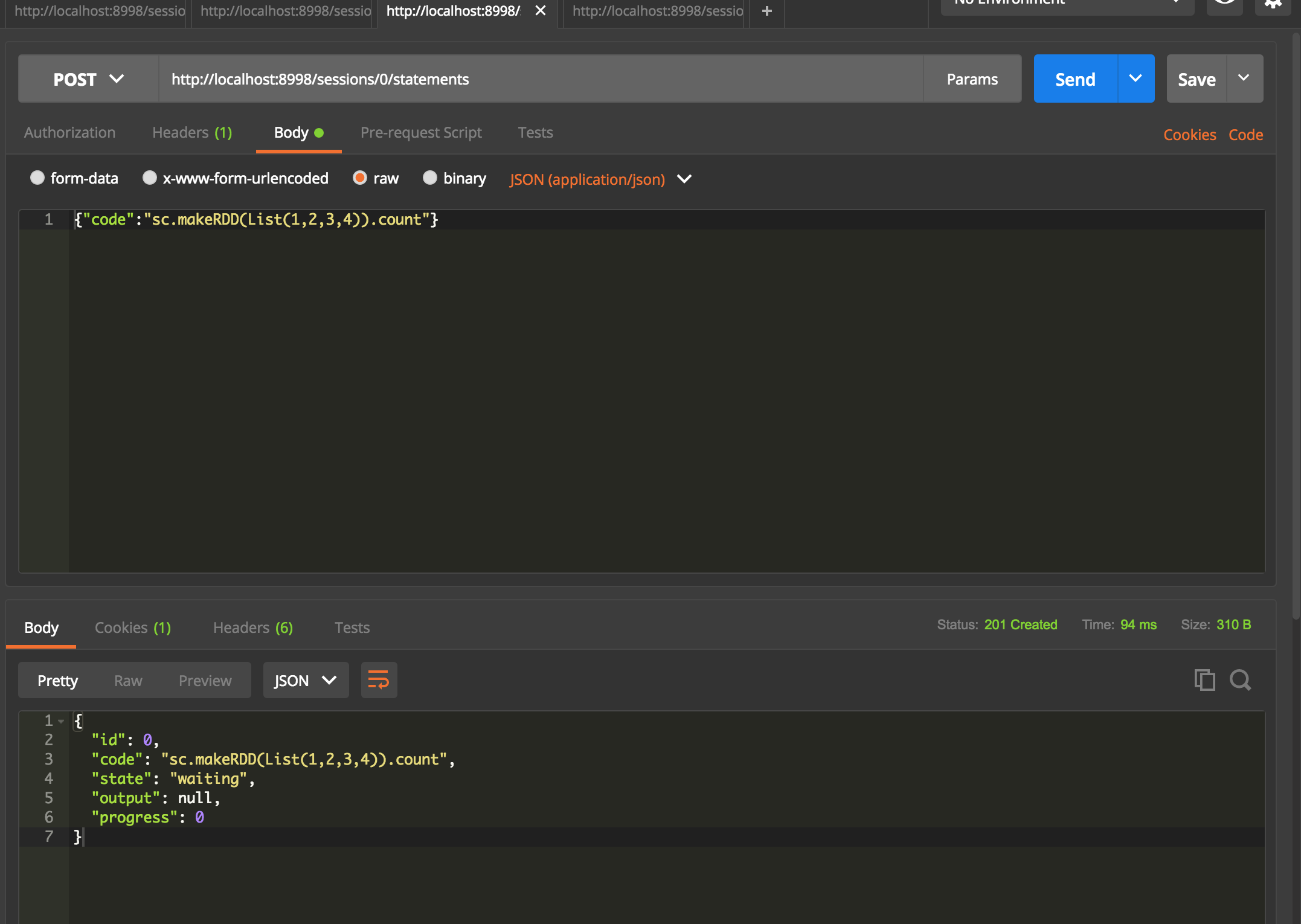
提交代码片断
post http://localhost:8998/sessions/0/statements
如果在同一个session,提交的代码片断是同享的,相当于你在同一个spark-shell里面进行操作
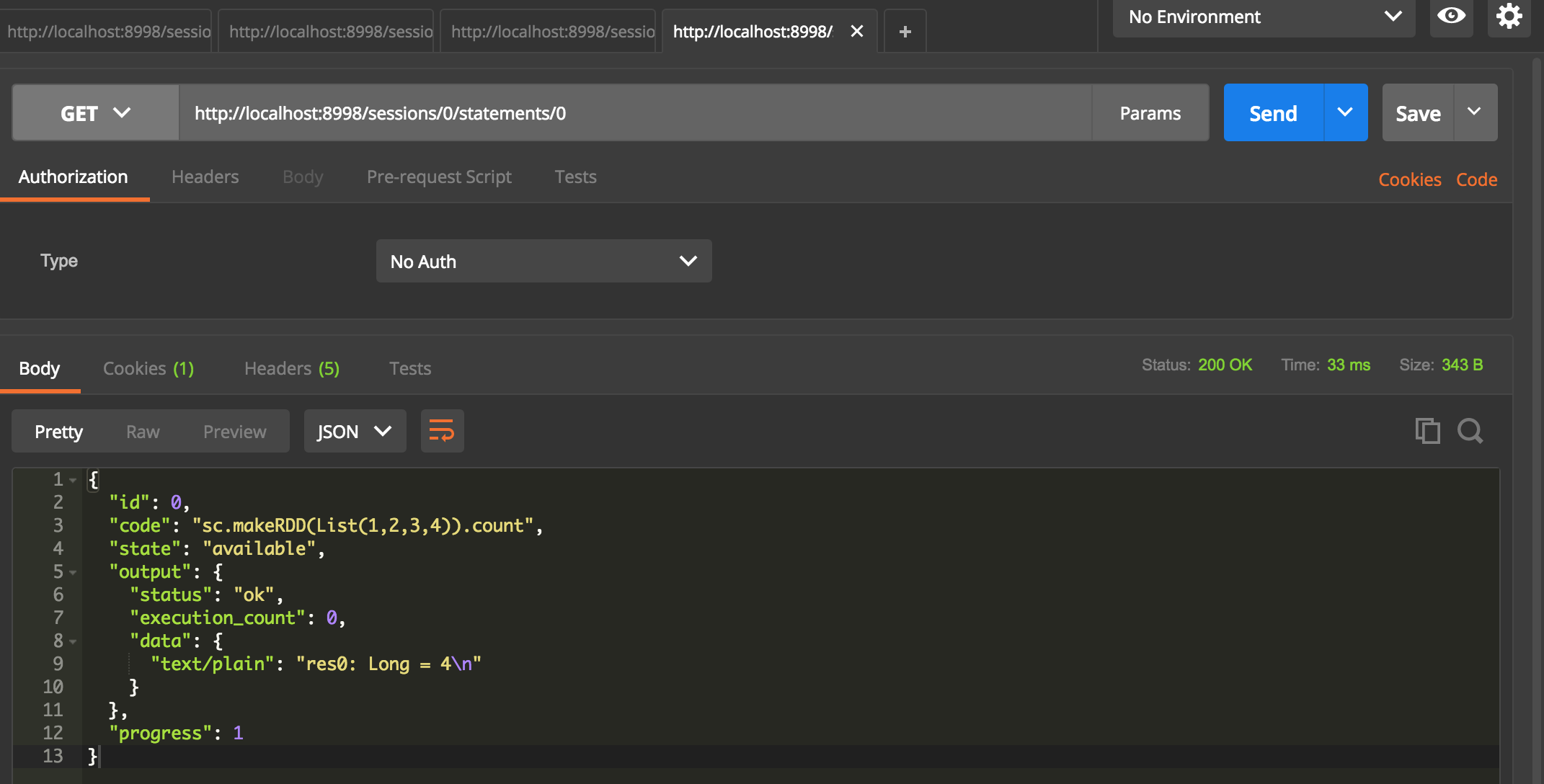
查看代码运行结果
get http://localhost:8998/sessions/0/statements/0
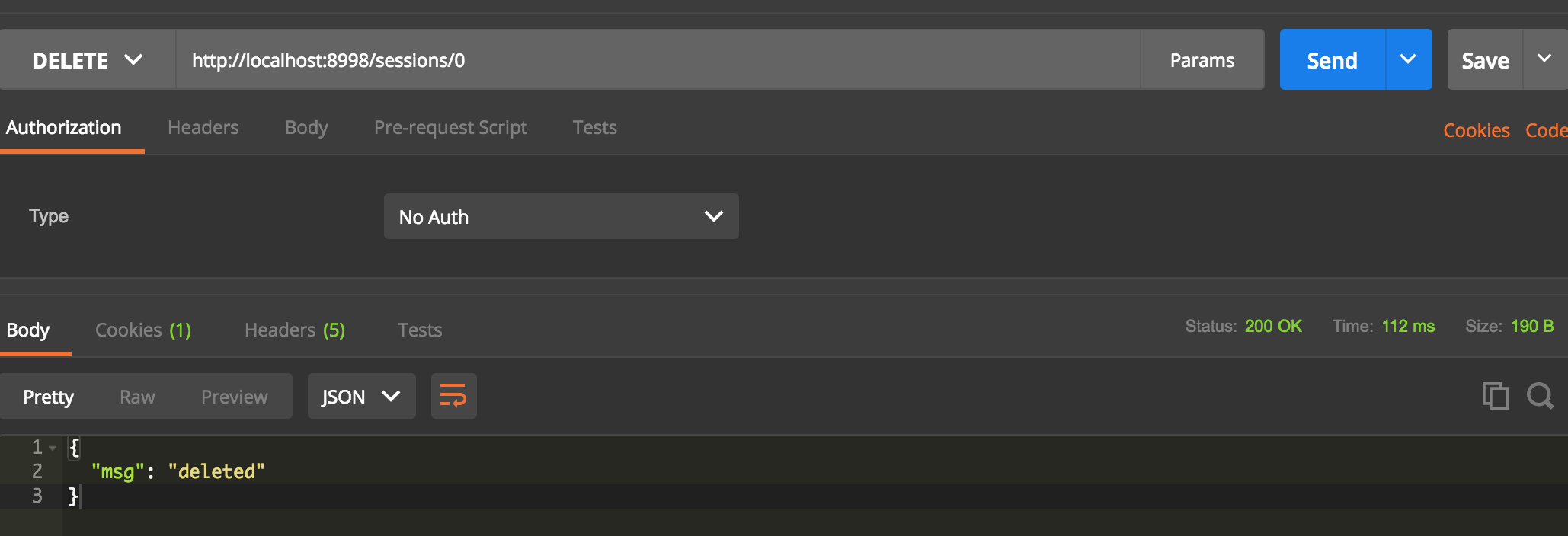
杀掉session
delete http://localhost:8998/sessions/0
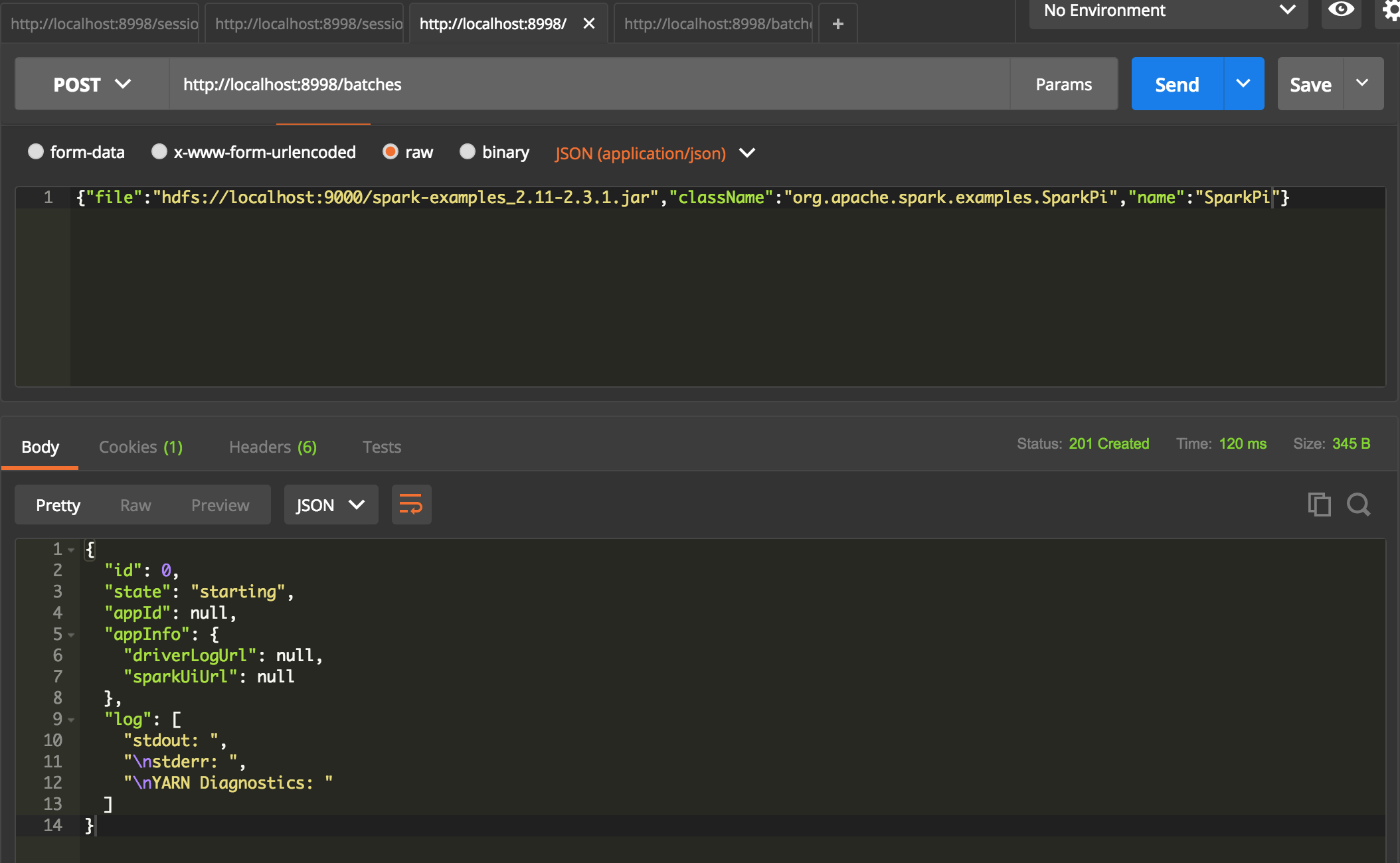
提交spark任务
post http://localhost:8998/batches
查看spark任务结果
get http://localhost:8998/batches
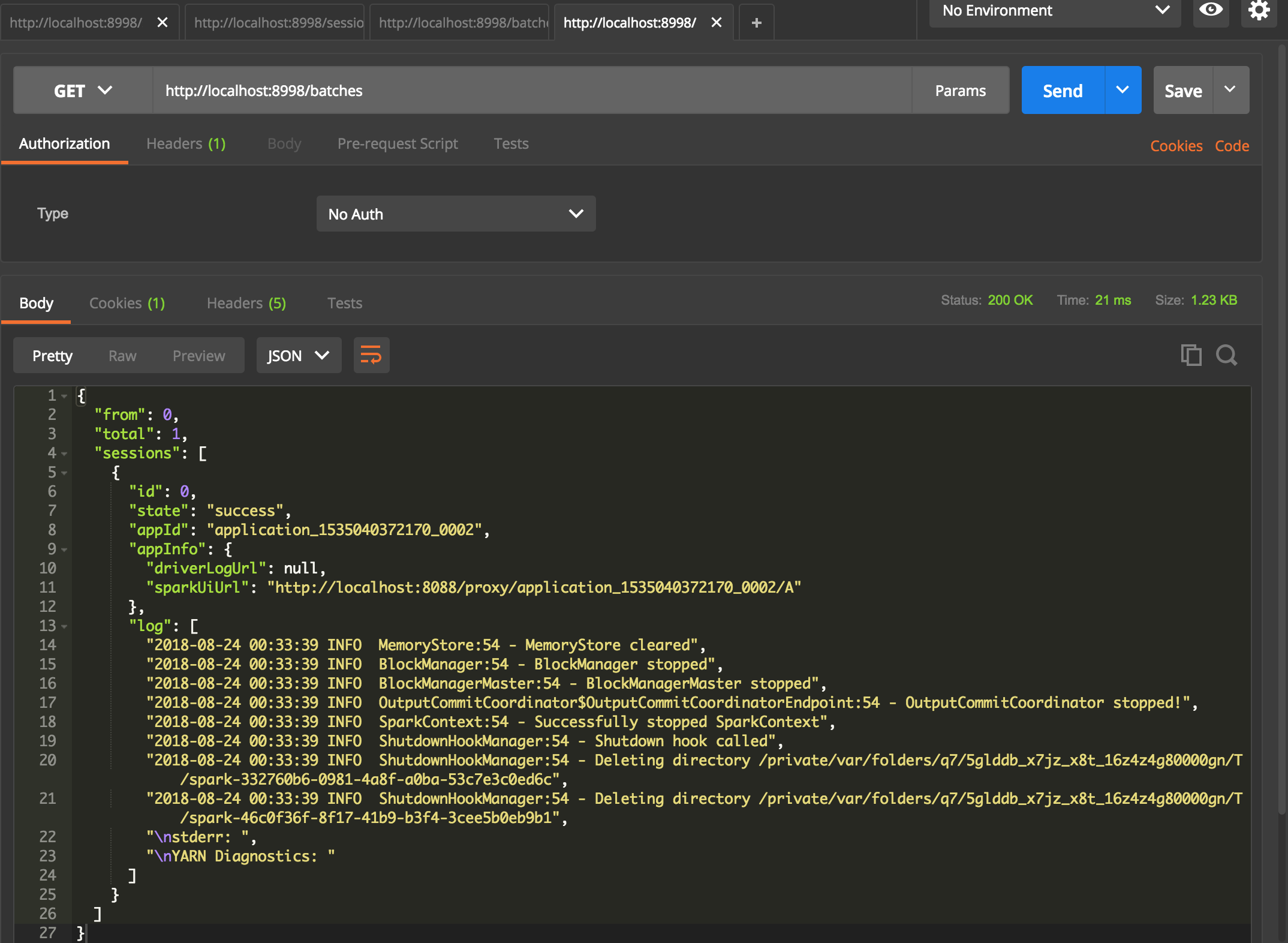
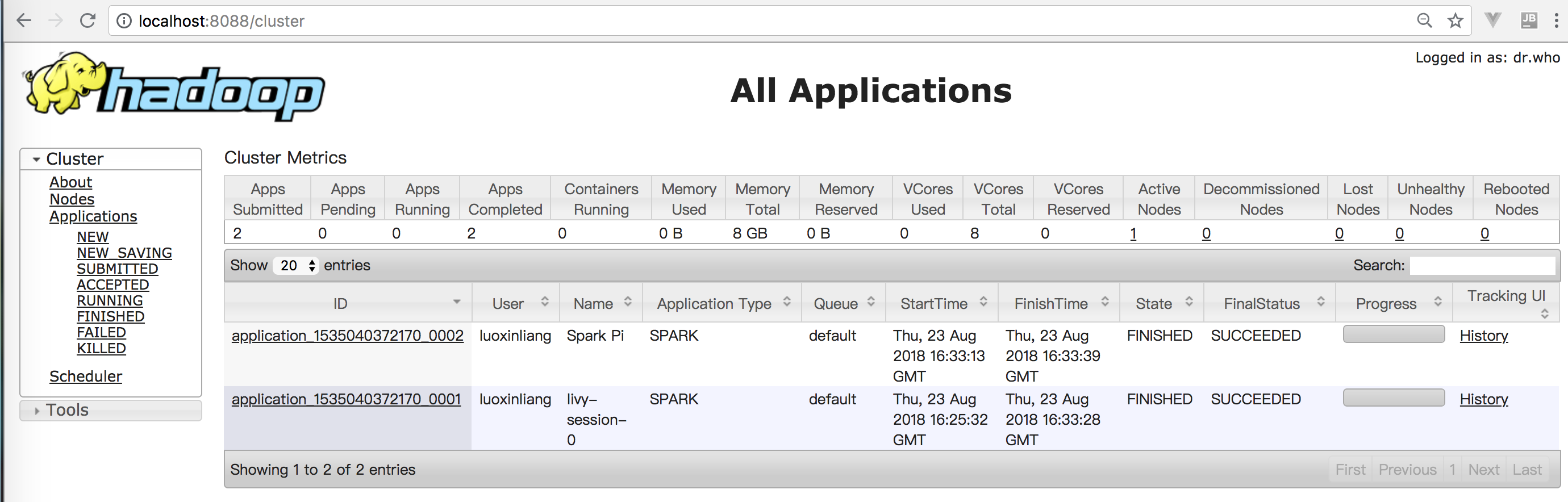
下面是刚才运行开始的session和提交的spark任务,在yarn任务列表中可以看到。






























还没有评论,来说两句吧...