EDA Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
概述
文章提出了一种文本分类任务中数据增强的方法:EDA,EDA中包括四种操作,SR、RI、 RS、RD。
实验显示,在五个通用的文本分类数据集上,使用EDA方法增强语料,模型都有一定性能上的提升。
尤其在语料不足的情况下,性能提升得越多。
EDA中的四种操作
分别是,同义词替换,随机插入,随机交换,随机删除。详细操作如下图

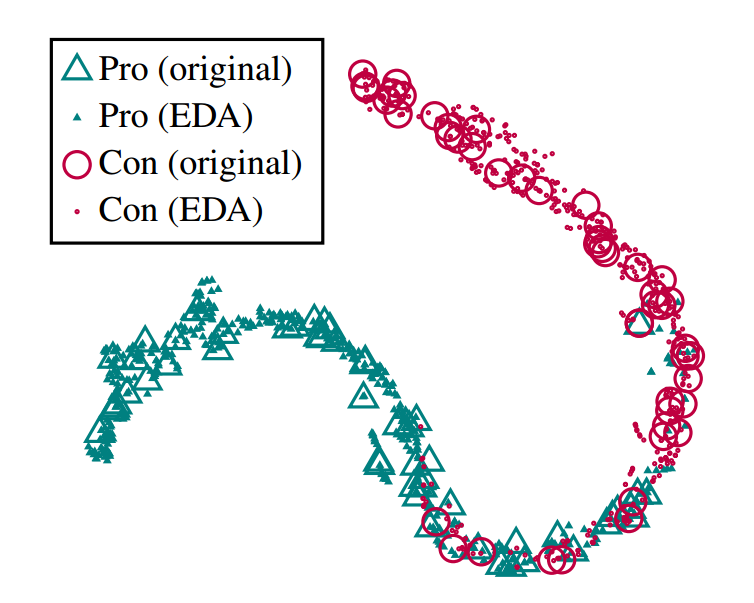
经过EDA方法操作后,原有句子的label还会是对的吗?
看论文的过程中,其实心中一直有一个疑问,经过EDA操作的句子,label还会是对的吗
作者在论文中回答了这一点,作者做了一个实验,用原有的训练集训练模型(未经过数据增强),
之后在测试集中使用EDA方法,拓展测试集,将原有的测试集和拓展出的语料,喂进模型中,
发现原有测试集和拓展出的语料,最后线性层的输出,在高维空间中,距离很小。如下图所示。
作者的建议
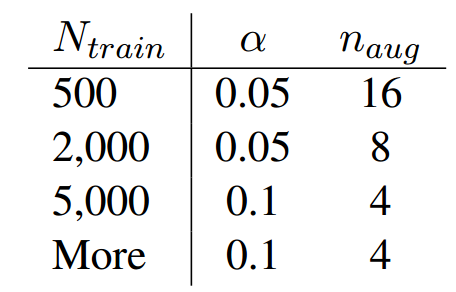
作者给出了在实际使用EDA方法的建议,表格的左边是数据的规模 N t r a i n N_{train} Ntrain, 右边 α \alpha α是概率、比率
比如同义词替换中,替换的单词数 n = α ∗ l n=\alpha * l n=α∗l, l l l是句子长度。随机插入、随机替换类似。随机删除
的话 p = α p=\alpha p=α. n a v g n_{avg} navg代表使用EDA方法从每一个句子拓展出的句子数量。
原论文地址
github地址






























——第一个MyBatis程序及配置")



还没有评论,来说两句吧...