2.爬虫基础——为什么学习爬虫?
我们来解答上一次提出的问题:为什么花费这么大力气去html页面提取信息干什么?还不如直接打开原始页面进行复制粘贴呢,这不是一样的吗?
第一点:个人复制粘贴的话,一个网页还好,十个网页也还行吧,但是一百个,一千个甚至更多呢?所以说,人力是不足以完成这个工作的。因此需要爬虫的参与。
第二点:爬虫模拟的是人的状态。比如,我想要进行复制粘贴所有的影评信息,是不是应该按顺序打开每一个的影评页面呢?举一个例子:还是豆瓣影评数据->https://movie.douban.com/review/best/【豆瓣最受欢迎的影评信息】
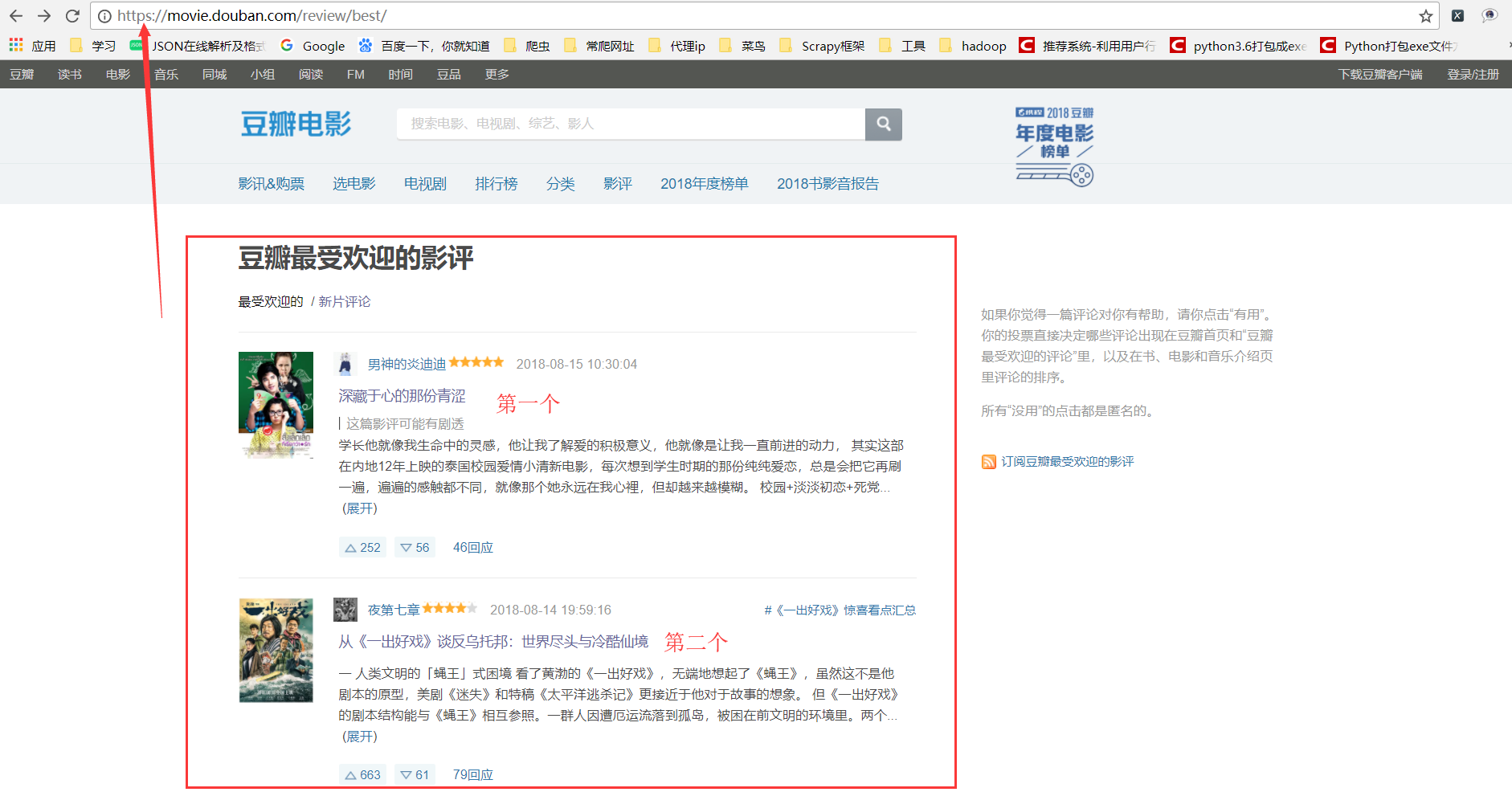
(1)人的状态:点击第一个,获取到影评,接着复制粘贴;然后是第二个,获取到影评,接着复制粘贴…
(2)爬虫的状态:获取第一个url对应的html源码,按照一定规则获取到影评,接着保存数据;获取第二个url对应的html源码,按照一定规则获取到影评,接着保存数据…
实际上,我们发现:爬虫就是完全模拟了人获取数据的操作的过程,把这一切操作过程给程序化了,人是打开网页看到的是html源码对应的页面,而爬虫是获取html源码,在html上按照一定规则进行数据提取。【强大的模拟能力】
第三点:时间成本大大降低。如果是按照人一个一个页面打开复制粘贴的话,整个耗费的时间将会非常多,而爬虫我们只需要写好程序,它就会从不懈怠地执行整个操作,并且大大降低时间成本呢。换句话说,当一个人复制粘贴了1个页面的时候,爬虫可能已经爬取了10个、50个、100个页面,也就是相当于这么多个人,对于公司来说,请这么多人来干这个还不如写个爬虫程序。当然,如果未来进化后的人类处理数据的速度可以超过爬虫,那爬虫存在的意义也就没有了,所以,本质还是成本的问题。


































还没有评论,来说两句吧...