shell编程学习笔记之一--学习第五天
文章目录
- 一、说明:
- 1、整理一些linux命令必须熟练掌握常的命令(复习+扩展学习Linux命令)
- 2、Linux下vim/vi 编辑器 命令总结
- 3、学习课件:
- 4、之前的博客:
- 二、实战演练(几个shell常用命令):
- 1、sed命令:
- 示例1、将name替换为chinese:
- 示例2、在每行开头加入 #id
- 示例3、在每行末尾加入 #id
- 示例4、在含有chinese的行后面加入demo111
- 示例5、在含有chinese的行前加入demo111
- 示例6、高级用法:
- 示例7、给一个含有数字的文件,提取除最大的和最小的俩个数
- 示例8、打印奇数行或偶数行
- 2、grep:
- 1、匹配:含有`127`的行
- 2、匹配含有`192`的行:
- 3、匹配只有`192.`的:
- 4、匹配以`192`开头`.`结尾的行
- 5、匹配一个ip的正确写法:
- 6、吧匹配到的行号打印出来:
- 7、`egrep` 和 `grep -E` 是一样的。
- 3、awk:
- ①、语法
- ②、选项参数说明:
- ③、基本用法
- 1】、匹配第一列:
- 2】、匹配第1和4列:
- 3】、匹配最后一列:
- 4】、匹配到`/etc/passwd`下面的用户名
- 5】、获取本机ip的方法:
- 6】、打印出服务器的使用率的数值:
- 7】、在提取的数值起前面加入一段字符串:
- 4、find:
- 实例1、查找指定目录下的.sh文件:
- 实例2、使用exec进行复制:
- 实例3、删除当前的num.sh文件:
一、说明:
打算从B站学习一下shell编程,从很多的课程视频中,挑选了一个:
B站视频地址:
打算开始学习着做着笔记:
这个需要一些Linux基础,还有vim的,如果不太熟练,可以看下我之前的整理的俩个博客:
1、整理一些linux命令必须熟练掌握常的命令(复习+扩展学习Linux命令)
整理一些linux命令必须熟练掌握常的命令(复习+扩展学习Linux命令)
2、Linux下vim/vi 编辑器 命令总结
Linux下vim/vi 编辑器 命令总结
3、学习课件:
这个地址我直接把B站中评论下方分享的弄出来了,如果失效,可以下方评论,我把我下载的分享给你。
下载地址
4、之前的博客:
shell编程学习笔记之–学习第一天
shell编程学习笔记之–学习第二天
shell编程学习笔记之–学习第三天
shell编程学习笔记之一–学习第四天
二、实战演练(几个shell常用命令):
1、sed命令:
Linux sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。-h或--help 显示帮助。-n或--quiet或--silent 仅显示script处理后的结果。-V或--version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!
示例1、将name替换为chinese:
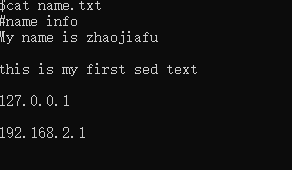
vi name.txt
敲入代码:
#name infoMy name is zhaojiafuthis is my first sed text127.0.0.1192.168.2.1
运行命令:
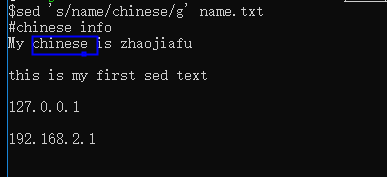
查看是否真正修改name.txt
这个是修改在缓存中,并没有真正修改原文件,需要加个参数-i。
sed -i 's/name/chinese/g' name.txt

再次cat查看,发现修改成功了。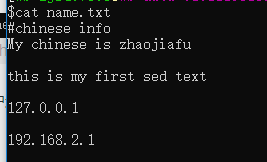
这样就不用打开在vim中进行替换了,vim的末行命令也是可以进行替换操作的。
示例2、在每行开头加入 #id
sed 's/^/& #id/g' name.txt
本文我没有写入,如果真正写入到文档,加个-i参数。^代表开头。
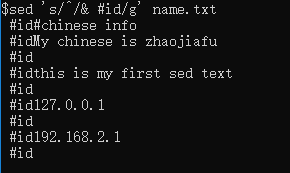
示例3、在每行末尾加入 #id
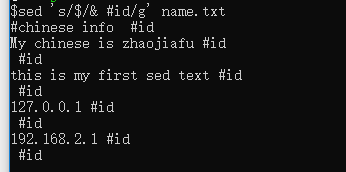
$代表末尾。
sed 's/$/& #id/g' name.txt
示例4、在含有chinese的行后面加入demo111
sed '/chinese/a demo111' name.txt
代码里面的a代表后面。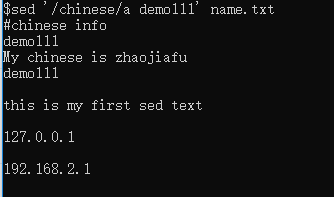
示例5、在含有chinese的行前加入demo111
sed '/chinese/i demo111' name.txt
i代表含有chinese一行的前面加入demo111。
示例6、高级用法:
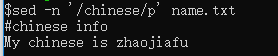
打印出含有chinese的所有行
sed -n ‘/chinese/p’ name.txt
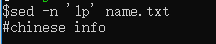
打印文档的第一行:
sed -n ‘1p’ name.txt
打印文档的1-5行:
sed -n ‘1,5p’ name.txt
打印文档的第三行到末尾所有行
sed -n ‘3,$p’ name.txt
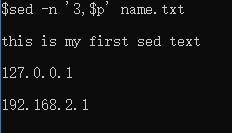
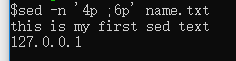
打印文章的第四行至第六行
sed -n ‘4p ;6p’ name.txt
删除文件的20至末尾所有行:
sed -i ‘20,$d’ num_sort.txt

示例7、给一个含有数字的文件,提取除最大的和最小的俩个数
num_sort.txt
12312 2323 32213 2312312321321432423321313213123132131322132412312 2323 32213 2312312321321432423321313213123
- 第一步:将空格替换成换行符:

使用grep将空行去掉:
cat num_sort.txt | sed ‘s/ /\n/g’| grep -v ‘^$’
grep -v 是指去掉后面匹配到的字符串,
‘^$’ 指的是匹配到的空行。

排序:
cat num_sort.txt | sed ‘s/ /\n/g’| grep -v ‘^$’ | sort -nr
sort -n是从小到大排序,r是至反向,-nr就是从大到小排序。


求出最大数和最小数
$cat num_sort.txt | sed ‘s/ /\n/g’| grep -v ‘^$’ | sort -nr |sed -n ‘1p;$p’
21321432423
3
示例8、打印奇数行或偶数行
方法1:
sed -n 'p;n' test.txt #奇数行sed -n 'n;p' test.txt #偶数行
方法2:
sed -n '1~2p' test.txt #奇数行sed -n '2~2p' test.txt #偶数行
2、grep:
我之前的博客记录的有些笔记。地址
实例:
name.txt文件:
$cat name.txt#chinese infoMy chinese is zhaojiafuthis is my first sed text127.0.0.1192.168.2.1192.168.2.192.168.192.
1、匹配:含有127的行
$cat name.txt |grep '127'127.0.0.1
2、匹配含有192的行:
$cat name.txt |grep '192'192.168.2.1192.168.2.192.168.192.
3、匹配只有192.的:
$cat name.txt |grep '^192\.$'192.
4、匹配以192开头.结尾的行
$cat name.txt |grep '^192.*\.$'192.168.2.192.168.192.
5、匹配一个ip的正确写法:
视频中的教程讲的有点不全,我这里写个正确的匹配ip的方法。
其中数字肯定不会0开头,一般1-3位,后面都是0-9的数字。
其中-E代表使用的是正则匹配。
$cat name.txt |grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'127.0.0.1192.168.2.1
6、吧匹配到的行号打印出来:
-n参数就是匹配到的行号打印出来,前面的6:和8:就是第6行和第8行
$cat name.txt |grep -n -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'6:127.0.0.18:192.168.2.1
7、egrep 和 grep -E 是一样的。
$grep -E "192|127" name.txt127.0.0.1192.168.2.1192.168.2.192.168.192.$egrep "192|127" name.txt127.0.0.1192.168.2.1192.168.2.192.168.192.
3、awk:
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。 之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter
Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
①、语法
awk [选项参数] 'script' var=value file(s)或awk [选项参数] -f scriptfile var=value file(s)
②、选项参数说明:
-F fs or --field-separator fs指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。-v var=value or --asign var=value赋值一个用户定义变量。-f scripfile or --file scriptfile从脚本文件中读取awk命令。-mf nnn and -mr nnn对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。-W compact or --compat, -W traditional or --traditional在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。-W copyleft or --copyleft, -W copyright or --copyright打印简短的版权信息。-W help or --help, -W usage or --usage打印全部awk选项和每个选项的简短说明。-W lint or --lint打印不能向传统unix平台移植的结构的警告。-W lint-old or --lint-old打印关于不能向传统unix平台移植的结构的警告。-W posix打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。-W re-interval or --re-inerval允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。-W source program-text or --source program-text使用program-text作为源代码,可与-f命令混用。-W version or --version打印bug报告信息的版本。
③、基本用法
创建一个awk_name.txt文件
$cat awk_name.txtMy name is zhaojiafu1My name is zhaojiafu2My name is zhaojiafu3My name is zhaojiafu4My name is zhaojiafu5My name is zhaojiafu6My name is zhaojiafu7My name is zhaojiafu8My name is zhaojiafu9
1】、匹配第一列:
$cat awk_name.txt |awk '{print $1}'MyMyMyMyMyMyMyMyMy
2】、匹配第1和4列:
$cat awk_name.txt |awk '{print $1,$4}'My zhaojiafu1My zhaojiafu2My zhaojiafu3My zhaojiafu4My zhaojiafu5My zhaojiafu6My zhaojiafu7My zhaojiafu8My zhaojiafu9
3】、匹配最后一列:
$cat awk_name.txt |awk '{print $NF}'zhaojiafu1zhaojiafu2zhaojiafu3zhaojiafu4zhaojiafu5zhaojiafu6zhaojiafu7zhaojiafu8zhaojiafu9
4】、匹配到/etc/passwd下面的用户名
方法一
$cat /etc/passwd |sed "s/:/ /g"|awk '{print $1}'rootbindaemonadm
方法二
$cat /etc/passwd |awk -F: '{print $1}'rootbindaemonadm
其中-F:是以:为切割,默认是空格,也可以以#或者其他字符为分割,-F#。
5】、获取本机ip的方法:
方法一:
$ifconfig eth0|grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'|sed 's/ /\n/g'|grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'|head -n 158.219.63.68
其中:
ifconfig eth0是为了获取含有ip的一组数据grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'是为了获取含有ip地址的一行数据sed 's/ /\n/g'是为了将空格全部替换成换行grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'是为了提取含有所以ip的行head -n 1是为了去第一行(因为第一行才是本机ip地址)
方法二:
我的这个是因为,没有视频中的addr:,有的话自己在进行一个awk -F:'{print $2}'提取即可。
$ifconfig eth0|grep -E '[1-9][0-9]{0,2}(\.[0-9]{1,3}){3}'|awk '{print $2}'58.219.63.68
6】、打印出服务器的使用率的数值:
$df -h|grep '\/$'|awk '{print $5}'|sed "s/%//g"75
7】、在提取的数值起前面加入一段字符串:
方法一:sed
接着上面的数值:
$df -h|grep '\/$'|awk '{print $5}'|sed "s/%//g"|sed "s/^/&使用率:/g"使用率:75
方法二:awk
$df -h|grep '\/$'|awk '{print $5}'|sed "s/%//g"|awk '{print "使用率:"$NF}'使用率:75
4、find:
之前的博客笔记:地址
实例1、查找指定目录下的.sh文件:
查找:
$find ../day03/ -name "*.sh"../day03/read_line.sh../day03/auto_scp.sh../day03/for_str.sh../day03/for_str2.sh../day03/demo/auto_lamp.sh../day03/demo/for2.sh../day03/demo/backup_mysql.sh../day03/demo/for1.sh../day03/demo/backup_time.sh../day03/while2.sh../day03/while.sh
实例2、使用exec进行复制:
$find ../day04/ -name "num.sh" -exec cp { } . \;
其中:
{}代表前面的返回值,填充到这里,和python字符串填充有点像。后面跟的
\;是固定搭配,记得前面要和其他字符有空格。$ls
awk_name.txt name.txt num.sh num_sort.txt sort2.txt sort.txt
实例3、删除当前的num.sh文件:
1.查找:
$find . -name "num.sh"./num.sh$find . -name "num.sh" -exec rm -rf { } \;$lsawk_name.txt name.txt num_sort.txt sort2.txt sort.txt
可以看出已经删除成功。
如果最后的\;和前面的命令没有空格会报错。
报错内容示例:































还没有评论,来说两句吧...