《数据结构与算法》期末考试
《数据结构与算法》期末考试
- 判断题
- 单选题
- 填空题
- 函数题
- 主观题
判断题
- 已知一棵二叉树的先序遍历结果是ABC, 则CAB不可能是中序遍历结果。 (T)
- 所谓“循环队列”是指用单向循环链表或者循环数组表示的队列。(F)
- 只有当局部最优跟全局最优解一致的时候,贪心法才能给出正确的解。(T)
- 若某线性表最常用的操作是存取任一指定序号的元素和在最后进行插入和删除运算,则利用顺序表存储最节省时间 (T)
- 即使把2个元素散列到有100个单元的表中,仍然有可能发生冲突。 (T)
- 算法分析的两个主要方面是时间复杂度和空间复杂度的分析。(T)
- 贪心法是局部搜索的一种特殊情况。(F)
- 对AVL树中的任一结点,其左、右子树的高度一定是一样的。(F)
- Prim 算法是通过每步添加一条边及其相连的顶点到一棵树,从而逐步生成最小生成树。(T)
10.任何最小堆中从根结点到任一叶结点路径上的所有结点是有序的(从小到大)。 (T)
单选题
- 下面四种排序算法中,稳定的算法是: C
A. 堆排序
B. 希尔排序
C. 归并排序
D. 快速排序 - 树最适合于用来表示 : D
A. 有序数据元素
B. 无序数据元素
C. 元素之间无联系的数据
D. 元素之间具有分支层次关系的数据 - 堆的形状是一棵: D
A. 二叉搜索树
B. 满二叉树
C. 非二叉树
D. 完全二叉树 - 对下图进行拓扑排序,可以得到不同的拓扑序列的个数是:B
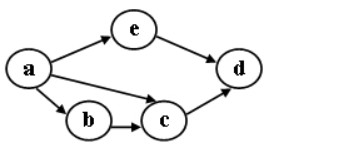
A. 4
B. 3
C. 2
D. 1 - 图的深度优先遍历类似于二叉树的: A
A. 先序遍历
B. 中序遍历
C. 后序遍历
D. 层次遍历 - 线性表、堆栈、队列的主要区别是什么?B
A. 线性表用指针,堆栈和队列用数组
B. 堆栈和队列都是插入、删除受到约束的线性表
C. 线性表和队列都可以用循环链表实现,但堆栈不能
D. 堆栈和队列都不是线性结构,而线性表是 - 具有5个顶点的有向完全图有多少条弧?C
A. 10
B. 16
C. 20
D. 25 - 在图中自c点开始进行广度优先遍历算法可能得到的结果为:C
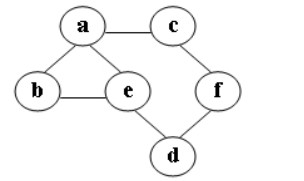
A. c,a,b,e,f,d
B. c,a,f,d,e,b
C. c,f,a,d,e,b
D. c,f,a,b,d,e - 带头结点的单链表h为空的判定条件是: B
A.h == NULL;
B.h->next == NULL;
C.h->next == h;
D.h != NULL; - 给定有向图的邻接矩阵如下:
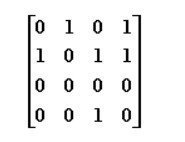
顶点2(编号从0开始)的出度和入度分别是:C
A. 3, 1
B. 1, 3
C. 0, 2
D. 2, 0
填空题
本题要求给出下列无权图中从B到其他顶点的最短路径。注意:填空时不能有任何空格,字母必须为大写。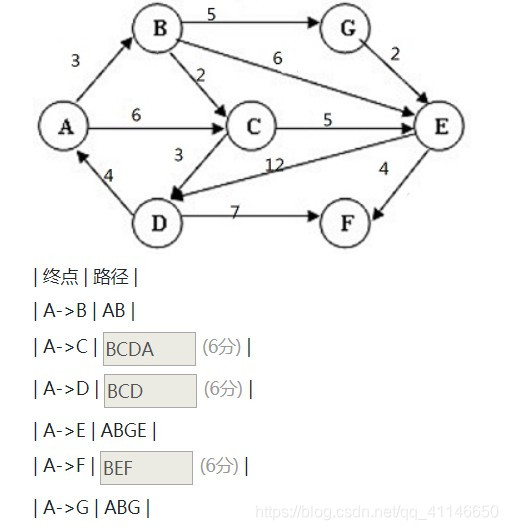
函数题
链式表的按序号查找
本题要求实现一个函数,找到并返回链式表的第K个元素。
函数接口定义:ElementType FindKth( List L, int K );
其中List结构定义如下
typedef struct LNode *PtrToLNode;struct LNode {ElementType Data;PtrToLNode Next;};typedef PtrToLNode List;
L是给定单链表,函数FindKth要返回链式表的第K个元素。如果该元素不存在,则返回ERROR
裁判测试程序样例:
#include <stdio.h>#include <stdlib.h>#define ERROR -1typedef int ElementType;typedef struct LNode *PtrToLNode;struct LNode {ElementType Data;PtrToLNode Next;};typedef PtrToLNode List;List Read(); /* 细节在此不表 */ElementType FindKth( List L, int K );int main(){int N, K;ElementType X;List L = Read();scanf("%d", &N);while ( N-- ) {scanf("%d", &K);X = FindKth(L, K);if ( X!= ERROR )printf("%d ", X);elseprintf("NA ");}return 0;}/* 你的代码将被嵌在这里 */
输入样例:
1 3 4 5 2 -163 6 1 5 4 2
输出样例:
4 NA 1 2 5 3
参考代码:
ElementType FindKth( List L, int K ){if(L==NULL)return ERROR;if(K<1)return ERROR;int i=1;List p=L;while(i<K){if(p==NULL)return ERROR;p=p->Next;i=i+1;}if(p==NULL)return ERROR;return p->Data;}
先序输出叶结点
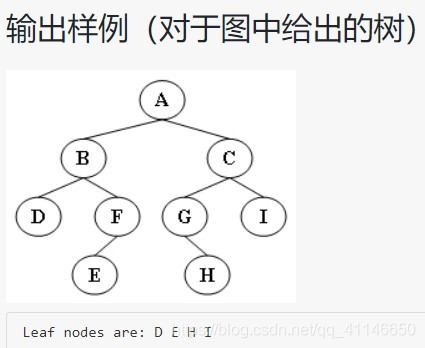
本题要求按照先序遍历的顺序输出给定二叉树的叶结点。
函数接口定义:void PreorderPrintLeaves( BinTree BT );
其中BinTree结构定义如下:
typedef struct TNode *Position;typedef Position BinTree;struct TNode{ElementType Data;BinTree Left;BinTree Right;};
函数PreorderPrintLeaves应按照先序遍历的顺序输出给定二叉树BT的叶结点,格式为一个空格跟着一个字符。
裁判测试程序样例:
#include <stdio.h>#include <stdlib.h>typedef char ElementType;typedef struct TNode *Position;typedef Position BinTree;struct TNode{ElementType Data;BinTree Left;BinTree Right;};BinTree CreatBinTree(); /* 实现细节忽略 */void PreorderPrintLeaves( BinTree BT );int main(){BinTree BT = CreatBinTree();printf("Leaf nodes are:");PreorderPrintLeaves(BT);printf("\n");return 0;}/* 你的代码将被嵌在这里 */
参考代码:
void PreorderPrintLeaves( BinTree BT ){if(BT!=NULL){if(BT->Left==NULL&&BT->Right==NULL)printf(" %c",BT->Data);else{PreorderPrintLeaves(BT->Left);PreorderPrintLeaves(BT->Right);}}}
主观题
请简述分而治之算法的思想。请举三个能利用分治算法解决实际问题的例子。选择其中一个例子描述解决该问题的过程
分而治之算法思想是把一个问题规模可以转化成若干个独立的子问题,而其中这个子问题又可以在划分成更小的独立子问题,对于一些问题小规模,我们可以直接利用求得解,并且问题规模比较大的可以利用得到子问题去合并得到解,而把问题划分成小问题时,我们可以利用递归去求解。
利用分而治之算法思想的去解决实际问题的例子:
(1).残缺棋盘问题求解
(2).归并排序
(3).快速排序
(4).选择问题
(5).金块问题,假硬币问题等等
快速排序的具体算法思路:
对于1个待排序的序列,利用分治法去求解的关键怎样把该问题去分解成若干个子问题,排序的结果是把序列按照我们的要求有序,我们先假设该序列不含有相同的关键字,并对该序列进行从小到大的排序,我们选择一个基准,使得我们待要排序的序列分成两部分,一部分比这个基准要小,一部分比这个基准要大,把这个基准放在其两个部分序列的中间,这样我们可以得到这样的一个的结果,基准的左边的数要比这个基准要小,而基准的右边比这个基准要大,也就是这两部分的数相对于这个基准已经达到我们的排序要求,并且我们发现这两部分的序列的数是相对独立的。而现在如果我们能够使这两部分的序列达到有序的要求,那我们就完成排序的任务。而对于这两部分的序列我们又可以按照刚才的思路对其进行划分,这一部分就是递归的部分,对于什么样的子问题规模不需要再划分了,我们可以认为一个数本身就是一个有序的序列,这样我们划分到一个数就需要再划分了。这个就完成对序列的排序。
对于这个基准怎么去选择,简单的就可以默认待排序的序列第一个为基准,而对于含有相同的关键字,只是在条件判断的时候加上一个相等的操作就行。对这个序列我们采取双指针扫描法,
把左指针放在第二个位置,右指针放在最后一个位置,对于从小到大进行排序,我们把左指针如果满足小于等于基准即第一个数,我就继续往左移动,直到大于基准时,这使再移动右指针,右指针如果满足大于等于基准即第一个数,我就继续往右移动,直到小于基准时,如果左指针小于右指针,代表我们对序列没有进行判断完,需要继续判断,这时把左右指针对应的值交换就行,再继续扫描,直到左指针大于或等于右指针的时候,退出循环,这时候把右指针对于的值于基准即第一个数进行交换,就满足基准的左边的数要比这个基准要小,而基准的右边比这个基准要大,这时候我们再对基准的左边和右边的序列再进行上述操作即可。(对于1个的序列我们就不需要再划分了)。
对于快速排序的时间复杂度,平均情况下,快速排序的时间复杂度为O(NlogN),对于一个基本有序的序列,快速排序的时间的复杂度要高一些,即快速排序在最坏的情况下时间复杂度为O(N^2)。


























![[我眼中的C#]简单的变量类型](https://image.dandelioncloud.cn/images/20220708/2894297011e2409db6449a173a83104b.png "[我眼中的C#]简单的变量类型")
 the action")


![[我眼中的C#]显式转换和隐式转换](https://image.dandelioncloud.cn/images/20220708/dd35a0cc723545348c7a29514bf14a54.png "[我眼中的C#]显式转换和隐式转换")


还没有评论,来说两句吧...