【损失函数合集】ECCV2016 Center Loss
前言
感觉一年下来了解了很多损失函数,准备做一个【损失函数合集】不定期更新一些损失函数的解读,相信这个系列会成为工程派非常感兴趣的一个专题,毕竟这可能是工程量最小同时可能会在某个任务上取得较大提升的最简单有效的方法了。话不多说,今天来介绍一下ECCV 2016的Center Loss。论文链接见附录。
介绍
我们知道在利用卷积神经网络(CNN)进行特征提取然后做分类任务的时候,最常用的就是Softmax Loss了。而Softmax Loss对CNN的分类特征没有什么强约束,只要最后可以把样本分开就可以了,没有明确的定义某个分类特征 x x x和它的类别 y y y需要有什么关系,也即是对 x x x的约束并不强。当给CNN传入一些对抗样本的时候,CNN会表现出分类困难。原因就是CNN对对抗样本提取的特征基本处于最后一层分类特征的边界上,使得类别的区分度低。论文在Figure2为我们展示了Mnist数据集的特征分布图(这是降维可视化之后的),如下所示:
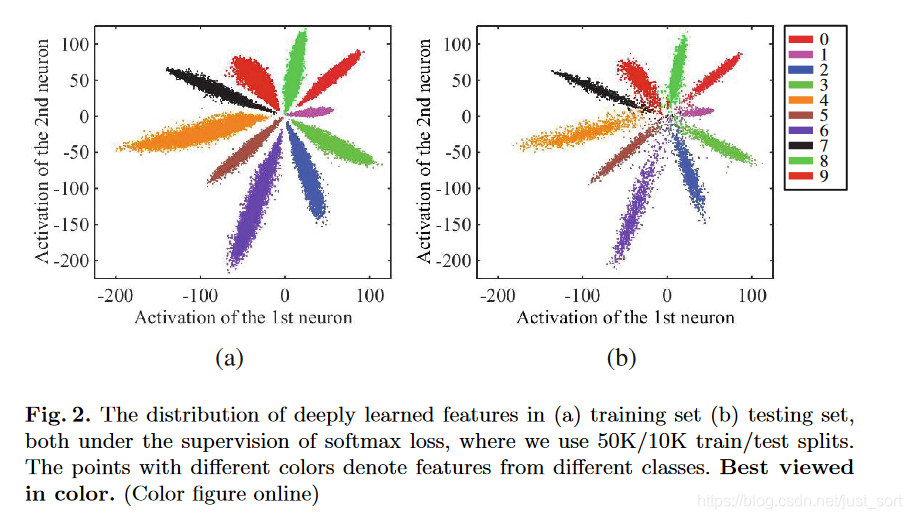
Figure2(a)表示训练集的特征,可以看到不同的类别之间的特征是有明显的间隔的,所以分类器很容易区分样本的类别。而Figure2(b)表示的是测试集的特征,可以看到,有些测试集样本的特征位于分类的边界上,这使得分类器非常难以判断这些样本的具体类别。这种现象用更专业的话来说就是分类器的特征类间相似度小,而类内相似度大。这和聚类里面的思想有一点像,聚类的时候需要尽可能的让同一个簇里面的相似度更大大,而簇之间的相似度更小,这样聚类的结果才更好。
更正式地,论文指出CNN学习到的特征应当具有“类内紧凑性”和“类间可分离性”,意思上面大概理解过了,下面就用这两个名词来描述了。
相关工作
为了对CNN学习到的特征的“类内紧凑性”进行约束,Contrastive Loss和Triple Loss被提出,这两个Loss这几天会接着介绍,今天先介绍Center Loss,不懂这两个个Loss也不太不影响理解Center Loss。简单来说,Contrastive Loss的思想是最小化一对同类样本特征之间的距离,最大化一对不同样本特征之间的距离。而Triplets loss则把一对变成3个。这两个Loss均要把样本进行组合来进行优化,导致样本的数量急剧增加( O ( n 2 ) , O ( n 3 ) O(n^2), O(n^3) O(n2),O(n3)),因此加长了训练时间并且训练难度也大大增加,为了改善这一缺点Center Loss被提出。
Center Loss
Center Loss可以直接对样本特征之间的距离进行约束。Center Loss添加的约束是,特征与相同类别的平均特征(有”Center”的味道了)的距离要足够小,即要求同类特征要更加接近它们的中心点,用公式来表达:
L C = 1 2 ∑ i = 1 m ∣ ∣ x i − c y i ∣ ∣ 2 2 L_{C}=\frac{1}{2}\sum_{i=1}^m||x_i-c_{y_i}||_2^2 LC=21∑i=1m∣∣xi−cyi∣∣22
其中 x i x_i xi表示第 i i i个样本被CNN提取的特征, c y i c_{y_i} cyi表示第 i i i类样本的平均特征, m m m表示样本数。从公式可以看到如果我们要计算同一类别所有样本的特征然后求平均值的话是不太可能的,因为数据量多了之后这个计算复杂度非常高。因为论文提出用mini-batch中每个类别的平均特征近似不同类别所有样本的平均特征,有点类似于BN层。
关于 L c L_c Lc的梯度和 c y i c_{y_i} cyi的更新公式如下:
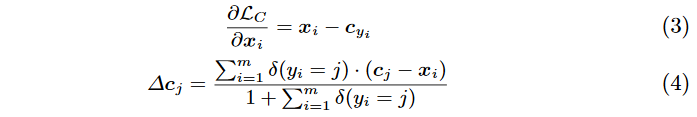 其中 δ ( x ) \delta(x) δ(x)函数代表的是当x为真时返回 1 1 1,否则为 0 0 0。而分母的 1 1 1是防止min-batch中没有类别 j j j的样本而导致除 0 0 0异常。然后论文还设置了一个 c j c_j cj的更新速率 α \alpha α,控制 c j c_j cj的更新速度。最后训练的总损失函数为:
其中 δ ( x ) \delta(x) δ(x)函数代表的是当x为真时返回 1 1 1,否则为 0 0 0。而分母的 1 1 1是防止min-batch中没有类别 j j j的样本而导致除 0 0 0异常。然后论文还设置了一个 c j c_j cj的更新速率 α \alpha α,控制 c j c_j cj的更新速度。最后训练的总损失函数为: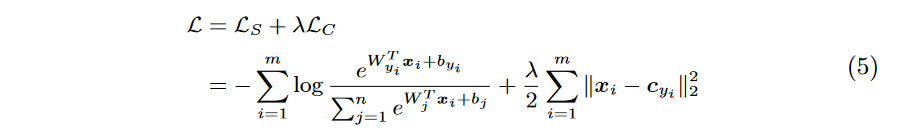 最后,Center Loss的算法表示如下:
最后,Center Loss的算法表示如下:

实验结果
对于不同的 λ \lambda λ,网络提取的特征具有不同的区分度,具体如Figure3所示,可以看到随着 λ \lambda λ的增加,特征的“类内紧凑性”越高。

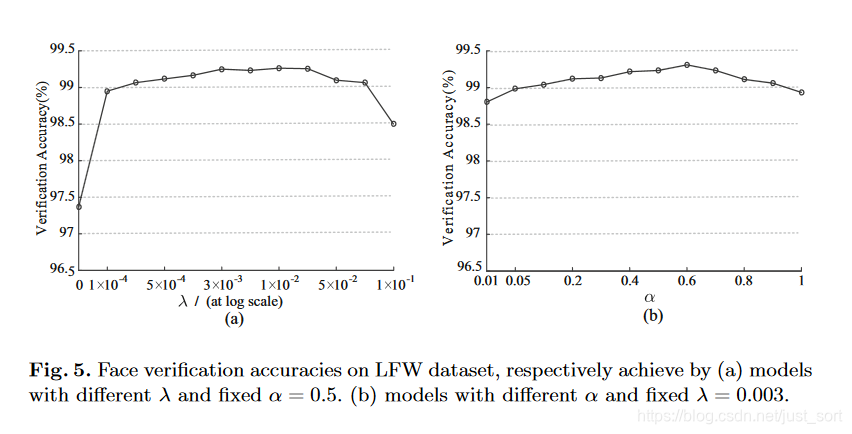
同时作者还研究了不同的 λ \lambda λ和 α \alpha α对人脸识别任务的影响,如Figure5所示,可以看出当 λ = 0.003 \lambda=0.003 λ=0.003和 α = 0.5 \alpha=0.5 α=0.5的时候对人脸识别是效果最好的。
代码实现
import torchimport torch.nn as nnfrom torch.autograd.function import Functionclass CenterLoss(nn.Module):def __init__(self, num_classes, feat_dim, size_average=True):super(CenterLoss, self).__init__()self.centers = nn.Parameter(torch.randn(num_classes, feat_dim))self.centerlossfunc = CenterlossFunc.applyself.feat_dim = feat_dimself.size_average = size_averagedef forward(self, label, feat):batch_size = feat.size(0)feat = feat.view(batch_size, -1)# To check the dim of centers and featuresif feat.size(1) != self.feat_dim:raise ValueError("Center's dim: {0} should be equal to input feature's \dim: {1}".format(self.feat_dim,feat.size(1)))batch_size_tensor = feat.new_empty(1).fill_(batch_size if self.size_average else 1)loss = self.centerlossfunc(feat, label, self.centers, batch_size_tensor)return lossclass CenterlossFunc(Function):@staticmethoddef forward(ctx, feature, label, centers, batch_size):ctx.save_for_backward(feature, label, centers, batch_size)centers_batch = centers.index_select(0, label.long())return (feature - centers_batch).pow(2).sum() / 2.0 / batch_size@staticmethoddef backward(ctx, grad_output):feature, label, centers, batch_size = ctx.saved_tensorscenters_batch = centers.index_select(0, label.long())diff = centers_batch - feature# init every iterationcounts = centers.new_ones(centers.size(0))ones = centers.new_ones(label.size(0))grad_centers = centers.new_zeros(centers.size())counts = counts.scatter_add_(0, label.long(), ones)grad_centers.scatter_add_(0, label.unsqueeze(1).expand(feature.size()).long(), diff)grad_centers = grad_centers/counts.view(-1, 1)return - grad_output * diff / batch_size, None, grad_centers / batch_size, Nonedef main(test_cuda=False):print('-'*80)device = torch.device("cuda" if test_cuda else "cpu")ct = CenterLoss(10,2,size_average=True).to(device)y = torch.Tensor([0,0,2,1]).to(device)feat = torch.zeros(4,2).to(device).requires_grad_()print (list(ct.parameters()))print (ct.centers.grad)out = ct(y,feat)print(out.item())out.backward()print(ct.centers.grad)print(feat.grad)if __name__ == '__main__':torch.manual_seed(999)main(test_cuda=False)if torch.cuda.is_available():main(test_cuda=True)
结论
这篇推文给大家介绍了Center Loss,可以改善分类的时候的“类内紧凑性”小的问题(这同时也放大了“类间可分离性”),是一个值得工程尝试的损失函数。
附录
- 论文原文:http://ydwen.github.io/papers/WenECCV16.pdf
- 代码实现:https://github.com/jxgu1016/MNIST\_center\_loss\_pytorch/blob/master/CenterLoss.py
推荐阅读
- 目标检测算法之RetinaNet(引入Focal Loss)
- 目标检测算法之AAAI2019 Oral论文GHM Loss
- 目标检测算法之CVPR2019 GIoU Loss
- 目标检测算法之AAAI 2020 DIoU Loss 已开源(YOLOV3涨近3个点)
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:



























")



")



还没有评论,来说两句吧...