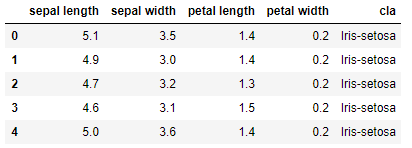
import numpy as npimport matplotlib as mplimport matplotlib.pyplot as pltimport pandas as pdimport warningsimport sklearnfrom sklearn.linear_model import LogisticRegressionCVfrom sklearn.linear_model.coordinate_descent import ConvergenceWarningfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.preprocessing import label_binarizefrom sklearn import metrics# 设置字符集,防止中文乱码mpl.rcParams['font.sans-serif']=[u'simHei']mpl.rcParams['axes.unicode_minus']=False# 拦截异常warnings.filterwarnings(action = 'ignore', category=ConvergenceWarning)# 数据加载path = "datas/iris.data"names = ['sepal length', 'sepal width', 'petal length', 'petal width', 'cla']df = pd.read_csv(path, header=None, names=names)df['cla'].value_counts()df.head()
def parseRecord(record): result=[] r = zip(names,record) for name,v in r: if name == 'cla': if v == 'Iris-setosa': result.append(1) elif v == 'Iris-versicolor': result.append(2) elif v == 'Iris-virginica': result.append(3) else: result.append(np.nan) else: result.append(float(v)) return result# 1. 数据转换为数字以及分割# 数据转换datas = df.apply(lambda r: parseRecord(r), axis=1)# 异常数据删除datas = datas.dropna(how='any')# 数据分割X = datas[names[0:-1]]Y = datas[names[-1]]# 数据抽样(训练数据和测试数据分割)X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.4, random_state=0)print ("原始数据条数:%d;训练数据条数:%d;特征个数:%d;测试样本条数:%d" % (len(X), len(X_train), X_train.shape[1], X_test.shape[0]))
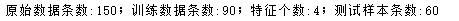
# 2. 数据标准化ss = StandardScaler()X_train = ss.fit_transform(X_train)X_test = ss.transform(X_test)# 3. 特征选择# 4. 降维处理# 5. 模型构建lr = LogisticRegressionCV(Cs=np.logspace(-4,1,50), cv=3, fit_intercept=True, penalty='l2', solver='lbfgs', tol=0.01, multi_class='multinomial')# solver可选:‘newton-cg’, 'lbfgs', 'liblinear', 'sag'(mini-batch),默认为liblinearlr.fit(X_train, Y_train)
# 6. 模型效果输出# 将正确的数据转换为矩阵形式y_test_hot = label_binarize(Y_test,classes=(1,2,3))# 得到预测的损失值lr_y_score = lr.decision_function(X_test)# 计算ROC的值lr_fpr, lr_tpr, lr_threasholds = metrics.roc_curve(y_test_hot.ravel(),lr_y_score.ravel())# threasholds阈值# 计算AUC的值lr_auc = metrics.auc(lr_fpr, lr_tpr)print ("Logistic算法R值:", lr.score(X_train, Y_train))print ("Logistic算法AUC值:", lr_auc)# 7. 模型预测lr_y_predict = lr.predict(X_test)

# KNN算法实现# a. 模型构建knn = KNeighborsClassifier(n_neighbors=3)knn.fit(X_train, Y_train)# b. 模型效果输出# 将正确的数据转换为矩阵形式y_test_hot = label_binarize(Y_test,classes=(1,2,3))# 得到预测的损失值knn_y_score = knn.predict_proba(X_test)# 计算ROC的值knn_fpr, knn_tpr, knn_threasholds = metrics.roc_curve(y_test_hot.ravel(),knn_y_score.ravel())# 计算AUC的值knn_auc = metrics.auc(knn_fpr, knn_tpr)print ("KNN算法R值:", knn.score(X_train, Y_train))print ("KNN算法AUC值:", knn_auc)# c. 模型预测knn_y_predict = knn.predict(X_test)knn_y_score

# 画图1:ROC曲线画图plt.figure(figsize=(8, 6), facecolor='w')plt.plot(lr_fpr,lr_tpr,c='r',lw=2,label=u'Logistic算法,AUC=%.3f' % lr_auc)plt.plot(knn_fpr,knn_tpr,c='g',lw=2,label=u'KNN算法,AUC=%.3f' % knn_auc)plt.plot((0,1),(0,1),c='#a0a0a0',lw=2,ls='--')# 设置X轴的最大和最小值plt.xlim(-0.01, 1.02)# 设置y轴的最大和最小值plt.ylim(-0.01, 1.02)plt.xticks(np.arange(0, 1.1, 0.1))plt.yticks(np.arange(0, 1.1, 0.1))plt.xlabel('False Positive Rate(FPR)', fontsize=16)plt.ylabel('True Positive Rate(TPR)', fontsize=16)plt.grid(b=True, ls=':')plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)plt.title(u'鸢尾花数据Logistic和KNN算法的ROC/AUC', fontsize=18)plt.show()

# 画图2:预测结果画图x_test_len = range(len(X_test))plt.figure(figsize=(12, 9), facecolor='w')plt.ylim(0.5,3.5)plt.plot(x_test_len, Y_test, 'ro',markersize = 6, zorder=3, label=u'真实值')plt.plot(x_test_len, lr_y_predict, 'go', markersize = 10, zorder=2, label=u'Logis算法预测值,$R^2$=%.3f' % lr.score(X_test, Y_test))plt.plot(x_test_len, knn_y_predict, 'yo', markersize = 16, zorder=1, label=u'KNN算法预测值,$R^2$=%.3f' % knn.score(X_test, Y_test))plt.legend(loc = 'lower right')plt.xlabel(u'数据编号', fontsize=18)plt.ylabel(u'种类', fontsize=18)plt.title(u'鸢尾花数据分类', fontsize=20)plt.show()





























还没有评论,来说两句吧...