FCN模型实现-Pytorch+预训练VGG16
FCN模型的网络与VGG16类似,之后后边将全连接层换成了卷基层,具体的网络结构与细节可以去看论文:
https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
下边详细讲一下用Pytorch对FCN的实现:
本文参考了https://zhuanlan.zhihu.com/p/32506912 但是修改了部分代码,加上了很多新的注释,并将代码更新到Pytorch1.x
首先是读取图像
#使用的VOC数据目录voc_root = '/media/cyq/CU/Ubuntu system files/VOCdevkit/VOC2012'#此函数用来读取图像和标签的名字def read_images(root=voc_root, train=True):txt_fname = root + '/ImageSets/Segmentation/' + ('train.txt' if train else 'val.txt')with open(txt_fname, 'r') as f:images = f.read().split()data = [os.path.join(root, 'JPEGImages', i+'.jpg') for i in images]label = [os.path.join(root, 'SegmentationClass', i+'.png') for i in images]return data, label
对输入图像做出裁剪,使图像大小一致,方便训练
#这里对图像和标签都截取对应的部分def rand_crop(data, label, height, width):'''data is PIL.Image objectlabel is PIL.Image object'''x = random.uniform(0,data.size[0]-width)x = int(x)y = random.uniform(0,data.size[1]-height)y = int(y)box = (x,y,x+width,y+height)data = data.crop(box)label = label.crop(box)return data, label
label图像与标签的映射
#21个类classes = ['background','aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable','dog','horse','motorbike','person','potted plant','sheep','sofa','train','tv/monitor']# 每个类对应的RGB值colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],[64,128,0],[192,128,0],[64,0,128],[192,0,128],[64,128,128],[192,128,128],[0,64,0],[128,64,0],[0,192,0],[128,192,0],[0,64,128]]#下边就是将label中每种颜色映射成0-20的数字cm2lbl = np.zeros(256**3) # 每个像素点有 0 ~ 255 的选择,RGB 三个通道for i,cm in enumerate(colormap):cm2lbl[(cm[0]*256+cm[1])*256+cm[2]] = i # 建立索引def image2label(im):data = np.array(im, dtype='int32')idx = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2]return np.array(cm2lbl[idx], dtype='int64') # 根据索引得到 label 矩阵
数据集制作
def img_transforms(im, label, crop_size):im, label = rand_crop(im, label, *crop_size)im_tfs = tfs.Compose([tfs.ToTensor(),tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])im = im_tfs(im)label = image2label(label)label = torch.from_numpy(label)return im, labelclass VOCSegDataset(data.Dataset):'''voc dataset'''def __init__(self, train, crop_size, transforms):self.crop_size = crop_sizeself.transforms = transformsdata_list, label_list = read_images(train=train)self.data_list = self._filter(data_list)self.label_list = self._filter(label_list)print('Read ' + str(len(self.data_list)) + ' images')def _filter(self, images): # 过滤掉图片大小小于 crop 大小的图片return [im for im in images if (Image.open(im).size[1] >= self.crop_size[0] andImage.open(im).size[0] >= self.crop_size[1])]def __getitem__(self, idx):img = self.data_list[idx]label = self.label_list[idx]img = Image.open(img)label = Image.open(label).convert('RGB')img, label = self.transforms(img, label, self.crop_size)return img, labeldef __len__(self):return len(self.data_list)# 实例化数据集input_shape = (320, 480)voc_train = VOCSegDataset(True, input_shape, img_transforms)voc_test = VOCSegDataset(False, input_shape, img_transforms)train_data = DataLoader(voc_train, 4, shuffle=True, num_workers=4)valid_data = DataLoader(voc_test, 4, num_workers=4)
模型定义(这里使用FCN32s)
# 使用预训练的 VGG16pretrained_net = models.vgg16(pretrained=True)num_classes = len(classes)class fcn(nn.Module):def __init__(self, num_classes):super(fcn, self).__init__()#卷积层使用VGG16的self.features = pretrained_net.features#将全连接层替换成卷积层self.conv1 = nn.Conv2d(512, 4096, 1)self.conv2 = nn.Conv2d(4096, 21, 1)self.relu = nn.ReLU(inplace=True)#上采样,这里只用到了32的self.upsample2x = nn.Upsample(scale_factor=2, mode='bilinear',align_corners=False)self.upsample8x = nn.Upsample(scale_factor=8, mode='bilinear', align_corners=False)self.upsample32x = nn.Upsample(scale_factor=32,mode='bilinear',align_corners=False)def forward(self, x):s = self.features(x)s = self.conv1(s)s = self.relu(s)s = self.conv2(s)s = self.relu(s)s = self.upsample32x(s)return s#创建模型net = fcn(num_classes)net.cuda()
参数设定,这里还是有很大可优化空间的
criterion = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(), lr=1e-2, weight_decay=1e-4)
计算准确率,这里使用像素点准确率
def acc_simu(label_true,label_pred):#所有像素点个数sum = len(voc_train.data_list)*label_true.shape[1]*label_true.shape[2]cnt = 0.check = label_true==label_predfor i in range(0,label_pred.shape[0]):for j in range(0,label_pred.shape[1]):for k in range(0,label_pred.shape[2]):if check[i][j][k]:cnt = cnt + 1return 100.*cnt/sum
模型训练
for e in range(80):train_loss = 0train_acc = 0#记录所花时间prev_time = datetime.datetime.now()net = net.train()for data in train_data:im = data[0].cuda()label = data[1].cuda()# forwardout = net(im)out = F.log_softmax(out, dim=1) # (b, n, h, w)loss = criterion(out, label)# backwardoptimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()label_pred = out.max(dim=1)[1].data.cpu().numpy()label_true = label.data.cpu().numpy()acc = acc_simu(label_true,label_pred)train_acc += accprint(train_acc,'%')net = net.eval()eval_loss = 0eval_acc = 0for data in valid_data:im = data[0].cuda()label = data[1].cuda()# forwardwith torch.no_grad():out = net(im)out = F.log_softmax(out, dim=1)loss = criterion(out, label)eval_loss += loss.item()label_pred = out.max(dim=1)[1].data.cpu().numpy()label_true = label.data.cpu().numpy()acc = acc_simu(label_true,label_pred)eval_acc += acccur_time = datetime.datetime.now()h, remainder = divmod((cur_time - prev_time).seconds, 3600)m, s = divmod(remainder, 60)epoch_str = ('Epoch: {}, Train Loss: {:.5f}, Train Acc: {:.5f}, \Valid Loss: {:.5f}, Valid Acc: {:.5f} '.format(e, train_loss / len(train_data), train_acc,eval_loss / len(valid_data), eval_acc))time_str = 'Time: {:.0f}:{:.0f}:{:.0f}'.format(h, m, s)print(epoch_str+time_str)torch.save(net, 'model.pkl')
运行结果
由于使用了VGG16预训练模型,使得模型训练容易了很多,经过了10次迭代,训练集正确率达到90.38%,测试集达到了81.77%然后我调节了学习率,又迭代了五次,训练集正确率达到了93.29%,然而测试机依旧才达到81.94% ,和论文中达到了89.1%还是有些差距的
下边贴出几张该模型图像分割之后的示例:



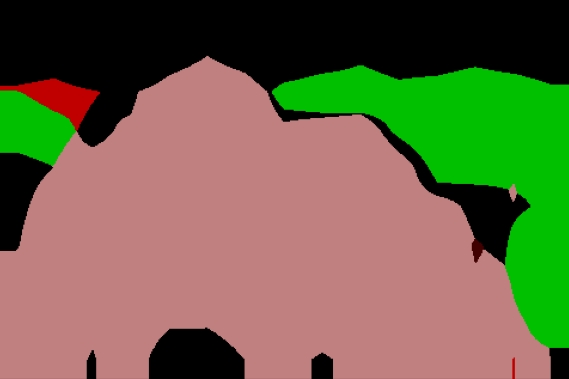

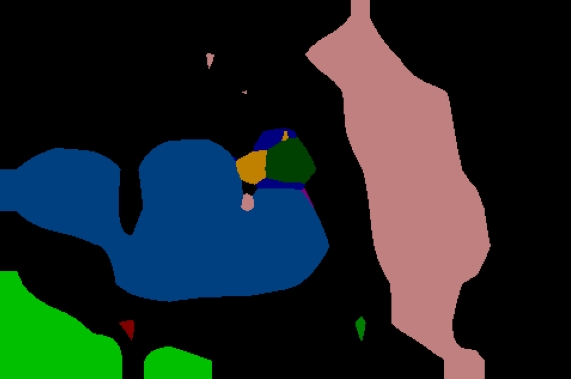
可以看出分割的物体大致还是被区别开了,但是轮廓地区错误率依旧很高,有一些图像内容比较复杂的出入就会相当大**博客代码可以按顺序copy到编译器中运行**

























和free()的原理及实现")








还没有评论,来说两句吧...