Python爬虫某招聘网站的岗位信息
前言" class="reference-link"> 前言
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:阿尔法游戏
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http://t.cn/A6Zvjdun
故事又要从一个盆友说起

昨晚有个盆友 问我 爬虫学的怎么样了?
正当我不明所以之际,盆友的微信语音通话接了进来
友:“看你在学python,爬虫写的怎么样了呀,我想抓一下某招聘网站的数据,能帮我整一个吗,不行的话我也去看看”
我:“哦哦,你不是技术嘛,自己来嘛
友:“我不是没怎么接触过嘛”
我:“行,刚好我也学习下,周末有时间我帮你看下”
简单介绍下这个朋友吧,游戏圈某技术大拿,真大拿的那种!!
故事聊完了,咱们开工吧
1、前期准备
因为是爬虫,所以咱们需要用到如下几个库
- requests
- fake_useragent
- json
- pandas
Requests 的介绍是这样的: 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用
反正就是你用来获取网页数据需要用到的,本次咱们只需要用到get方法:
res=request.get(url)构造一个向服务器请求资源的url对象, 这个对象是Request库内部生成的, 这时候的res返回的是一个包含服务器资源的Response对象,包含从服务器返回的所有的相关资源。
fake_useragent 直译就是 假身份,作用和直译基本一样,是个表里不一的“人”
UserAgent是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换UserAgent可以避免触发相应的反爬机制。fake-useragent对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。
json 就是上期我们本来打算介绍但是换了一个库实现的 用于处理json数据,可以将已编码的 JSON 字符串解码为 Python 对象
pandas 是我们的老朋友了,因为常和excel打交道,对表格的钟爱,所以pandas在这里主要作用只是将抓取的数据转化为dataframe型后导出成excel表
导入需要用到的库
import requestsfrom fake_useragent import UserAgentimport jsonimport pandas as pdimport time
2、任务分析
其实这步应该在 第1步 前期准备 之前,但是文档写到了这里,咱也不想回去了。
这一步很关键,主要是思路分析,大致可以分为以下几点:
- 明确你需要的数据是什么
- 找到你需要的数据来源
- 理清原始数据的结构
- 输出你需要的数据形式
1)明确你需要的数据
比如盆友需要岗位信息,包含哪些字段,常规的有岗位名称、薪酬范围、需要的工作年限等等。当你明确需要的数据指标之后,你再去数据来源看是否有这些指标已经如何获取。
| 岗位 | 薪酬 | 年限 |
|---|---|---|
| 运营 | 30-50k | 5-8年 |
| 技术 | 30-50k | 5-8年 |
2)找到你需要的数据来源
盆友需要的是脉脉上的岗位信息,那么我们需要熟悉脉脉的岗位信息在哪可见,以及它们是如何展示的。
这是移动端
移动端没法直接获取url信息,我们可以去pc端看看
这是pc端
这里pc端用的是Google Chrome浏览器 为了让你能够点开xhr等等,你需要安装一个浏览器工具
下载浏览器驱动程序:http://chromedriver.storage.googleapis.com/index.html
查看驱动和浏览器版本的映射关系:http://blog.csdn.net/huilan\_same/article/details/51896672
pc端是一个列表,我们通过下拉可以加载更多,这说明这个页面是非静态页面,因此在获取url的时候需要特别注意。
操作流程:
- 第1步,获取数据源URL地址: F12 打开浏览器开发者工具调试页面,选中network——xhr,刷新网页后选择 招聘,可以看见右侧有刷新调试页面有内容刷新,选中最近一个刷新的条目即可获取数据源url地址,见右侧的request URL内容即是。
- 第2步,找到该URL地址规律: url = ‘https://maimai.cn/sdk/company/obtian\_company\_job?webcid=jYZTTwkX&count=20&page=0&job\_title='(你点了应该会提示没数据),仔细分析,我们可以得到动态变化部分应该为count和page,count表示每页20个,page表示当前页数。通过修改count和page后再浏览器打开我们验证了该判断。
- 第3步,获取数据源URL地址: 因为网页动态,这里建议把cookie记录下来备用,cookie数据在request Header中。
3)理清原始数据的结构
当我们获取到数据来源url之后,就需要理清这些原始数据长啥样,如此才好去解析整理出想要的信息。打开一个url,我们发现是一个json,嗯,很完整的多层json。
网页json图
使用json.loads方法做简单的预处理,然后我们一层一层寻找目标数据指标所在。
【这里我是通过spyder变量管理器 点开数据 让大家直观理解】
- 第一层:字典
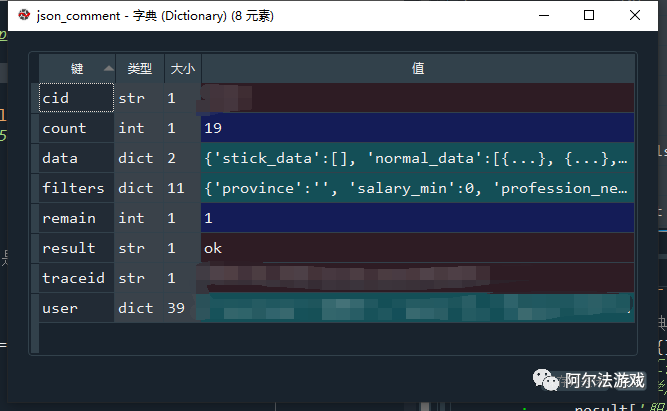
- 第二层:字典
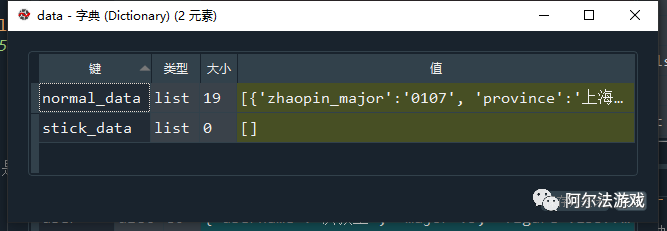
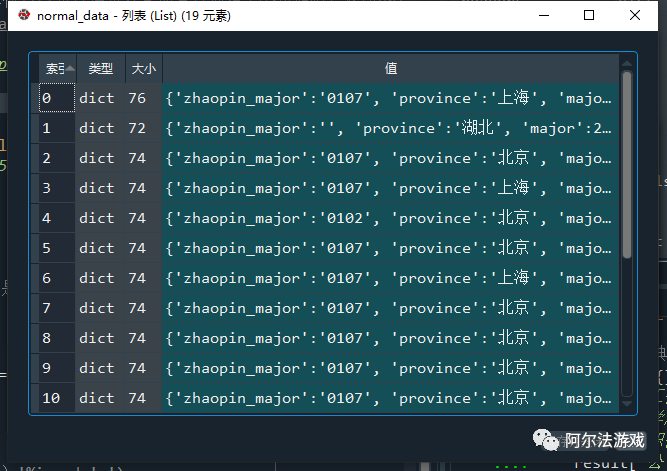
- 第三层:列表
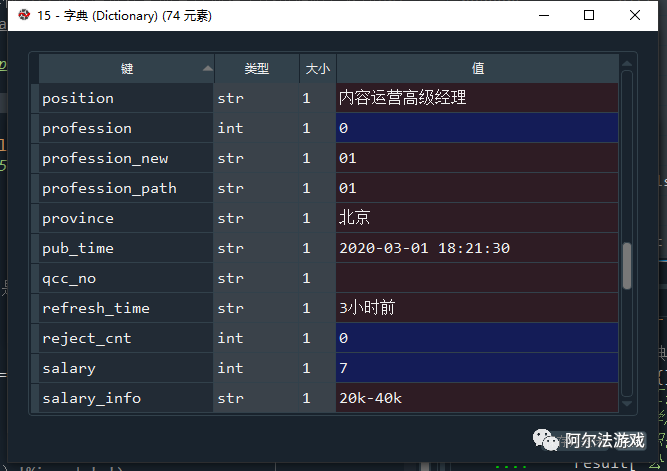
- 第四层:字典
4)输出你需要的数据
通过理清原始数据结构,结合你需要的数据,咱们就可以进行数据简单过滤选择了
直接创建一个空字典,存储你需要的数据信息
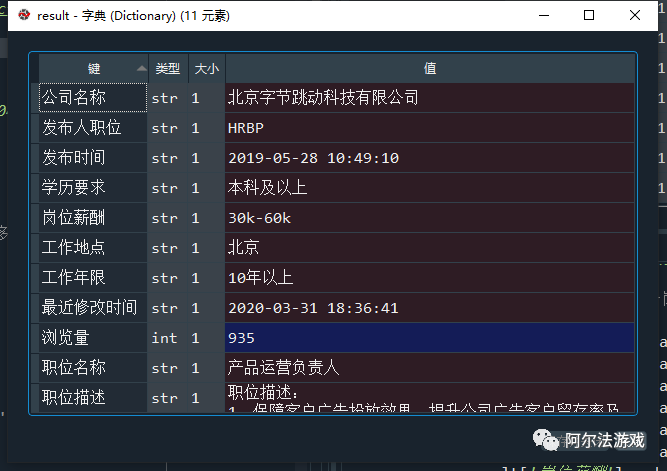
3、实现细节
1)材料准备
将url按照规律进行拆分
#url里count和page是变化的规律所在,自选一个进行循环#因脉脉没有通用的岗位list汇总页面,因此如果想获取其他list可以通过搜索或者查询指定公司职位后修改url即可#url = https://maimai.cn/sdk/company/obtian_company_job?webcid=jYZTTwkX&count=20&page=50&job_title=path = 'https://maimai.cn/sdk/company/obtian_company_job?webcid=jYZTTwkX&count=20&page='tail = '&job_title='#这里需要注意,一定要加cookie,否则将获取不到数据headers = {"User-Agent": UserAgent(verify_ssl=False).random,"Cookie":'填入你自己的浏览器cookie值'}
2)数据请求
请求数据并用json.load()简单进行数据类型转化python对象
#创建空list,用于存储抓取的岗位信息(字典存储)list = []#计数用的变量nn = 0#因单页显示20条岗位信息,所以需要翻页(实际网页效果是下拉加载更多)#数据为json,因此需要json.load 解析for i in range(0,51): #我这里只去前50页数据url = path + str(i) +tailresponse_comment = requests.get(url,headers = headers)json_comment = response_comment.textjson_comment = json.loads(json_comment)
3)数据筛选
接上个for循环,因为每页内有20条数据,因此需要再用一个循环取出每条数据并存入一个空字典中,同时将每个字典合到空列表中进行汇总
data = json_comment['data']#单页显示20条岗位信息,逐一采集for i in range(len(data['normal_data'])):n = n+1#创建空字典用于存储单个岗位信息result = {}result['工作年限'] = data['normal_data'][i]['worktime']result['学历要求'] = data['normal_data'][i]['degree']result['职位描述'] = data['normal_data'][i]['description']result['公司名称'] = data['normal_data'][i]['company']result['工作地点'] = data['normal_data'][i]['city']result['职位名称'] = data['normal_data'][i]['position']result['岗位薪酬'] = data['normal_data'][i]['salary_info']result['最近修改时间'] = data['normal_data'][i]['modify_time']result['发布时间'] = data['normal_data'][i]['pub_time']result['浏览量'] = data['normal_data'][i]['views']result['发布人职位'] = data['normal_data'][i]['user']['position'].upper()#将岗位信息存入list中list.append(result)
4)数据导出
直接使用pandas的to_excel方法导出数据成excel
#将存有岗位信息的列表转化为dataframe表格形式df = pd.DataFrame(list)df.to_excel(r'F:\Python\岗位数据.xlsx',sheet_name='岗位信息',index = 0
5)结果展示
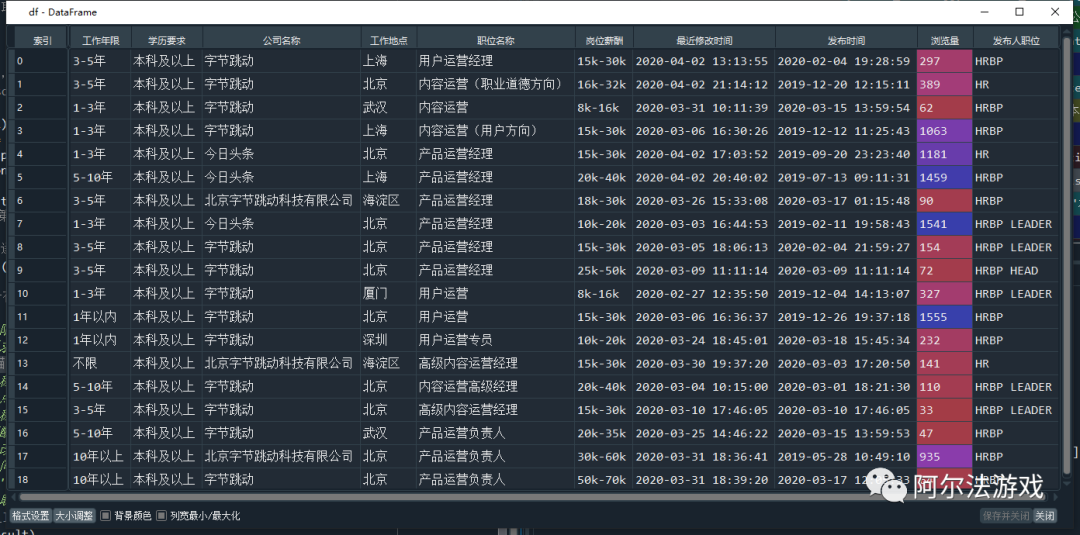
4、完整代码
import requestsfrom fake_useragent import UserAgentimport jsonimport pandas as pdimport timestart_time = time.perf_counter()#url里count和page是变化的规律所在,自选一个进行循环#因脉脉没有通用的岗位list汇总页面,因此如果想获取其他list可以通过搜索或者查询指定公司职位后修改url即可#url = https://maimai.cn/sdk/company/obtian_company_job?webcid=jYZTTwkX&count=20&page=50&job_title=path = 'https://maimai.cn/sdk/company/obtian_company_job?webcid=jYZTTwkX&count=20&page='tail = '&job_title='#这里需要注意,一定要加cookie,否则将获取不到数据headers = {"User-Agent": UserAgent(verify_ssl=False).random,"Cookie":'你的cookie'}#创建空list,用于存储抓取的岗位信息(字典存储)list = []#计数用的变量nn = 0#因单页显示20条岗位信息,所以需要翻页(实际网页效果是下拉加载更多)#数据为json,因此需要json.load 解析for i in range(1,2):url = path + str(i) +tailresponse_comment = requests.get(url,headers = headers)json_comment = response_comment.textjson_comment = json.loads(json_comment)data = json_comment['data']# print('\r正在抓取第%d页岗位信息(每页20个岗位)'%i,end=' ')#单页显示20条岗位信息,逐一采集for i in range(len(data['normal_data'])):n = n+1#创建空字典用于存储单个岗位信息result = {}result['工作年限'] = data['normal_data'][i]['worktime']result['学历要求'] = data['normal_data'][i]['degree']result['职位描述'] = data['normal_data'][i]['description']result['公司名称'] = data['normal_data'][i]['company']result['工作地点'] = data['normal_data'][i]['city']result['职位名称'] = data['normal_data'][i]['position']result['岗位薪酬'] = data['normal_data'][i]['salary_info']result['最近修改时间'] = data['normal_data'][i]['modify_time']result['发布时间'] = data['normal_data'][i]['pub_time']result['浏览量'] = data['normal_data'][i]['views']result['发布人职位'] = data['normal_data'][i]['user']['position'].upper()#将岗位信息存入list中list.append(result)print('\r已整合%d个岗位信息'%n,end=' ')use_time = time.perf_counter()print('\n合计运行时长:{0:.2f} 秒'.format(use_time-start_time))#将存有岗位信息的列表转化为dataframe表格形式df = pd.DataFrame(list)df.to_excel(r'F:\Python\脉脉-字节跳动招聘岗位.xlsx',sheet_name='岗位信息',index = 0)


























一Spring MVC拦截器")
")

")




还没有评论,来说两句吧...