集成学习之Stacking详解
1、Stacking原理
stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。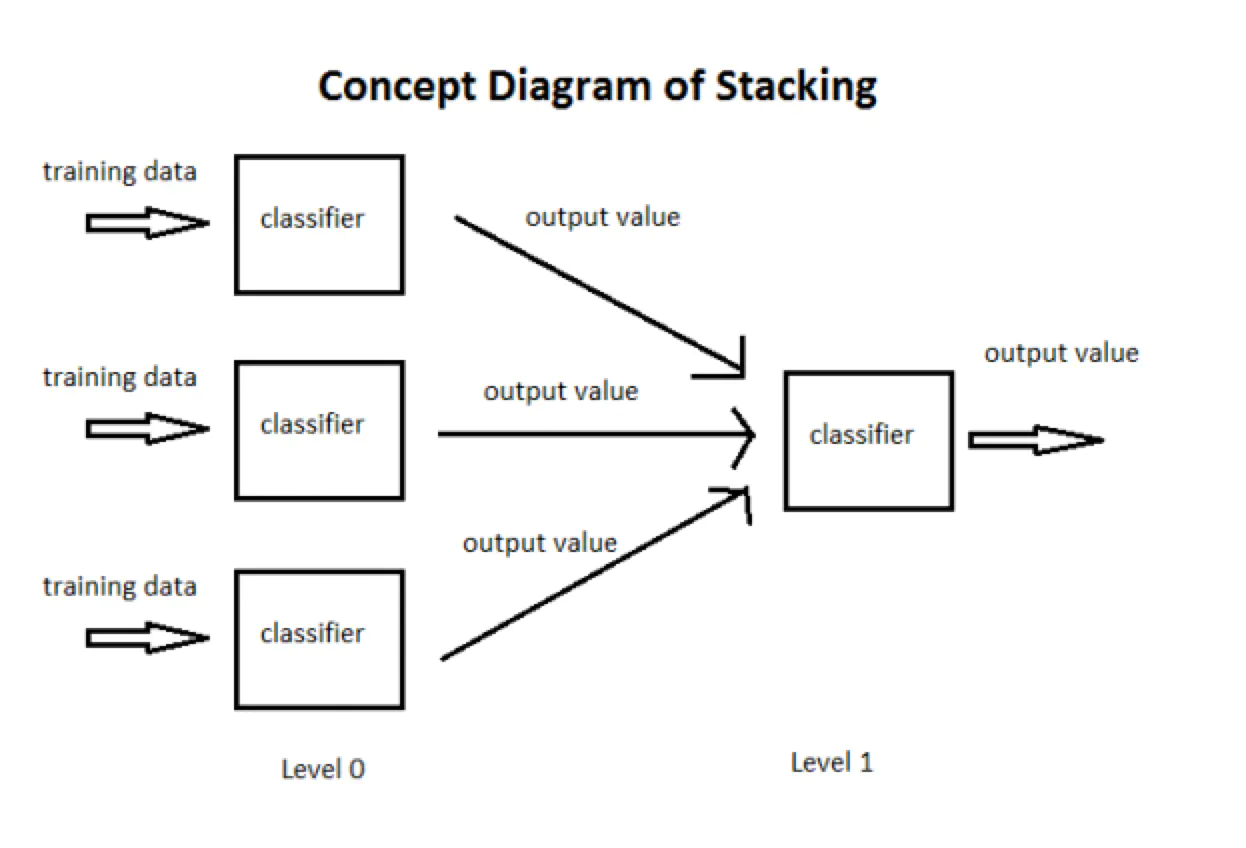
最初的想法是:
1:用数据集D来训练h1,h2,h3…,
2:用这些训练出来的初级学习器在数据集D上面进行预测得到次级训练集。
3:用次级训练集来训练次级学习器。
但是这样的实现是有很大的缺陷的。在原始数据集D上面训练的模型,然后用这些模型再D上面再进行预测得到的次级训练集肯定是非常好的。会出现过拟合的现象。
次级训练集的构成不是直接由模型在训练集D上面预测得到,而是使用交叉验证的方法,将训练集D分为k份,对于每一份,用剩余数据集训练模型,然后预测出这一份的结果。重复上面步骤,直到每一份都预测出来。这样就不会出现上面的过拟合这种情况。并且在构造次级训练集的过程当中,顺便把测试集的次级数据也给构造出来了。
对于我们所有的初级训练器,都要重复上面的步骤,才构造出来最终的次级训练集和次级测试集。
2、Stacking 的基本思想
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。
上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。
在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
我们贴一张周志华老师《机器学习》一张图来说一下stacking学习算法。
过程1-3 是训练出来个体学习器,也就是初级学习器。
过程5-9是 使用训练出来的个体学习器来得预测的结果,这个预测的结果当做次级学习器的训练集。
过程11 是用初级学习器预测的结果训练出次级学习器,得到我们最后训练的模型。
如果想要预测一个数据的输出,只需要把这条数据用初级学习器预测,然后将预测后的结果用次级学习器预测便可。
3、Stacking分类应用
这里我们用二分类的例子做介绍。
例如我们用 RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier 作为第一层学习器(当然这里我们可以添加更多的分类器,也可以用不同的特征组合但是同样的学习方法作为基分类器):
clfs = [RandomForestClassifier(n_estimators = n_trees, criterion = 'gini'),ExtraTreesClassifier(n_estimators = n_trees * 2, criterion = 'gini'),GradientBoostingClassifier(n_estimators = n_trees),]
接着要训练第一层学习器,并得到第二层学习器所需要的数据,这里会用到 k 折交叉验证。我们首先会将数据集进行一个划分,比如使用80%的训练数据来训练,20%的数据用来测试。
dev_cutoff = len(Y) * 4/5X_dev = X[:dev_cutoff]Y_dev = Y[:dev_cutoff]X_test = X[dev_cutoff:]Y_test = Y[dev_cutoff:]
然后对训练数据通过交叉验证训练 clf,并得到第二层的训练数据 blend_train,同时,在每个基分类器的每一折交叉验证中,我们都会对测试数据进行一次预测,以得到我们blend_test,二者的定义如下:
blend_train = np.zeros((X_dev.shape[0], len(clfs))) # Number of training data x Number of classifiersblend_test = np.zeros((X_test.shape[0], len(clfs))) # Number of testing data x Number of classifiers
按照上面说的,blend_train基于下面的方法得到,注意,下图是对于一个分类器来说的,所以每个分类器得到的blend_train的行数与用于训练的数据一样多,所以blend_train的shape为X_dev.shape[0]*len(clfs),即训练集长度 * 基分类器个数:
而对于第二轮的测试集blend_test来说,由于每次交叉验证的过程中都要进行一次预测,假设我们是5折交叉验证,那么对于每个分类器来说,得到的blend_test的shape是测试集行数 * 交叉验证折数,此时的做法是,对axis=1方向取平均值,以得到测试集行数 * 1 的测试数据,所以总的blend_test就是测试集行数 * 基分类器个数,可以跟blend_train保持一致:

得到blend_train 和 blend_test的代码如下:
for j, clf in enumerate(clfs):print 'Training classifier [%s]' % (j)blend_test_j = np.zeros((X_test.shape[0], len(skf))) # Number of testing data x Number of folds , we will take the mean of the predictions laterfor i, (train_index, cv_index) in enumerate(skf):print 'Fold [%s]' % (i)# This is the training and validation setX_train = X_dev[train_index]Y_train = Y_dev[train_index]X_cv = X_dev[cv_index]Y_cv = Y_dev[cv_index]clf.fit(X_train, Y_train)# This output will be the basis for our blended classifier to train against,# which is also the output of our classifiersblend_train[cv_index, j] = clf.predict(X_cv)blend_test_j[:, i] = clf.predict(X_test)# Take the mean of the predictions of the cross validation setblend_test[:, j] = blend_test_j.mean(1)
接着我们就可以用 blend_train, Y_dev 去训练第二层的学习器 LogisticRegression(当然也可以是别的分类器,比如lightGBM,XGBoost):
bclf = LogisticRegression()bclf.fit(blend_train, Y_dev)
最后,基于我们训练的二级分类器,我们可以预测测试集 blend_test,并得到 score:
Y_test_predict = bclf.predict(blend_test)score = metrics.accuracy_score(Y_test, Y_test_predict)print 'Accuracy = %s' % (score)
如果是多分类怎么办呢,我们这里就不能用predict方法啦,我么要用的是predict_proba方法,得到基分类器对每个类的预测概率代入二级分类器中训练,修改的部分代码如下:
blend_train = np.zeros((np.array(X_dev.values.tolist()).shape[0], num_classes*len(clfs)),dtype=np.float32) # Number of training data x Number of classifiersblend_test = np.zeros((np.array(X_test.values.tolist()).shape[0], num_classes*len(clfs)),dtype=np.float32) # Number of testing data x Number of classifiers# For each classifier, we train the number of fold times (=len(skf))for j, clf in enumerate(clfs):for i, (train_index, cv_index) in enumerate(skf):print('Fold [%s]' % (i))# This is the training and validation setX_train = X_dev[train_index]Y_train = Y_dev[train_index]X_cv = X_dev[cv_index]X_train = np.concatenate((X_train, ret_x),axis=0)Y_train = np.concatenate((Y_train, ret_y),axis=0)clf.fit(X_train, Y_train)blend_train[cv_index, j*num_classes:(j+1)*num_classes] = clf.predict_proba(X_cv)blend_test[:, j*num_classes:(j+1)*num_classes] += clf.predict_proba(X_test)blend_test = blend_test / float(n_folds)
上面的代码修改的主要就是blend_train和blend_test的shape,可以看到,对于多分类问题来说,二者的第二维的shape不再是基分类器的数量,而是class的数量*基分类器的数量,这是大家要注意的,否则可能不会得到我们想要的结果。
构造stacking方法
我们写一个stacking方法,下面是它的实现代码:
import numpy as npfrom sklearn.model_selection import KFolddef get_stacking(clf, x_train, y_train, x_test, n_folds=10):"""这个函数是stacking的核心,使用交叉验证的方法得到次级训练集x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .如果输入为pandas的DataFrame类型则会把报错"""train_num, test_num = x_train.shape[0], x_test.shape[0]second_level_train_set = np.zeros((train_num,))second_level_test_set = np.zeros((test_num,))test_nfolds_sets = np.zeros((test_num, n_folds))kf = KFold(n_splits=n_folds)for i,(train_index, test_index) in enumerate(kf.split(x_train)):x_tra, y_tra = x_train[train_index], y_train[train_index]x_tst, y_tst = x_train[test_index], y_train[test_index]clf.fit(x_tra, y_tra)second_level_train_set[test_index] = clf.predict(x_tst)test_nfolds_sets[:,i] = clf.predict(x_test)second_level_test_set[:] = test_nfolds_sets.mean(axis=1)return second_level_train_set, second_level_test_set#我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,GradientBoostingClassifier, ExtraTreesClassifier)from sklearn.svm import SVCrf_model = RandomForestClassifier()adb_model = AdaBoostClassifier()gdbc_model = GradientBoostingClassifier()et_model = ExtraTreesClassifier()svc_model = SVC()#在这里我们使用train_test_split来人为的制造一些数据from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitiris = load_iris()train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2)train_sets = []test_sets = []for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:train_set, test_set = get_stacking(clf, train_x, train_y, test_x)train_sets.append(train_set)test_sets.append(test_set)meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1)#使用决策树作为我们的次级分类器from sklearn.tree import DecisionTreeClassifierdt_model = DecisionTreeClassifier()dt_model.fit(meta_train, train_y)df_predict = dt_model.predict(meta_test)print(df_predict)输出结果如下(因为是随机划分的,所以每次运行结果可能不一样):[1 0 1 1 1 2 1 2 2 2 0 0 1 2 2 1 0 2 1 0 0 1 1 0 0 2 0 2 1 2]
构造stacking类
事实上还可以构造一个stacking的类,它拥有fit和predict方法
from sklearn.model_selection import KFoldfrom sklearn.base import BaseEstimator, RegressorMixin, TransformerMixin, cloneimport numpy as np#对于分类问题可以使用 ClassifierMixinclass StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):def __init__(self, base_models, meta_model, n_folds=5):self.base_models = base_modelsself.meta_model = meta_modelself.n_folds = n_folds# 我们将原来的模型clone出来,并且进行实现fit功能def fit(self, X, y):self.base_models_ = [list() for x in self.base_models]self.meta_model_ = clone(self.meta_model)kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)#对于每个模型,使用交叉验证的方法来训练初级学习器,并且得到次级训练集out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))for i, model in enumerate(self.base_models):for train_index, holdout_index in kfold.split(X, y):self.base_models_[i].append(instance)instance = clone(model)instance.fit(X[train_index], y[train_index])y_pred = instance.predict(X[holdout_index])out_of_fold_predictions[holdout_index, i] = y_pred# 使用次级训练集来训练次级学习器self.meta_model_.fit(out_of_fold_predictions, y)return self#在上面的fit方法当中,我们已经将我们训练出来的初级学习器和次级学习器保存下来了#predict的时候只需要用这些学习器构造我们的次级预测数据集并且进行预测就可以了def predict(self, X):meta_features = np.column_stack([np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)for base_models in self.base_models_ ])return self.meta_model_.predict(meta_features)




























")

")



还没有评论,来说两句吧...