Hadoop-分布式文件系统HDFS
文章目录
- HDFS的shell命令
- HDFS的架构
- 例子:上传一个文件的过程
- NameNode如何管理元数据
- NameNode的职责
- DataNode的工作原理
HDFS的shell命令
既然是一个文件系统,它有对文件的基本操作(类似linux里面的cp、mv、ls等)
调用方式:把hadoop里面的bin添加到环境变量,以下一些操作hadoop3可以直接通过web页面操作
hadoop fs -ls / #查看HDFS的根目录hadoop fs -mkdir /test #在根目录下建立test文件夹hadoop fs -put ./xx #上传hadoop fs -get /test/test.txt #下载hadoop fs -appendToFile xxlocal.txt /test/text.txt #将xxlocal.txt里面内容追加到hdfs/test/text.txt中hadoop fs -moveFromLocal xxlocal.txt /test #将xxlocal.txt移动到hdfs上,本地没有了hadoop fs -du -s -h /test #统计文件夹的大小(包含所有副本),去掉-s 查看文件夹内部细节的大小hadoop fs -setrep 10 /test/xx.txt #设置文件为10个副本(前提是至少有10个节点),否则实际存储还是节点的数量。。。
HDFS的架构
- NameNode
- DataNode
- Secondary NameNode
例子:上传一个文件的过程
- 客户端请求上传一个文件(请求NameNode)
- NameNode会分配哪几个DataNode给客户端,NameNode里面记录元数据(文件分成几个block,每个block在那个DataNode上)
- 客户端将文件上传到DataNode上
(1)上传block1,上传完了之后到block2,再到block3,如果完成了,接下来的过程跟客户端无关了
(2)同时当block1上传完之后,由block1上传副本到另一个DataNode,再由副本上传另一个副本到另一个DataNode
(3)如果第三个副本由第二个传输的时候失败了,第二个响应第一个,第一个响应NameNode,NameNode知道第三个副本上传失败,会重新再分配一个DataNode,由第一或者第二个中任意一个再去上传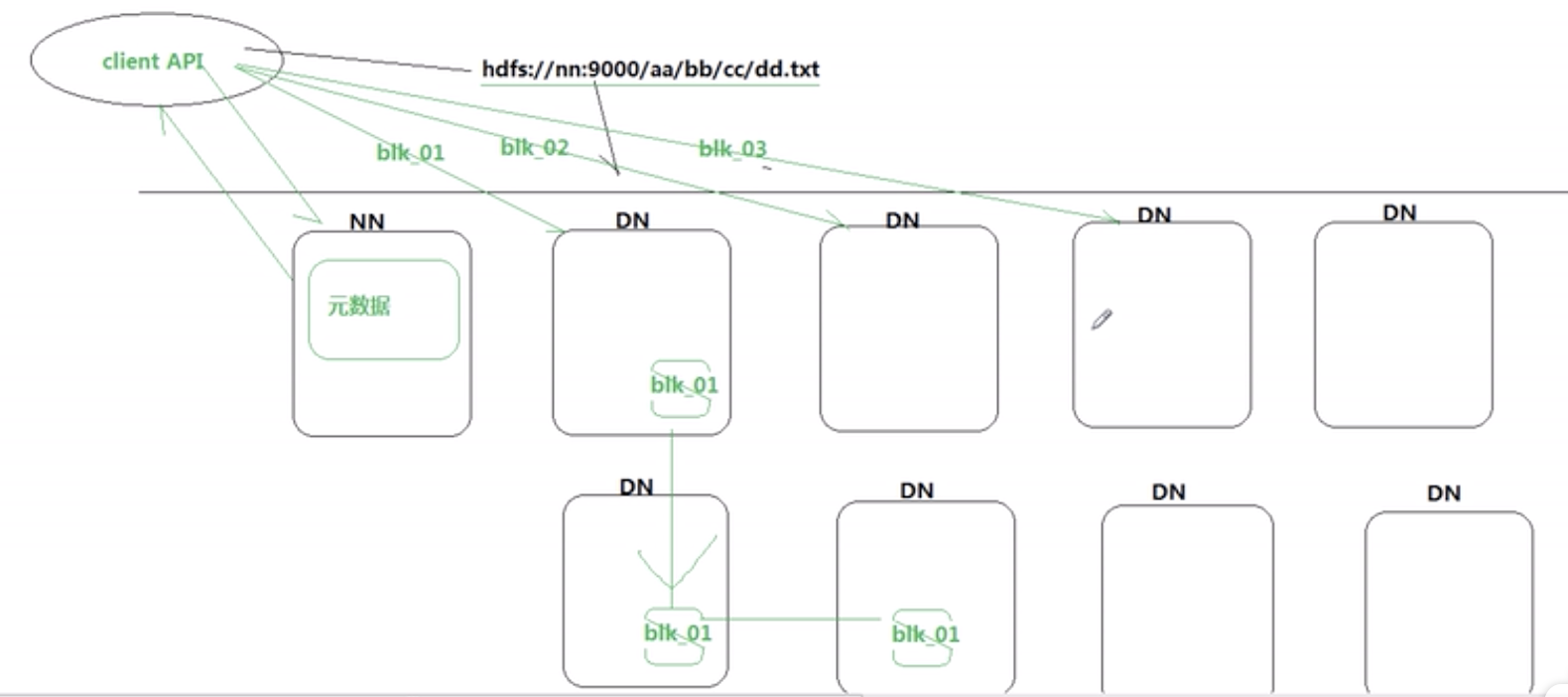
NameNode如何管理元数据
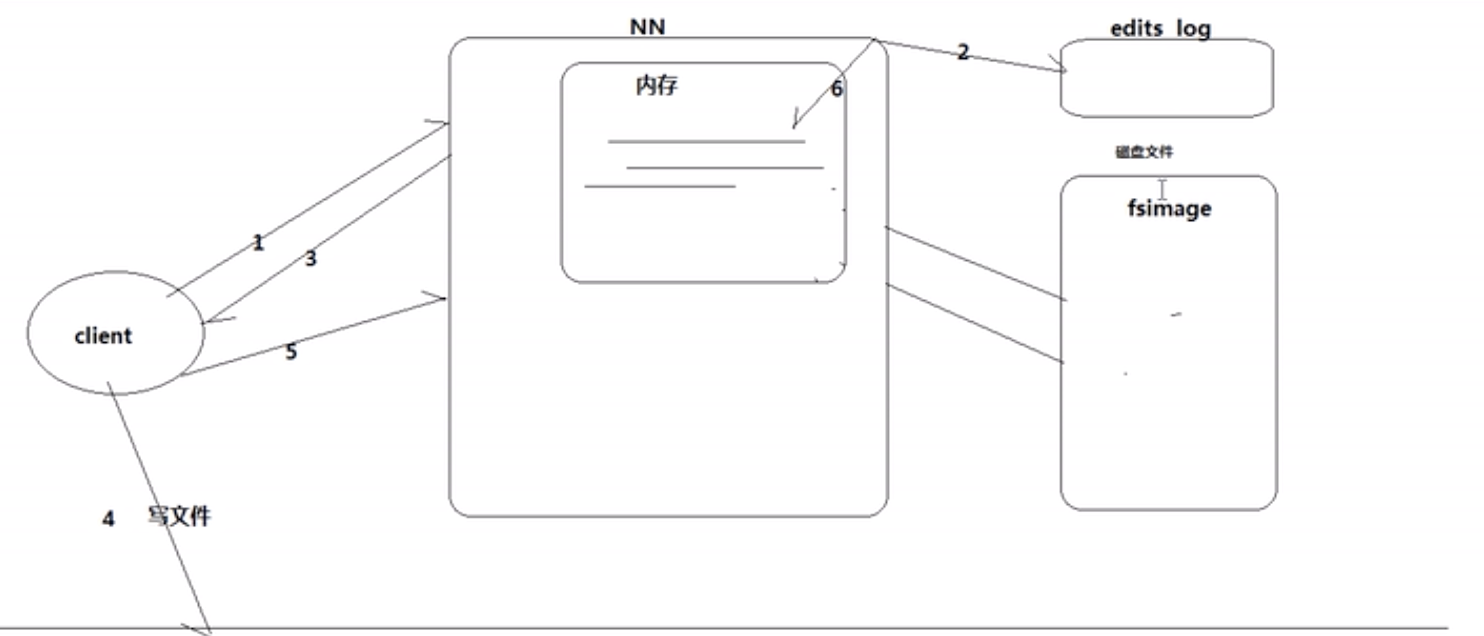
- 客户端请求写数据,NN(NameNode)会分配DataNode,这些数据会先在edits_log(很小,做缓存用)里面保存为日志
- 当客户端写完之后,给NN响应,NN将日志以元数据的形式读到内存里(方便查询速度、实时响应多个客户端)
- 等到edits_log满了之后,它会和fsimage(存在硬盘的元数据,和内存中是同步的)进行合并,需要借助Secondary NameNode(因为这个过程需要将log数据转到元数据的格式,需要计算时间),合并过程如下:
注释:Checkpoint:合并操作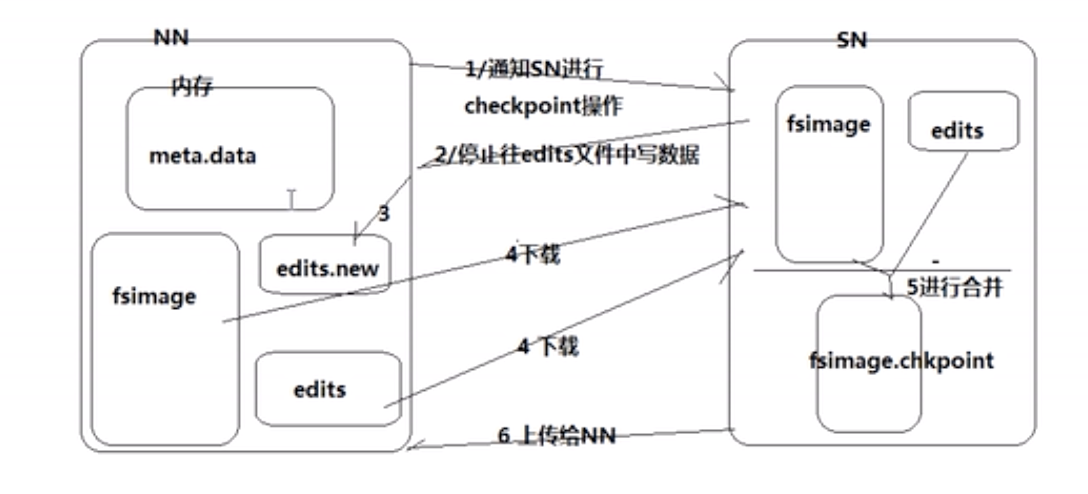
- 元数据的存储格式

- /test/a.log : HDFS的虚拟路径
- 3 :副本数
- {blk_1, blk_2}:几个block
- [{blk_1:[h0,h1,h3]}]:blk_1三个副本在哪几个DataNode主机上(h0,h1,h3)
NameNode的职责
- 管理元数据
- 维护HDFS的目录
- 响应客户端的请求
DataNode的工作原理


























")


还没有评论,来说两句吧...