mysqlmvcc解决幻读
求数据库大神,mysql事务隔离级别repeatable-read 详解
术式之后皆为逻辑,一切皆为需求和实现。希望此文能从需求、现状和解决方式的角度帮大家理解隔离级别。
隔离级别的产生
在串型执行的条件下,数据修改的顺序是固定的、可预期的结果,但是并发执行的情况下,数据的修改是不可预期的,也不固定,为了实现数据修改在并发执行的情况下得到一个固定、可预期的结果,由此产生了隔离级别。
所以隔离级别的作用是用来平衡数据库并发访问与数据一致性的方法。
事务的4种隔离级别
READUNCOMMITTED未提交读,可以读取未提交的数据。READCOMMITTED已提交读,对于锁定读(selectwithforupdate或者forshare)、update和delete语句,InnoDB仅锁定索引记录,而不锁定它们之间的间隙,因此允许在锁定的记录旁边自由插入新记录。Gaplocking仅用于外键约束检查和重复键检查。REPEATABLEREAD可重复读,事务中的一致性读取读取的是事务第一次读取所建立的快照。SERIALIZABLE序列化
在了解了4种隔离级别的需求后,在采用锁控制隔离级别的基础上,我们需要了解加锁的对象(数据本身&间隙),以及了解整个数据范围的全集组成。
数据范围全集组成
SQL语句根据条件判断不需要扫描的数据范围(不加锁);
SQL语句根据条件扫描到的可能需要加锁的数据范围;
以单个数据范围为例,数据范围全集包含:(数据范围不一定是连续的值,也可能是间隔的值组成)
1.数据已经填充了整个数据范围:(被完全填充的数据范围,不存在数据间隙)
整形,对值具有唯一约束条件的数据范围1~5,
已有数据1、2、3、4、5,此时数据范围已被完全填充;
整形,对值具有唯一约束条件的数据范围1和5,
已有数据1、5,此时数据范围已被完全填充;
2.数据填充了部分数据范围:(未被完全填充的数据范围,是存在数据间隙)
整形的数据范围1~5,
已有数据1、2、3、4、5,但是因为没有唯一约束,
所以数据范围可以继续被1~5的数据重复填充;
整形,具有唯一约束条件的数据范围1~5,
已有数据2,5,此时数据范围未被完全填充,还可以填充1、3、4;
3.数据范围内没有任何数据(存在间隙)
整形的数据范围1~5,数据范围内当前没有任何数据。
在了解了数据全集的组成后,我们再来看看事务并发时,会带来的问题。
无控制的并发所带来的问题
并发事务如果不加以控制的话会带来一些问题,主要包括以下几种情况。
1.范围内已有数据更改导致的:
更新丢失:当多个事务选择了同一行,然后基于最初选定的值更新该行时,
由于每个事物不知道其他事务的存在,最后的更新就会覆盖其他事务所做的更新;
脏读:一个事务正在对一条记录做修改,这个事务完成并提交前,这条记录就处于不一致状态。
这时,另外一个事务也来读取同一条记录,如果不加控制,
第二个事务读取了这些“脏”数据,并据此做了进一步的处理,就会产生提交的数据依赖关系。
这种现象就叫“脏读”。
2.范围内数据量发生了变化导致:
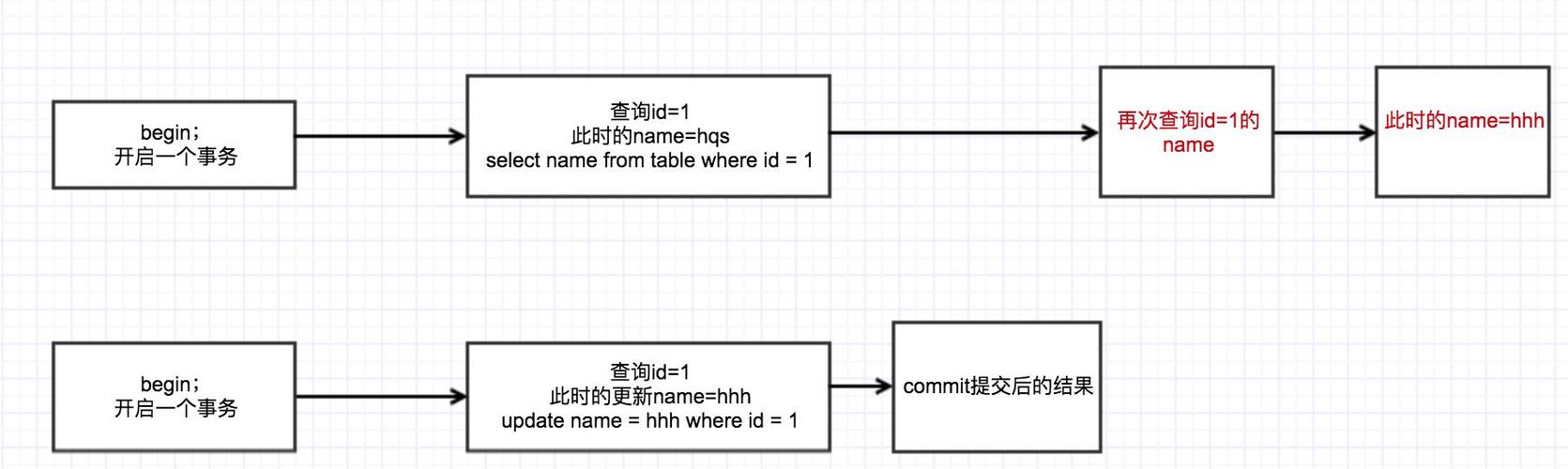
不可重复读:一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,
却发现其读出的数据已经发生了改变,或者某些记录已经被删除了。
这种现象就叫“不可重复读”。
幻读:一个事务按相同的查询条件重新读取以前检索过的数据,
却发现其他事务插入了满足其查询条件的新数据,这种现象称为“幻读”。
可以简单的认为满足条件的数据量变化了。
因为无控制的并发会带来一系列的问题,这些问题会导致无法满足我们所需要的结果。因此我们需要控制并发,以实现我们所期望的结果(隔离级别)。
MySQL隔离级别的实现
InnoDB通过加锁的策略来支持这些隔离级别。
行锁包含:
RecordLocks
索引记录锁,索引记录锁始终锁定索引记录,即使表中未定义索引,
这种情况下,InnoDB创建一个隐藏的聚簇索引,并使用该索引进行记录锁定。
GapLocks
间隙锁是索引记录之间的间隙上的锁,或者对第一条记录之前或者最后一条记录之后的锁。
间隙锁是性能和并发之间权衡的一部分。
对于无间隙的数据范围不需要间隙锁,因为没有间隙。
Next-KeyLocks
索引记录上的记录锁和索引记录之前的gaplock的组合。
假设索引包含10、11、13和20。
可能的next-keylocks包括以下间隔,其中圆括号表示不包含间隔端点,方括号表示包含端点:
(负无穷大,10](10,11](11,13](13,20](20,正无穷大)对于最后一个间隔,next-key将会锁定索引中最大值的上方,
左右滑动进行查看
“上确界”伪记录的值高于索引中任何实际值。
上确界不是一个真正的索引记录,因此,实际上,这个next-key只锁定最大索引值之后的间隙。
基于此,当获取的数据范围中,数据已填充了所有的数据范围,那么此时是不存在间隙的,也就不需要gaplock。
对于数据范围内存在间隙的,需要根据隔离级别确认是否对间隙加锁。
默认的REPEATABLEREAD隔离级别,为了保证可重复读,除了对数据本身加锁以外,还需要对数据间隙加锁。
READCOMMITTED已提交读,不匹配行的记录锁在MySQL评估了where条件后释放。
对于update语句,InnoDB执行”semi-consistent”读取,这样它会将最新提交的版本返回到MySQL,
以便MySQL可以确定该行是否与update的where条件相匹配。
总结&延展:
唯一索引存在唯一约束,所以变更后的数据若违反了唯一约束的原则,则会失败。
当where条件使用二级索引筛选数据时,会对二级索引命中的条目和对应的聚簇索引都加锁;所以其他事务变更命中加锁的聚簇索引时,都会等待锁。
行锁的增加是一行一行增加的,所以可能导致并发情况下死锁的发生。
在sessionA对符合条件的某聚簇索引加锁时,可能sessionB已持有该聚簇索引的RecordLocks,而sessionB正在等待sessionA已持有的某聚簇索引的RecordLocks。
sessionA和sessionB是通过两个不相干的二级索引定位到的聚簇索引。
sessionA通过索引idA,sessionB通过索引idB。
当where条件获取的数据无间隙时,无论隔离级别为rc或rr,都不会存在间隙锁。
比如通过唯一索引获取到了已完全填充的数据范围,此时不需要间隙锁。
间隙锁的目的在于阻止数据插入间隙,所以无论是通过insert或update变更导致的间隙内数据的存在,都会被阻止。
rc隔离级别模式下,查询和索引扫描将禁用gaplocking,此时gaplocking仅用于外键约束检查和重复键检查(主要是唯一性检查)。
rr模式下,为了防止幻读,会加上GapLocks。
事务中,SQL开始则加锁,事务结束才释放锁。
就锁类型而言,应该有优化锁,锁升级等,例如rr模式未使用索引查询的情况下,是否可以直接升级为表锁。
就锁的应用场景而言,在回放场景中,如果确定事务可并发,则可以考虑不加锁,加快回放速度。
锁只是并发控制的一种粒度,只是一个很小的部分:
从不同场景下是否需要控制并发,(已知无交集且有序的数据的变更,MySQL的MTS相同前置事务的多事务并发回放)
并发控制的粒度,(锁是一种逻辑粒度,可能还存在物理层和其他逻辑粒度或方式)
相同粒度下的优化,(锁本身存在优化,如IX、IS类型的优化锁)
粒度加载的安全&性能(如获取行锁前,先获取页锁,页锁在执行获取行锁操作后即释放,无论是否获取成功)等多个层次去思考并发这玩意。

mysql中的next key与mvcc有何不同?各自的应用体现在哪
理想的MVCC是可以解决幻读的,但是innodb真正实现起来的并不是理想中的MVCC。innodb真正解决幻读的还是靠的是nextkeylock,因为innodb的写操作其实排他锁操作,所以用实际实现的MVCC解决读并发问题。
本回答由网友推荐
化工原理化工原理化工原理
化工分为合成和分离,对应形成反应单元和分离单元。反应单元通常俩种,化学反应单元和生化反应单元;常见分离单元如常见的精馏、吸附、蒸发、吸附、萃取、净取、筛分。国内的化工原理应该叫做单元操作 基础传热学 基础流体力学。希望我的回答对你有所帮助

二维码的原理可以从哪些原理来讲述?
[3]二维码的原理可以从矩阵式二维码的原理和行列式二维码的原理来讲述
mysql中explain执行结果中的rows究竟是怎么个统计原理
mysql中explain执行结果中的rows究竟是怎么个统计原理
r这里的rows表示的是mysql执行过程中处理的条数。
根据图中显示:三个条件比两个条件的执行过程处理的条数更多了,其原因应该是由于mysql执行条件的顺序造成的,新引入的条件列c被作为第一优先执行,而这个条件的执行影响到的rows数量超过了条件列a或列b。
第一次执行,条件只有a和b时,mysql执行顺序是a或b中优先级高的,假设为b,那么此时rows的数值就是执行b所涉及到的条数。
第二次执行,条件为a,b和c,根据执行结果,mysql执行顺序发生了变化,先执行c了,那么此时rows的数值就变成了执行c所涉及的条数。而不巧的是条件c涉及的rows比b的多,结果导致条件增加时,处理的条数也增加了。mysql中explain执行结果中的rows究竟是怎么个统计原理
r这里的rows表示的是mysql执行过程中处理的条数。
根据图中显示:三个条件比两个条件的执行过程处理的条数更多了,其原因应该是由于mysql执行条件的顺序造成的,新引入的条件列c被作为第一优先执行,而这个条件的执行影响到的rows数量超过了条件列a或列b。
第一次执行,条件只有a和b时,mysql执行顺序是a或b中优先级高的,假设为b,那么此时rows的数值就是执行b所涉及到的条数。
mysql读写分离原理是什么?要如何操作?
在老版本的MySQL 3.22中,MySQL的单表限大小为4GB,当时的MySQL的存储引擎还是ISAM存储引擎。但是,当出现MyISAM存储引擎之后,也就是从MySQL 3.23开始,MySQL单表最大限制就已经扩大到了64PB了(官方文档显示)。也就是说,从目前的技术环境来看,MySQL数据库的MyISAM存储 引擎单表大小限制已经不是有MySQL数据库本身来决定,而是由所在主机的OS上面的文件系统来决定了。
而MySQL另外一个最流行的存储引擎之一Innodb存储数据的策略是分为两种的,一种是共享表空间存储方式,还有一种是独享表空间存储方式。
当使用共享表空间存储方式的时候,Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所 以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单 表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
而当使用独享表空间来存放Innodb的表的时候,每个表的数据以一个单独的文件来存放,这个时候的单表限制,又变成文件系统的大小限制了。slave从服务器(ubuntu)
(1)找到mysql安装文件夹修改my.cnf文件,vim my.cnf
(2) ./support-files/myql.server restart 重启mysql服务 , ./bin/mysql 进入mysql命令窗口
(3)连接master
change master to master_host=’192.168.0.104’, //master 服务器ip
master_port=3306,
master_user=’repl’,
master_password=’mysql’,
master_log_file=’master-bin.000001’,//master服务器产生的日志
master_log_pos=0;
(4)启动slave
start slave;要了解mysql读写分离,首先要了解MySQL-Proxy。
MySQL-Proxy是处在你的MySQL数据库客户和服务端之间的程序,这个代理可以用来分析、监控和变换(transform)通信数据,它支持非常广泛的使用场景:
(1)负载平衡和故障转移处理
(2)查询分析和日志
(3)SQL宏(SQL macros)
(4)查询重写(query rewriting)
(5)执行shell命令
MySQL Proxy更强大的一项功能是实现“读写分离(Read/Write Splitting)”。基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。
MySQL读写分离
数据库Master主服务器:192.168.10.130
数据库Slave从服务器:192.168.10.131
内容太多。。。。请楼主自行到该文章中查看吧,百度搜索“急速蚂蚁”或者“jisumayi.com”即可


























")

:设计循环双端队列")





还没有评论,来说两句吧...