Java Virtual Machine(一)
目录
- 概述
- 内存结构
- 程序计数器
- 虚拟机栈
- 概述
- 线程诊断
- 本地方法栈
- 堆
- 概述
- 堆内存诊断
- 方法区
- 运行时常量池
- String Table
- 直接内存
- 垃圾回收
- 判断对象可以被回收的算法
- 引用计数法
- 可达性分析算法
- 五种常见引用类型
- 简介及其回收机制
- 代码演示
- 垃圾回收算法
- 标记清除算法
- 标记整理算法
- 复制算法
- 对比
- 分代回收
- 分代回收小结
- VM Options
- 演示垃圾回收
- 垃圾回收器
- 回收器分类
- G1
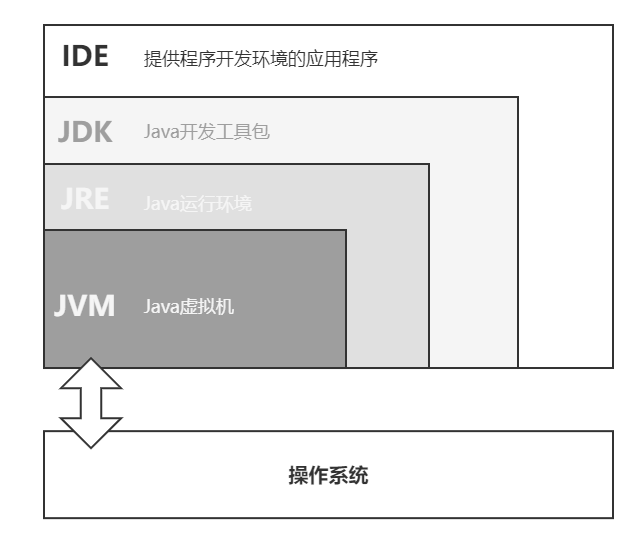
1. 概述
JVM: java程序运行环境(字节码运行环境)。
好处:
- 一处编译、到处运行
- 自动内存管理,垃圾回收机制(GC)
- …
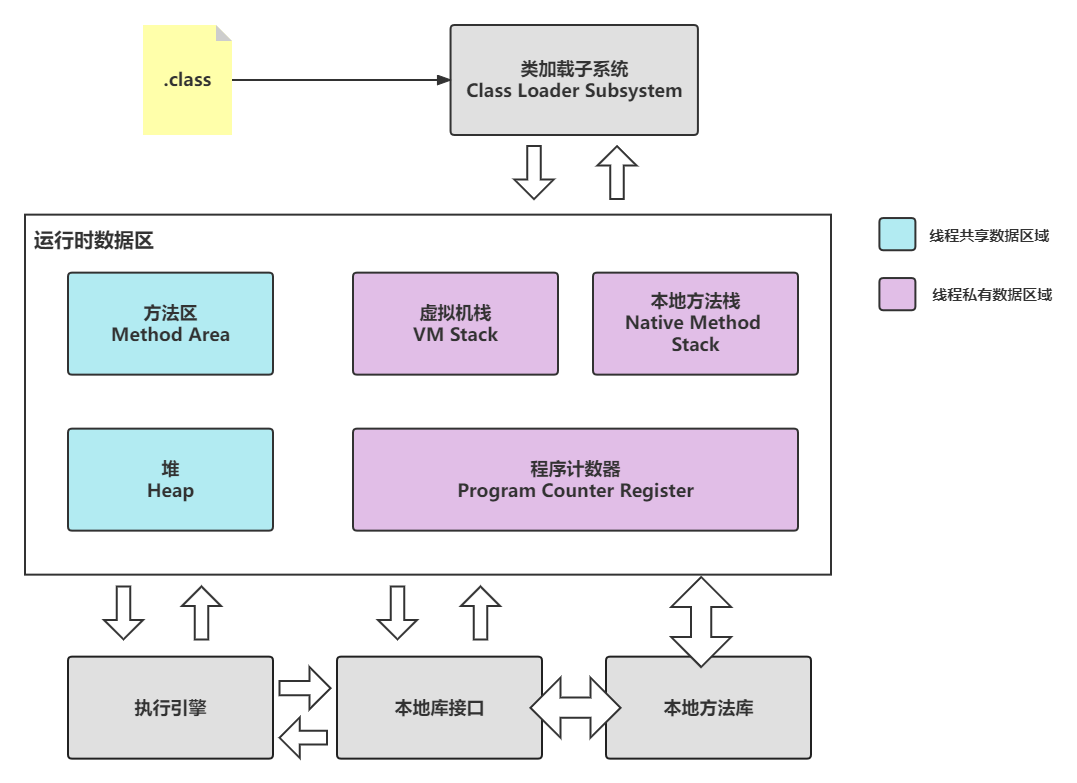
2. 内存结构
1. 程序计数器
先看一段简单程序及其字节码:javap -c Demo1.class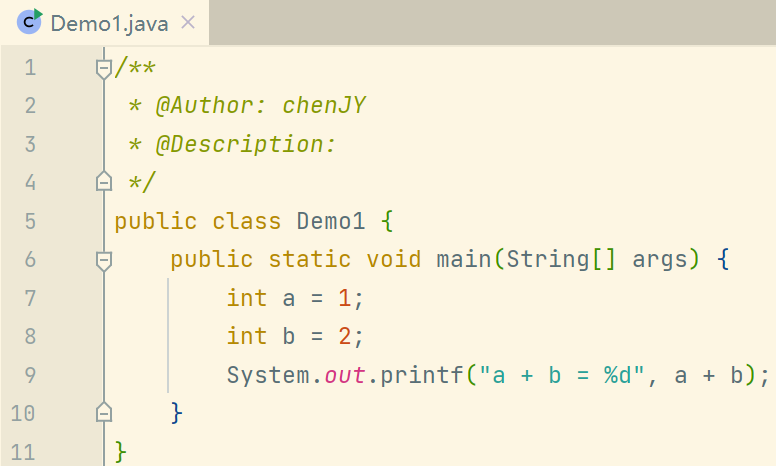

java代码执行流程: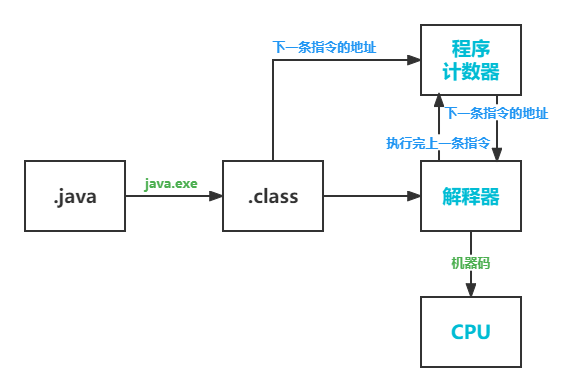
程序计数器:
作用: 记住下一条jvm指令的地址。
- 二进制字节码前面的数字是下一条指令的地址
- 物理实现:寄存器(速度很快)
特点:
- 线程私有
- 不会存在内存溢出
2. 虚拟机栈
1. 概述
栈: 先进后出的数据结构。
虚拟机栈: 线程运行时的内存空间。
- 一个栈由多个栈帧组成,一个栈帧就对应一个方法的调用所占用的内存
- 每个线程只有一个活动栈帧,对应着当前执行的那个方法
- 栈帧内存在每一次方法执行完之后都会弹出栈内存
栈内存溢出原因(StackOverflowError):
- 栈帧过多(如,不断递归调用)
- 栈内存过大
VM options设置栈内存大小:-Xss256k 设置每个线程的栈大小。
- jdk5之前,每个栈的大小是 256k,之后是 1M
- 相同物理内存下,减小此值可生成更多线程,但操作系统对于一个进程的线程数是由限制的
- 超出线程数限制,就会报错
StackOverflowError
2. 线程诊断
Linux查看线程占用:
top查看进程内存、CPU占用(定位进程)ps H -eo pid,tid,%cpu | grep xxxxx查看线程对CPU的占用(定位线程)- H 打印所有进程和线程
-eo 规定要输出的内容
- pid,tid,%cpu pid,tid和CPU占用
- grep 过滤进程的条件
jstack 进程id列出进程中的所有线程(根据线程id—tid的十六进制数去找到目标线程)
排除线程死锁: 迟迟得不到结果。
jstack 进程id会打印出死锁死锁所在范围
Find one Java-level deadlock
Java stack information for the threads listed above
3. 本地方法栈
本地方法栈: JVM在调用本地方法的时候需要的内存空间。
- 本地方法:不是由Java代码编写的,可以直接与操作系统底层打交道的API(如,Object的clone()、hashCode()、notify()、wait())
4. 堆
1. 概述
堆: 通过 new ,创建对象都会使用堆内存。
特点:
- 线程共享,线程安全问题
- 垃圾回收机制
VM options设置堆内存大小:
-Xmx8m设置JVM最大堆内存为8M
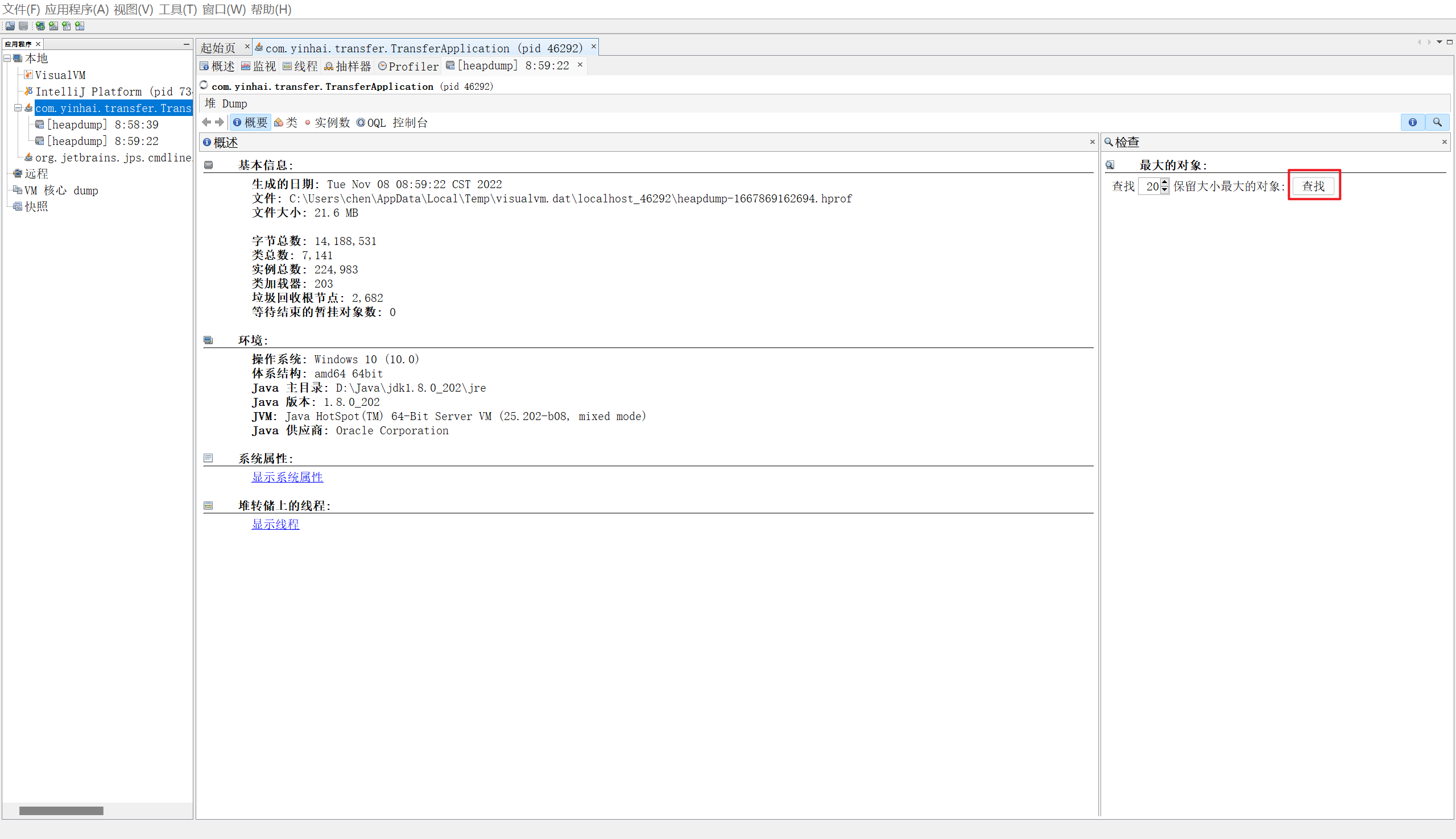
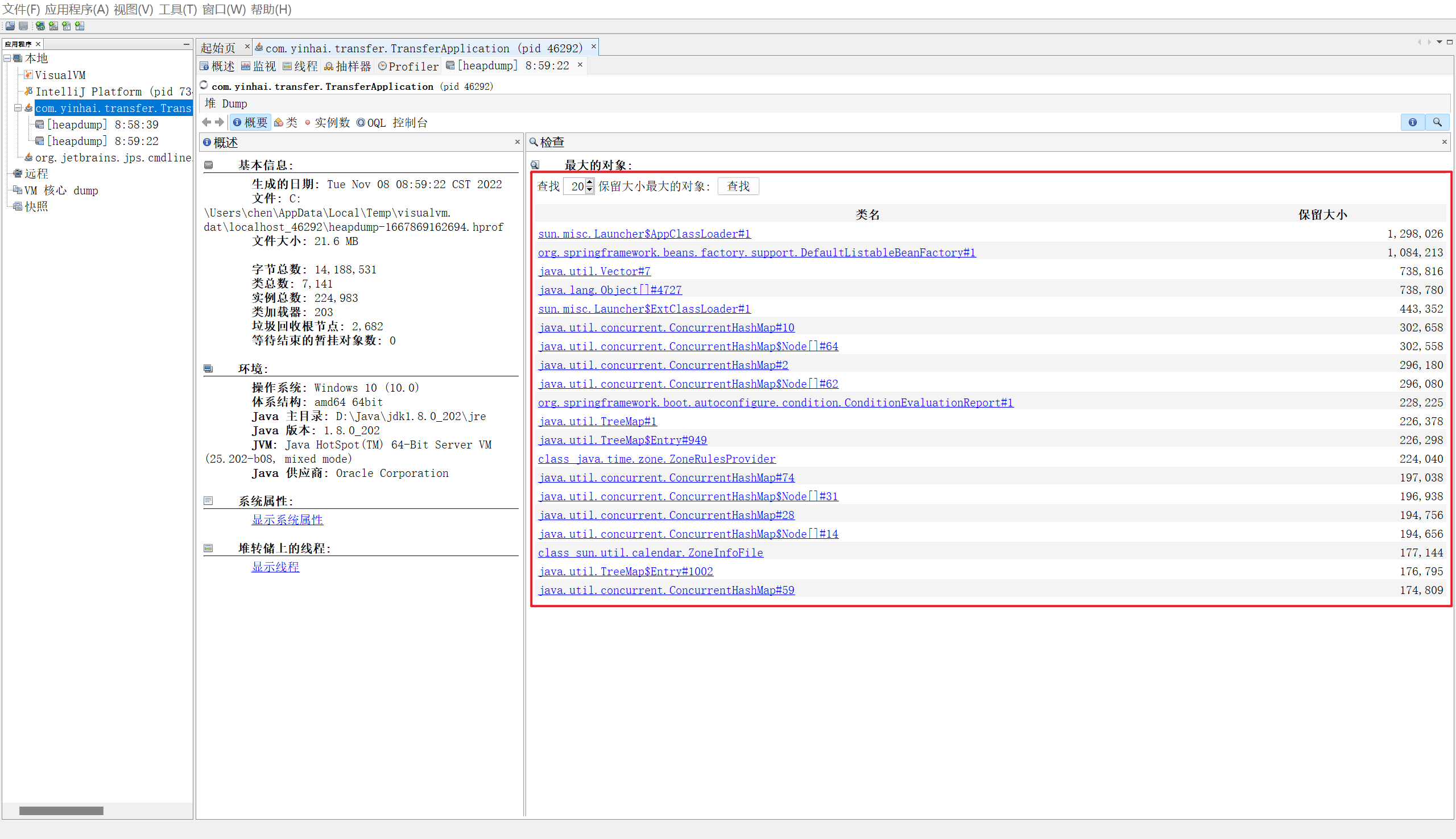
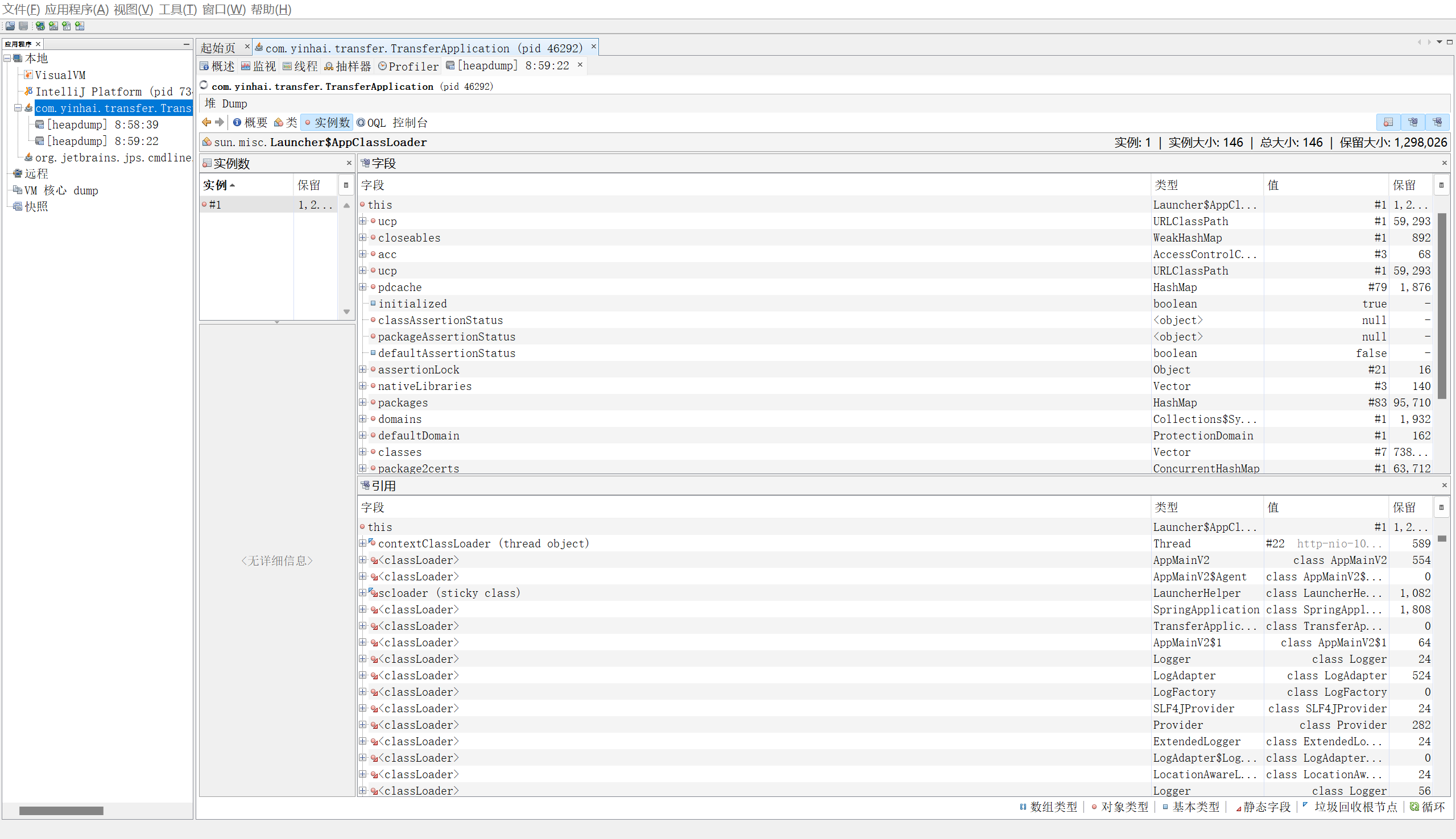
2. 堆内存诊断
jps 查看有哪些java进程(显示:进程id 进程名)
jmap -heap pid 查看堆内存占用情况
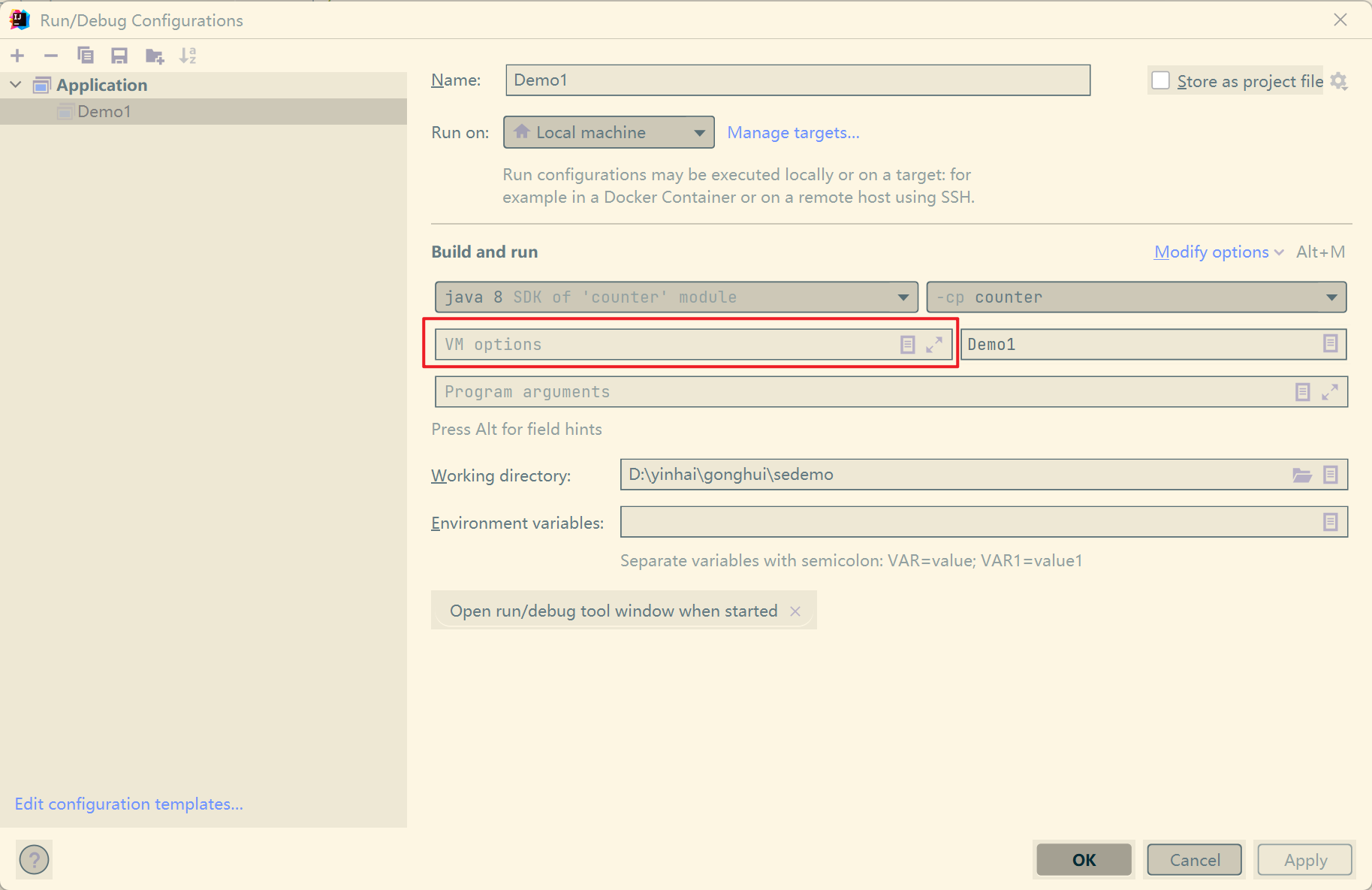
jconsole 图形界面检查内存、线程、类…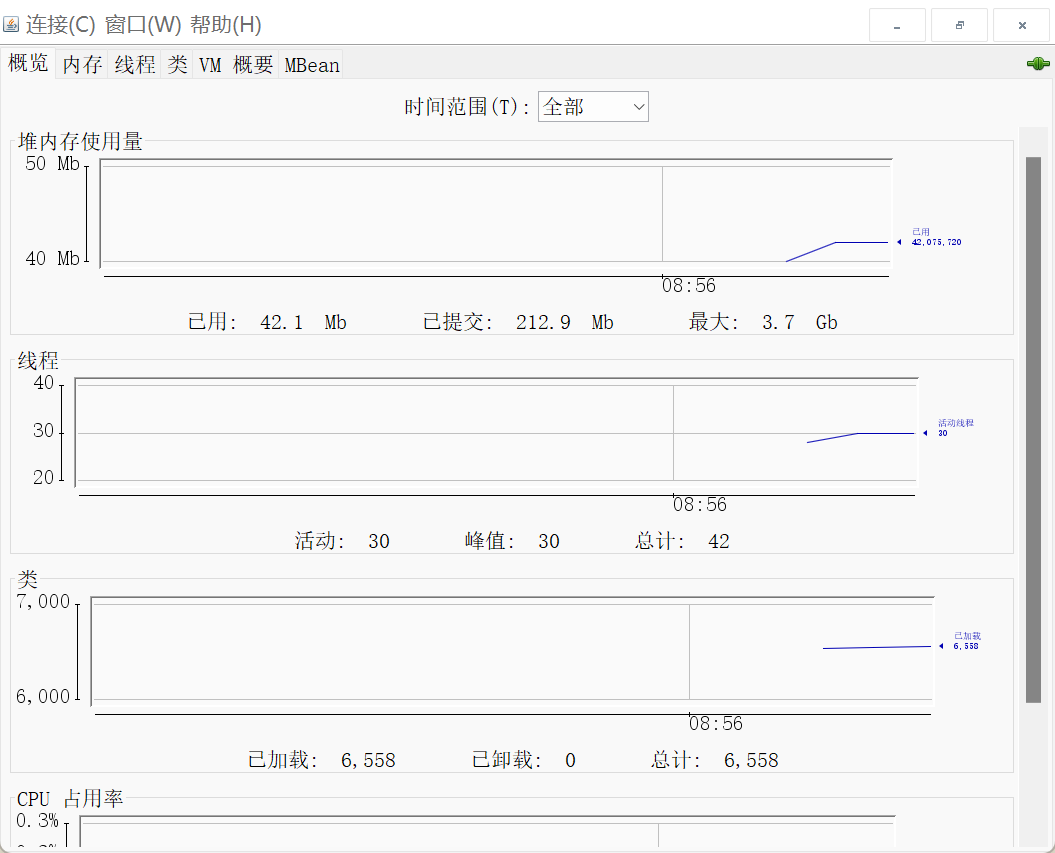
jvisualvm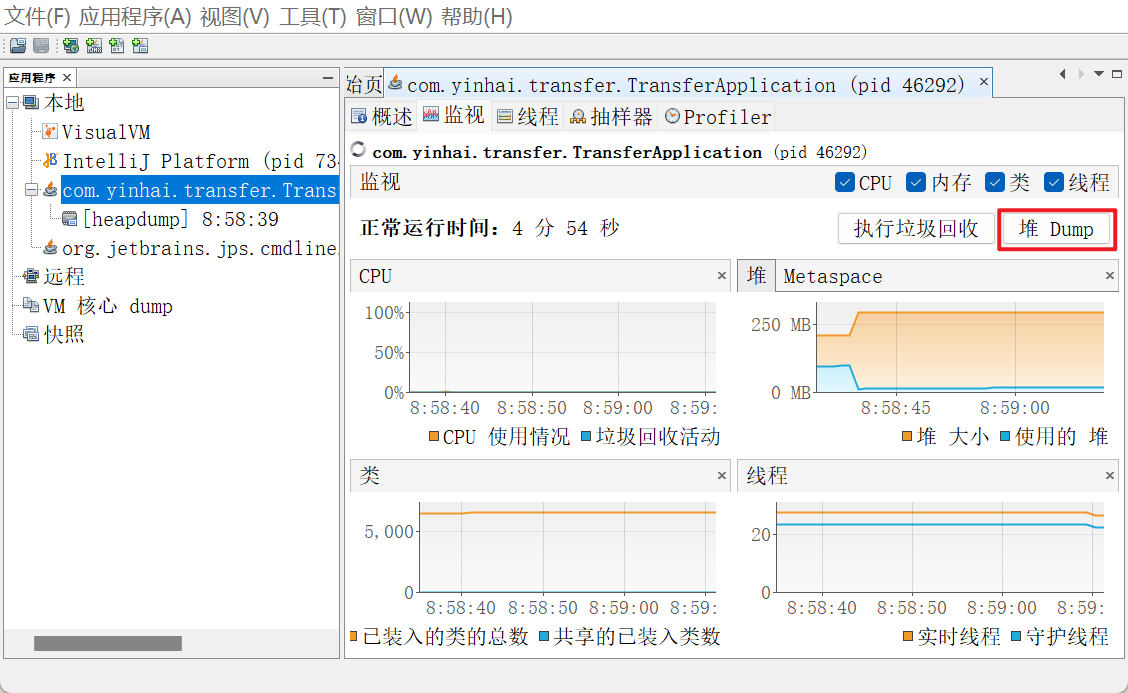
5. 方法区
方法区:
- 线程共享区域
- 存储与类结构相关的信息:run-time constant pool、field、method data、methods、constructors
- 虚拟机启动时创建
- 逻辑上是堆的组成部分
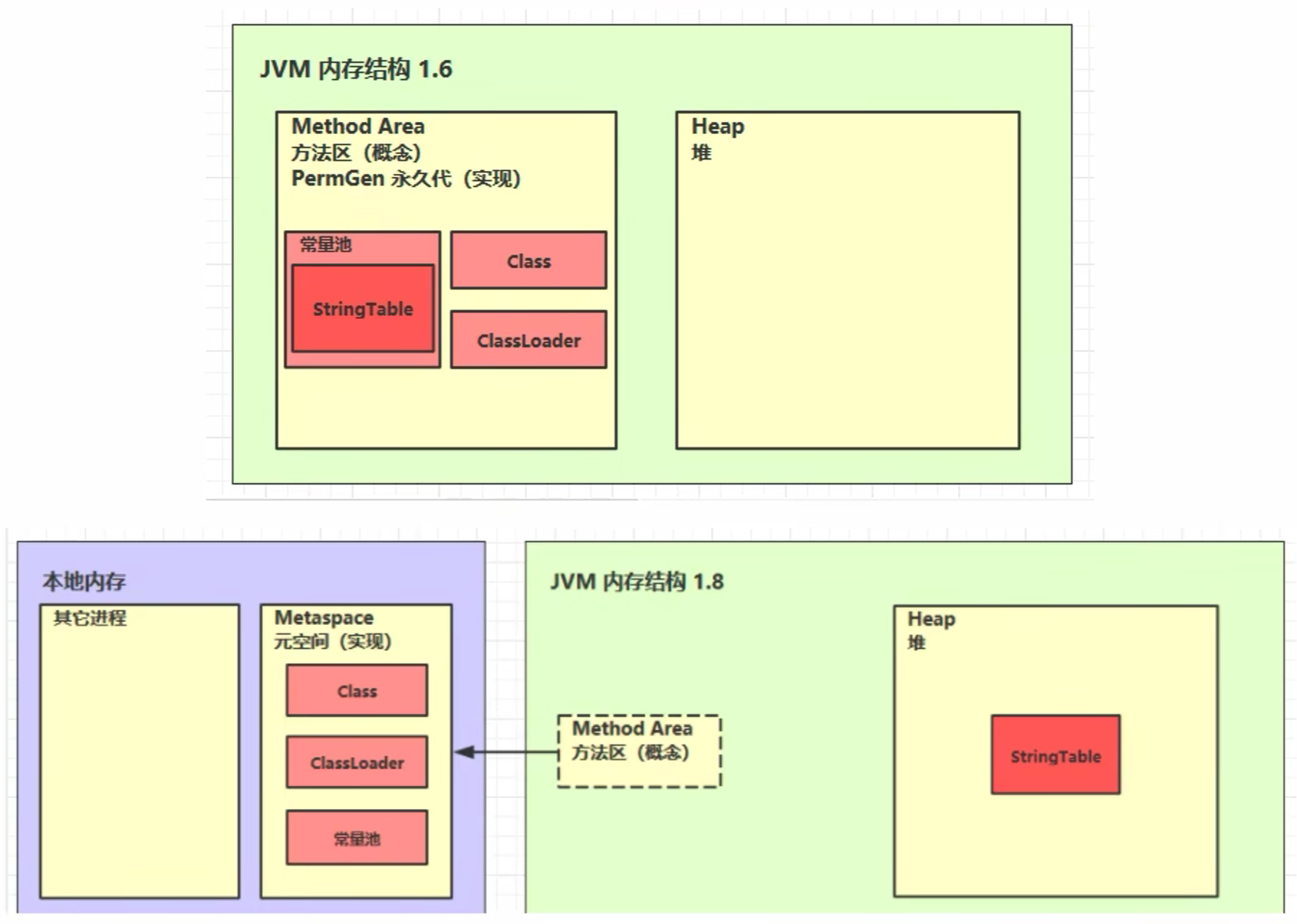
方法区内存溢出: 1.8之前是永久代内存不足导致内存溢出、1.8之后是元空间内存不足导致内存溢出。
VM options设置永久代最大保留区域(了解即可):-XX:MaxPermSize=2048m
在1.8已经弃用。
VM options设置元空间:
-XX:MetaspaceSize=100m设置元空间初始大小为100M-XX:MaxMetaspaceSize=100m设置元空间最大可分配大小为100M
通过字节码动态生成类的包:CGLIB
1. 运行时常量池
常量池: 就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息。
运行时常量池: 常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
JVM指令集
2. String Table
- 字符串的创建过程:
请点击跳转我的文章: 从字节码分析字符串是否相等
- 字符串延迟加载(实例化):

通过debug可以发现,只有当使用到某个字符串的时候,才会放入到串池(String Table)中,而且,不会重复放置相同的字符串。
这就是延迟加载机制。
串池的位置:
- 1.6 存在永久代中,内存溢出的时候会报错:
java.lang.OutOfMemoryError: PermGen space 1.8 存在堆中,内存溢出会报错:
java.lang.OutOfMemoryError: Java heap space,java.lang.OutOfMemoryError: GC overhead limit exceeded- 设置堆最大内存为4M:
-Xmx4m 代码:
public class TestStringTableLocation {public static void main(String[] args) {List<String> list = new ArrayList<>();int i = 0;try {for (int j = 0; j < 10000000; j++) {list.add(String.valueOf(j).intern());i++;}} catch (Throwable e) {e.printStackTrace();} finally {System.out.println(i);}}}

上述报错的原因:当98%的时间花在了垃圾回收上面,但是只有2%的堆空间被回收了,JVM就会放弃垃圾回收,直接报错(并不会报堆空间不足的错)
如果想要报堆空间不足的错,就需要将上述的机制关掉:完整的虚拟机参数:-Xmx4m -XX:-UseGCOverheadLimit
- 设置堆最大内存为4M:
演示串池的垃圾回收:
虚拟机参数:-Xmx4m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
-XX:+PrintStringTableStatistics:打印有关StringTable和SymbolTable的统计信息(+是开启、-是关闭)-XX:+PrintGCDetails: 打印输出详细的GC收集日志的信息-verbose:gc:在控制台输出GC情况public class TestStringTableGC {
public static void main(String[] args) {int i = 0;try {
} catch (Throwable e) {e.printStackTrace();} finally {System.out.println(i);}}}
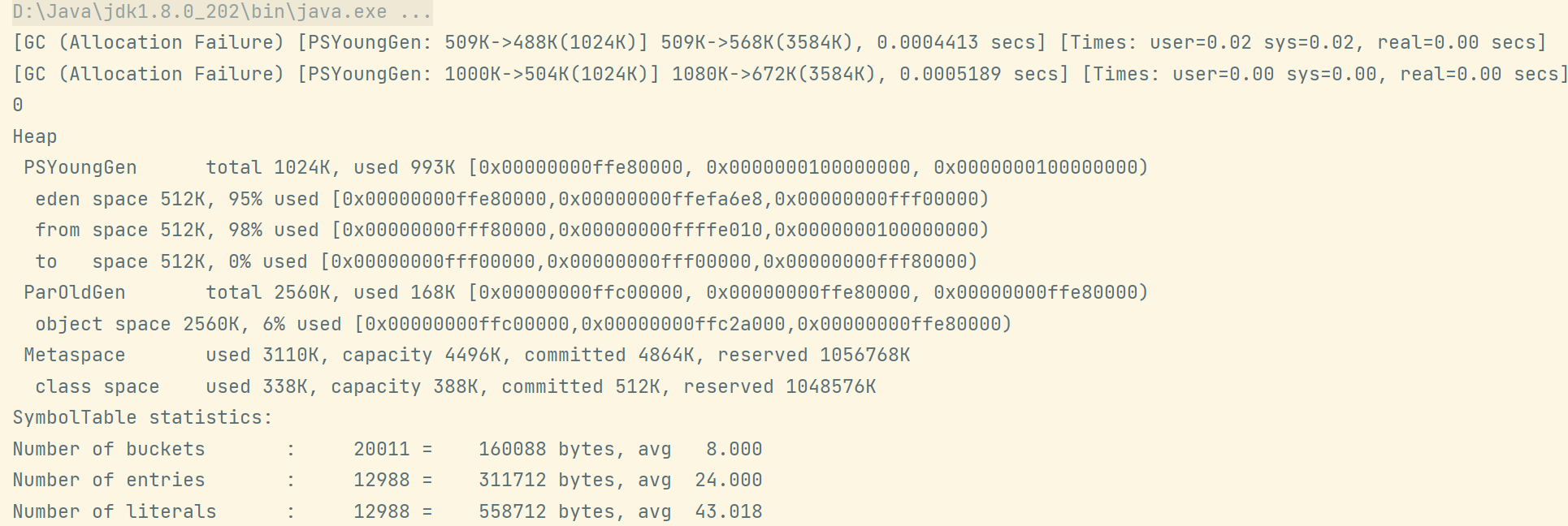

public class TestStringTableGC {public static void main(String[] args) {int i = 0;try {for (int j = 0; j < 100; j++) {String.valueOf(j).intern();i++;}} catch (Throwable e) {e.printStackTrace();} finally {System.out.println(i);}}}

通过不断修改循环的上限值,可以从控制台看到GC回收被触发:
性能调优:
通过上述案例我们可以知道,String Table采用的是桶机制,所以:
- 当桶足够多的时候,桶元素发生hash碰撞的几率就更小,查找速度就会增快
- 当桶的数量较少的时候,桶元素发生hash碰撞的几率就更大,导致链表更长,从而降低查找速度
所以String Table的性能调优就是修改桶的个数。
虚拟机参数:
-Xms500m设置堆内存初始值为500m-Xmx500m设置堆最大内存为500M-XX:+PrintStringTableStatistics打印有关StringTable和SymbolTable的统计信息-XX:StringTableSize=20000设置串池的桶个数为20000public class TestStringTableOptimization {
public static void main(String[] args) throws IOException {try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("D:\\YH\\examtest20210723.sql")))) {String line = null;long start = System.nanoTime();while (true) {line = reader.readLine();if (line == null) {break;}line.intern();}System.out.println("const:" + (System.nanoTime() - start) / 100000);}}
}
当桶的个数为2000时: -XX:StringTableSize=20000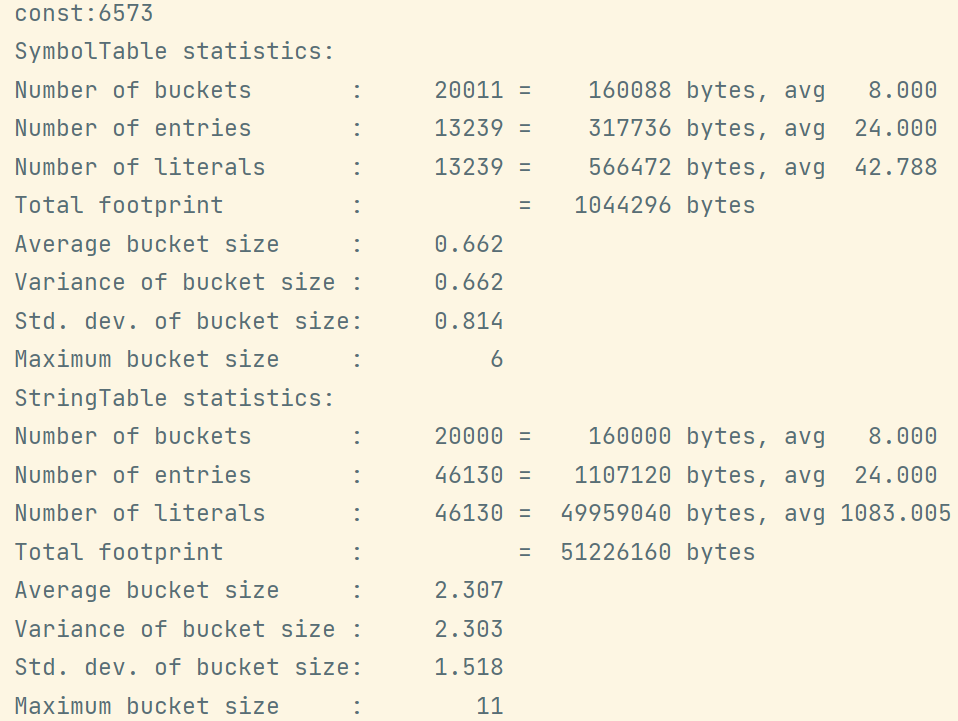
当桶的个数为10000时: -XX:StringTableSize=10000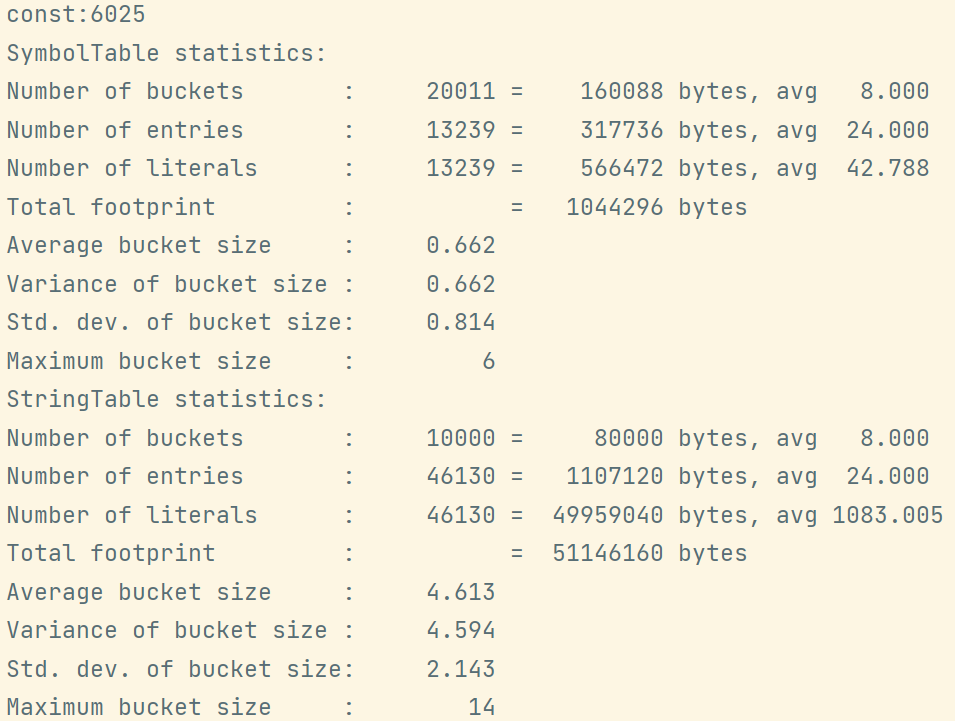
当桶的个数为1009时: -XX:StringTableSize=1009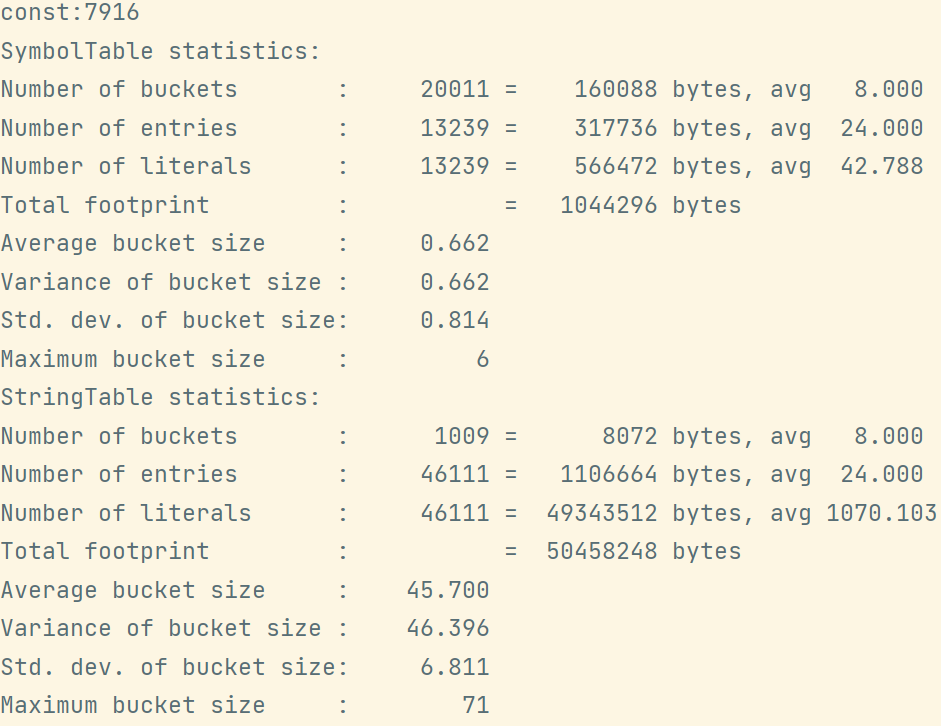
字符串入串池的优点: 极大节约了内存占用(重复的字符串只会在串池中存储一个)
不存入串池
list.add(line);public class TestStringTableOptimization {public static void main(String[] args) throws IOException {List<String> list = new ArrayList<>();System.in.read();for (int i = 0; i < 10; i++) {try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("D:\\YH\\examtest20210723.sql")))) {String line = null;long start = System.nanoTime();while (true) {line = reader.readLine();if (line == null) {break;}/*line.intern();*/list.add(line);}System.out.println("const:" + (System.nanoTime() - start) / 100000);}}System.in.read();}}

- 存入串池:
list.add(line.intern());
3. 直接内存
直接内存:
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
不使用直接内存: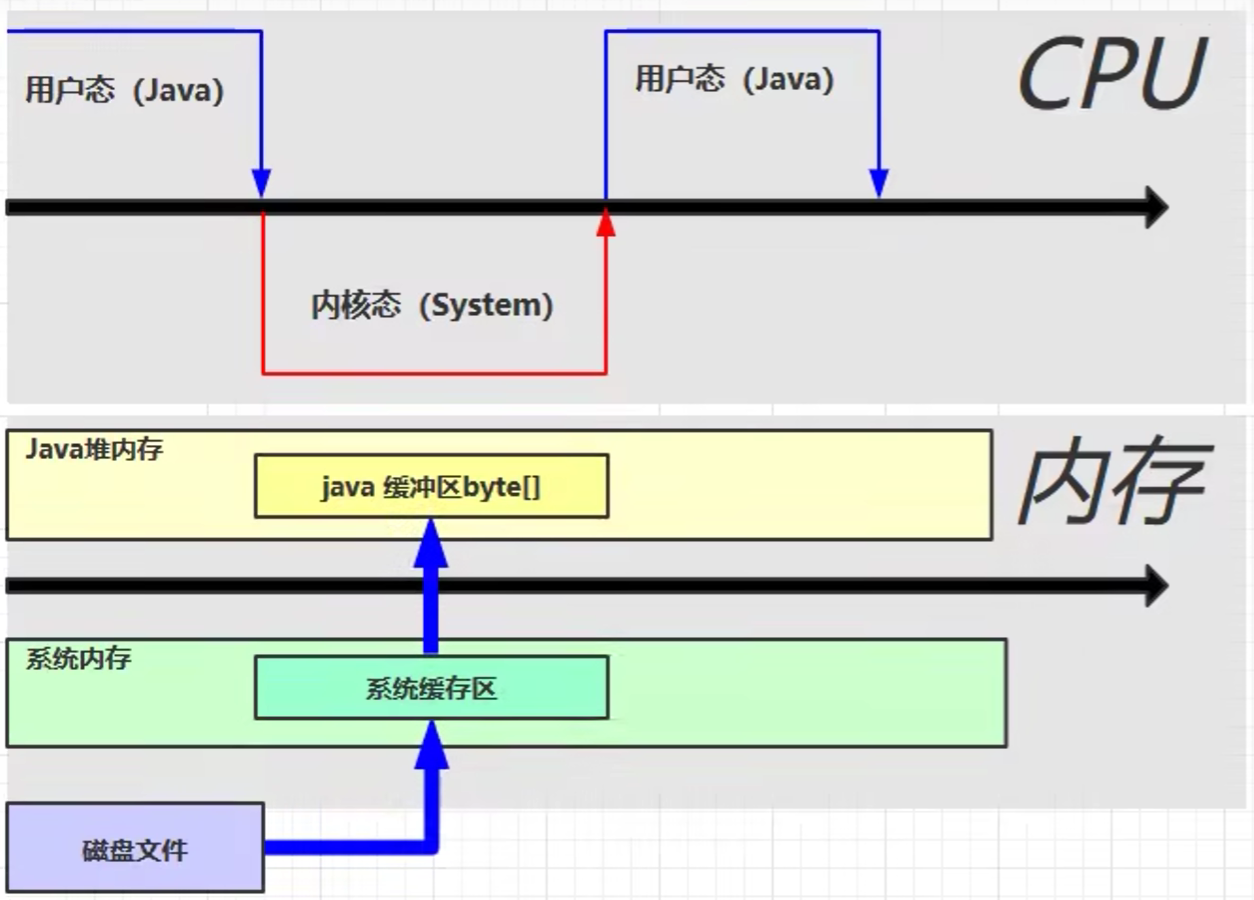
使用直接内存: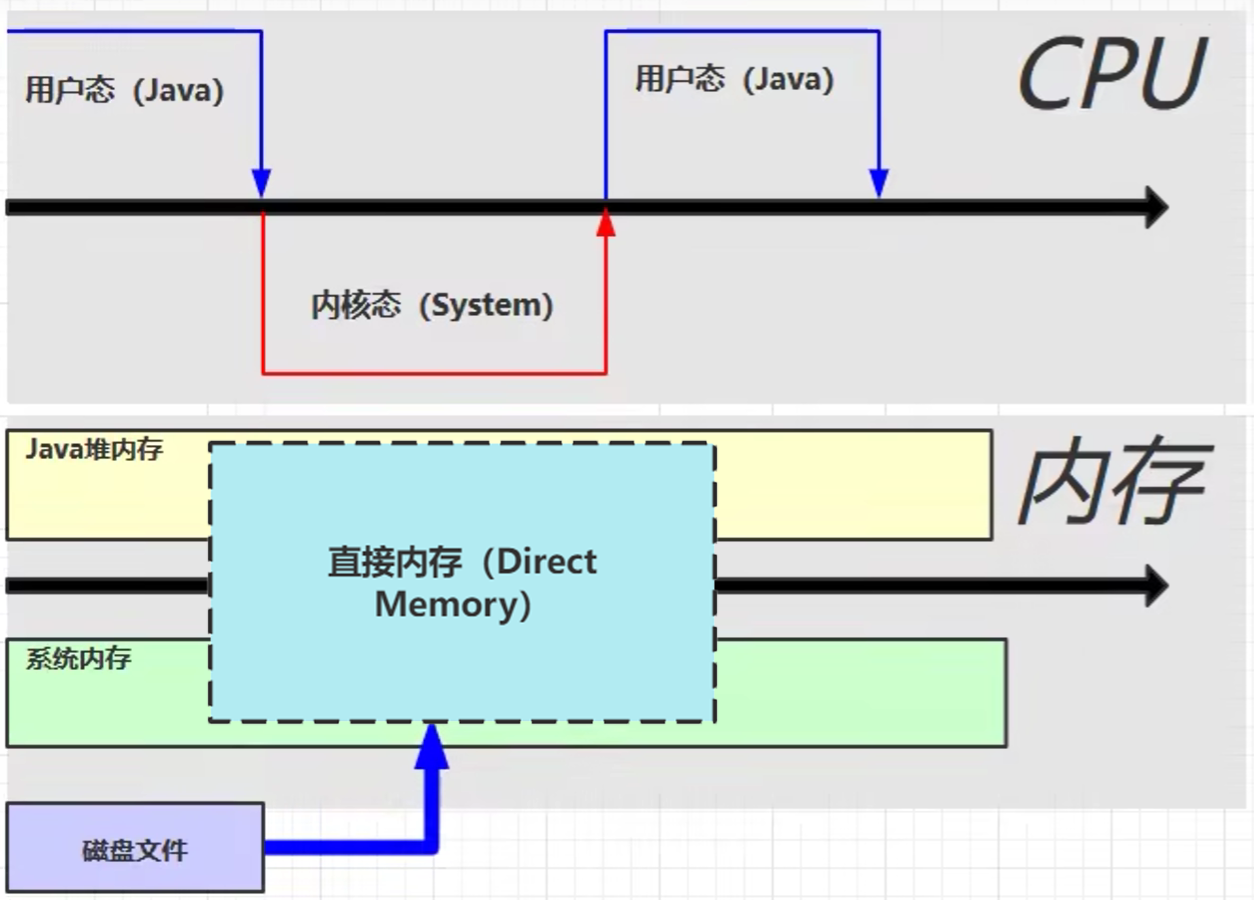
直接内存使得java代码能直接读取到系统内存的数据,极大缩减了代码执行时间。
分配直接内存缓冲区的方法:
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);}
直接内存溢出演示:
public class TestDirectOut {static int _100Mb = 1024 * 1024 * 100;public static void main(String[] args) {List<ByteBuffer> list = new ArrayList<>();int i = 0;try {while (true) {// allocateDirect分配多少内存,就会占用本地多少内存ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_100Mb);list.add(byteBuffer);i++;}} finally {System.out.println(i);}}}

分配和回收原理:
- 使用了
Unsafe对象完成直接内存的分配回收,并且回收需要主动调用freeMemory方法 ByteBuffer的实现类内部,使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程通过Cleaner的clean方法调用freeMemory来释放直接内存
JVM调优常用参数: -XX:+DisableExplicitGC
- 让显示的垃圾回收无效(即直接手动敲代码回收,如
System.gc()) - 因为显示的垃圾回收是一种 Full gc 即,要回收新生代,还要回收老年代,会造成较长的代码停留时间
但是,禁用掉显示的垃圾回收之后,直接内存的回收就只能依靠 Cleaner 来检测回收了,这样就会导致直接内存长时间得不到释放。
public static void main(String[] args) throws IOException {ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);System.out.println("分配完毕...");System.in.read();System.out.println("开始释放...");byteBuffer = null;System.gc(); // 显式的垃圾回收,Full GCSystem.in.read();}
这时候就需要使用Unsafe来手动回收内存了:
public static void main(String[] args) throws IOException {Unsafe unsafe = getUnsafe();// 分配内存long base = unsafe.allocateMemory(_1Gb);unsafe.setMemory(base, _1Gb, (byte) 0);System.in.read();// 释放内存unsafe.freeMemory(base);System.in.read();}public static Unsafe getUnsafe() {try {Field f = Unsafe.class.getDeclaredField("theUnsafe");f.setAccessible(true);Unsafe unsafe = (Unsafe) f.get(null);return unsafe;} catch (NoSuchFieldException | IllegalAccessException e) {throw new RuntimeException(e);}}
3. 垃圾回收
1. 判断对象可以被回收的算法
1. 引用计数法
引用计数法: 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1,当引用失效时,计数器就减1。任何时刻计数器为0的对象就是不再被使用的。
巨大缺陷: 很难解决对象之间相互循环引用的问题,因此JVM并未采用这种方法。
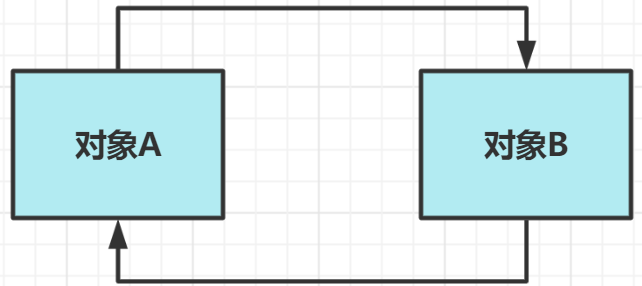
2. 可达性分析算法
可达性分析算法:
- 用过一系列的
gc root来判断对象是否被引用 - 如果
gc root可以直接或间接引用到某个对象,就表明该对象被引用,反之则说明该对象不可用 - 在下次垃圾回收到达的时候,不可用的对象就会被回收
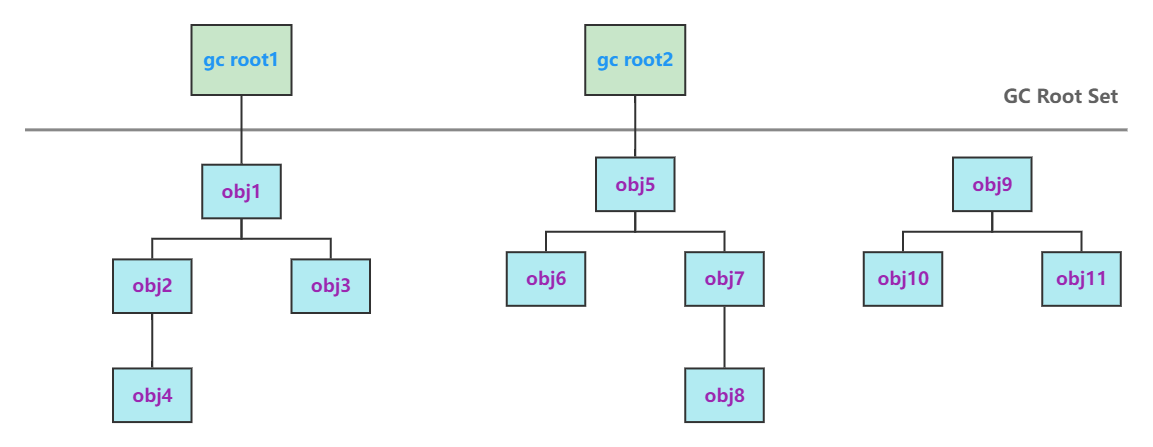
如图,下次垃圾回收的时候,obj9、obj10、obj11就会被回收。
GC Roots对象取用范围:
System Class系统类,启动类加载器加载的类(核心类)- 如Object、String、HashMap等
Native Stack本地方法栈的操作系统方法Busy Monitor被synchronized或者lock加锁的对象Thread活动线程用到的对象(一个线程对应一个栈,栈帧内的对象)
宣告对象死亡:
宣告对象死亡至少需要经历两次标记过程:
第一次标记:
- 在对对象进行可达性分析发现对象没有被 gc root 引用,则会对其进行标记并进行第一次筛选
第一次筛选主要是为了判断改对象是否需要执行
finalize()
利用finalize()方法最多只会被调用一次的特性,我们可以实现延长对象的生命周期
这是由于finalize()方法的调用时机具有不确定性,从一个对象变得不可到达开始,到finalize()方法被执行,所花费的时间这段时间是任意长的- 当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为没有必要执行
- 如果对象被判定为有必要执行,则会被放到一个F-Queue队列
第二次标记:
- gc将F-Queue中的对象进行第二次标记
- 如果这时候,对象通过调用
finalize()与 gc root 引用链上的任何一个对象建立关联,那么此对象就会被移出即将被回收的队列
2. 五种常见引用类型
1. 简介及其回收机制
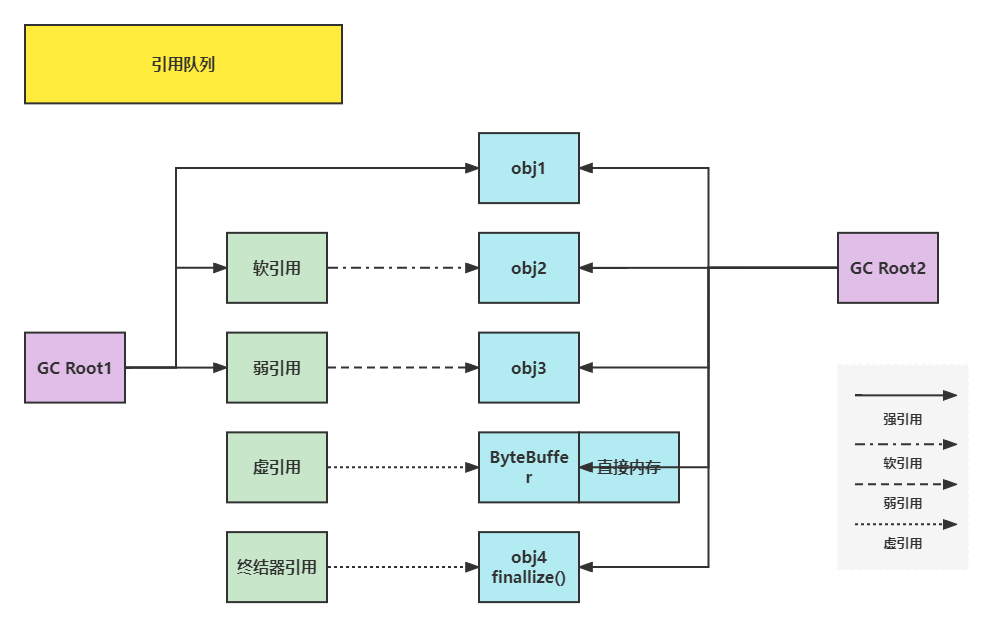
强引用:
- 如:
Object obj = new Object()变量obj强引用了实例出的对象 - 只要引用链能找到此对象,就不会被回收
软/弱引用:
- 只要没有被强引用直接地引用,都有可能被垃圾回收,如下图:
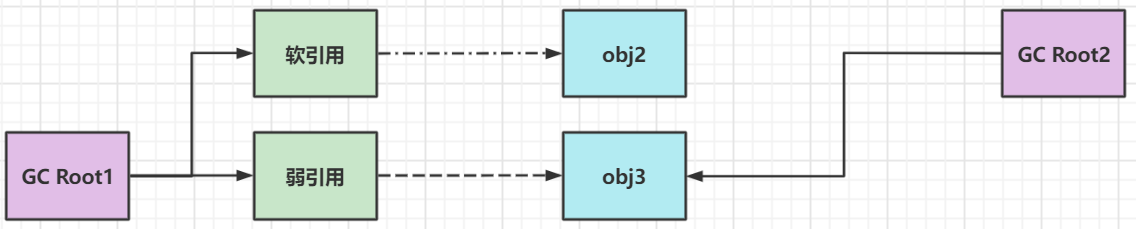
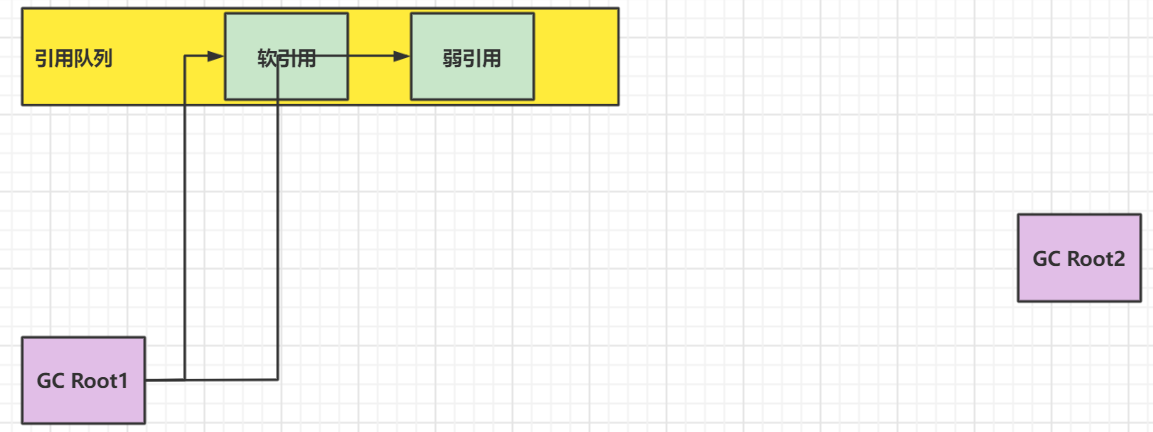
软引用被回收: 因为obj2在引用cg root引用链中没有被强引用直接引用,所以在下一次垃圾回收且内存不够的时候,有可能被回收
弱引用被回收: obj3被强引用直接引用了,所以就不会被垃圾回收。可如果obj3也没有强引用直接引用,就会在下一次垃圾回收的时候被回收 - 当软/弱引用的对象被回收之后,如果在创建软/弱引用的时候,被分配了一个引用队列,那么软/弱引用就会进入引用队列(这两者也会占用内存,也可以释放掉)

虚/终结引用:
- 虚/终结引用 必须配合引用队列来使用
- 当 虚/终结引用对象 被创建的时候,就会创建一个引用队列
- 虚引用回收:

在创建ByteBuffer对象的时候,就会使用Cleaner来监测,而一旦没有强引用引用ByteBuffer的时候,ByteBuffer自己就会被垃圾回收掉,如下:
但是这时候,直接内存还没有被回收,所以这时候,虚引用对象就会进入引用队列,由Reference Handler线程调用虚引用相关方法(Unsafe.freeMemory)释放直接内存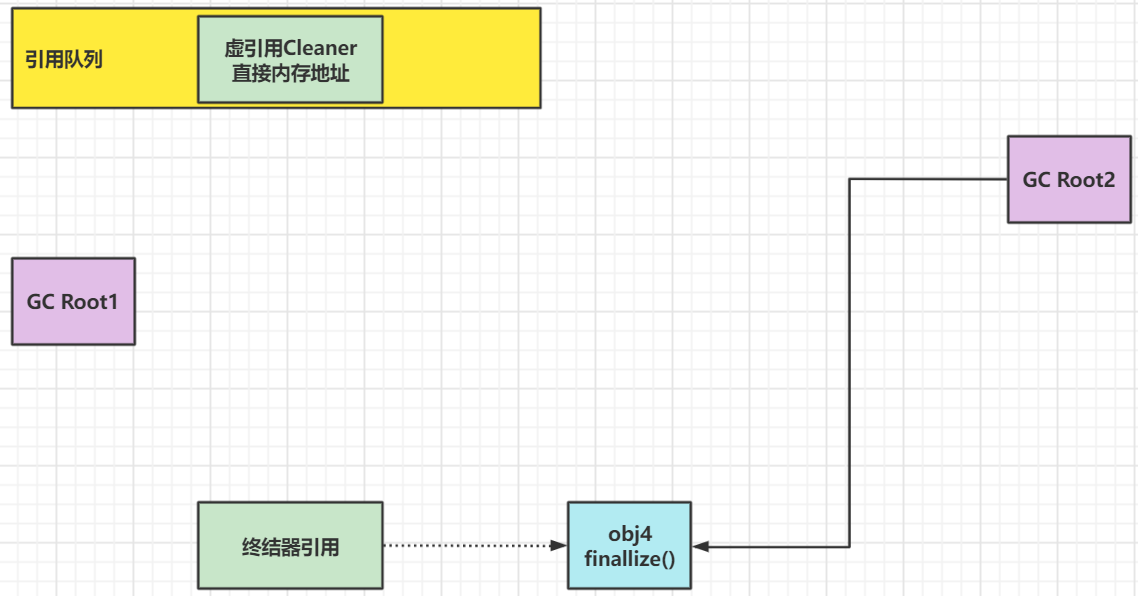
- 终结引用回收:
当没有强引用去引用对象(重写了finallize()的对象)的时候,JVM就会给此对象创建一个终结器引用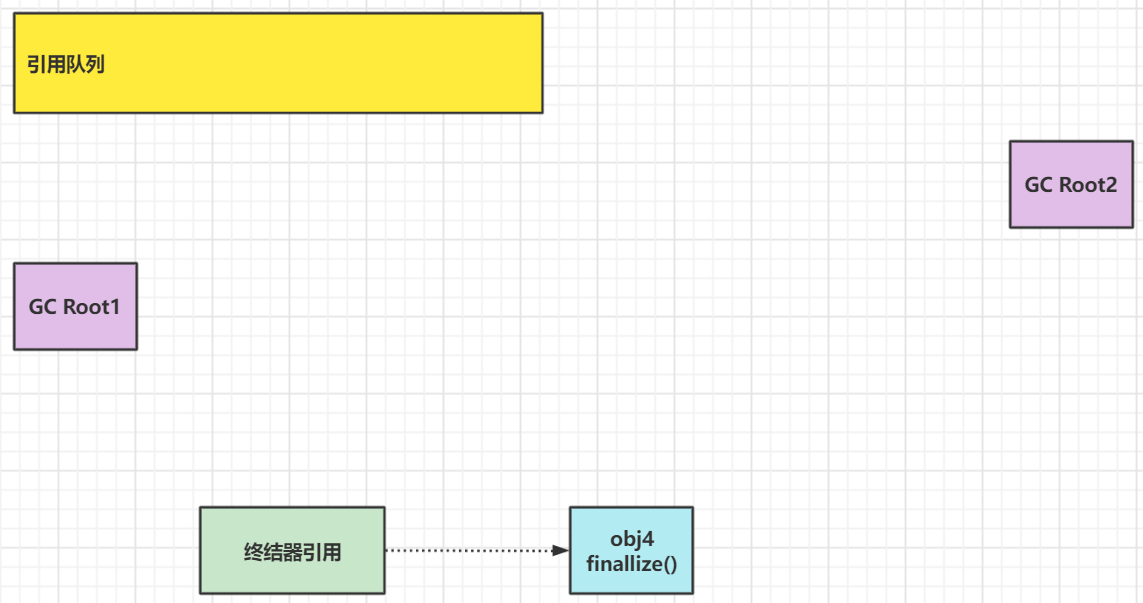
当对象被垃圾回收器回收的时候,终结器引用也会进入引用队列,但这时候对象还没有被回收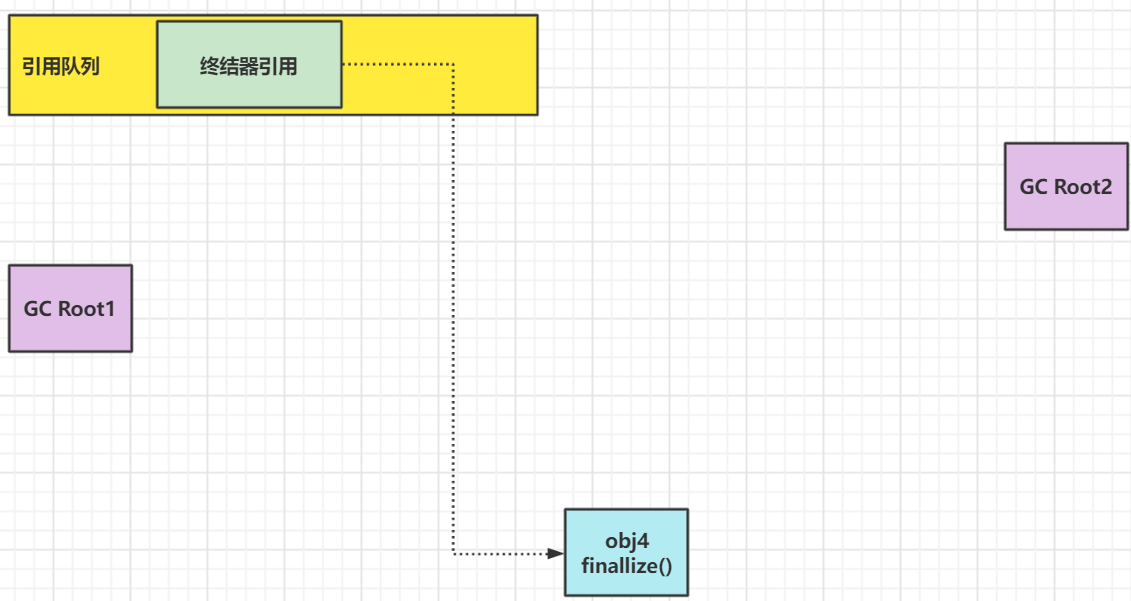
然后Finalizer线程(此线程优先级很低,被执行的机会很少)通过终结器引用找到被引用对象并调用它的finalize方法,第二次 GC 时才能回收被引用对象
2. 代码演示
在JDK1.2之前,只有引用和没引用两种状态。
SoftReference 实现软引用的类,WeakReference 实现弱引用的类、PhantomReference 实现虚引用的类。
软引用演示:
- 虚拟机参数:
-Xmx20m -XX:+PrintGCDetails -verbose:gc最大堆内存20M,打印GC细节,控制台输出gc情况 代码(软引用所引用对象的回收):
不使用软引用情况:
public class TestSoft {
private static final int _4MB = 4 * 1024 * 1024;public static void main(String[] args) throws IOException {List<byte[]> list = new ArrayList<>();for (int i = 0; i < 5; i++) {list.add(new byte[_4MB]);}System.in.read();}会造成内存溢出![530bd51fa8f547b5b8213b77455eabf8.png][]* 使用软引用:public class TestSoft {private static final int _4MB = 4 * 1024 * 1024;public static void main(String[] args) throws IOException {soft();}public static void soft() {// list --> SoftReference --> byte[]List<SoftReference<byte[]>> list = new ArrayList<>();for (int i = 0; i < 5; i++) {SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB]);System.out.println(ref.get());list.add(ref);System.out.println(list.size());}System.out.println("循环结束:" + list.size());for (SoftReference<byte[]> ref : list) {System.out.println(ref.get());}}}不会造成内存溢出:![8e5fd036a942459bbee3f76bdae36247.png][]**软引用特点:** 一次垃圾回收之后,内存仍然不足,就会把软引用所引用的对象回收。
代码(软引用对象本身的回收)
使用引用队列
ReferenceQueue// 引用队列ReferenceQueue<byte[]> queue = new ReferenceQueue<>();// 创建软引用的同时关联引用队列SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);// 从队列中获取无用的 软引用对象,并移除Reference<? extends byte[]> poll = queue.poll();while( poll != null) {list.remove(poll);poll = queue.poll();}
完整代码
public class TestSoft{private static final int _4MB = 4 * 1024 * 1024;public static void main(String[] args) {List<SoftReference<byte[]>> list = new ArrayList<>();// 引用队列ReferenceQueue<byte[]> queue = new ReferenceQueue<>();for (int i = 0; i < 5; i++) {// 关联了引用队列, 当软引用所关联的 byte[]被回收时,软引用自己会加入到 queue 中去SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);System.out.println(ref.get());list.add(ref);System.out.println(list.size());}// 从队列中获取无用的 软引用对象,并移除Reference<? extends byte[]> poll = queue.poll();while( poll != null) {list.remove(poll);poll = queue.poll();}System.out.println("===========================");for (SoftReference<byte[]> reference : list) {System.out.println(reference.get());}}}
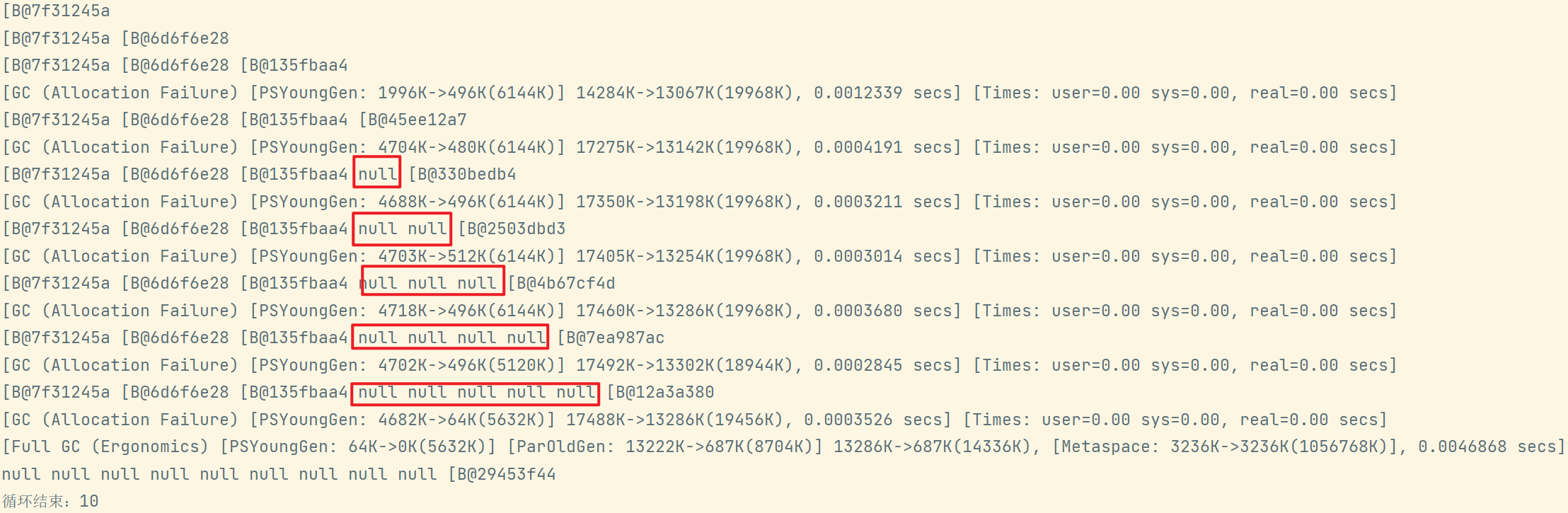
弱引用演示:
- 虚拟机参数:
-Xmx20m -XX:+PrintGCDetails -verbose:gc 代码(弱引用所引用的对象被回收)
public class TestWeak{private static final int _4MB = 4 * 1024 * 1024;public static void main(String[] args) {// list --> WeakReference --> byte[]List<WeakReference<byte[]>> list = new ArrayList<>();for (int i = 0; i < 10; i++) {WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);list.add(ref);for (WeakReference<byte[]> w : list) {System.out.print(w.get()+" ");}System.out.println();}System.out.println("循环结束:" + list.size());}}
3. 垃圾回收算法
1. 标记清除算法
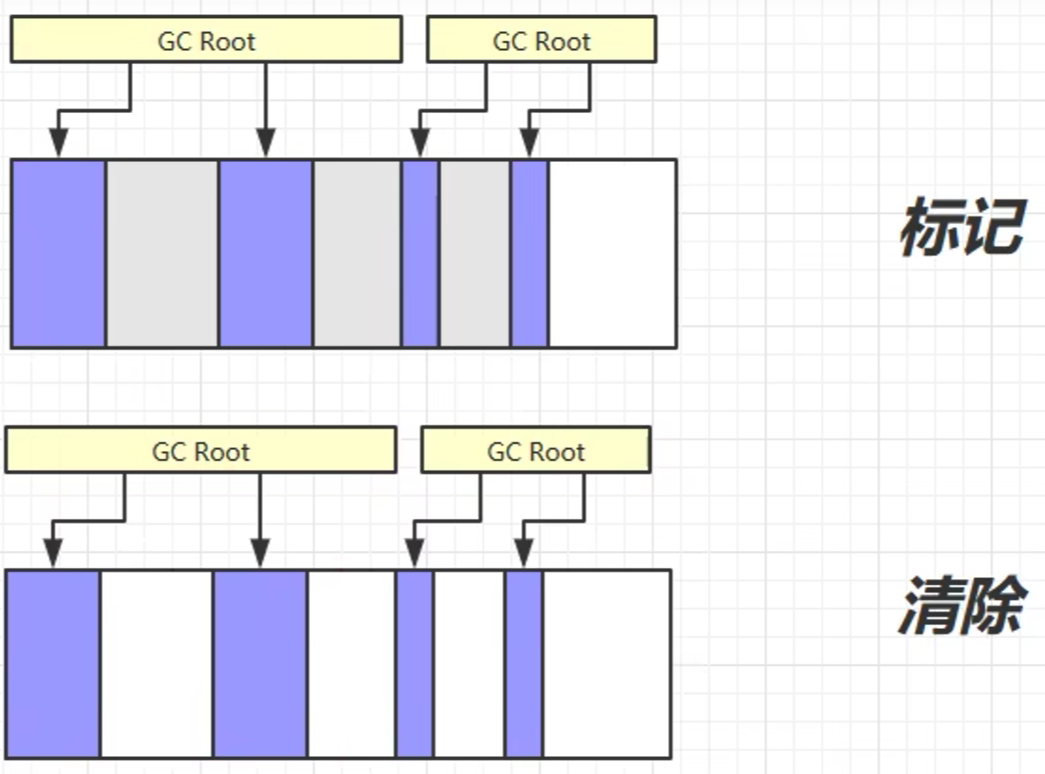
- 先扫描没被 GC Root 引用链引用的对象,并对其进行标记
- 释放被标记对象的内存
并不会清零被释放的空间,新来的对象,会被插入到合适的释放空间中
优点:
- 速度快,只需要记录地址
缺点:
- 容易产生内存碎片
只会清除对象,并不会释放的空间做进一步处理
2. 标记整理算法

优点:
- 没有内存碎片
缺点:
- 涉及到对象移动,效率偏低
3. 复制算法
先做标记: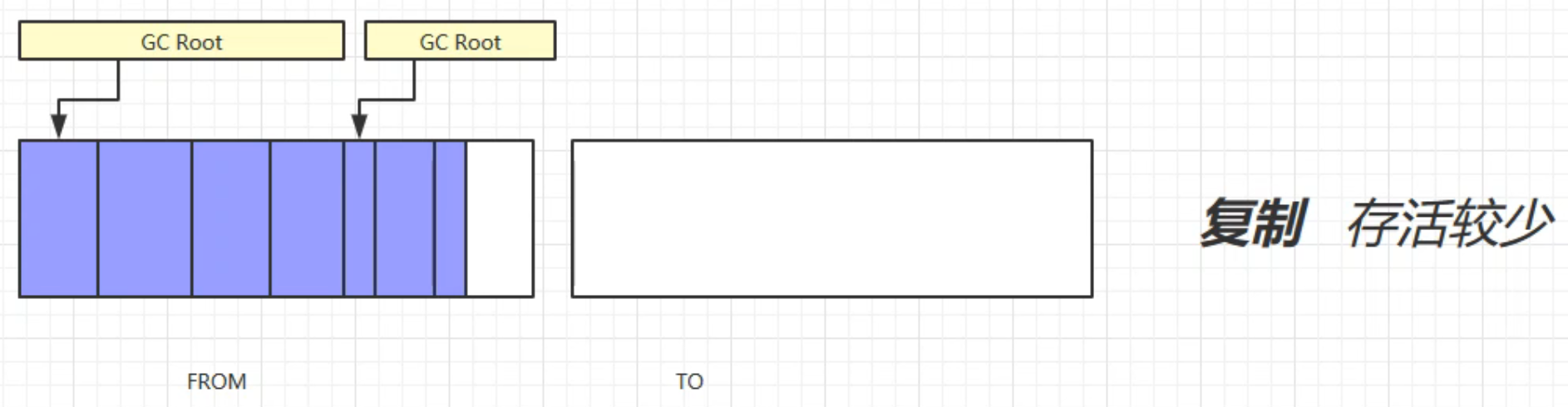
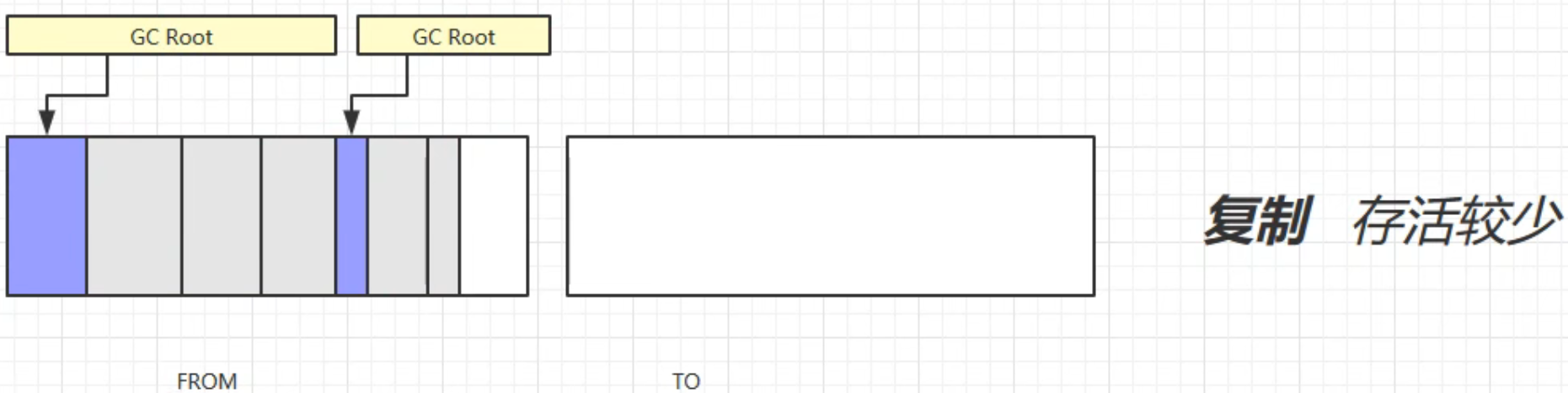
将被引用的对象复制到To中,顺便完成碎片整理: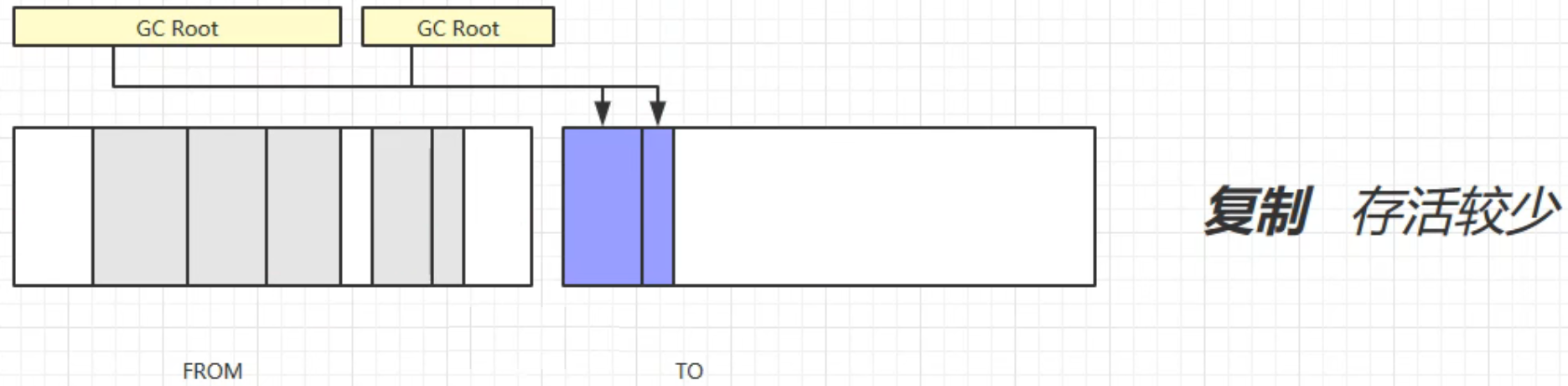
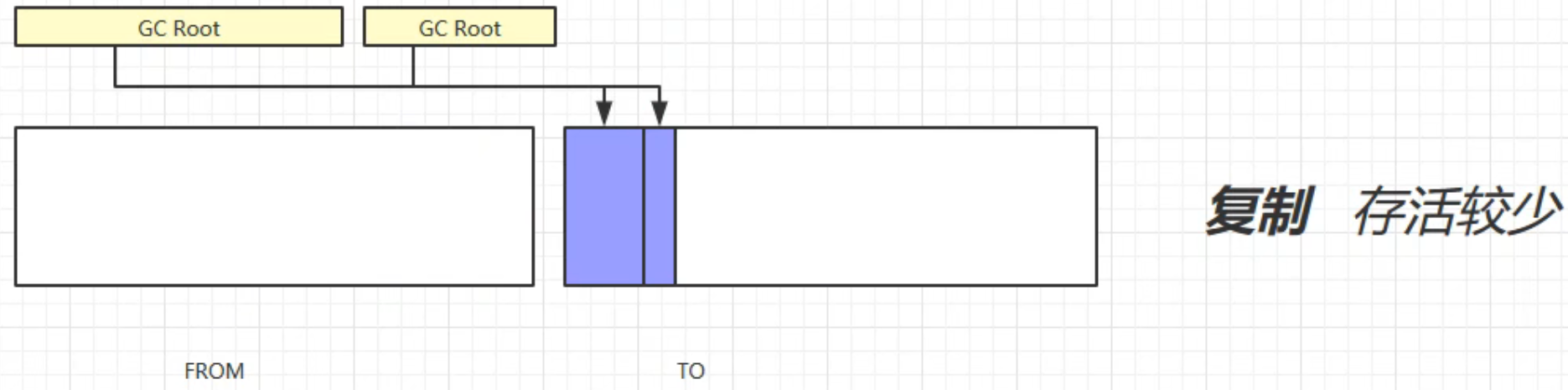
交换from和to的位置: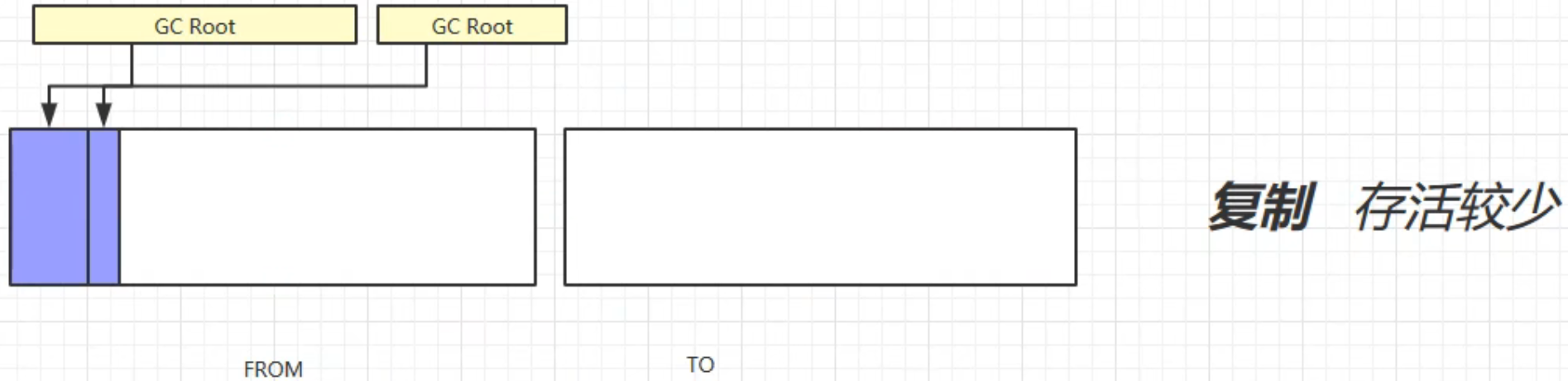
4. 对比
| 算法 | 优点 | 缺点 |
|---|---|---|
| 标记清除(Mark Sweep) | 速度快 | 会造成内存碎片 |
| 标记整理(Mark Compact) | 没有内存碎片 | 速度慢 |
| 复制(Copy) | 没有内存碎片 | 需要占用双倍内存空间 |
5. 分代回收
JVM采用的垃圾回收算法,是综合上述三种算法的一种叫做 分代回收 的算法。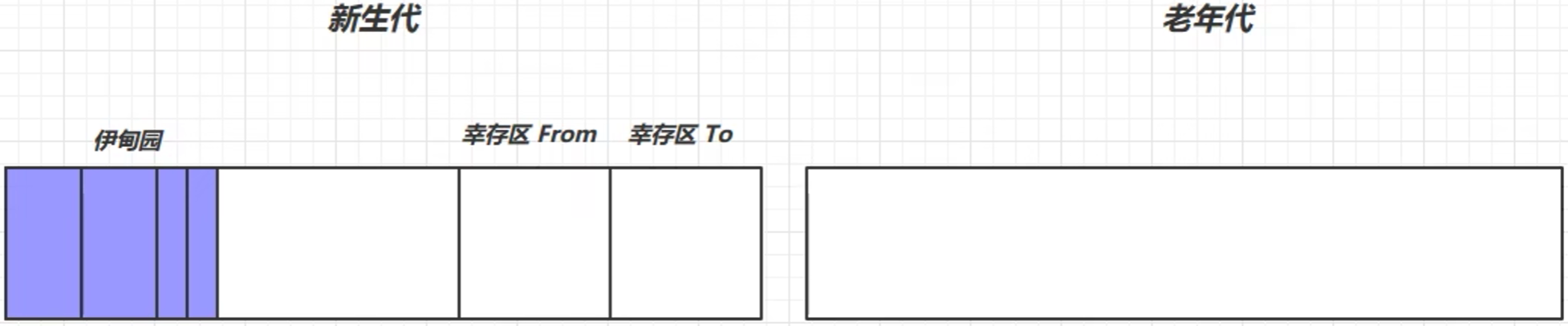
新生代:用完就可以丢的对象;老年代:需要一直使用的对象。
故而,老年代和新生代的回收策略不同。
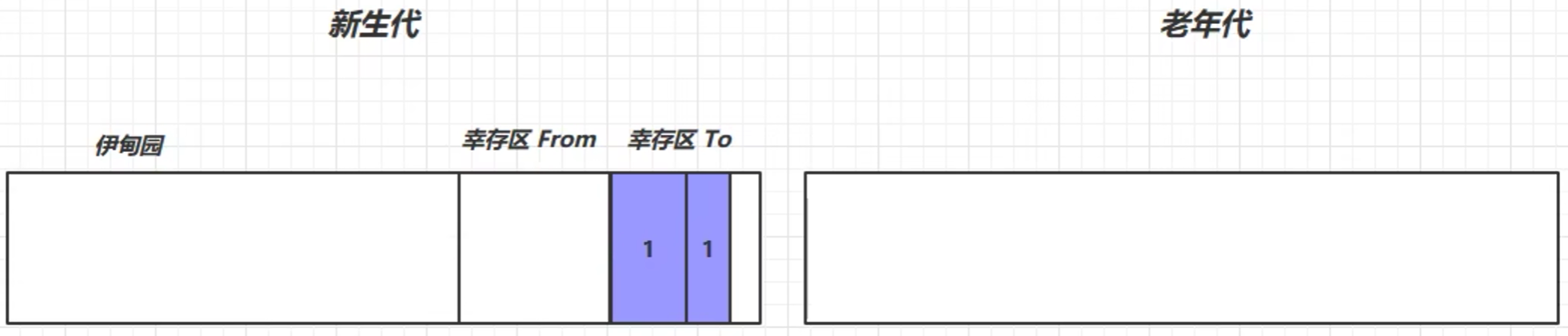
- 当新生代的伊甸园区逐渐放不下的时候,会触发一次垃圾回收——Minor GC
标记→复制→To→To区幸存者寿命+1(初始是0)→回收伊甸园空间→交换幸存区from和to的位置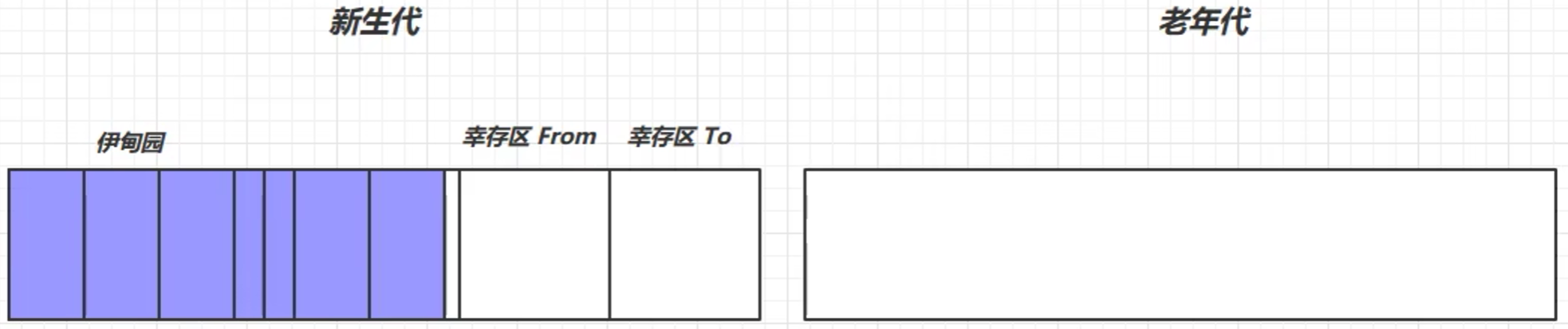
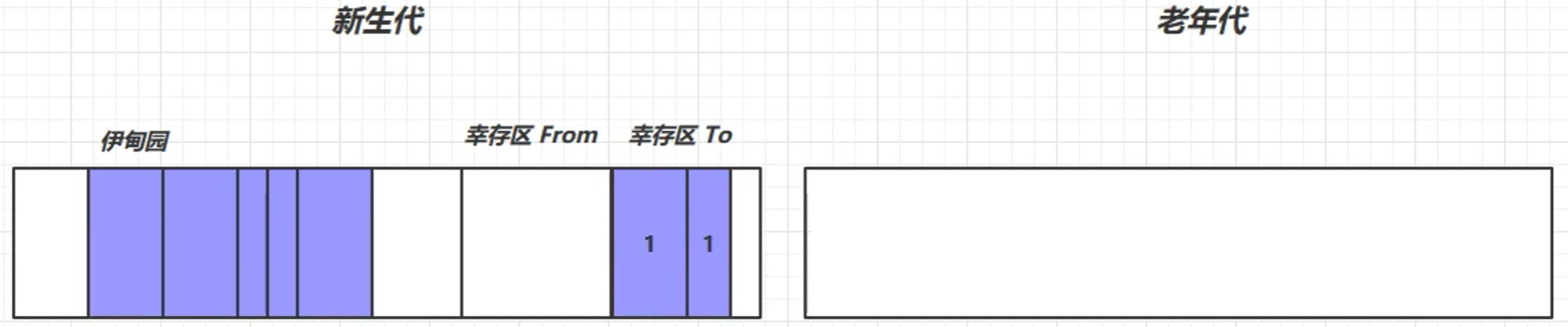

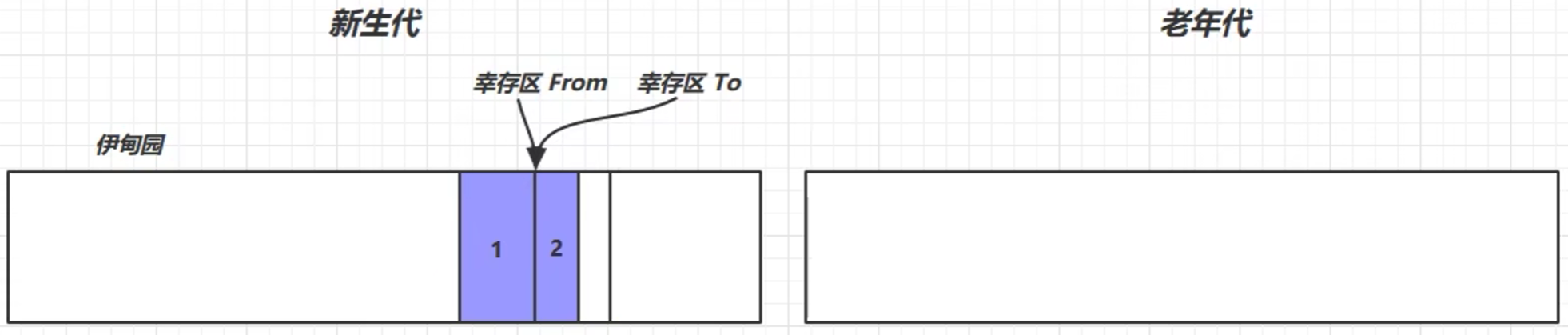
- 继续往伊甸园存数据,当伊甸园又满了,就触发垃圾回收——Minor GC
标记伊甸园区幸存对象、标记幸存区from中幸存对象→将幸存对象转移到from区→对幸存的对象寿命+1→回收内存空间→交换from和to的位置→伊甸园放入新对象

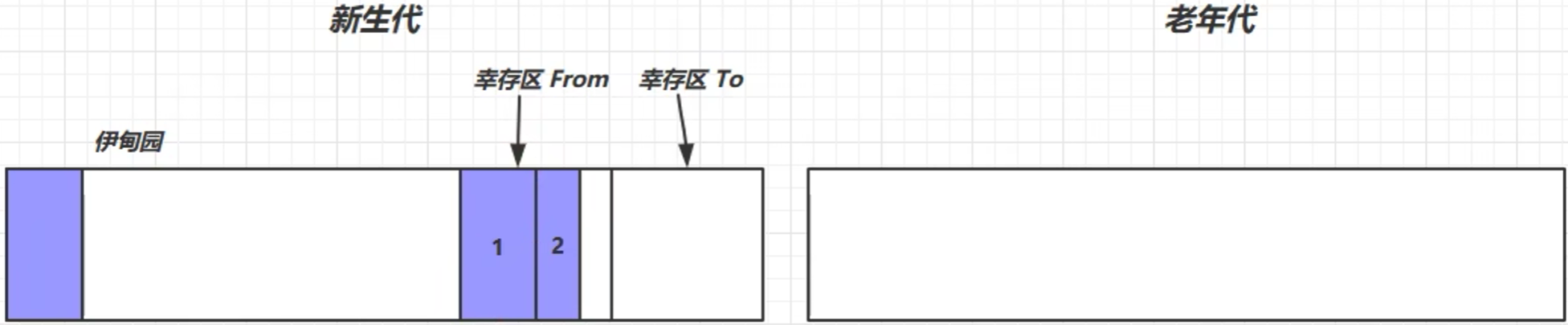
- 当新生代幸存区中某一对象的寿命超过了某一阈值(比如说15),就说明该对象的价值比较大,就会把该对象晋升到老年代中
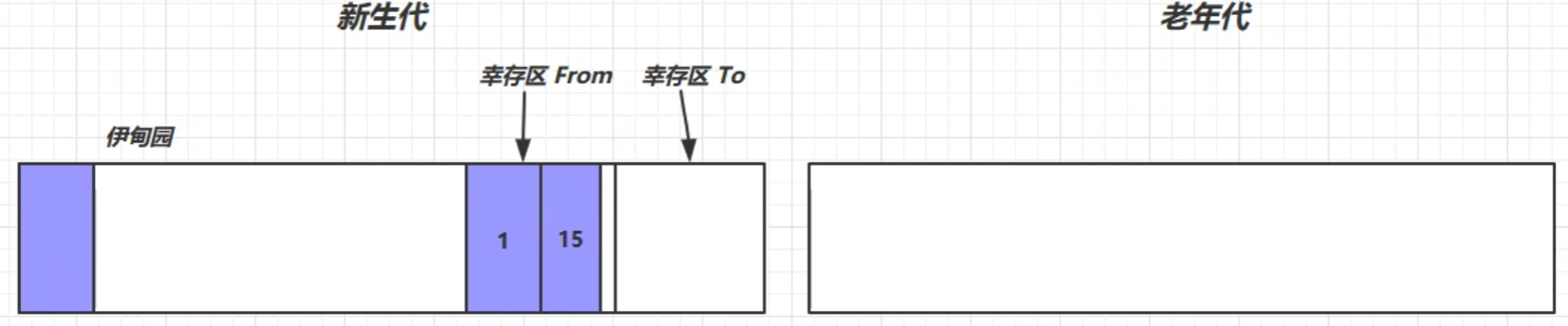
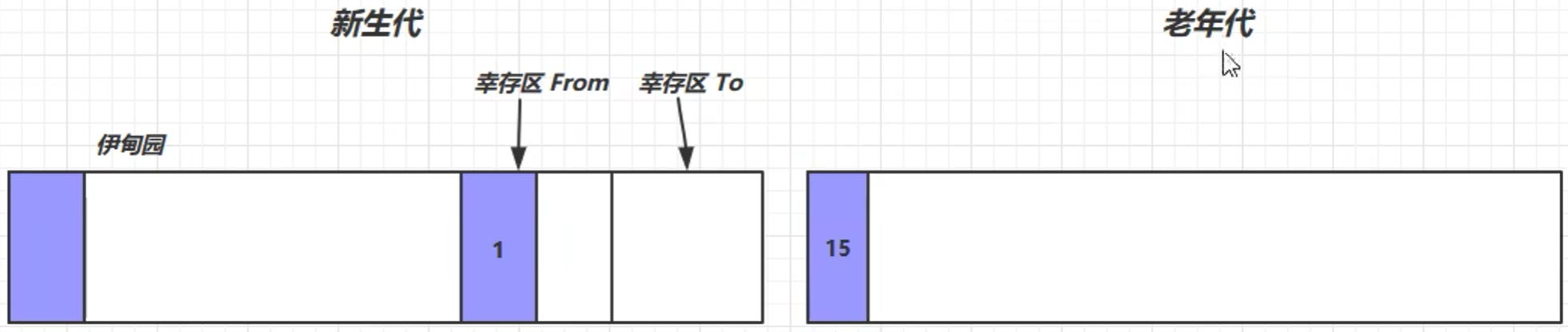
- 当老年代的内存空间不足的时候,就会触发垃圾回收——Full GC (标记整理算法)
先对新生代进行回收——Minor GC,如果回收之后空间还是不足,就会对老年代进行回收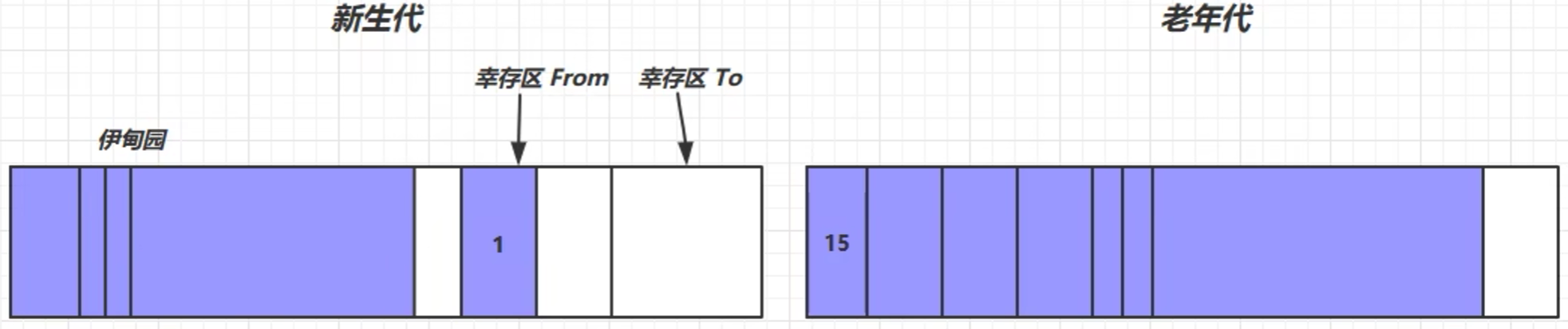
6. 分代回收小结
- 对象首先分配在 新生代——伊甸园区
- 新生代空间不足触发 Minor GC,将 伊甸园 和 From 中的存活对象 复制 到 To 中,存活对象 +1,并且交换 From 和 To
- Minor GC 会引发 stop the world 暂停其他用户的线程,先让 gc 回收结束之后(速度很快,大部分都是回收,少部分复制),再恢复用户线程
- 当对象寿命超过阈值的时候(最大阈值——15,4bit),就会晋升老年代
- 当老年代空间不足,先尝试做一次Minor GC,如果空间仍不足,就触发 Full GC,然后引发 stop the world,但时停时间比 Minor GC 更长
- 当 Full GC 之后, 老年代空间仍然不足,就会触发 OutOfMemoryError
7. VM Options
| 参数 | 说明 |
|---|---|
-Xsssize | 设置栈内存大小 |
-Xmssize | 堆初始大小 |
-Xmxsize-XX:MaxHeapSize=size | 堆最大大小 |
-XX:MetaspaceSize=size | 元空间初始大小 |
-XX:MaxMetaspaceSize=size | 元空间最大可分配大小 |
-XX:-UseGCOverheadLimit | 关闭GCOverheadLimit特性 |
-XX:+PrintStringTableStatistics | 打印有关StringTable和SymbolTable的统计信息 |
-XX:+PrintGCDetails -verbose:gc | 控制台打印GC详情 |
-XX:StringTableSize=size | 设置串池的桶个数 |
-XX:+DisableExplicitGC | 显示的垃圾回收无效 |
-Xmnsize-XX:NewSize=size + -XX:MaxNewSize=size | 新生代大小 |
-XX:SurvivorRatio=ratio | 幸存区比例,radio:伊甸园占比 伊甸园:from:to=radio:1:1,默认是8:1:1 |
-XX:InitialSurvivorRatio=ratio -XX:+UseAdaptiveSizePolicy | 初始化比例 开启动态调整 |
-XX:MaxTenuringThreshold=threshold | 晋升阈值 |
-XX:+PrintTenuringDistribution | 晋升详情 |
-XX:+ScavengeBeforeFullGC | 开启 FullGC 前 MinorGC |
-XX:+UseSerialGC | 使新生代和老年代都使用串行回收器 |
8. 演示垃圾回收
虚拟机参数: -Xms20m -Xmx20m -Xmn10m -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc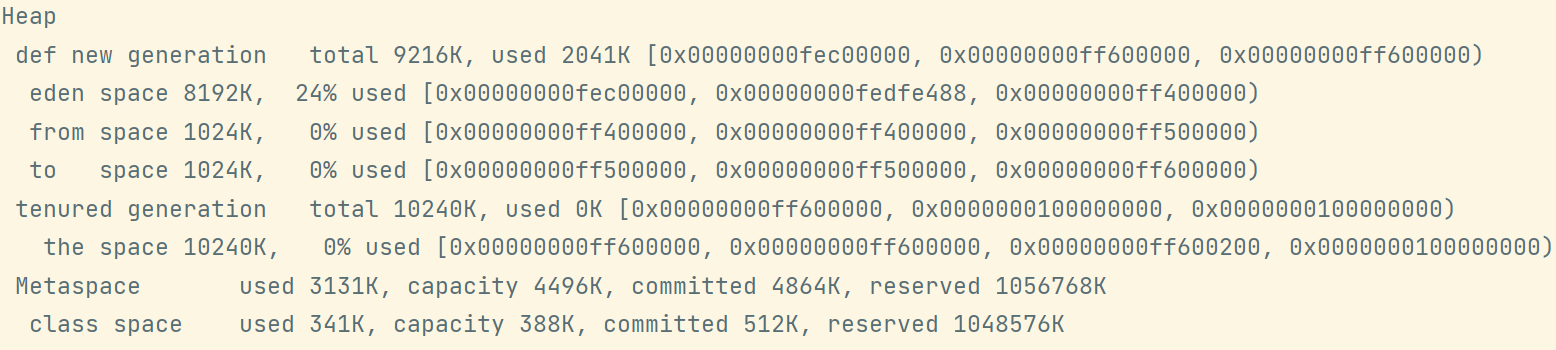
演示一:
public class TestPolicy {private static final int _512KB = 512 * 1024;private static final int _1MB = 1024 * 1024;private static final int _6MB = 6 * 1024 * 1024;private static final int _7MB = 7 * 1024 * 1024;private static final int _8MB = 8 * 1024 * 1024;public static void main(String[] args) throws InterruptedException {ArrayList<byte[]> list = new ArrayList<>();list.add(new byte[_7MB]);list.add(new byte[_7MB]);list.add(new byte[_1MB]);}}
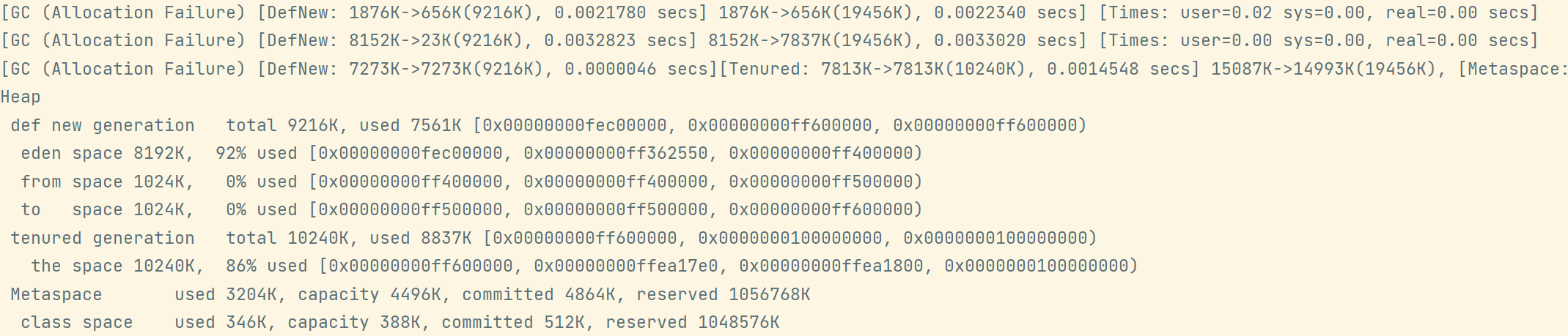
演示二:大对象(即内存超过伊甸园大小的对象)
这时候,大对象因为在新生代放不下了,就会直接晋升到老年代,所以不会触发 Minor GC
ArrayList<byte[]> list = new ArrayList<>();list.add(new byte[_8MB]);
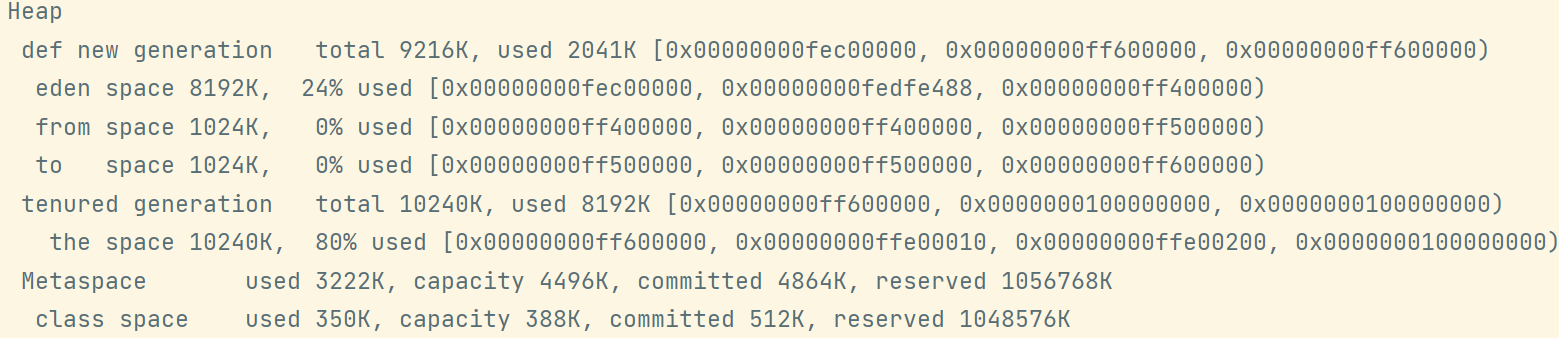
ArrayList<byte[]> list = new ArrayList<>();list.add(new byte[_8MB]);list.add(new byte[_8MB]);
新生代放不下了,老年代也放不下,所以会报错:
但还是会挣扎一下,触发一次 Full GC ,顺带 MInor GC,如果还是放不下,那就回报错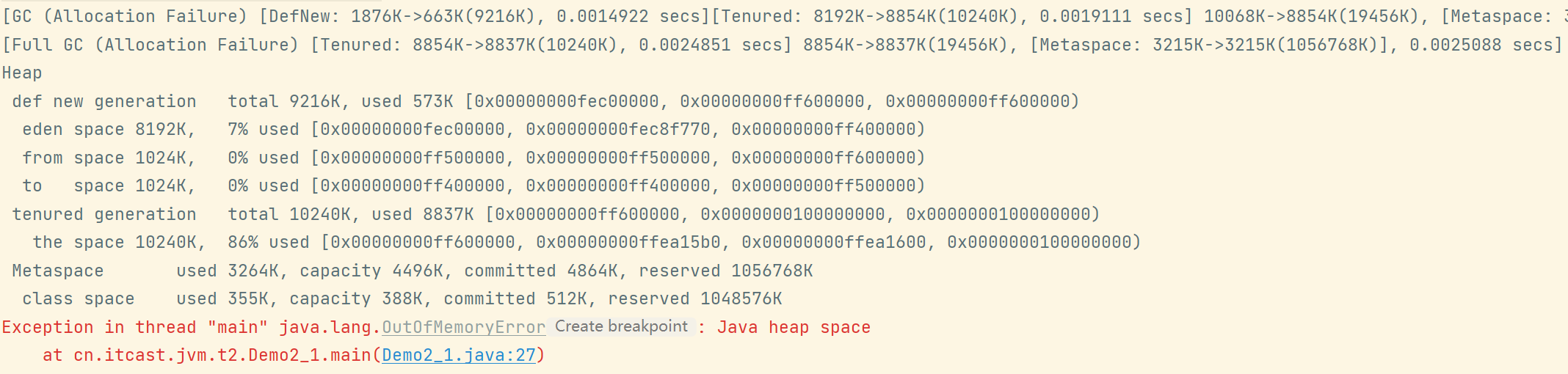
演示三:线程抛出OOM,不会影响其他线程运行
new Thread(() -> {ArrayList<byte[]> list = new ArrayList<>();list.add(new byte[_8MB]);list.add(new byte[_8MB]);}).start();System.out.println("sleep....");Thread.sleep(1000L);
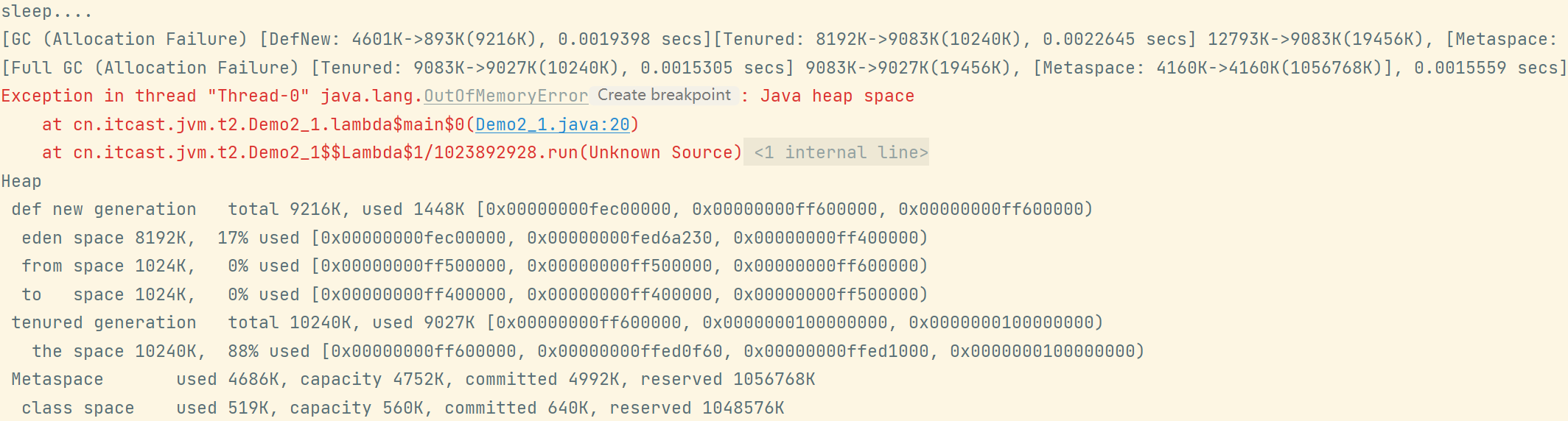
- 当一个线程抛出 OOM 之后,其占用的内存资源会被全部释放掉,因此不会影响到其他线程的运行
4. 垃圾回收器
1. 回收器分类
分类:
串行
- 单线程
堆内存较小、适合个人电脑
-XX:+UseSerialGC会同时启动 serial(新生代串行回收,复制算法)和serialOld(老年代串行回收,复制算法)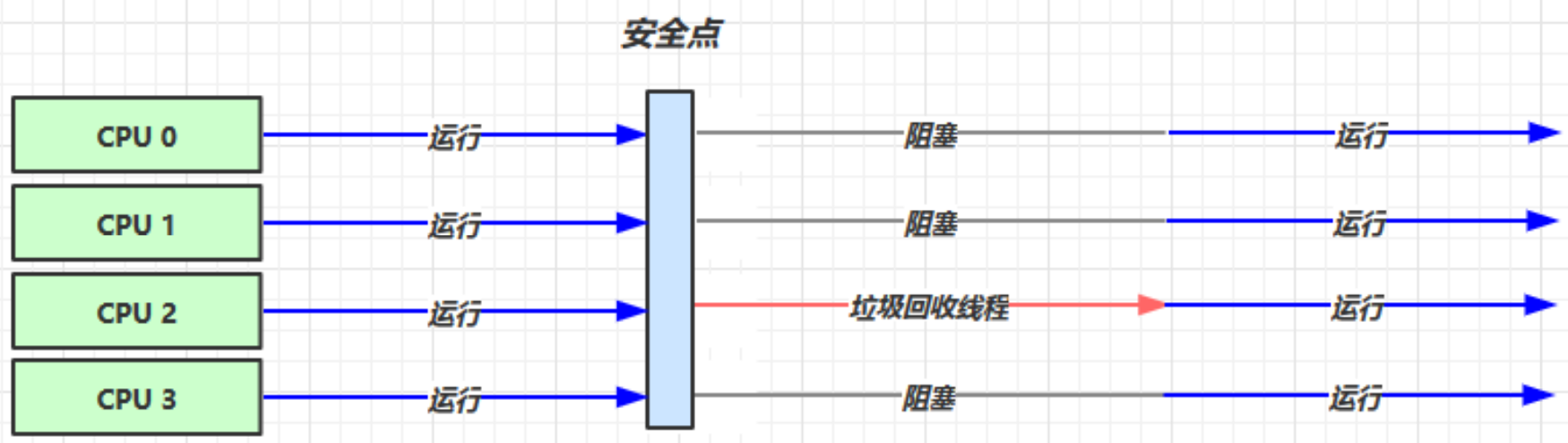
吞吐量优先
- 多线程
- 堆内存较大,多核CPU
让单位时间内,STW的时间最短(追求最快的速度)
jdk1.8默认使用的垃圾回收器
-XX:+UseParallelGC-XX:+UseParallelOldGC只需要开启其中一个,另外一个就会开启-XX:+UseAdaptiveSizePolicy采用自适应大小策略(新生代大小)XX:GCTimeRatio=radio 调整吞吐量(垃圾回收时间占比 = 1/(1+radio),一般采用 19)-XX:MaxGCPauseMillis=ms 垃圾回收最大暂停毫秒数(默认值200ms,会与 GCTimeRatio 冲突)-XX:ParallelGCThreads=n 设置垃圾回收线程数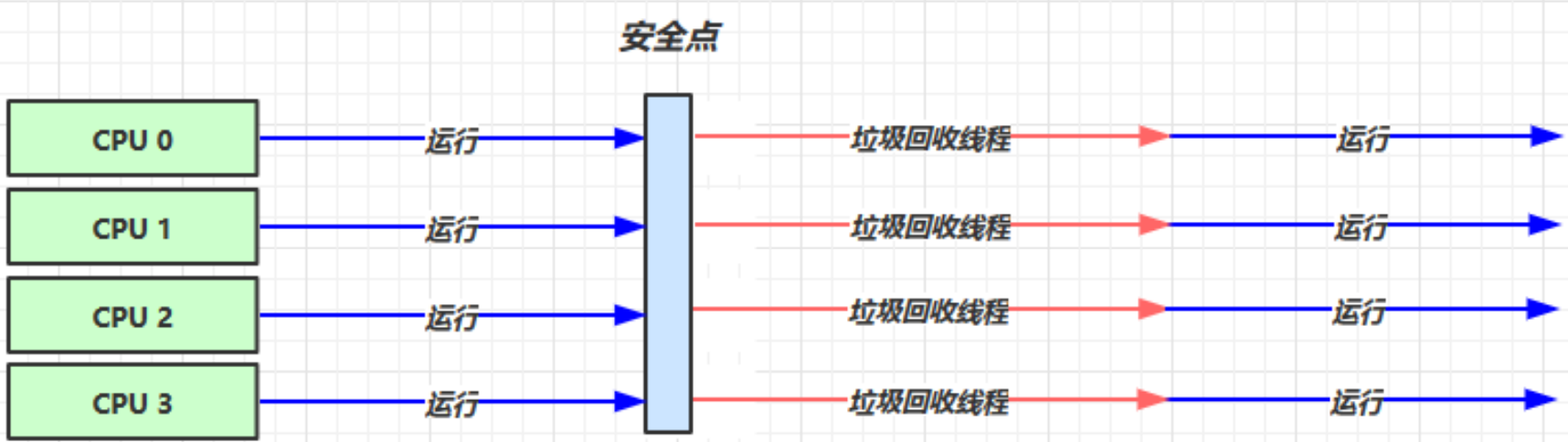
响应时间优先
- 多线程
- 堆内存较大,多核CPU
尽可能让单次STW(stop the world)时间最短(次数很多,单次速度很快)
-XX:+UseConcMarkSweepGC开启 并行并发CMS垃圾回收器(在垃圾回收的一些阶段,可以和用户进程一起运行)-XX:+UseParNewGC工作在新生代的复制算法回收器,和CMS一起工作的SerialOld当CMS并发失败时,CMS会退化到此串行垃圾回收器
-XX:ParallelGCThreads=n 指定并行 GC 线程的数量(最好与CPU核数相当)-XX:ConcGCThreads=threads GC并行时使用的线程数-XX:CMSInitiatingOccupancyFraction=percent 执行CMS垃圾回收的内存占比(默认65%开启CMS垃圾回收)-XX:+CMSScavengeBeforeRemark重新标记之前对新生代进行一次垃圾回收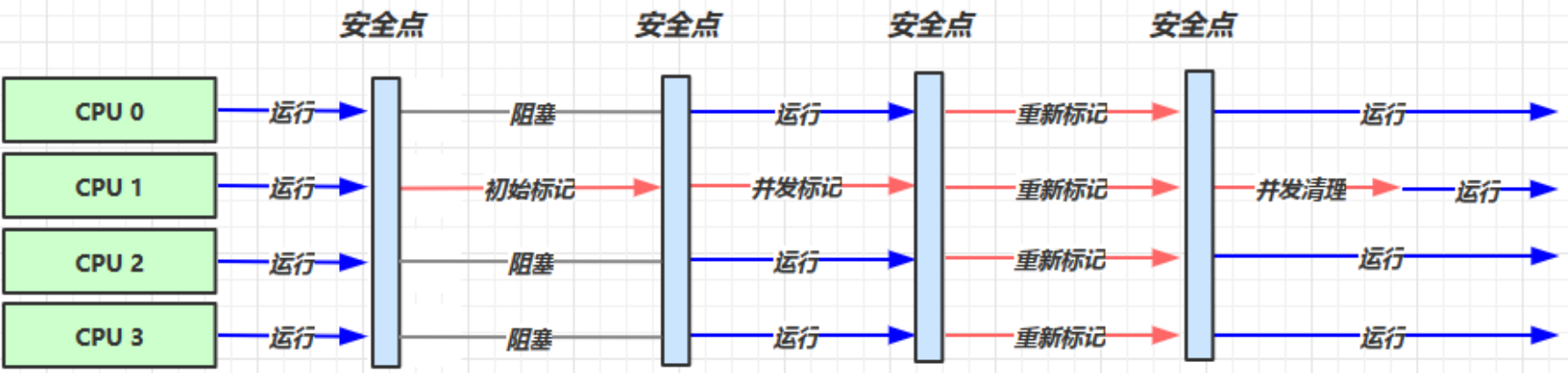
CMS采用标记清除算法,产生的碎片会比较多,导致并发失败,退化到SerialOld,然后处理好碎片之后再次回到CMS并发,这样退化的时候,会导致响应时间一下子变长。
2. G1
Garbage First
适用场景:
- 同时注重吞吐量(Throughput)和低延迟(Low latency),默认的暂停目标是 200 ms
- 超大堆内存,会将堆划分为多个大小相等的 Region
- 整体上是 标记+整理 算法,两个区域之间是 复制 算法
JVM 参数:
-XX:+UseG1GC开启-XX:G1HeapRegionSize=size 设置堆的region大小,2的次方-XX:MaxGCPauseMillis=time 垃圾回收最大暂停毫秒数(默认值200ms)
回收阶段:
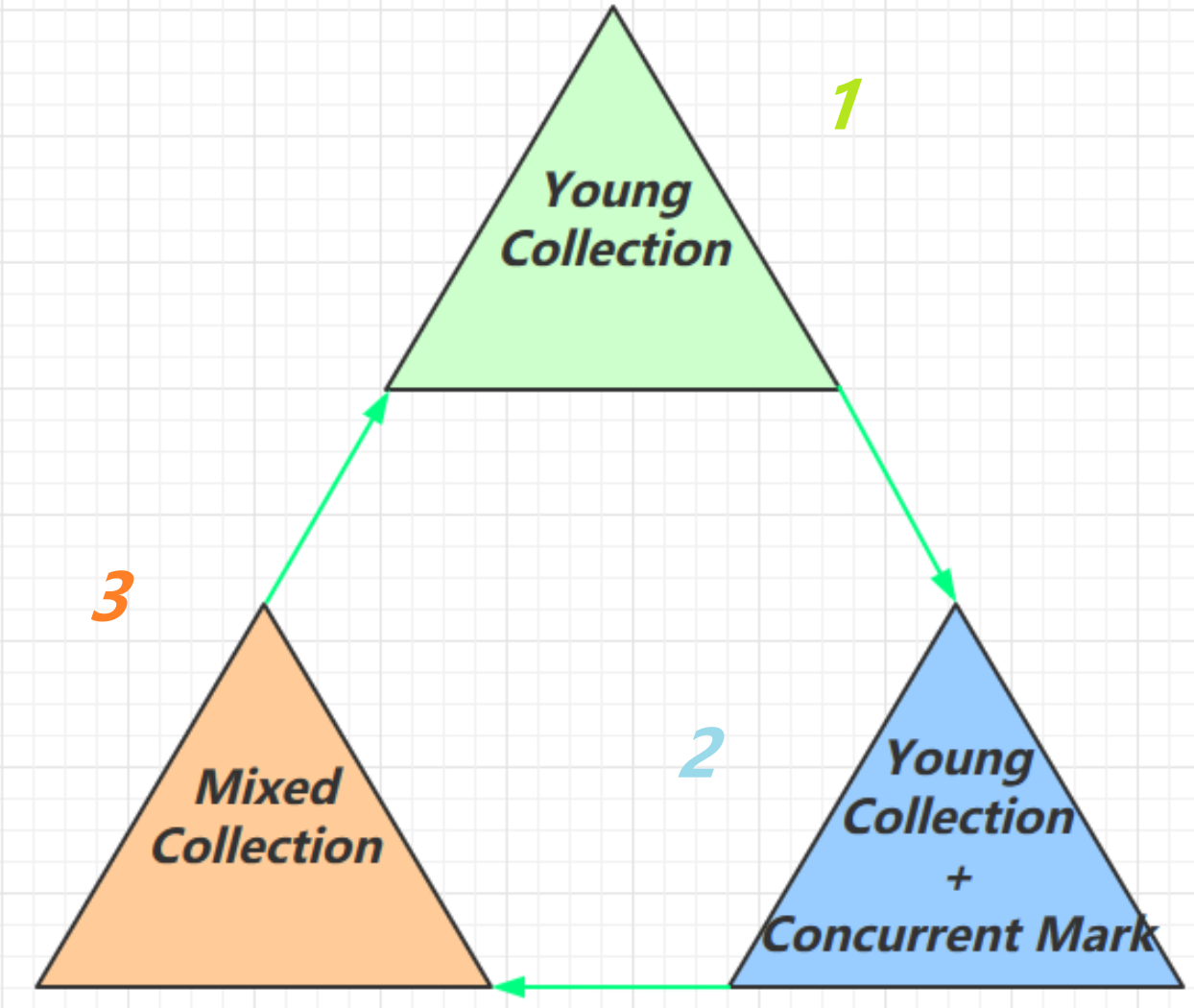
Young Collection
- 新建对象,存入伊甸园区域
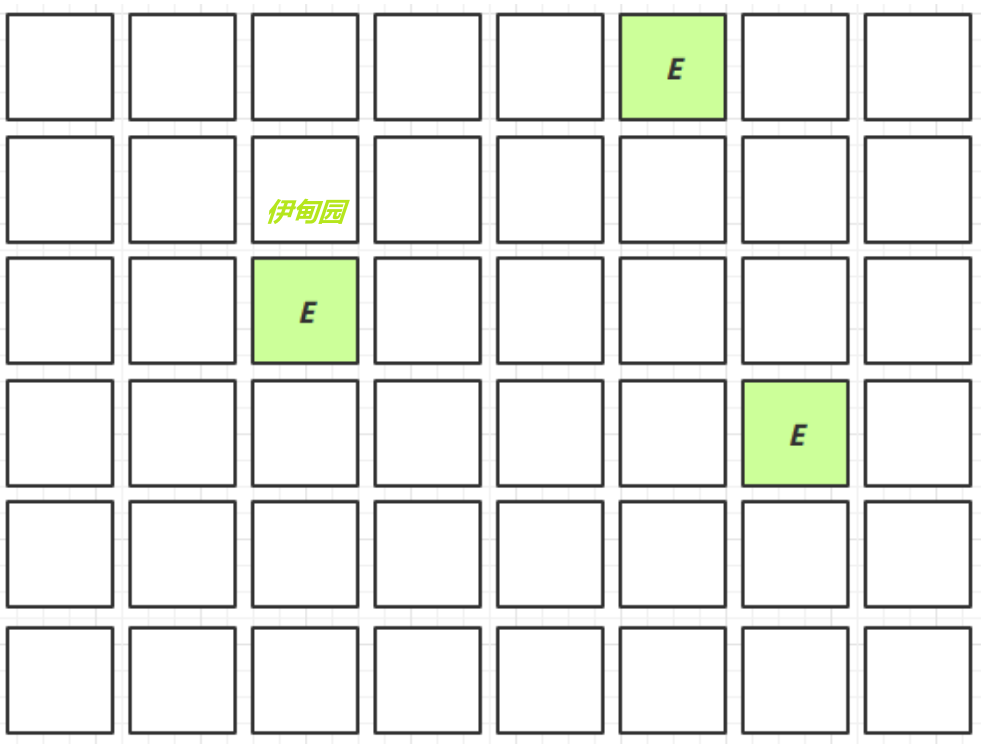
新生代的对象多了,就会存入幸存区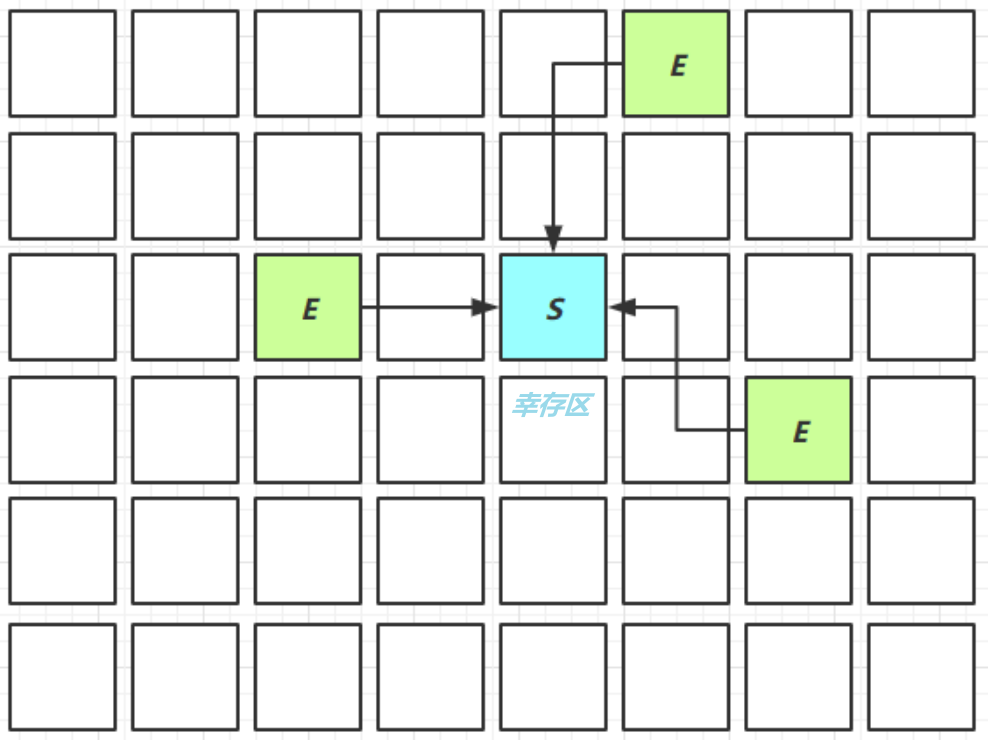
当伊甸园转不下了或者幸存区的对象年龄超过了阈值,就会进入老年代
- 新建对象,存入伊甸园区域
Young Collection + CM
- 在 Young GC 时会进行 GC Root 的 初始标记
- 老年代占用堆空间比例达到阈值时,进行 并发标记(不会 STW),由下面的 JVM 参数决定
-XX:InitiatingHeapOccupancyPercent=percent 默认45%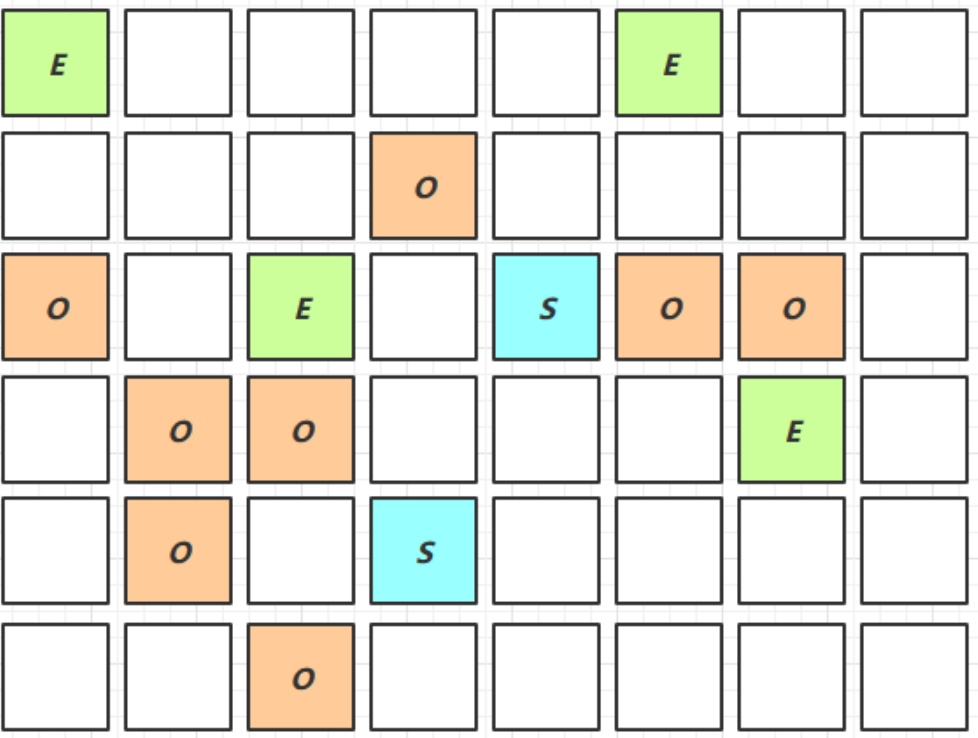
Mixed Collection
- 会对 E、S、O 进行全面垃圾回收
- 最终标记(Remark)会 STW
- 拷贝存活(Evacuation)会 STW
-XX:MaxGCPauseMillis=ms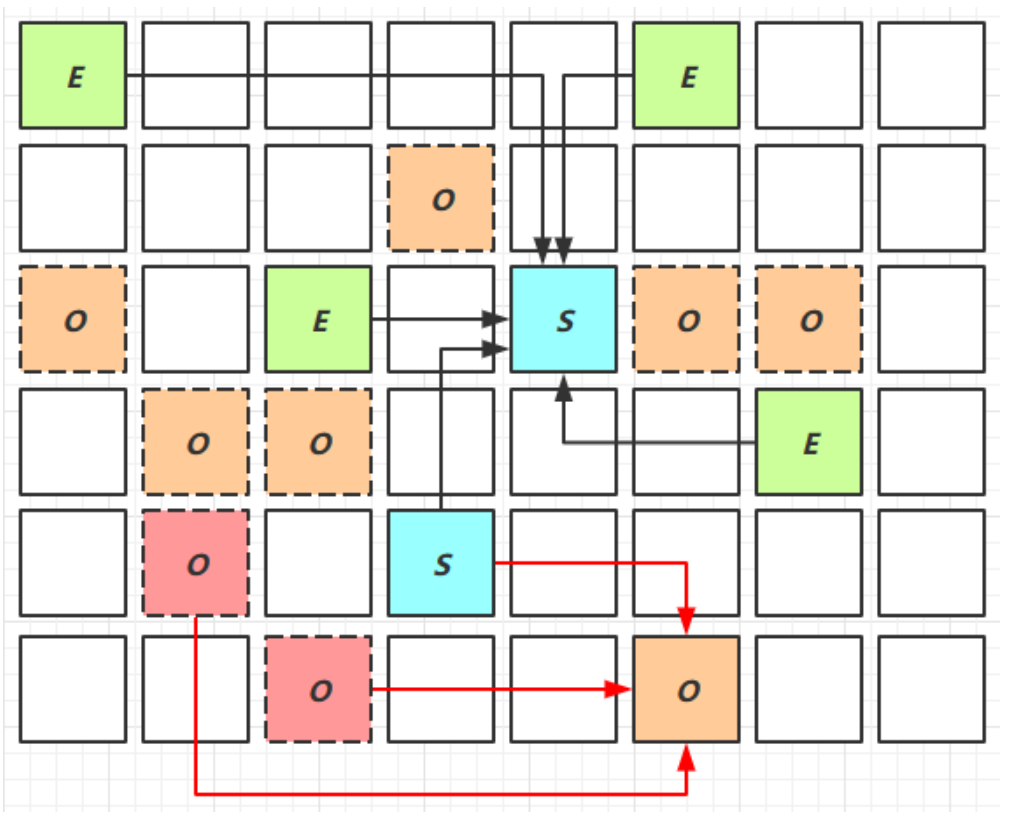
会回收那些内存占用较多的老年代。
Full GC
SerialGC
- 新生代内存不足发生的垃圾收集 - minor gc
- 老年代内存不足发生的垃圾收集 - full gc
ParallelGC
- 新生代内存不足发生的垃圾收集 - minor gc
- 老年代内存不足发生的垃圾收集 - full gc
CMS
- 新生代内存不足发生的垃圾收集 - minor gc
- 老年代内存不足发生 - full gc
G1
- 新生代内存不足发生的垃圾收集 - minor gc
- 老年代内存不足 - full gc
Young Collection 跨代引用
新生代回收的跨代引用(老年代引用新生代)问题
寻找老年代中引用了新生代的对象,为了方便查找,会将老年代划分为卡表(512k)
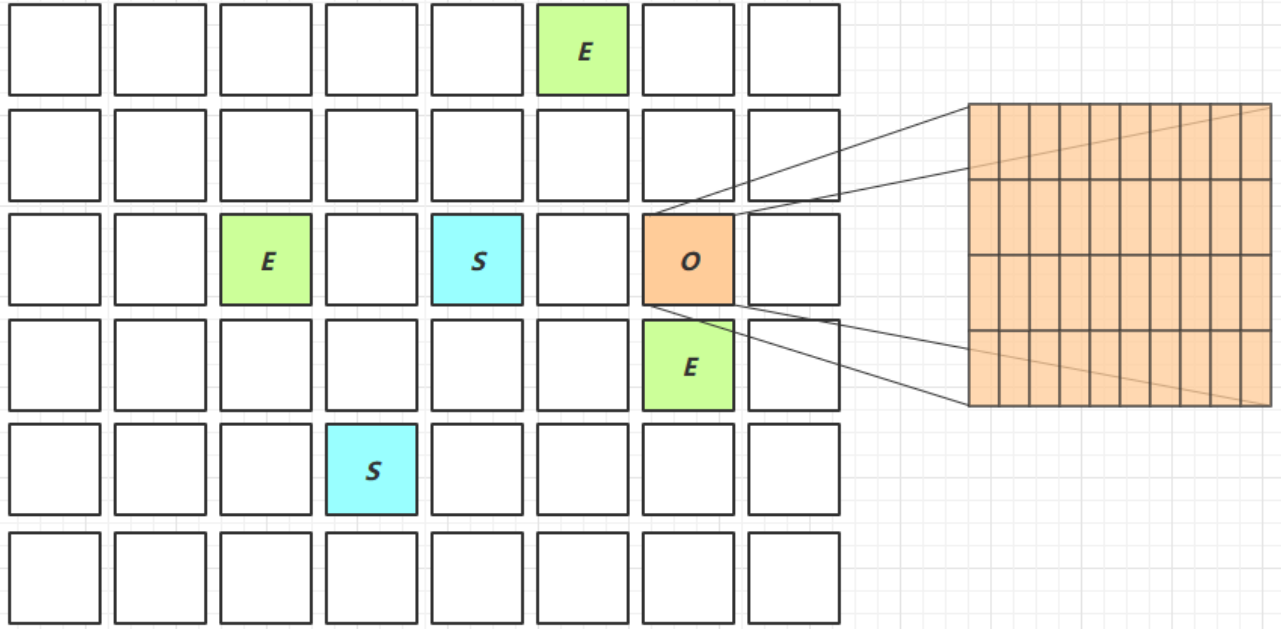
如果卡表中有对象引用了新生代,那么就称之为脏卡(dirty card)
而新生代这边,会有一个 Remembered Set 记录从外部对于新生代对象的引用
每次引用变更,都会通过 post-write barrier 和 dirty card queue 去更新脏卡,然后由 concurrent refinement threads 更新 Remembered Set
这样可以加快新生代的垃圾回收速度* **Remark**pre-write barriersatb\_mark\_queue![5beb9b115077472ab215f7d54733bfc4.png][]没被remark的对象,如果没有被强引用引用,就会被回收
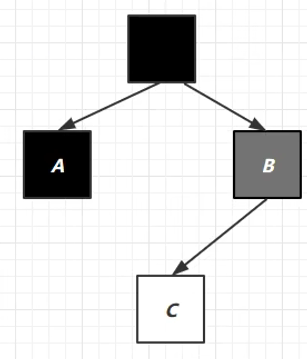
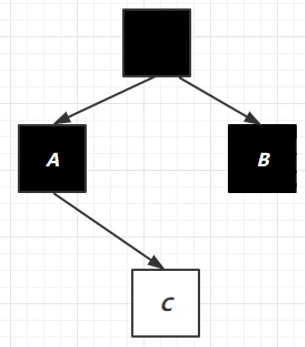
在并发环境中,对象C先被B引用,又被A引用,如下图:
因为C之前已经处理过了,所以A引用的时候不再remark,故而C就会被清理
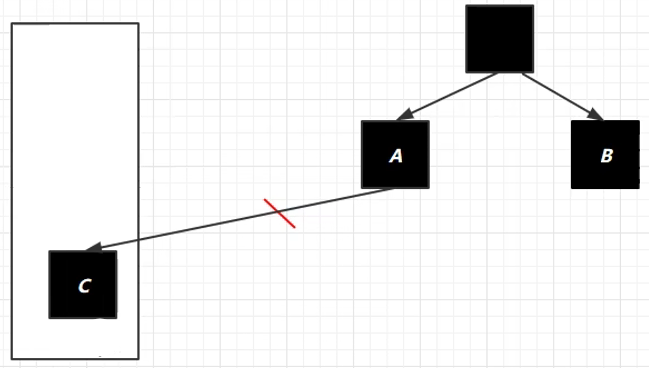
为了防止上述情况,在对象引用发生改变时,JVM就会给对象添加上写屏障(对象引用发生改变,写屏障代码就会执行)
写屏障指令执行之后,就会将C加入到一个队列中,并将其置于 待处理 状态,然后进行 remark ,发现有强引用引用着C,就将其变成黑色


JDK 8u20 字符去重
- 优点:节省大量内存
- 缺点:略微多占用了 CPU 时间,新生代回收时间略微增加
vm options:
-XX:+UseStringDeduplication- 将所有新分配的字符串放入一个队列
- 当新生代回收时,G1并发检查是否有字符串重复
- 如果它们值一样,让它们引用同一个 char[]
不同于
str.intern(), str.intern() 关注的是字符串对象
字符串去重关注的是 char[],在 JVM 内部,使用了不同的字符串表
JDK 8u40 并发标记类卸载
- 所有对象都经过并发标记后,就能知道哪些类不再被使用,当一个类加载器的所有类都不再使用,则卸载它所加载的所有类。
- vm options:
-XX:+ClassUnloadingWithConcurrentMark默认开启
JDK 8u60 回收巨型对象
- 一个对象大于 region 的一半时,称之为巨型对象
- G1 不会对巨型对象进行拷贝
- 回收时被优先考虑
- G1 会跟踪老年代所有 incoming 引用,这样老年代 incoming 引用为 0 的巨型对象就可以在新生代垃圾回收时处理掉
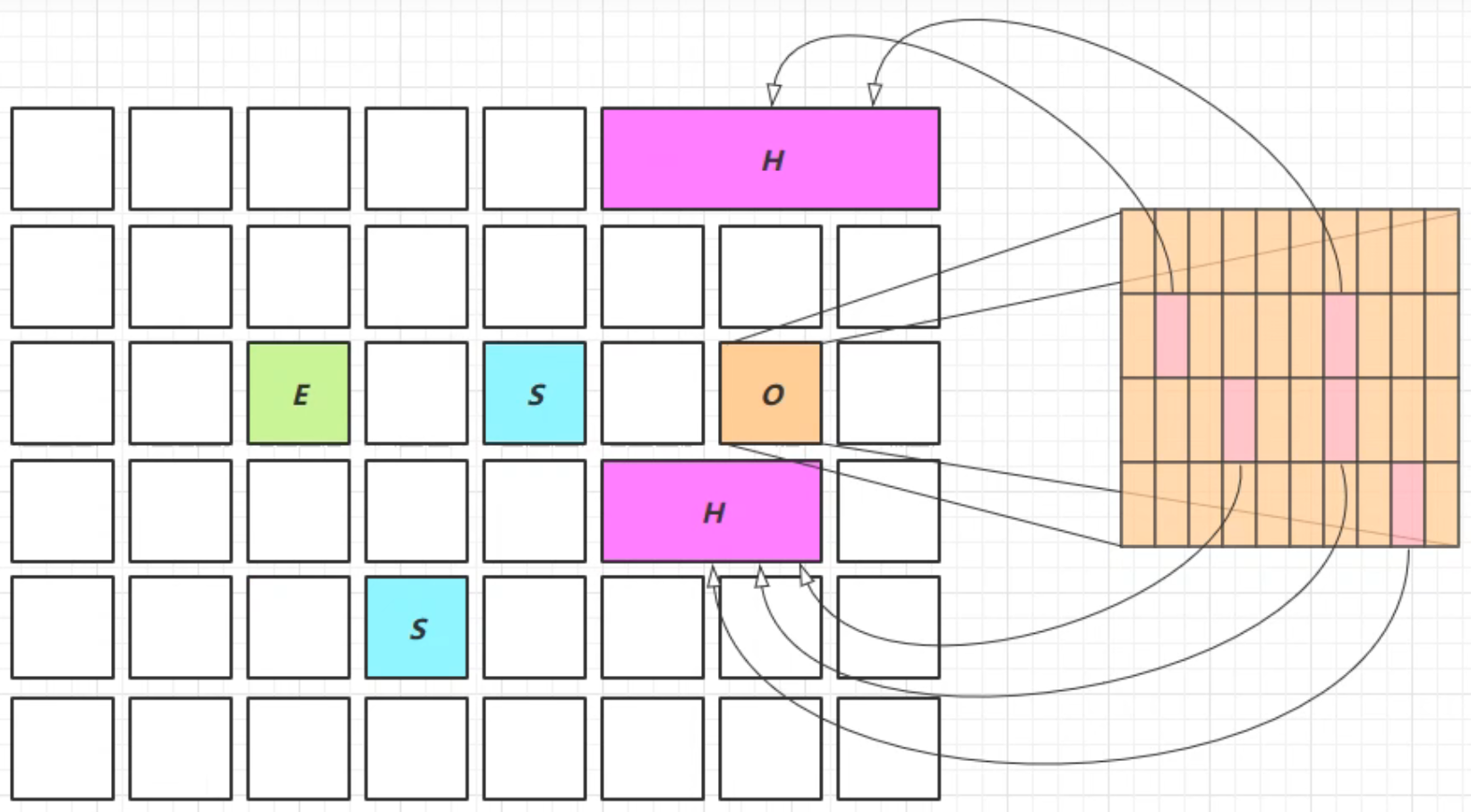
总之,巨型对象越早回收越好。
JDK 9 并发标记起始时间的调整
- 并发标记必须在堆空间占满前完成,否则退化为 FullGC
- JDK 9 之前需要使用
-XX:InitiatingHeapOccupancyPercent老年代回收阈值(并发标记) JDK 9 可以动态调整阈值
-XX:InitiatingHeapOccupancyPercent用来设置初始值- 进行数据采样并动态调整
- 总会添加一个安全的空档空间
Java se官方文档
"D:\Java\jdk1.8.0_202\bin\java" -XX:+PrintFlagsFinal -version | findstr "GC" 打印垃圾回收的虚拟机参数


































还没有评论,来说两句吧...