Redis介绍及5种数据类型的使用
目录
Redis 介绍
基础知识
正反向索引
Redis-String
Redis-List
Redis-Hash
Redis-Set
Redis-SortedSet
Redis 介绍
redis是内存中的数据结构存储系统,可用于数据库、缓存、消息中间件。数据结构有string、hashes、lists、set、zset,其中string可以为字符,数值(bitmaps)
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence),并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
redis与memcache比较:
1) memcache的value没有类型的概念,获取k对应的value值时,返回value的所有数据到client,client要有实现的代码去解码.
2) 类型不是很重要 Redis的server中对每种类型都有自己的方法 index() ipop。
问题:客户端通过一个缓存系统 取回value中某一个元素?
memcached:返回value所有的数据到clent server 网卡IO、clent要有你实现的代码去解码
Redis:类型不是很重要 Redis的server中对每种类型都有自己的方法 index() ipop
基础知识
磁盘
寻址:ms
带宽:G/M
内存:
寻址:ns
带宽:很大
数据和磁盘体积不一样
在寻址上磁盘比内存慢了10W倍
I/O buffer:成本问题
磁盘与磁道,扇区,一扇区512Byte带来一个成本变大的问题:索引很多
4k 操作系统,无论你读多少,都是最少4k从磁盘拿
1) 当磁盘上数据越来越大时,访问磁盘数据的速度会越来越慢,因为受制于磁盘I/O瓶颈
2) 大量数据存放在数据库中,数据在数据库存是分为一个一个4k的数据块,正好与系统I/O最小读数据大小4k相对应,完全不浪费系统I/O资源。
3) 为了提高数据库访问效率,引入索引对象,索引就是将表中字段有索引标记的数据的那列放在索引块中,也是一个一个4k存储,索引块中的数据指向数据库表中标记的行数据。
4) 表数据和索引都是存在磁盘,B+T放入内存中,当有一个用户查询语句过来,where子句命中索引的话,先到B+T这个树干,然后树干找到索引页,将索引页数据放到B+T内存,然后通过索引可以找到数据块并放入内存中返回用户。
5) 数据库建表时要给出schema(有多少列,每个列是什么类型),字段类型就是字段宽度,这样在建表的时候就定死了每一行要存储的宽度,表存储时是行级存储,这样有个好处。
比如说有一张表10个字段,每个字段4个字节,当我插入两个字段后,其他8个字段值会占位填充,这样当后面进行增删改时就不需要移动数据,就在字段位置上赋值就行。
数据库量变大性能下降怎么解释
如果表有索引,增删改会变慢,因为增删改表里的数据多少,会调整索引的位置,也就是会维护索引,所以会变慢。
查询速度:
- 1个或少量查询速度依然很快
- 并发大的时候会受硬盘带宽速度影响
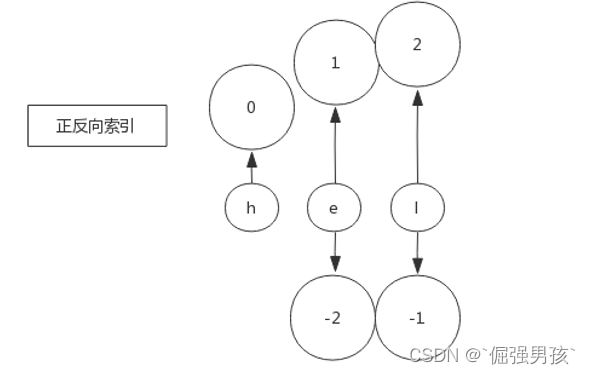
正反向索引
Redis-String
分为:字符串、数值、bitmap(位图)
string 的编码有三种:int、raw、embstr
- int:用来保存整数值;存储 8 个字节的长整型(long,2^63-1)。
- raw:用来保存长字符串;存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)
- embstr:用来保存短字符串;代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),存储小于 44 个字节的字符串。
- 当 int 编码保存的值不再是整数,或大小超过了long的范围时,自动转化为raw。对于 embstr 编码,由于 Redis 没有对其编写任何的修改程序(embstr 是只读的),在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。

字符串
- set key value [NX|XX] 设置一个key(判断key是否存在,NX新建;XX更新)
- get key 获取key对应value值
- mset k1 v1 k2 v2 设置多个key
- mget k1 k2 k3 …. 获取多个key的value
- msetnx k1 v1 k2 v2 设置多个key(原子性)
- append k “ world” 字符串基础上进行追加
- getrange k 0 1 根据索引正向获取
- getrange k 0 -1 根据索引反向获取
- strlen key 获取长度
- type key 返回key对应value的类型
- getset key aaa 替换旧值
数值
- incr key 自增1
- incrby key 5 自增指定数量
- decr key 自减1
- decrby key 5 自减指定数量
- incrbyfloat key 0.5 增加浮点型
bitmap(位图)
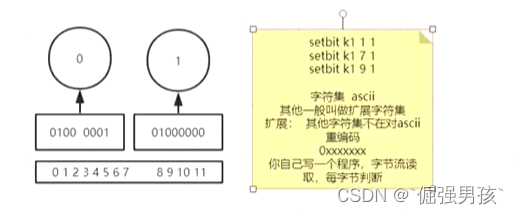
setbit k1 1 1: 即 01000000 -> 对应ASCII码: @
setbit k1 7 1: 即 01000010 -> 对应ASCII码: A
setbit k1 9 1: 即 01000010 01000000 get k1为: A@
bitpos:查找0或1第一次出现的二进制位置
bitpos k1 1 0 0:返回1;0 0 代表第一个字节
bitpos k1 1 1 1:返回9;1 1 代表第二个字节
bitpos k1 0 1 :返回1;0 1 代表全量,默认查找二进制位1
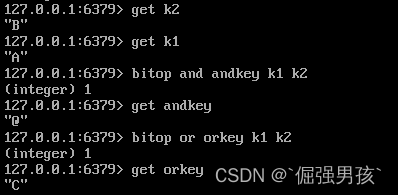
当 A:01000001;B:01000010 bitop and andkey k1 k2:k1与k2按位与运算
get andkey:返回@; 有0则0
bitop or orkey k1 k2:k1与k2按位或运算
get orkey:返回C;有1则1
- bitcount k1 0 1:获取两个字节中有几个1
bitmap 应用场景1:
用户系统统计用户登录天数且窗口随机
- 如果用传统的MySQL关系型数据库实现,但是在数据量巨大用户量的需求下,显然太耗费空间与性能。
redis 实现:
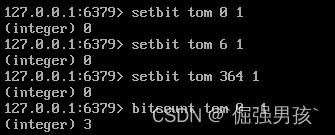
setbit tom 0 1 : tom第1天登录
setbit tom 6 1 : tom第7天登录
setbit tom 364 1 : tom第365天登录统计tom一年的登录天数:bitcount tom 0 -1
占用空间:每个人365/8=46B;假设一千万用户,则需要46B*10000000=460M
bitmap 应用场景2:
假设电商平台(2亿用户)过节大促,给每个当天登录的用户都发放一份礼物,求需要多少份礼物?(即:活跃用户统计)
将上面的k v 反转即可
即:日期作为key 登录的 userId 为 value
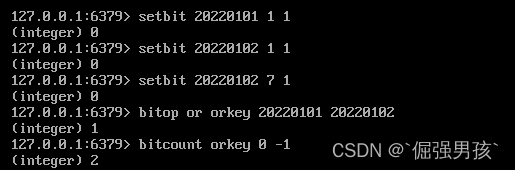
- setbit 20220101 1 1:2022年1月1日 id为1的登录了
- setbit 20220102 1 1:2021年1月2日 id为1的登录了
- setbit 20220102 7 1:2022年1月2日 id为7的也登录了
统计这两天的登录用户数:
bitop or orkey 20220101 20220102
bitcount orkey 0 -1
Redis-List
有序(插入)、可重复
- 按顺序将values添加到list中
lpush [key] [values] 从左到右
rpush [key] [values] 从右到左例:lpush k1 a b c d 输出:d c b a
- lpop [key] 弹出最后一个元素
rpop [key] 弹出第一个元素- lrange k1 0 -1 获取所有value
- lindex k1 2 根据索引获取对应value
- lset k1 2 xx 覆盖索引对应value
- lrem k1 1 a 由正向移除一个a元素
- linsert k1 before/after a b 从a元素之前或之后插入元素b
- 阻塞、单播队列(先进先出)
blpop k1 2 2代表阻塞2秒钟
blpop k1 0 0代表一直阻塞- ltrim k1 0 1 删除两个位置两端以外的数据
Redis-Hash
对数值进行计算
场景:点赞、收藏、详情页
- hset key name value 存入一个k、v
- hmset key name value age value 存入多个k、v
- hget name age 根据多个k获取多个v
- hkeys key 获取所有k
- hvals key 获取所有v
- hgetall key 获取所有k、v
- hincrbyfloat key age -1 数值计算
Redis-Set
无序、去重
集合操作
随机事件
- sadd k a b c c 设置k
- smembers k 取所有值去重 a b c
- srem k a b 移除
- sinter k1 k2/sinterstore dest k1 k2 取交集
- sunion k1 k2 并集去重
- sidff k1 k2 取k1,k2参考,差集
- srandmember k1 count count可以为正数和负数
count为正数,返回从k1中取count的数量出来,且不重复(场景:抽奖,人多奖品少)
count为负数,返回count数量,但是会重复(场景:抽奖,人少奖品多,人可以重复)- spop k1 取出一个数,并且k1删除这个数(场景:抽奖人不能重复抽)
Redis-SortedSet
元素 、排名、 分值
物理内存左小右大
- zadd k1 8 apple 6 banana 3 orange 三个元素,分值分别为8 6 3
- zrange k1 0 -1 取出k1所有元素,排名根据分值由小到大排列
- zrevrange k1 0 -1 反向排名,分值从大到小排列
- zscore k1 apple 获取apple的分值
- zrank k1 apple 获取apple的排名
- zrange k1 0 -1 withscores 取所有元素并加上分值
- zincrby k1 0.5 apple 将apple的分值增加0.5
- zunionstore dest 2 k1 k2 默认是sum求和,没有权重
- zunionstore dest 2 k1 k2 weights 1 0.5 aggreate max 求交集
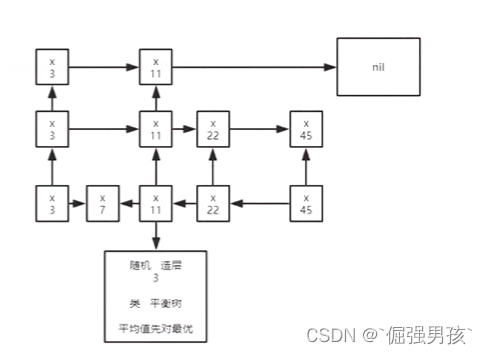
排序是怎么实现的,增删改查的速度?
skip list结构:跳跃表
牺牲存储空间来获取查询效率,随机造层
保证每一层是上一层节点数的一半
参考:【闲聊杂谈】聊一聊Redis中的Sorted Set_FeenixOne的博客-CSDN博客_sortedset 随机



























")






还没有评论,来说两句吧...