【编译原理】介绍
1. 为什么需要编译器
1.1 什么是编译器
编译器的定义:一种计算机程序,它能将一种语言翻译成另一种语言。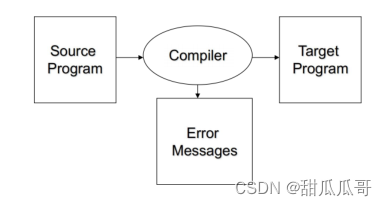
编译器是一个复杂的程序
编译器用于多种形式的计算(命令行解释器,接口程序)
1.2 什么是编译
编译的过程就是将高级语言翻译成汇编语言或者机器语言的过程。(记住:计算机只能识别二进制数据)
高级语言:易于书写和理解,但必须高效、简单地表达复杂的数学公式。
汇编语言:例如MOV X,2
机器语言:例如C706 0000 0002
意思是:将数据0002存储到地址为0000的存储器中。(C706是操作码,0002是操作数)
问题是:不易书写,难以阅读/理解。
1.3 编译器
1.4 编程语言
低级编程语言:
- 与机器有关的
- 机器语言(例如100100111)
- 汇编语言
- 面向机器的程序设计语言
高级编程语言:机器无关语言(C, C++,Java)
1.5 编译的功能
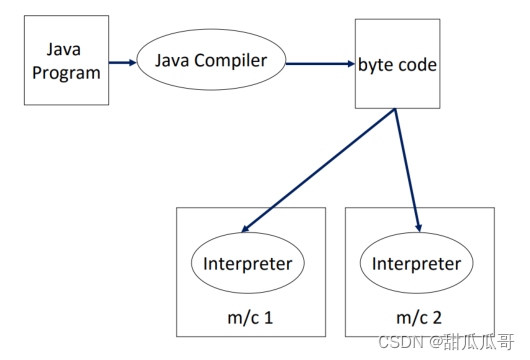
编译器和解释器的区别:
编译器的作用:把某种编程语言写成的源代码转换成另一种编程语言。
解释器的作用:能够把高级编程语言一行一行直接转译运行。
表示编程语言单词结构的符号方法有:
- 有限自动机
- 正则表达式
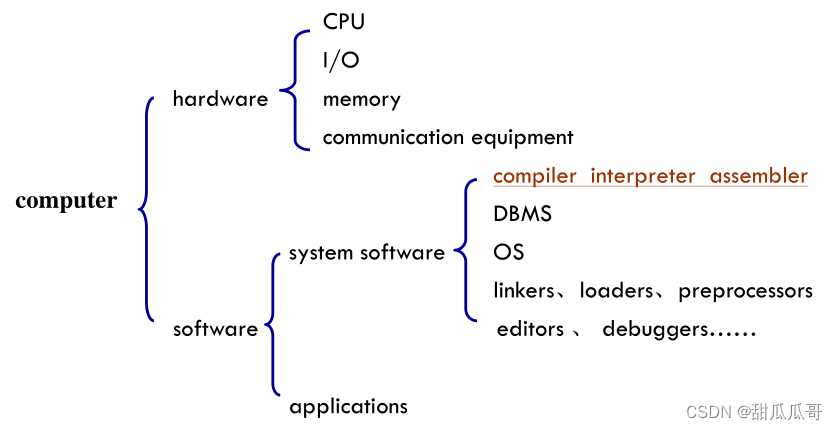
2 与编译器相关的程序
2.1 解释器
- 立即执行源程序,而不是生成目标代码。
- 执行速度比编译代码慢10倍或更多。
- 与编译器共享他们的许多操作。
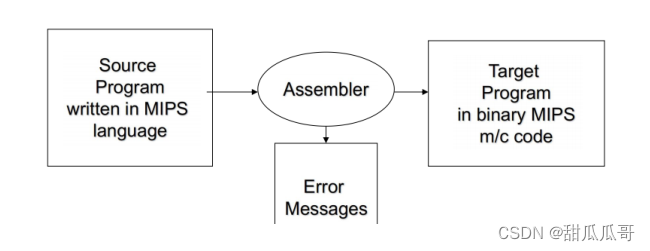
2.2 汇编器
- 特定计算机汇编语言的翻译器。
- 汇编语言是一种机器语言的符号形式。
- 编译器可以生成汇编语言作为其目标语言,而汇编器则完成了对目标代码的翻译。
- 汇编器比编译器要简单得多。
- 它们确实有共同的特点,因为它们都必须从源代码转换到目标代码。
2.3 替代编译器方案
- 编译到机器代码
- 解释
- 汇编语言输出
- 中间代码输出
- 来自预处理器的输入
- 加载程序直接使用的输出,或链接编辑器与其他代码组合使用的输出
2.4 链接器
- 将单独的对象文件收集到一个可直接执行的文件中。
- 将目标程序连接到标准库函数的代码和OS提供的资源。
- 成为编译器的主要活动之一,取决于操作系统和处理器。
2.5 加载器
解析相对于给定基的所有可重新定位地址。
使可执行代码更灵活。
通常作为操作环境的一部分,很少作为实际的单独程序。
2.6 预处理器
删除注释,包括其他文件,并执行宏替换。
语言(如C语言)所需,或者可以在以后添加提供额外功能的语言。
2.7 编辑器
编译器已与编辑器和其他程序捆绑在一起,成为一个交互式开发环境(IDE)。
面向编程语言的格式或结构,称为基于结构。
可能包括编译器的一些操作,通知一些错误。
2.8 调试器
用于确定编译程序中的执行错误。
跟踪大多数或所有源代码信息。
在预先指定的称为断点的位置停止执行。
编译器必须提供适当的符号信息。
2.9 配置文件
收集执行过程中对象程序行为的统计信息:
- 每个过程的调用时间
- 执行时间百分比
用于提高程序的执行速度
2.10 项目经理
协调不同人员处理的文件,维护程序的一致版本。
语言独立或与编译器捆绑在一起。
Unix系统上两个流行的项目管理程序:
- Sccs(源代码控制系统)
- Rcs(修订控制系统)
3 翻译过程
3.1 六个阶段
词法分析器 (Scanner/ lexcial analyzer)
语法分析器 (Parser/ syntax analyzer)
语义分析
源代码优化器
代码生成器
目标代码优化器
3.2 三个辅助部件
文字表
符号表
错误处理程序
" class="reference-link">3.3 编译器的阶段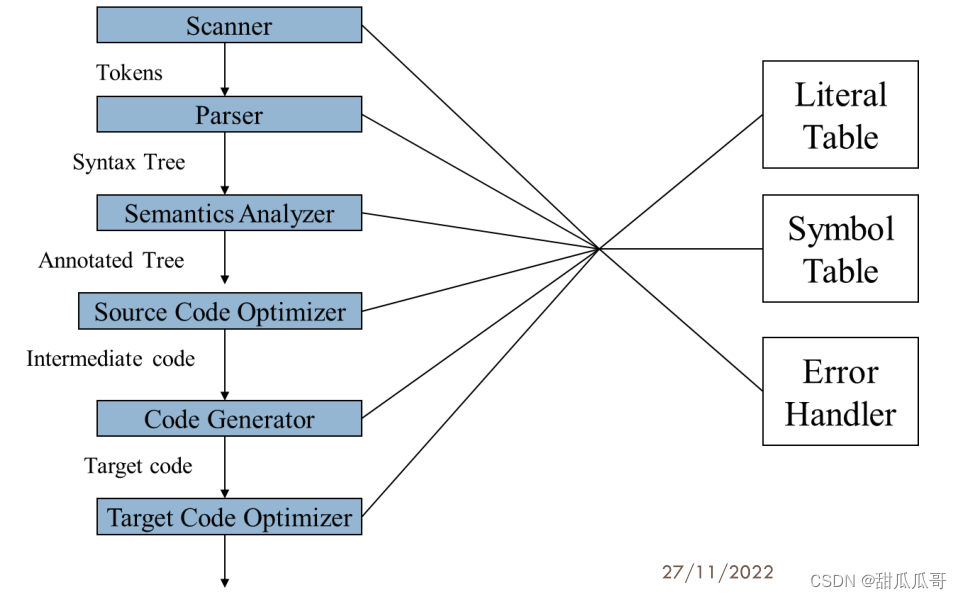
词法分析:识别句子中的所有单词
语法分析:分析句子的结构 (人,动词,宾语,从句)
语义分析:分析句子的“含义”
根据句子的意思翻译:中间代码生成
优化翻译句子:优化 (例如:添加 了,过,着 等等)
给出最后的翻译句子:目标代码生成
3.4 词法分析器
词法分析器(Scanner/ Lexical analyzer):它将字符序列收集成有意义的单位,称为令牌。
We: pron, studied: verb… (We和studied都是token)
3.5 语法分析器
语法分析器 (Parser/ Syntax analyzer):它决定了程序的结构。语法分析的结果是解析树或语法树。
例子: a[index]=4+2
解析树: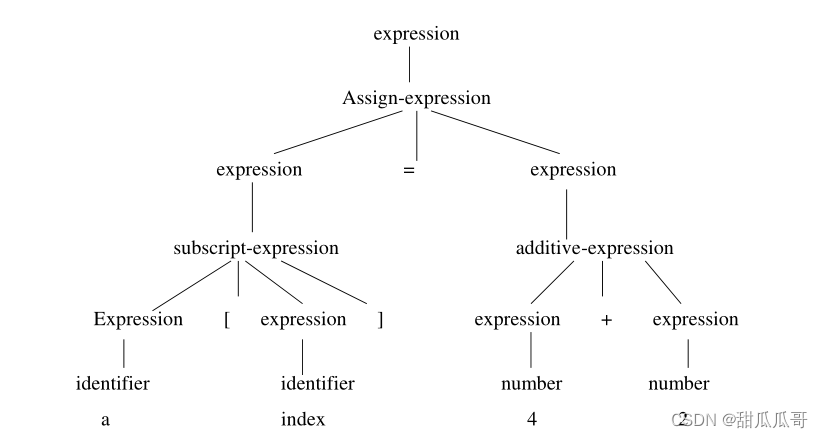
语法树: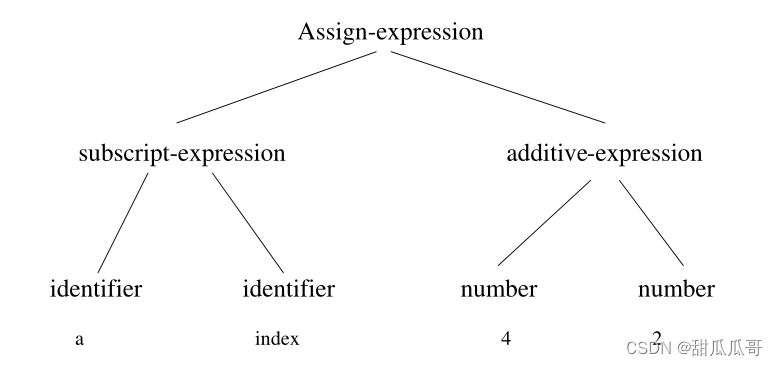
3.6 语义分析器
程序的语义是其“含义”,而不是其语法或结构,即在执行之前确定其某些运行时行为。
静态语义:声明和类型检查
属性:语义分析器计算的额外信息。
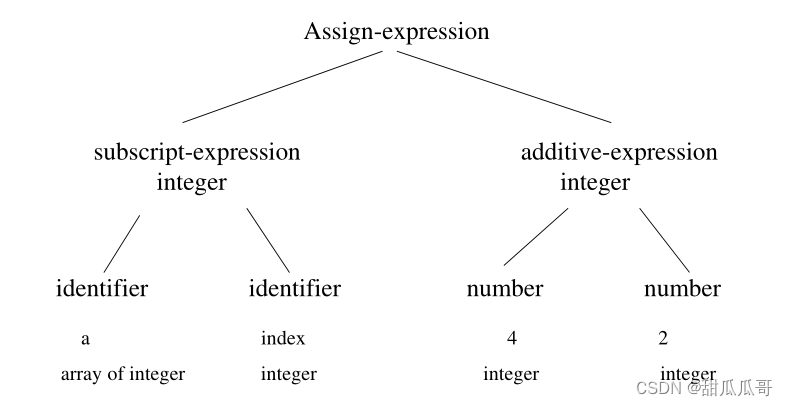
例子: a[index]=4+2
注释语法树: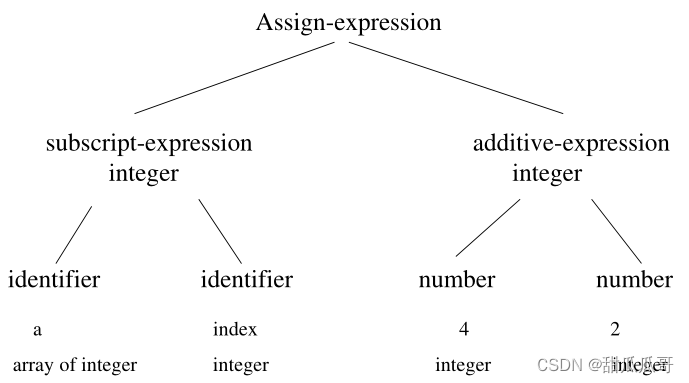
3.7 源代码优化器
大多数优化步骤的最早点是在语义分析之后。
代码改进仅取决于源代码,并作为一个单独的阶段。
单个编译器在优化类型和布局方面表现出很大的差异。
例子:a[index] = 4 + 2
- 直接在带注释的树上执行常量折叠
- 使用中间码:三地址码、p码
3.8 注释树的优化
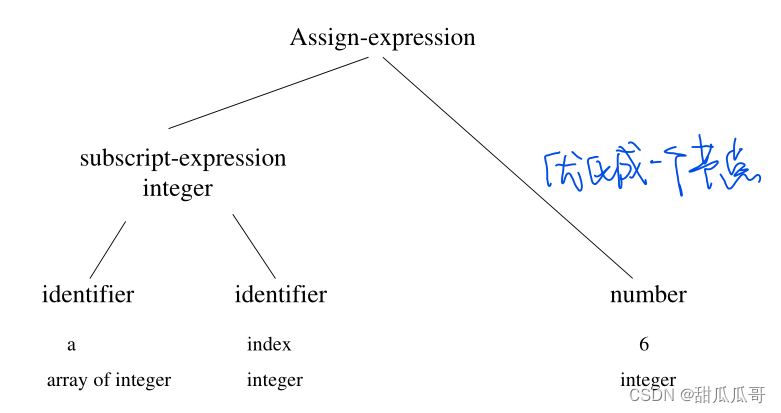
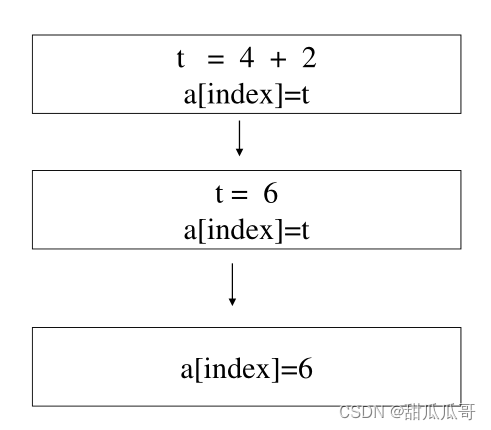
3.9 中间代码优化
3.10 代码生成
它接受中间代码或IR(指令寄存器)并为目标机器生成代码。
目标机器的特性成为主要因素:使用说明和数据表示
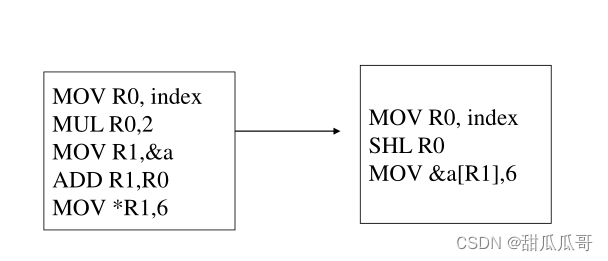
例如:a[index] = 4+2 (假设汇编语言中的代码序列)
一种可能的代码序列: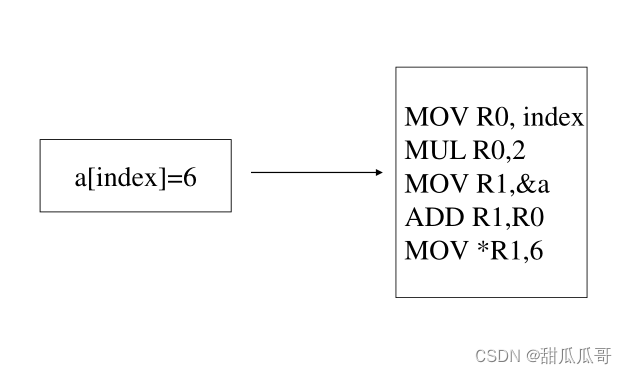
3.11 目标代码优化器
它改进了代码生成器生成的目标代码:
- 地址模式选择
- 指令更换
- 以及冗余消除
4 编译器中的主要数据结构
4.1 阶段间通信的主要数据结构
4.1.1 TOKENS
词法分析器将字符收集到令牌中,作为TOKEN的枚举数据类型的值。
还可以保留字符串或其他派生信息,例如标识符的名称、数字标记的值。
单个全局变量或令牌数组。
4.1.2 语法树
解析器生成的基于指针的标准结构。
每个节点表示解析器或更高版本收集的信息,这些信息可以动态分配或存储在符号表中。
根据语言结构的类型,节点需要不同的属性,这些属性可以表示为变量记录。
4.1.3 符号表
保存与标识符相关的信息:函数、变量、常量和数据类型。
几乎与编译器的每个阶段交互。
访问操作需要恒定时间。
经常使用一个或多个哈希表。
4.1.4 文字表
存储常量和字符串,减少程序的大小。
快速插入和查找至关重要。
4.1.5 中间代码
保存为文本字符串数组、临时文本或结构链接列表,取决于中间代码的类型(例如三地址代码和p代码)。
应该易于重组。
4.1.6 临时文件
保存编译期间中间步骤的乘积。
解决代码生成过程中内存限制或反补丁问题。
5 编译器结构中的其他问题
5.1 编译器的结构
不同角度的多个视图:
- 逻辑结构
- 物理结构
- 操作顺序
结构的主要影响
- 可靠性、效率
- 有用性、可维护性
5.2 分析和合成
编译器的分析部分分析源程序以计算其属性
- 词汇分析、语法分析和语义分析以及优化
- 更多的数学知识和更好的理解
编译器的合成部分生成翻译的代码
- 代码生成和优化
- 更专业化
这两个部分可以彼此独立地更改。
5.2.1 分析部分
词汇分析器或扫描器
语法分析器或解析器
一些语义分析
我们生成某种形式的中间表示和符号表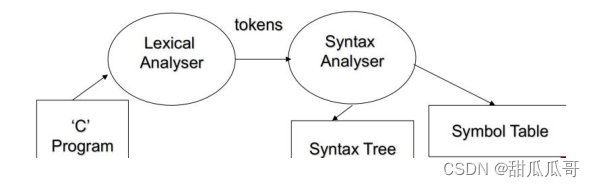
5.2.2 合成部分
代码生成阶段
可能有一个或多个优化阶段
所有这些阶段可以顺序运行,也可以并行运行
5.3 前端和后端
前端的操作取决于源语言
扫描器、解析器和语义分析器,以及中间代码合成
后端的操作取决于目标语言
代码生成以及一些优化分析
中间表示是它们之间的沟通媒介
这种结构对于编译器的可移植性很重要
5.4 遍
在生成代码之前处理整个源程序的重复称为遍。
遍可能与阶段对应,也可能与阶段不对应。
- 遍通常由几个阶段组成。
- 编译器可以是一次遍,这会导致高效编译,但目标代码效率较低。
- 大多数具有优化功能的编译器使用多个遍:
1)一个遍用于扫描和解析
2)一个遍用于语义分析和源代码级优化
3)一个遍用于代码生成和目标级优化
5.5 语言定义和编译器
编程语言的词汇和句法结构
- 正则表达式
- 上下文无关语法
英语描述中编程语言的语义
- 语言参考手册
- 语言定义
语言定义和编译器通常是同时开发的
- 这些技术对定义有重大影响
- 定义对技术有重大影响
要实现的语言是众所周知的,并且具有现有的定义
- 这不是一项容易的任务
一种语言偶尔会有数学术语中的形式定义给出的语义
- 函数编程社区中所谓的指称语义
- 给出编译器符合定义的数学证明
运行时环境的结构和行为影响编译器构造
- 静态运行时环境
- 半动态或基于堆栈的环境
- 完全动态或基于堆的环境
5.6 编译器选项和接口
与操作系统接口的机制
- 输入和输出设施
- 访问目标计算机的文件系统
用户用于各种目的的选项
- 列表特性规范
- 代码优化选项
5.7 错误处理
静态(或编译时)错误必须由编译器报告:
- 生成有意义的错误消息并在每次错误后继续编译。
- 编译器的每个阶段都需要不同类型的错误处理。
异常处理:
- 生成额外的代码以执行适当的运行时测试,以确保所有此类错误在执行过程中引起适当的事件。


































还没有评论,来说两句吧...