知识蒸馏系列:蒸馏算法【标准蒸馏、DML蒸馏(互学习蒸馏)、CML蒸馏(协同互学习蒸馏)、U-DML蒸馏(统一互学习蒸馏)】
知识蒸馏(Knowledge Distillation,简记为 KD)是一种经典的模型压缩方法,核心思想是通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型(或多模型的 ensemble),在不改变学生模型结构的情况下提高其性能。
2015 年 Hinton 团队提出的基于“响应”(response-based)的知识蒸馏技术(一般将该文算法称为 vanilla-KD [1])掀起了相关研究热潮,其后基于“特征”(feature-based)和基于“关系”(relation-based)的 KD 算法被陆续提出。
现有的知识蒸馏方法主要有以下4种,
- 标准蒸馏
- DML蒸馏(互学习蒸馏)
- CML蒸馏(协同互学习蒸馏)
- U-DML蒸馏(统一互学习蒸馏)
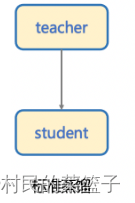
1、标准蒸馏
标准的蒸馏方法是通过一个大模型作为 Teacher 模型来指导 Student 模型提升效果,

























 —— 一个窗口显示多张图片")








还没有评论,来说两句吧...