【CVPR2017 Best Paper】Densely Connected Convolutional Networks
【CVPR2017 Best Paper】Densely Connected Convolutional Networks
- 作者

- 摘要
近年研究表明,如果卷积网络中,输入周围的层与输出周围的层有更短的连接,那么网络可以更深、更准确、训练更高效。本文根据这个观察,提出Dense Convolutional Network(DenseNet),在前馈中每一层都与其他层相连。传统卷积网络,L层有L个连接,本文有L(L+1)/2个直接连接。对每一层,所有之前层的特征图都作为输入,本层输出特征图作为所有之后层的输入。DenseNets有很多优点:减轻梯度消失现象、加强特征传播、增强特征重复利用、本质上降低了参数。我们再四个有竞争力的目标识别benchmark任务(CIFAR-10、CIFAR-100、SVHN、ImageNet)上测试,DenseNet比state-of-the-art获得了明显提升,并利用更少的计算资源获得更高的性能。
- 开源
代码和预训练模型在:https://github.com/liuzhuang13/DenseNet.
- 介绍
虽然20年前就提出了CNN,但近些年的硬件升级和网络结构优化使得深度CNN的训练成为可能。从LeNet到ResNet,CNN网络越来越深,容易出现梯度消失。很多网络通过创造早期层和后期层的更短连接路径来解决此问题。本文连接特征图尺寸匹配的所有层。如下图:对比ResNets,我们没有进行特征相加,而是concatenate。因此第l层有l个输入,由之前所有卷积block的特征图构成。

一种可能是本文方法需要更少的参数,因为没必要重复学习多余的特征图。传统的前馈网络可看做带有状态的算法,层层传递。每层从前层读取状态,并写入下一层。状态会被修改,也会保存需要的信息。近年的ResNets变体显示很多层贡献很小,可以在训练时drop。所以ResNets的状态类似于RNN,但是ResNets的参数量很大,因为每层都有自己的权重。DenseNet明确区分加入网络的信息和被保留的信息。DenseNet的层非常窄,每层只有12个过滤器,只增加小的特征图集到网络的“集体知识库”,并保留剩下的特征图不变,最终分类器基于所有特征图进行预测。
除了参数效率更高,一个很大的优点是DenseNets优化了信息和梯度的流通,更好训练。进一步,我们发现紧密连接具有正则化效果,在小规模训练集上可降低过拟合。
- 相关工作
把网络加深或者拓宽都可以改善性能。而DenseNets通过特征重复利用来开发网络潜能,紧密模型更容易训练,参数更高效。将不同层学习到的特征图串联,可以增加之后层的输入变化。这是DenseNets与ResNets的最大不同。而相比于Inception networks,DenseNets更简单高效。
- DenseNets详解
X0是输入图像,网络有L层,每层实现非线性变换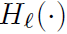 ,
, 由BN、ReLU、Pooling、Conv等构成,定义第l层输出为 。
由BN、ReLU、Pooling、Conv等构成,定义第l层输出为 。
ResNets**:**传统卷积前馈网络为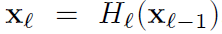 ,ResNets增加一个跨层连接,跳过非线性变换,变为
,ResNets增加一个跨层连接,跳过非线性变换,变为 。一大好处是梯度可从后面层直接流动到前面层。然而这等式中二者是相加关系,可能会影响信息流通。
。一大好处是梯度可从后面层直接流动到前面层。然而这等式中二者是相加关系,可能会影响信息流通。
Dense connectivity**:**第l层接受所有之前层的特征图作为输入 ,表示从0到l-1层学习的特征图的串联。
Composite function**:*本文定义非线性变换 由BN、ReLU、3\3卷积构成。
由BN、ReLU、3\3卷积构成。
Pooling layers**:*特征图尺寸变化后无法进行串联操作,但是卷积网络的部分本质就是降采样层去改变特征图尺寸。为了促进降采样,我们将网络分为多个紧密连接的dense blocks。我们将block之间的层称为transition layers(过渡层),负责卷积或者池化。在实验中,过渡层由一个BN层、一个1\1卷积层、一个2*2平均值池化层组成。

Growth rate**:**如果每个 生成k个特征图,由此可见第l层有
生成k个特征图,由此可见第l层有 个输入特征图,k0是输入层的通道数。DenseNet有一个重要的不同之处是有非常窄的层,例如k为12。我们称超参数k为网络增长率(growth rate)。下面的实验显示足够小的k也能获得state-of-the-art结果。因为在block中,每层都连接到所有之前的特征图,因此也连接到网络的“集体知识”。我们可将特征图集看做网络总体状态,每个层添加k个特征图到总状态,增长率调节每层对总状态的贡献量。上面提到不像传统网络架构,本文网络的总状态可在各处被使用,因此没必要进行层与层间总状态的复制。
个输入特征图,k0是输入层的通道数。DenseNet有一个重要的不同之处是有非常窄的层,例如k为12。我们称超参数k为网络增长率(growth rate)。下面的实验显示足够小的k也能获得state-of-the-art结果。因为在block中,每层都连接到所有之前的特征图,因此也连接到网络的“集体知识”。我们可将特征图集看做网络总体状态,每个层添加k个特征图到总状态,增长率调节每层对总状态的贡献量。上面提到不像传统网络架构,本文网络的总状态可在各处被使用,因此没必要进行层与层间总状态的复制。
Bottlenect layers**:虽然每层只输出k个特征图,但有非常多的输入。使用1*1卷积层作为bottlenect层,在每个3*3卷积层之前降低输入特征图的数量,使计算更高效。我们发现这个设计对DenseNet特别高效。我们将网络带有bottleneck层BN-ReLU-Conv(1*1)-BN-ReLU-Conv(3*3)的版本称为DenseNet-B*。在实验中,每个1\1卷积层生成4k个特征图。
Compression**:为了进一步改善网络紧致度,我们可以降低transition层的特征图数量。如果一个dense block包含m个特征图,接下来的transition层生成θm个特征图,0<θ<=1,作为压缩系数。我们将θ<1作为DenseNet-C**,实验中设置θ = 0.5。
Implementation Details**:*在除了ImageNet的数据集上,网络有3个dense blocks,每个有相同层数。在第一个dense blocks之前,输入图像接16通道卷积层(或者growth rate的2倍for DenseNet-BC)。为了保持特征图尺寸不变,对核尺寸3\3的卷积层,输入的每条边填充1个像素值为0。使用1*1卷积,2*2average pooling作为dense blocks之间的过渡层。在最后一个dense block,接一个全局平均持化层和softmax分类器。三个dense blocks的特征图尺寸分别是32*32,16*16,8*8。我们实验了这些结构配置:L = 40,k = 12; L =100,k = 12;L = 100,k = 24。对于DenseNet-BC,L = 100,k = 12; L =250,k = 24;L = 190,k =40。
在ImageNet,使用DenseNet-BC结构,4个dense blocks,在224*224输入。初始卷积层使用7*7*2k,stride2,其它层的特征图数量根据k设置。如下图:

- 实验结果
- 数据集
CIFAR**:*两个数据集,32\32的彩色场景图像。训练接5w,测试集1w。我们将5000训练集图像作为验证集。使用镜像/移动做图像增广。使用通道平均值和方差进行了图像的归一化。
SVHN**:*The Street View House Numbers数据集,包含32\32彩色数字图像。73257训练接,26032测试集,531131额外训练集。不增广。从训练集分出6000当验证集。选择在验证集中错误率最低的模型。像素值除以255,归一化到[0,1]。
ImageNet**:*ILSVRC2012分类数据集包含120万训练集,5万验证集,共1000类。训练集使用其他论文常用的增广方法,在测试时使用224\224的single-crop或10-crop。使用验证集的分类错误率。
- 训练
使用SGD。在CIFAR和SVHN,使用batch-size为64,分别训练300和40的epoch。为了降低GPU的显存,请参考《Memory-efficient implementation of densenets》。Weight decay为10的-4,Nesterov momentum为0.9。权重初始化使用《Delving deep into rectifiers: Surpassing human-level performance on imagenet classification》。对前三个数据集,我们在每个卷积层(除了第一个)使用**dropout layer,dropout rate为0.2**。
- CIFAR**和SVHN**的分类结果
我们训练时使用不同的深度L和增长率k。下表显示CIFAR和SVHN结果。

准确率:在SVHN中,DenseNet-BC比DenseNet结果差,可能是因为SVHN是相对简单的任务,极端深模型会导致训练集的过拟合。
容量:DenseNet性能随着L和k的提升而提升。
参数高效:同等性能下,参数比ResNet减少90%。
过拟合:高效使用参数带来一个好处,即不容易过拟合。DenseNet-BC会更高效。
- ImageNet**的分类结果**
为了更公平的比较,我们将其他条件保持一致,只把ResNet公布的Troch实现中改成DenseNet网络。Table3记录single-crop和10-crop验证集的分类错误。Figure3显示DenseNet和ResNet在single-crop和10-crop验证集的分类错误在不同参数量和FLOPS量的变换。
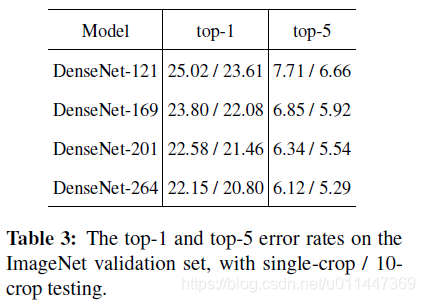

数据说明DenseNets与ResNets在性能上平分秋色,但只需要更少的参数和计算量,起码少一半。而且很多超参数都是利于ResNet,相信根据DenseNet的需要进行超参数优化后,性能还会提升。
- 探讨
表面上看,DenseNet与ResNet的不同,只在于以下两个公式的区别,一个相加,一个串联。但是小的改进带来重大性能优化。
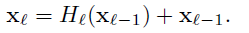

模型紧密度:作为输入串联的直接影响,DenseNet任何层学习的特征图都可以被随后层直接访问。这鼓励了特征被重复使用,导致模型更加紧密。下图比较了DenseNet和ResNet的模型高效程度。
下图显示DenseNet-BC是非常参数高效的变体。只需1/3的ResNet的参数可获得同样性能。

隐式深度监督:猜测准确度的提升,是因为通过更短的连接,个别层获得额外的loss方程的监督信息。
随机vs**确定的连接:**
特征重复利用:对一个block的每个卷积层,我们计算权重平均绝对值分布。下图显示三个dense blocks的heat-map。卷重显示层对之前层的依赖性。
- 在同一个block中,所有层都传播权重。
- Transition层也在所有层传播权重。
- Transition层输出很多多余特征,说明需要DenseNet-BC。






























二叉树的遍历及其七种实现方式")




还没有评论,来说两句吧...