机器学习中各类算法、代价函数、衡量标准
机器学习中各类算法、代价函数、衡量标准
本文是基于以下的系统环境,学习和测试机器学习中的各类算法:
- Windows 10
- PyCharm
一、机器学习算法
1、无监督学习
1.1 聚类算法
KMeans算法
- 优点:
1)速度快,可并行 - 缺点:
1)最终结果对于初始化中心点敏感
2)需求预先设定聚类个数 - 相关实现包或类:
1)sklearn.cluster.KMeans
二、数据预处理
1. 数据变换
1.1 数据归一化
- 优点:
1)利用特征的最大最小值,将特征的值缩放到[0,1]区间
- 缺点:
1)加入新的数据时,需要重新计算所有的点,并且最大值和最小值非常容易受到异常点的影响,所以在实际情况下,很少用归一化 - 相关实现包或类:
1)sklearn.preprocessing.MinMaxScaler
1.2 数据标准化

- 目的:
异常点对最大值和最小值影响太大,为了使某一个特征对最终结果不会造成更大影响,而采取数据标准化 - 优点:
将数据缩放成均值为0,标准差为1的新数据,在实际情况下,使用比较广泛 - 缺点:
1)需要具有一定的数据量
2)原始数据应符合高斯分布
3)加入新的数据时,需要重新计算所有的点 - 相关实现包或类:
sklearn.preprocessing.StandardScaler
1.3 缺失值处理
对于缺失值处理,一般有两种方式,删除和插补
- 删除
如果每列或者每行数据缺失值达到一定的比例,建议放弃整行或者整列 - 插补
可以通过缺失值每列的平均值、中位数等来填充 - 相关实现包或类:
sklearn.preprocessing.Imputer
1.4 数据降维
降维是针对于数据特征的数量进行降维,数据降维的方式有2种,特征选择和主成分分析
2. 特征工程
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性
2.1 数据转换
2.2 特征抽取
将非数值型的特征属性转换成数值类型的过程就是特征抽取,让计算机更好的理解数据
2.2.1 字典数据特征抽取
from sklearn.feature_extraction import DictVectorizerdata = [{ 'city': '北京', 'temperature': 100},{ 'city': '上海', 'temperature': 60},{ 'city': '深圳', 'temperature': 30}]model = DictVectorizer(sparse=False)transform = model.fit_transform(data)print(model.get_feature_names())print(transform)# ['city=上海', 'city=北京', 'city=深圳', 'temperature']# [[ 0. 1. 0. 100.]# [ 1. 0. 0. 60.]# [ 0. 0. 1. 30.]]
2.2.2 文本数据特征抽取
文本全部为英文的情况
from sklearn.feature_extraction.text import CountVectorizer
data = [“life is short, like python”, “life is too long, dislike python”]
model = CountVectorizer()
transform = model.fit_transform(data)
print(model.get_feature_names())
print(transform.toarray())单个字母不统计
[‘dislike’, ‘is’, ‘life’, ‘like’, ‘long’, ‘python’, ‘short’, ‘too’]
[[0 1 1 1 0 1 1 0]
[1 1 1 0 1 1 0 1]]
文本全部为中英文混合的情况
对于含有中英文的文本,需要先进行分词
from sklearn.feature_extraction.text import CountVectorizer
import jieba
data1 = “人生苦短,我喜欢python”
data2 = “人生漫长,不用python”
con1 = jieba.cut(data1)
con2 = jieba.cut(data2)
content1 = list(con1)
content2 = list(con2)
c1 = ‘ ‘.join(content1)
c2 = ‘ ‘.join(content2)
print(c1)
print(c2)model = CountVectorizer()
cv = model.fit_transform([c1, c2])
print(model.get_feature_names())
print(cv.toarray())人生 苦短 , 我 喜欢 python
人生 漫长 , 不用 python
[‘python’, ‘不用’, ‘人生’, ‘喜欢’, ‘漫长’, ‘苦短’]
[[1 0 1 1 0 1]
[1 1 1 0 1 0]]
tf-idf提取
tf:term frequency 词的频率
idf:inverse document frequency 逆文档频率 = log(总文档数量 / 该词出现的文档数量)
tf * idf = 重要性程度对于含有中英文的文本,需要先进行分词
from sklearn.feature_extraction.text import CountVectorizer
import jieba
data1 = “人生苦短,我喜欢python”
data2 = “人生漫长,不用python”
con1 = jieba.cut(data1)
con2 = jieba.cut(data2)
content1 = list(con1)
content2 = list(con2)
c1 = ‘ ‘.join(content1)
c2 = ‘ ‘.join(content2)
print(c1)
print(c2)model = CountVectorizer()
cv = model.fit_transform([c1, c2])
print(model.get_feature_names())
print(cv.toarray())人生 苦短 , 我 喜欢 python
人生 漫长 , 不用 python
[‘python’, ‘不用’, ‘人生’, ‘喜欢’, ‘漫长’, ‘苦短’]
[[0.40993715 0. 0.40993715 0.57615236 0. 0.57615236]
[0.40993715 0.57615236 0.40993715 0. 0.57615236 0. ]]
3、有监督学习
3.1 随机森林算法
- 优点:
1)能够处理高维度特征数据,并且不用做特征选择
2)训练完成后,能够给出哪些特征比较重要
1)容易做并行化方法,速度比较快
1)可以进行可视化展示,便于分析 - 缺点:
1)最终结果对于初始化中心点敏感
2)需求预先设定聚类个数 - 相关实现包或类:
1)sklearn.cluster.KMeans
三、代价函数
1、均方误差代价函数
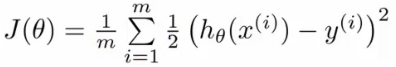
2、交叉熵代价函数
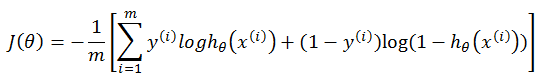
三、衡量标准
1、熵
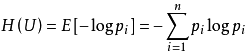
2、Gini系数
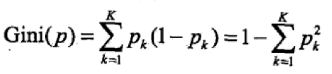
四、深度学习
1、人工神经网络
1.1 激活函数
在神经网络诞生初期,人们绝大多数都会使用Sigmoid函数作为激活函数
g ( z ) = 1 1 + e x g(z) = \frac{1}{1+e^x} g(z)=1+ex1
随着神经网络的层数比较多,梯度消失的现象非常容易发生,一旦出现梯度消失的现象,我们就无法做反向传播了,神经网络就无法收敛,因此Sigmoid函数已经退出了机器学习的舞台,取而代之的是ReLU函数
R e L U = m a x ( 0 , x ) ReLU = max(0,x) ReLU=max(0,x)


























")



")



还没有评论,来说两句吧...