机器学习方法之决策树
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
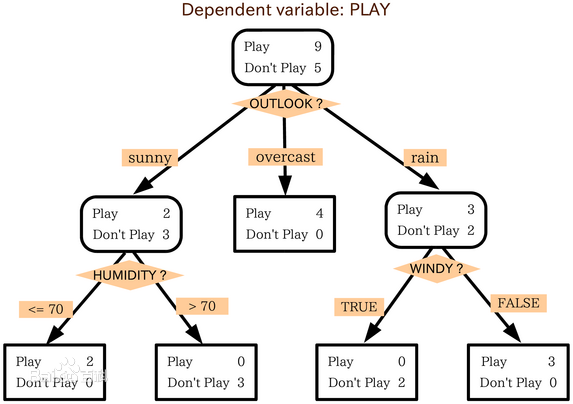
上图中是否出去玩取决于天气情况(sunny、overcast、rain)和空气湿度(humidity、windy)这2个属性的值。
信息熵
决策树算法种类很多,本文主要介绍ID3算法。ID3算法在1970-1980年,由J.Ross. Quinlan提出。在介绍决策树算法前,我们先引入熵(entropy)的概念。
信息和抽象,具体该如何度量呢?1948年,香农提出了**信息熵(entropy)**的概念。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少。
我们用比特(bit)来衡量信息的多少,变量的不确定性越大,熵也就越大。计算公式如下,其中 P ( x i ) P(x_i) P(xi)表示每种事件发生的可能性。
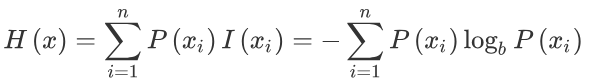
ID3算法
该算法在选择每一个属性判断结点的时候是根据信息增益(Information Gain)。通过下面公式可以计算A来作为节点分类获取了多少信息。
G a i n ( A ) = I n f o ( D ) − I n f o A ( D ) Gain(A) = Info(D) - InfoA(D) Gain(A)=Info(D)−InfoA(D)
上图是一个买车的实例,一个人是否买车取决于他的年龄、收入、信用度和他是否是学生。下图(右)是原始数据,下图(左)是简单的决策树划分。那我们是如何确定age作为第一个属性结点的呢?
一共有14条数据,其中9人买车,5人没买车,所以根据公式可以算出 I n f o ( D ) Info(D) Info(D)的值。接着我们计算选择age作为属性结点的信息熵。age有三个取值,其中youth有5条信息(2人买车,3人没买),middle_aged有4条信息(全部买车),senior有5条信息(3人买车,2人没买),所以根据公式可以算出 I n f o a g e ( D ) Info_{age}(D) Infoage(D)和 G a i n ( a g e ) Gain(age) Gain(age)的值,如下所示:
类似, G a i n ( i n c o m e ) = 0.029 , G a i n ( s t u d e n t ) = 0.151 , G a i n ( c r e d i t r a t i n g ) = 0.048 Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048 Gain(income)=0.029,Gain(student)=0.151,Gain(creditrating)=0.048
所以,选择age作为第一个根节点。重复。。。

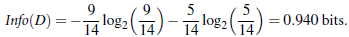
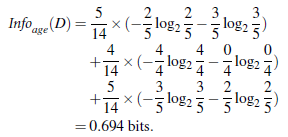

最终我们得到了如下所示的决策树。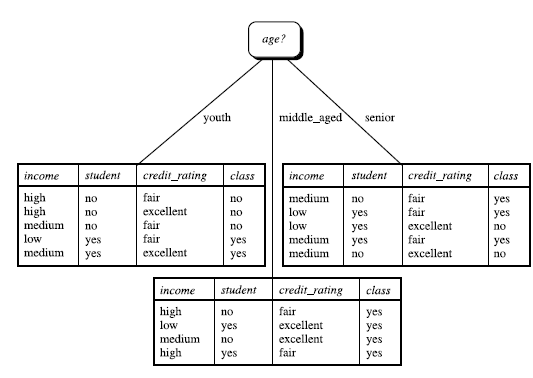
算法流程
- 从根节点出发,根节点包括所有的训练样本。
- 一个节点(包括根节点),若节点内所有样本均属于同一类别,那么将该节点就成为叶节点,并将该节点标记为样本个数最多的类别。
- 否则利用采用信息增益法来选择用于对样本进行划分的特征,该特征即为测试特征,特征的每一个值都对应着从该节点产生的一个分支及被划分的一个子集。在决策树中,所有的特征均为符号值,即离散值。如果某个特征的值为连续值,那么需要先将其离散化。
- 递归上述划分子集及产生叶节点的过程,这样每一个子集都会产生一个决策(子)树,直到所有节点变成叶节点。
- 递归操作的停止条件就是:
(1) 一个节点中所有的样本均为同一类别,那么产生叶节点
(2) 没有特征可以用来对该节点样本进行划分,这里用attribute_list=null为表示。此时也强制产生叶节点,该节点的类别为样本个数最多的类别
(3) 没有样本能满足剩余特征的取值,即test_attribute=a_i 对应的样本为空。此时也强制产生叶节点,该节点的类别为样本个数最多的类别
l流程图如下所示: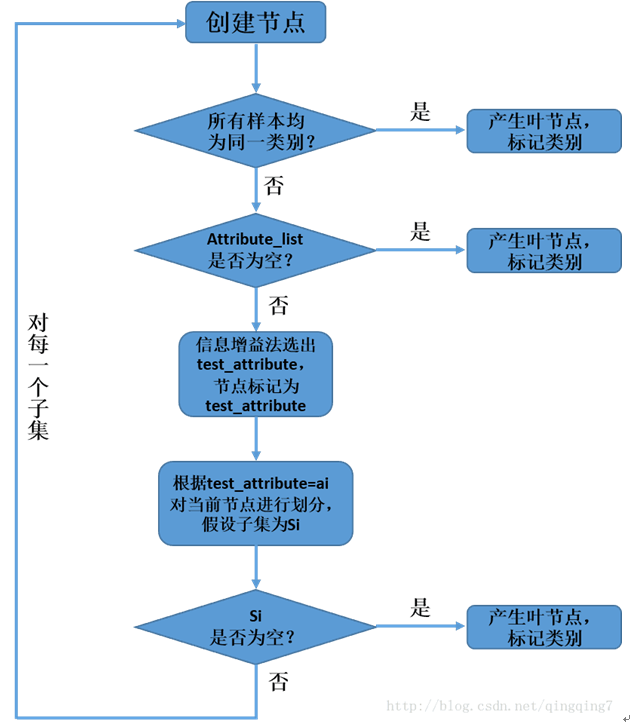
代码实现
from sklearn.feature_extraction import DictVectorizerimport csvfrom sklearn import treefrom sklearn import preprocessingimport pydotplus#读入csv文件Extradata = open("G:/PycharmProjects/Machine_Learning/Decision_Tree/AllElectronics.csv","r",encoding="utf-8")reader = csv.reader(Extradata)headers = next(reader) #逐行读取数据 python3中为nex(),python2 中为reader.next()#print(headers)featureList = [] #特征列表labelList = [] #标签列表for row in reader:labelList.append(row[len(row)-1]) #读取每行数据最后一列的标签,存入标签列表rowDict = {} #创建字典,存储每行特征数据for i in range(1,len(row)-1):#从第2列开始到倒数第2列读取特征数据rowDict[headers[i]] = row[i] #对应键值对存储数据featureList.append(rowDict) #将每行特征数据字典存入特征列表#print(featureList)#向量化特征数据vec = DictVectorizer()dum_X = vec.fit_transform(featureList).toarray()# print("dum_X: " + str(dum_X))# print(vec.get_feature_names())## print("labelList: " + str(labelList))##向量化标签数据label = preprocessing.LabelBinarizer()dum_Y = label.fit_transform(labelList)#print("dum_Y: " + str(dum_Y))#调用sklearn方法构建决策树classfiy = tree.DecisionTreeClassifier(criterion='entropy')classfiy = classfiy.fit(dum_X,dum_Y)#print("classfiy: " + str(classfiy))#将决策树存为dot文件with open("G:/PycharmProjects/Machine_Learning/Decision_Tree/AllElectronics.dot", 'w') as f:f = tree.export_graphviz(classfiy,feature_names=vec.get_feature_names(),out_file=f)#可视化决策树的模型,并存为pdf文件dot_data = tree.export_graphviz(classfiy,out_file=None)graph = pydotplus.graph_from_dot_data(dot_data )graph.write_pdf("aa.pdf")#验证决策树分类模型oneRow_X = dum_X[0,:]#print("oneRow_X: " + str(oneRow_X))newRow_X = oneRow_X#修改特征数据的值newRow_X[0] = 1newRow_X[2] = 0newRow_X[3] = 1newRow_X[4] = 0#print("newRow_X: " + str(newRow_X))finalRow_X = newRow_X.reshape(1,10) #将一位数组转换为二维数组predict_Y = classfiy.predict(finalRow_X) #调用决策树模型预测,注意,finalRow_X要求二维#predict_Y = classfiy.predict([[1., 0., 0., 0., 1., 1., 0., 0., 1., 0.]])print("predict_Y: " + str(predict_Y))
代码中预测结果见下图:
最后生成的决策树模型见下图: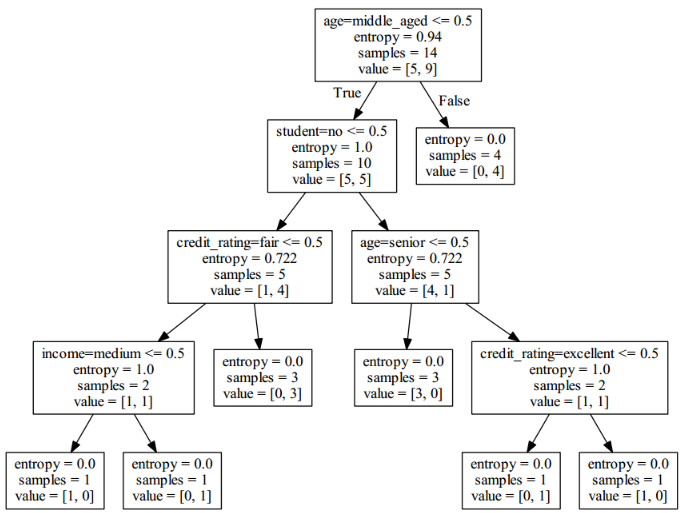
其他决策树算法
- C4.5: Quinlan
Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)
**共同点:**都是贪心算法,自上而下(Top-down approach)
**区别:**属性选择度量方法不同: C4.5 (gain ratio), CART(gini index), ID3 (Information Gain)
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类、回归 | 二叉树 | 基尼系数、均方差 | 支持 | 支持 | 支持 |
决策树的优缺点
优点
- 简单直观,生成的决策树很直观。
- 基本不需要预处理,不需要提前归一化,处理缺失值。
- 既可以处理离散值也可以处理连续值。很多算法只是专注于离散值或者连续值。
- 可以处理多维度输出的分类问题。
- 相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
- 可以交叉验证的剪枝来选择模型,从而提高泛化能力。
缺点
- 决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
- 决策树会因为样本发生一点点的改动,就会导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
- 寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4.有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。- 如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
参考资料
Scikit-learn中的决策树

































还没有评论,来说两句吧...