利用卷积神经网络识别手写数字
1.测试数据准备
1.我们使用的测试数据,可以直接从keras.datasets.mnist导入
import numpy as npimport seaborn as snsimport matplotlib.pyplot as pltplt.rcParams['figure.figsize']=(7,7)from keras.datasets import mnistfrom keras.models import Sequentialfrom keras.utils import np_utilsimport kerasfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2Dfrom keras.layers.normalization import BatchNormalizationepochs = 20input_shape = (28, 28, 1)nb_classes = 10(X_train, y_train), (X_test, y_test) = mnist.load_data()print('X_train shape:', X_train.shape)print('X_test shape:', X_test.shape)
能看到一共有6W条训练数据和1W条测试数据
由于被墙的原因,mnist可能无法下载,可以换成本地数据导入的方式。下载数据请点击这里,数据导入方式换成
path='./mnist.npz'f = np.load(path)X_train, y_train = f['x_train'], f['y_train']X_test, y_test = f['x_test'], f['y_test']f.close()
2.查看数据
for i in range(9):plt.subplot(3, 3, i+1)plt.imshow(X_train[i], cmap='gray', interpolation='none')plt.title("Class {}".format(y_train[i]))
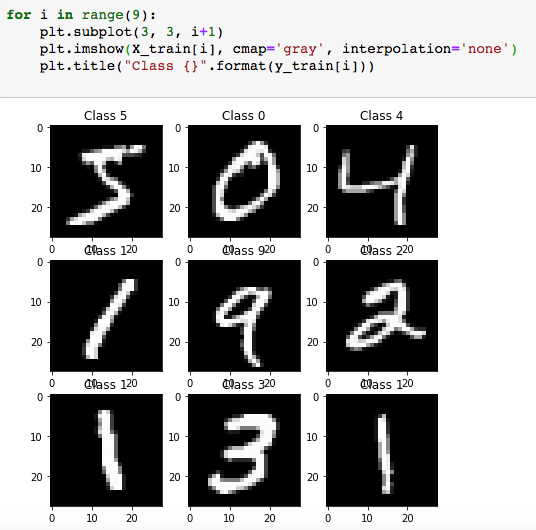
3.将数据格式转换为keras接受的数据结构
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)print('X_train shape:', X_train.shape)print('X_test shape:', X_test.shape)

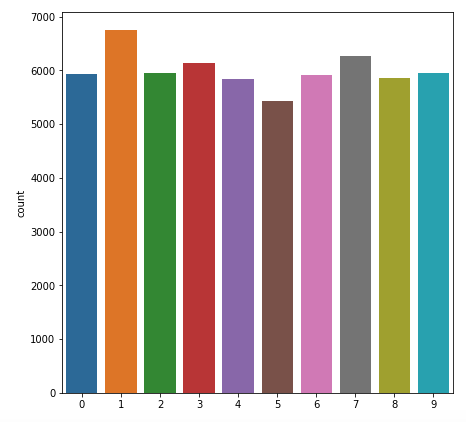
使用seaborn观察训练数据集的y值分布
sns.countplot(y_train)
Y_train = np_utils.to_categorical(y_train, nb_classes)Y_test = np_utils.to_categorical(y_test, nb_classes)print("Y_train:", Y_train.shape)

2.定义深度神经网络结构
model = Sequential()model.add(Conv2D(32, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal', input_shape=input_shape))model.add(Conv2D(32, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal'))model.add(MaxPool2D(2,2))model.add(Dropout(0.2))model.add(Conv2D(64, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal', padding='same'))model.add(Conv2D(64, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal', padding='same'))model.add(MaxPool2D(2,2))model.add(Dropout(0.25))model.add(Conv2D(128, kernel_size=(3,3), activation='relu', kernel_initializer='he_normal', padding='same'))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(BatchNormalization())model.add(Dropout(0.25))model.add(Dense(nb_classes, activation='softmax'))model.compile(loss=keras.losses.categorical_crossentropy,optimizer=keras.optimizers.Adam(),metrics=['accuracy'])model.summary()

3.训练模型
完成数据训练并保存训练好的模型
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)datagen.fit(X_train)filepath = 'model.hdf5'from keras.callbacks import ModelCheckpoint# monitor计算每一个模型validation_data的准确率# save_best_only 只保存最好的一个模型checkpointer = ModelCheckpoint(filepath, monitor='val_acc', save_best_only=True, mode='max')# steps_per_epoch指定循环次数h = model.fit_generator(datagen.flow(X_train, Y_train, batch_size=500),steps_per_epoch=len(X_train)/1000, epochs=epochs,validation_data=datagen.flow(X_test, Y_test, batch_size=len(X_test)),validation_steps=1, callbacks=[checkpointer])
训练完成后可以看到模型在测试数据上的准确率已经达到了99.39%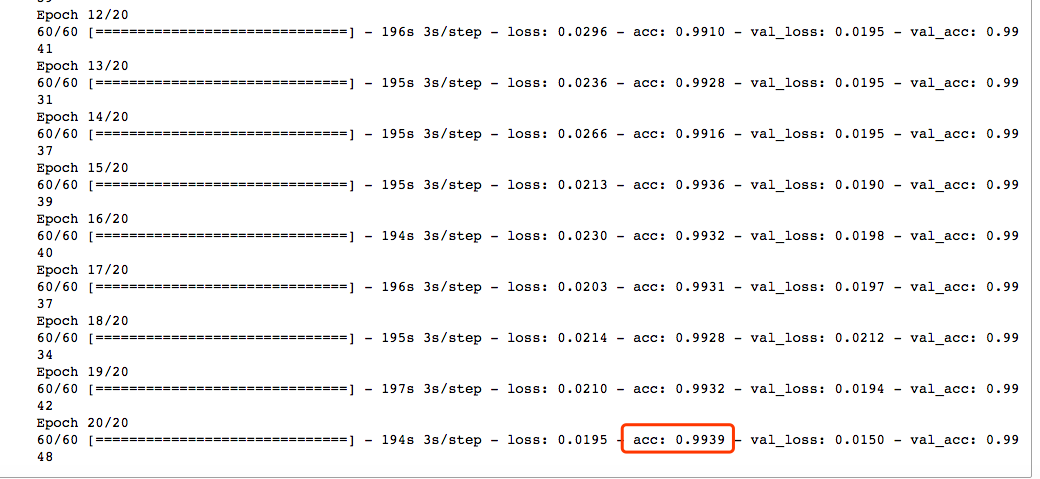
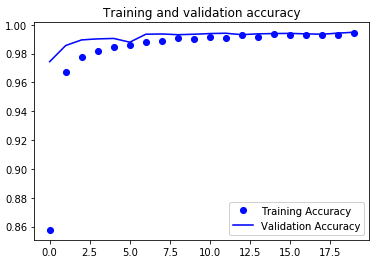
我们可以用pyplot打印一下,随着epochs的执行,模型在训练数据和测试数据集的准确率的表现情况
history = h.historyaccuracy = history['acc']val_accuracy = history['val_acc']loss = history['loss']val_loss = history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy, 'bo', label='Training Accuracy')plt.plot(epochs, val_accuracy, 'b', label='Validation Accuracy')plt.title('Training and validation accuracy')plt.legend()plt.show()
4.模型评估
from keras.models import load_modelmodel = load_model('model.hdf5')score = model.evaluate(X_test, Y_test)print('Test score:', score[0])print('Test accuracy:', score[1])
可以看到一共有1W组数据,损失函数约为0.24,准确率达到了0.984,已经比较高了。
我们可以抽取一些预测数据,与真实值进行对比
predicted_classes = model.predict_classes(X_test)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
选取9个预测正确的进行打印
plt.figure()for i, correct in enumerate(correct_indices[:9]):plt.subplot(3,3,i+1)plt.imshow(X_test[correct].reshape(28, 28), cmap='gray', interpolation='none')plt.title("Predicted {}, Class {}".format(predicted_classes[correct], y_test[correct]))

当然我们也可以选择9个错误的进行打印
plt.figure()for i, incorrect in enumerate(incorrect_indices[:9]):plt.subplot(3,3,i+1)plt.imshow(X_test[incorrect].reshape(28, 28), cmap='gray', interpolation='none')plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))

可以看到,有一些真实值为1的图片,被识别错误了,说明模型还有一些改进的空间。
所有源码、测试数据以及训练好的模型已上传至git,点击这里可直接查看,有疑问的同学请在博客下方留言或提Issuees,谢谢!


































还没有评论,来说两句吧...