[Hadoop] Hive表的file_format参数
Hive官网
" class="reference-link">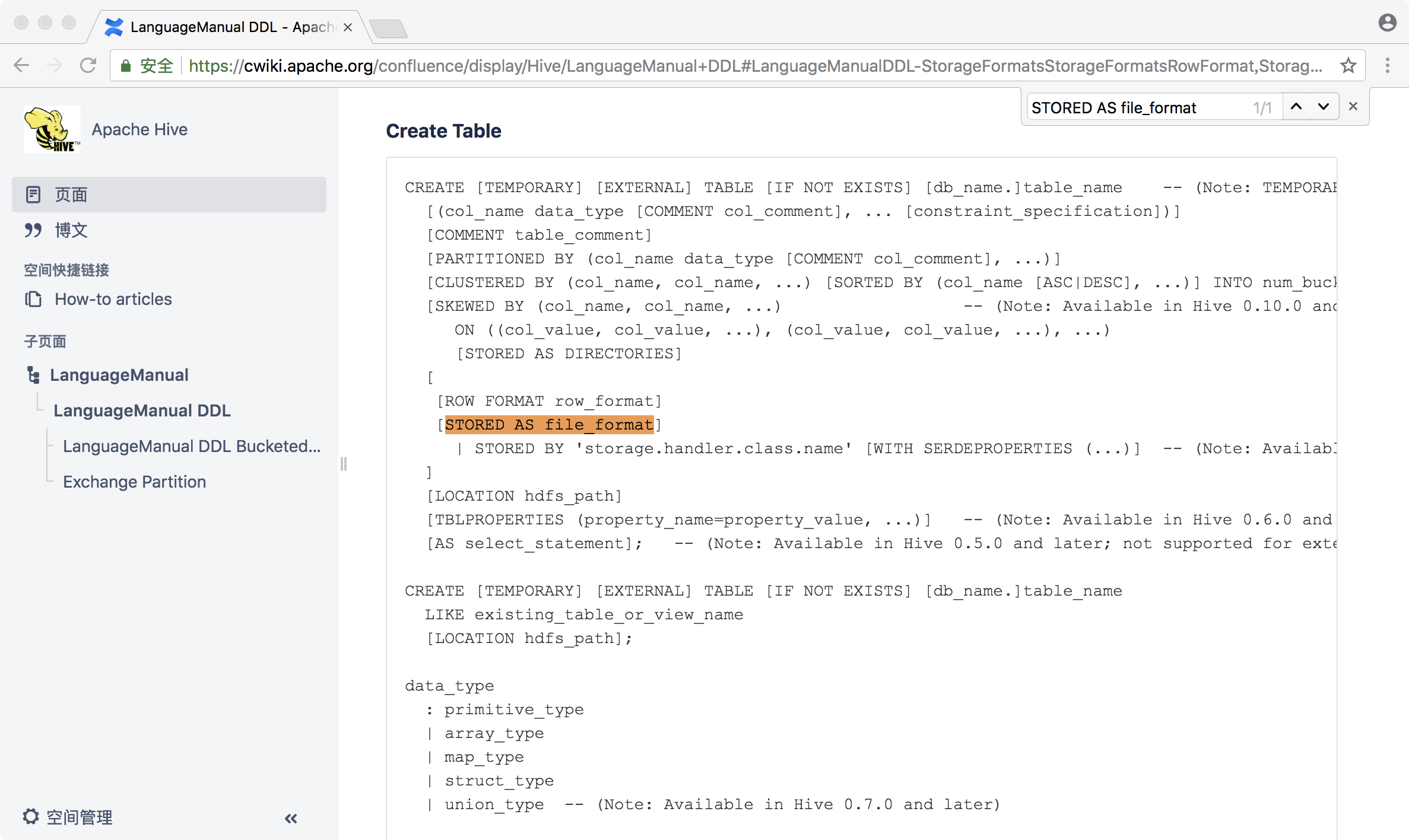
1. file_format
Hive的建表语句里面有一个STORED AS file_format结合使用的方法,指定hive的存储格式。不仅能节省hive的存储空间,还可以提高执行效率。
file_format:: SEQUENCEFILE| TEXTFILE -- (Default, depending on hive.default.fileformat configuration) # 默认存储文本格式,不能区分数据类型| RCFILE -- (Note: Available in Hive 0.6.0 and later)| ORC -- (Note: Available in Hive 0.11.0 and later)| PARQUET -- (Note: Available in Hive 0.13.0 and later)| AVRO -- (Note: Available in Hive 0.14.0 and later)| JSONFILE -- (Note: Available in Hive 4.0.0 and later)| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
其中:
- TEXTFILE:文本格式,为hive默认的存储格式,这种格式不能区分数据类型(Int类型的数据也只能当作文本来处理)。TEXTFILE在使用时只需要指定两个东西:列与列之间的分隔符;行与行之间的分隔符。
- SEQUENCEFILE:二进制的,它存在一些问题,这种存储格式存储的数据size比原始数据还要大,现在基本不用。
- RCFILE:它是一个混合的行列编成的,它保证所有行的一个列都在一个节点(block)之上,缺点是row group太小(4M)了,实际的好处只是空间节省只提升了大约10%,工作中不会大面积使用,所以现在基本也不使用了。
- ORC:优化过后的RC(行列存储),它提供了更高效的存储方式。一个strip(250M)包含了索引文件,索引范围1~10W。查询时只会查询index范围内的strip,提高查询效率。默认每10000行为一个单位。orc默认采用zlib压缩方式。详见官网说明。
- PARQUET:源于dremel(三秒钟完成一个T的数据处理),效率很高。
- AVRO:不常用。
- JSONFILE:不常用。
示例:
去hive里面创建一张表,不指定存储格式。查看建表语句,# Storage Information部分会看到输入输出都是文本格式。
- InputFormat: org.apache.hadoop.mapred.TextInputFormat # 默认为文本格式
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat # 默认也为文本格式
hive> create table tb1(id int);
OK
Time taken: 0.149 seconds
hive> desc formatted tb1;
OKcol_name data_type comment
id int
Detailed Table Information
Database: default
Owner: hadoop
CreateTime: Tue Aug 14 02:16:16 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://192.168.1.8:9000/user/hive/warehouse/tb1
Table Type: MANAGED_TABLE
Table Parameters:transient_lastDdlTime 1534184176
Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:serialization.format 1
Time taken: 0.153 seconds, Fetched: 26 row(s)
hive>
创建第二张表,指定输入和输入格式都为文本格式,会得到跟上面的表一样的结果。应用时需要用到其他格式的输入和输出,用这种方法来指定。
hive> create table tb2(id int) stored as> INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'> OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';OKTime taken: 0.114 secondshive> desc formatted tb2;OK# col_name data_type commentid int# Detailed Table InformationDatabase: defaultOwner: hadoopCreateTime: Tue Aug 14 02:18:12 CST 2018LastAccessTime: UNKNOWNProtect Mode: NoneRetention: 0Location: hdfs://192.168.1.8:9000/user/hive/warehouse/tb2Table Type: MANAGED_TABLETable Parameters:transient_lastDdlTime 1534184292# Storage InformationSerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeInputFormat: org.apache.hadoop.mapred.TextInputFormatOutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatCompressed: NoNum Buckets: -1Bucket Columns: []Sort Columns: []Storage Desc Params:serialization.format 1Time taken: 0.17 seconds, Fetched: 26 row(s)hive>
扩展:
行式存储:将一个个完整的数据行存储在数据页中,一行的数据全部存在一块:保证一行所有的列都在一个block里面。每一行的数据有各种不同类型的字段,压缩起来优势不大。
列式存储:每一列单独存放,数据即是索引。每一列的数据类型是一样的且重复的数据很多,在压缩时列式存储更有优势,压缩比更高。
在大数据中,一个表有非常多的字段,我们大部分场景只有用到其中的某些字段,这种场景我们必然优先选择列式存储。
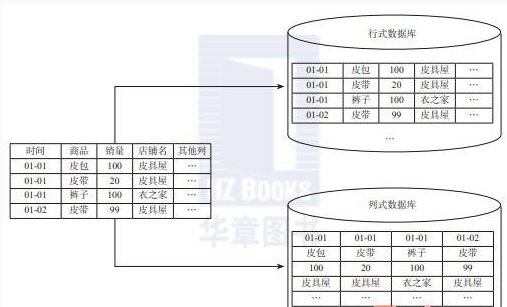
HDFS中列式存储的样子:

























Oracle中用Exp命令导出指定用户下的所有表的前N行数据,并用imp数据导入到本地数据库中--修改编码")








还没有评论,来说两句吧...