python爬虫小白之bs4:pip install BeautifulSoup错误汇总
做爬虫时大都多数会用到Beautiful Soup,它 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间
但是你使用命令:pip install beautifulsoup时会报错,错误如下: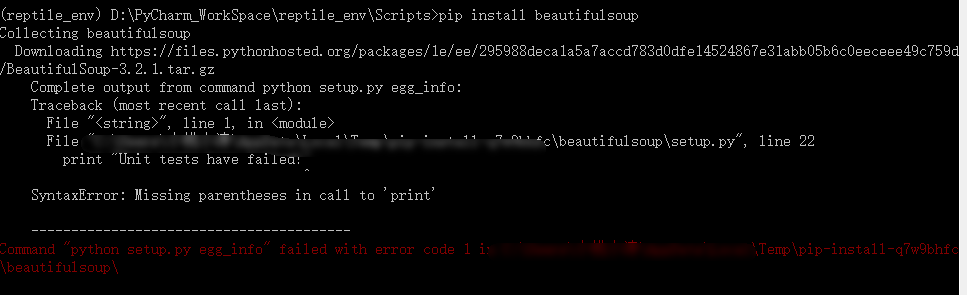
更改命令为:pip install beautifulsoup4 就行了
完成后,执行代码;发现又出现了错误,错误信息提示我们还需要安装lxml这个库
命令为:pip install lxml 安装就行了
参考:https://www.cnblogs.com/zdz8207/p/python_learn_note_17.html
https://blog.csdn.net/qq_34215281/article/details/77714584


























:类加载器和双亲委派机制")







还没有评论,来说两句吧...