B树、B+树、B*树
B树
B树是一种平衡的多路查找树
定义:一棵m 阶的B树,或者为空树,或为满足下列特性的m 叉树:
1 树中每个结点至多有m个孩子;
2 除根结点和叶子结点外,其它每个结点至少有m/2个孩子;
3 若根结点不是叶子结点,则至少有2个孩子;
4 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息;
5 有k个孩子的非终端结点包含k-1个关键字
B树实现、插入相关代码:
#pragma oncetemplate<class K,class V,size_t M>struct BTreeNode{pair<K,V> _kvs[M];//多开一个空间 ,方便分裂BTreeNode<K,V,M> * _sub[M+1];BTreeNode<K,V,M> * _parent;size_t _size; // 关键字的数量BTreeNode():_parent(NULL),_size(0){for (size_t i = 0;i < M;++i){_sub[i] = NULL;}}};template<class K,class V,size_t M>class BTree{typedef BTreeNode<K,V,M> Node;public:BTree():_root(NULL){}pair<Node*,int> Find(const K& key)//寻找{Node *cur = _root;Node * parent = NULL;while (cur){size_t i = 0;while (i<cur->_size){if (cur->_kvs[i].first > key)//在i的左树{break;}else if (cur->_kvs[i].first <key){++i;}else{return make_pair(cur,i);}}parent = cur;cur = cur->_sub[i];}return make_pair(parent,-1);}bool Insert(const pair<K,V>& kv){if (_root == NULL){_root = new Node;_root->_kvs[0] = kv;_root->_size = 1;return true;}pair<Node*,int> ret = Find(kv.first);if (ret.second >= 0){return false;}Node* cur = ret.first;pair<K,V> newKV = kv;Node* sub = NULL;while (1){//往cur插入newKV,sub InsertKV(cur,newKV,sub);if (cur->_size < M){return true;}else //分裂{Node* newNode = Divide(cur);pair<K,V> midKV = cur->_kvs[cur->_size/2];cur->_size -= (newNode->_size+1);//1.根节点分裂if (cur == _root){_root = new Node;_root->_kvs[0] = midKV;_root->_size = 1;_root->_sub[0] = cur;_root->_sub[1] = newNode;cur->_parent = _root;newNode->_parent = _root;return true;}else{cur = cur->_parent;newKV = midKV;sub = newNode;}}}}Node* Divide(Node *cur){Node * newNode = new Node;int mid = cur->_size/2;size_t j = 0;size_t i = mid+1;for (;i < cur->_size;++i){newNode->_kvs[j] = cur->_kvs[i];newNode->_sub[j] = cur->_sub[i];if(newNode->_sub[j])newNode->_sub[j]->_parent = newNode;newNode->_size++;j++;}newNode->_sub[j] = cur->_sub[i];if(newNode->_sub[j])newNode->_sub[j]->_parent = newNode;return newNode;}void InsertKV(Node* cur,const pair<K,V> &kv,Node* sub) {int end = cur->_size-1;while (end >= 0){if (cur->_kvs[end].first > kv.first){cur->_kvs[end+1] = cur->_kvs[end];cur->_sub[end+2] = cur->_sub[end+1];--end;}else{break;}}cur->_kvs[end+1] = kv;cur->_sub[end+2] = sub;if(sub) sub->_parent = cur;cur->_size++;}void InOrder(){_InOrder(_root);cout<<endl;}void _InOrder(Node *root){if (root == NULL){return;}Node * cur = root;size_t i = 0;for (;i < cur->_size;++i){_InOrder(cur->_sub[i]);cout<<cur->_kvs[i].first<<" ";}_InOrder(cur->_sub[i]);}private:Node* _root;};void TestBTree(){int a[]={53,75,139,49,145,36,101};BTree<int,int,3> b;for (size_t i = 0;i<sizeof(a)/sizeof(a[0]);++i){b.Insert(make_pair(a[i],i));}b.InOrder();}
B+树
B+树的特点与B树的区别

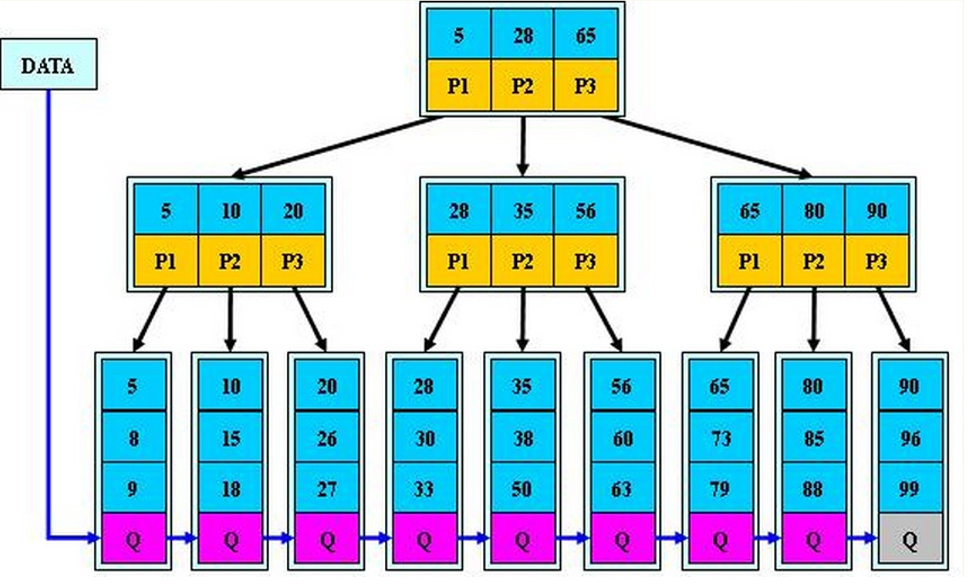
- 内部节点中,关键字的个数与其子树的个数相同,不像B树种,子树的个数总比关键字个数多1个
- 所有指向文件的关键字及其指针都在叶子节点中,不像B树,有的指向文件的关键字是在内部节点中。换句话说,B+树中,内部节点仅仅起到索引的作用,
- 在搜索过程中,如果查询和内部节点的关键字一致,那么搜索过程不停止,而是继续向下搜索这个分支
- B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
根据B+树的结构,我们可以发现B+树相比于B树,在文件系统,数据库系统当中,更有优势,原因如下:
索引作为索引文件存在磁盘里
- B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说I/O读写次数也就降低了。 - B+树的查询效率更加稳定
由于内部结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 - B+树更有利于对数据库的扫描
B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题,而B+树只需要遍历叶子节点就可以解决对全部关键字信息的扫描,所以对于数据库中频繁使用的range query,B+树有着更高的性能。
B*树
B*树的特点
- B*树是为了节省空间而提出的,B和B+树中若每个节点最多能存放M个关键字,则最少需要(M-1)/2个关键字,而B*树能够更加节省空间,最少是(2/3)M个关键字,因此更能够有效的利用空间,但是插入动作会更加麻烦,即块的最低使用率为2/3(代替B+树的1/2)。
- B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;


























")


")




还没有评论,来说两句吧...