553-链式哈希表实现和哈希表总结
C++或者Java无序关联容器底层采用链式哈希表实现
为什么不采用线性探测哈希表?
如果采用线性探测哈希表,缺陷是:
1、发生哈希冲突时,需要从当前发生哈希冲突的位置向后不断的去找,找到第一个空闲的位置把元素放上,这个过程的时间复杂度就趋近于O(n)了,存储变慢了,查询和删除也变慢,哈希冲突的发生越严重,就越靠近O(n)的时间复杂度,这个时间复杂度能否优化?哈希冲突是无法避免的,但是发生哈希冲突以后,在进行增删查的时候,能不能把时间效率提高一点,不让它趋近于O(n)的时间复杂度呢?不能,因为它是一个线性表,是数组,得环形遍历,趋近于O(n),按一个位置一个位置找,找的越多,时间复杂度就靠近O(n),这个是无法优化的,因为只有这么一个数组的结构。这个问题在线性哈希表中,无法优化,但是在链式哈希表中是可以优化的!
2、在多核盛行的情况下,非常方便的使用并发程序(多线程,多进程),在多线程环境中,有线程安全的问题,多个线程能不能同时在一个数组中进行数据的增删查呢?肯定是不可以的!!!在C++的所有容器都不是线程安全的,所以我们必须添加线程的互斥操作,互斥锁,读写锁,自旋锁,然后在多线程下对容器的添加修改删除做互斥操作,保证这些容器在多线程环境下操作它都是一个原子操作。同样的,线性哈希表作为一个数组,没有办法去一边修改一边查询的,或者一边删除一边查询。
很明显,在线性哈希表中,往数组增加一个元素,又要通过除留余数法计算哈希值,发生哈希冲突了,又要遍历数组找到一个空闲的位置放,这么多的操作能是一个原子操作吗?肯定不能是一个原子操作,这步骤太多了。
在多线程环境中,线性探测所用到的基于数组实现的哈希表只能给全局的表用互斥锁来保证哈希表的原子操作,保证线程安全。
(因为线性探测只有一个数组,得把整个数组锁起来,也就是说,多个线程,对同1个数组操作,如果多个线程对这个数组添加的元素是不在同一个位置上的,理论来说,应该可以并发运行,实际上不能让他们并发,因为有可能多个线程,你要放在3位置,我要放在4位置,然后3和4位置原本已经有元素了,你和我就都发生哈希冲突了,都要向后找第一个空闲的位置,如果我和你同时找到了1号位置,如果我和你都认为1号位置是空闲,都放元素进去,后放的那个元素把先放的元素给覆盖掉了,这就有问题了!!!)
所以,我们给整个哈希表加锁了,要么你先操作,要么我先操作。
但是,链式哈希表在多线程环境下可以采用分段的锁,既保证了线程安全,又有一定的并发量,提高了效率。
当然,我们库里的无序关联容器并没有实现多线程环境中的线程安全问题,也就是并没有去加锁,但是毫不妨碍当我们真真正正想实现一个线程安全,运行在多线程环境下的一个基于哈希表实现的无序关联容器,我们在代码上就可以通过分段锁来实现!
链式哈希表
我们要把下面这一行数据放到链式哈希表中。
我们使用的哈希函数还是除留余数法。
解决哈希冲突的方法是链地址法
除留余数法为了解决哈希冲突,建议所采用的数组的元素个数是素数个, 除了1和自己,不会被其他数字整除 ,尽量避免余数产生冲突
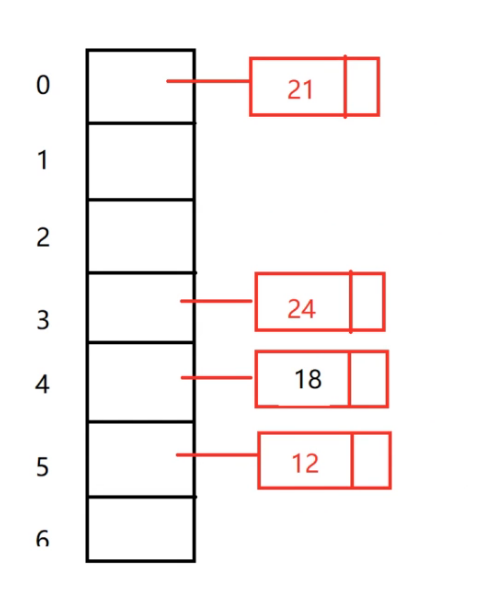
这个哈希表的下标是0-6,和线性哈希表一样,只不过现在这个是竖着放的,12%7=5,把12放在数组下标是5的位置
链式哈希表在解决哈希冲突时,就不向后遍历探测了,而是在这个桶里边生成一个数据结构:链表
这个链表的节点存储的是元素值和next指针,把发生哈希冲突的元素都串在一个链表上
18%7=4,把18串在下标为4的桶的链表上
21%7=0 把21放在0号位置
24%7=3 把24放在3号位置
33%7=5,发生哈希冲突了,但是没关系,链表嘛,继续向后增加节点就可以了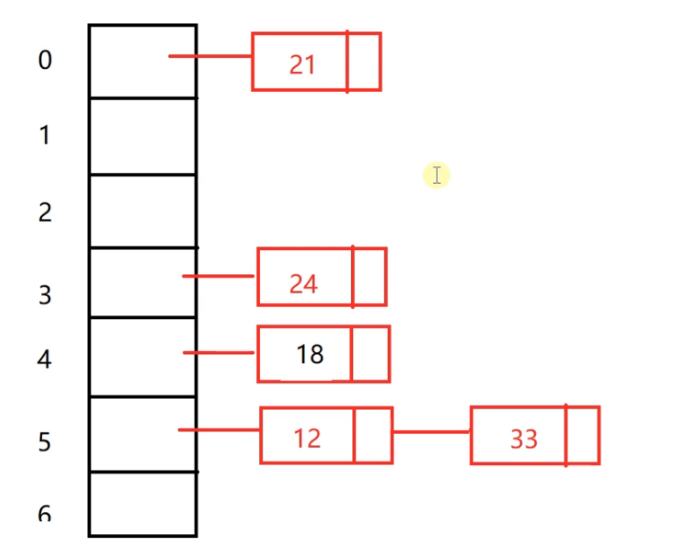
以此类推。
链式哈希表,一维数组是没有变的,每个元素是一个桶,但是这个桶存储的是链表 
发生哈希冲突的时候,不会像线性哈希表那样往其他桶跑,通过哈希函数算出在哪个桶,就是在哪个桶,这个桶放的是链表,采用尾插或者头插把这个元素插进链表里
链式哈希表的搜索:
如果你要搜索21的话,先通过哈希函数-除留余数法,21%7=0,我们就去0号桶里查,
当这个链式哈希表里的每个桶的链表比较长时,链表搜索花费的时间就大,节点越多,时间复杂度就趋近于O(n) 
当然,我们也不会放任这种情况的。
链式哈希表也有装载因子。
已占用桶的个数如果达到占总的桶个数的0.75,哈希表就要进行扩容了
链式哈希表的删除操作:
先搜,搜到再删除。
先拿原始的数据模上7,得出余数,知道在哪个桶放,这个操作时间复杂度是O(1),然后在这个桶里的链表去找到这个元素的节点,然后删除这个节点
这个链式哈希表不能出现这种情况: 其他的桶都是空的,然后其中一个桶的链表特别特别长,好像都挤到一个桶里去了,这说明选择的哈希函数不好或者自己创建的哈希函数太差了,没有办法把原始的数据通过哈希函数的映射离散开来。 我们需要的哈希函数是尽量把数据离散开,散列结果越离散越好,就可以均匀的分配在桶中 。
所以,我们一般把除留余数法,桶的个数取成素数,这样才会让散列的结果产生最少的冲突,所有的数据不会集中在一个或者几个桶中,而是离散开来,提高了整体哈希表的效率。
对于链式哈希表的增删查时间复杂度:无限趋近于O(1) ,因为哈希冲突的存在
链式哈希表的优化
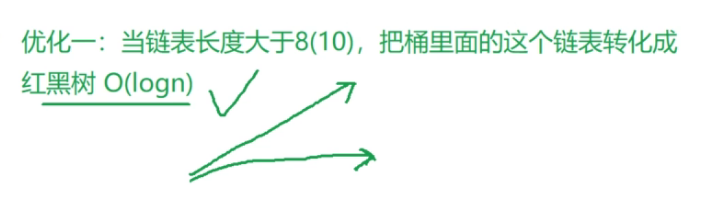
优化2:
在多线程环境中,我们在每个桶添加一把锁就可以保证线程安全,(分段锁),每把锁控制各自桶的链表的多线程下的并发操作就可以了。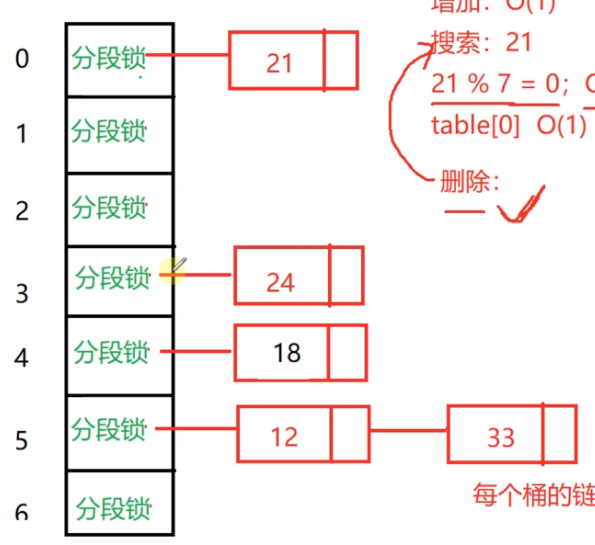
不同桶里的链表可以并发操作。同一个桶里的链表不能并发操作,因为有锁。
链式哈希表的代码实现
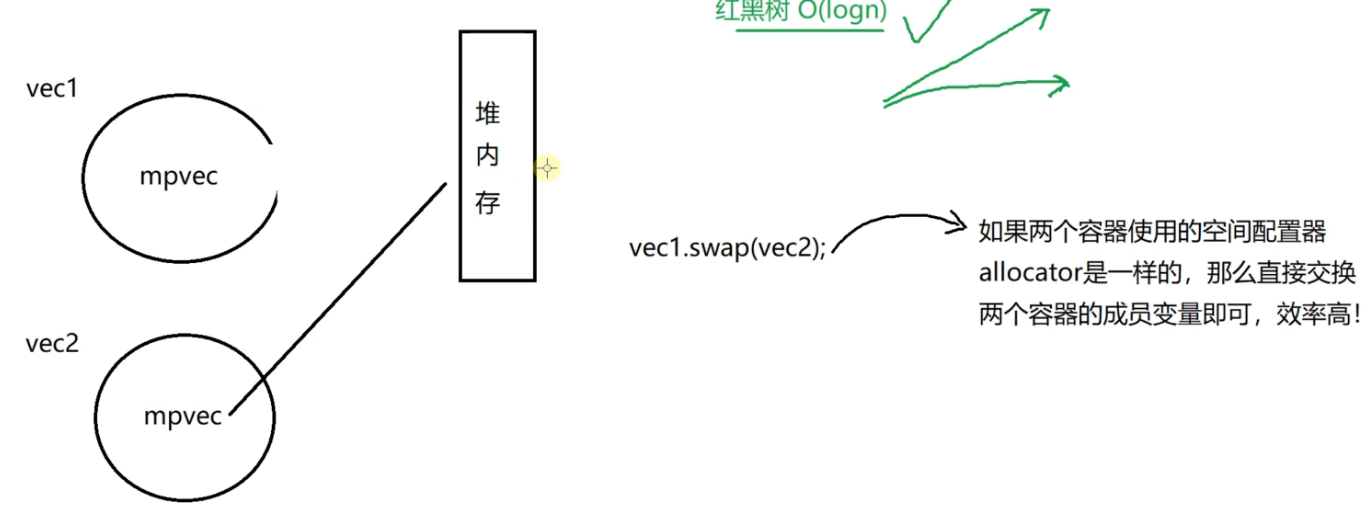
两个vector的swap交换图解: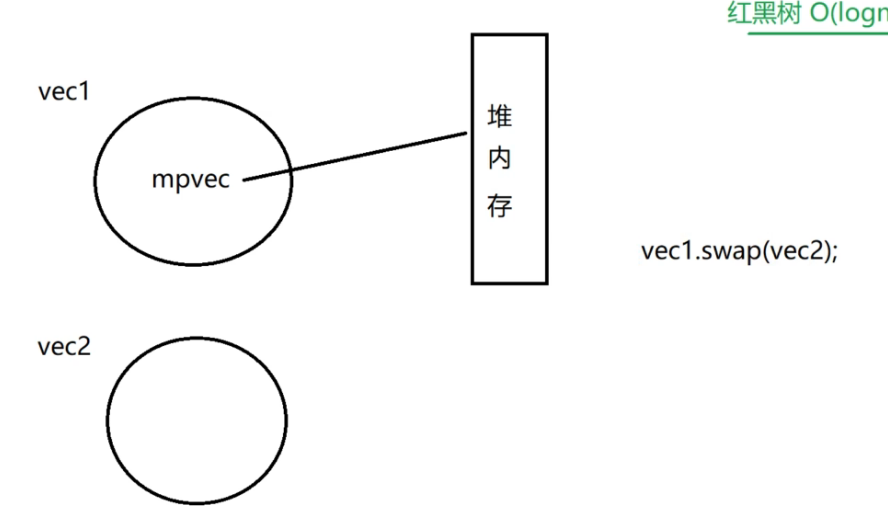

比如说一个容器是从内存池取出的内存进行管理,一个容器是普通的释放内存free方法。这样就不能简单的成员变量交换了。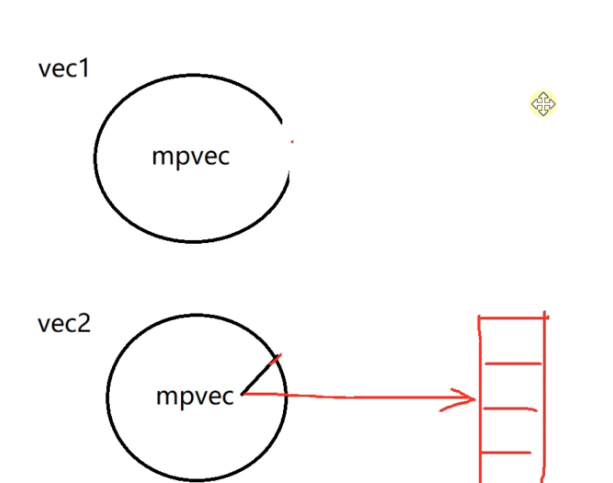
#include <iostream>#include <vector>#include <list>#include <algorithm>using namespace std;//链式哈希表class HashTable{public:HashTable(int size = primes_[0], double loadFactor = 0.75)//构造函数: useBucketNum_(0), loadFactor_(loadFactor), primeIdx_(0){if (size != primes_[0]){for (; primeIdx_ < PRIME_SIZE; primeIdx_++){if (primes_[primeIdx_] >= size)break;}if (primeIdx_ == PRIME_SIZE){primeIdx_--;}}table_.resize(primes_[primeIdx_]);}public://增加元素 不能重复插入keyvoid insert(int key){//判断扩容double factor = useBucketNum_ * 1.0 / table_.size();cout << "factor:" << factor << endl;if (factor > loadFactor_){expand();}int idx = key % table_.size();//O(1)if (table_[idx].empty()){useBucketNum_++;table_[idx].emplace_front(key);//头插法}else{//使用全局的::find泛型算法,而不是调用自己的成员方法find,要去重auto it = ::find(table_[idx].begin(), table_[idx].end(), key);//O(n)if (it == table_[idx].end()){//key不存在table_[idx].emplace_front(key);}}}//删除元素void erase(int key){int idx = key % table_.size();//O(1)// 如果链表节点过长:如果散列结果比较集中(散列函数有问题!!!)// 如果散列结果比较离散,链表长度一般不会过长,因为有装载因子auto it = ::find(table_[idx].begin(), table_[idx].end(), key);//O(n)if (it != table_[idx].end()){table_[idx].erase(it);if (table_[idx].empty()){useBucketNum_--;}}}//搜索元素bool find(int key){int idx = key % table_.size();//O(1)auto it = ::find(table_[idx].begin(), table_[idx].end(), key);return it != table_[idx].end();}private://扩容函数void expand(){if (primeIdx_ + 1 == PRIME_SIZE){throw "hashtable can not expand anymore!";}primeIdx_++;useBucketNum_ = 0;vector<list<int>> oldTable;//swap会不会效率很低???//swap效率是非常高的,因为它只是交换了两个容器的成员变量,没有交换堆内存和表数据table_.swap(oldTable);//table成了空的内容,oldtable存储旧的哈希表内容table_.resize(primes_[primeIdx_]);//扩容for (auto list : oldTable){for (auto key : list)//能进来这个for循环说明这个链表是有数据的{int idx = key % table_.size();if (table_[idx].empty()){useBucketNum_++;}table_[idx].emplace_front(key);}}}private:vector<list<int>> table_;//哈希表的数据结构int useBucketNum_;//记录已使用的桶的个数double loadFactor_;//记录哈希表装载因子static const int PRIME_SIZE = 10;//素数表的大小static int primes_[PRIME_SIZE];//素数表int primeIdx_;//当前使用的素数下标};int HashTable::primes_[PRIME_SIZE] = {3, 7, 23, 47, 97, 251, 443, 911, 1471, 42773 };int main(){HashTable htable;htable.insert(21);htable.insert(32);htable.insert(14);htable.insert(15);htable.insert(22);htable.insert(67);cout << htable.find(67) << endl;htable.erase(67);cout << htable.find(67) << endl;return 0;}
哈希表总结

散列函数:


二次探测:比如说插入78,发现发生哈希冲突了,就在它的右边找一次,然后左边找一次,然后右边找一次,然后左边找一次…是对线性探测的优化




























还没有评论,来说两句吧...