A Unified Generative Framework for Aspect-Based Sentiment Analysis
这篇文章作者来自复旦大学,主要设计了一个框架,将细粒度情感分析众多子问题转化成统一的生成问题。
paper
code
文章目录
- 任务定义
- 模型
- 模型特点
- 模型结构
- 实验
- 度量方法
- 数据集
- 实验组
任务定义
首先,作者总结了Aspect-based Sentiment Analysis(ABSA)的七个子任务,分别如下: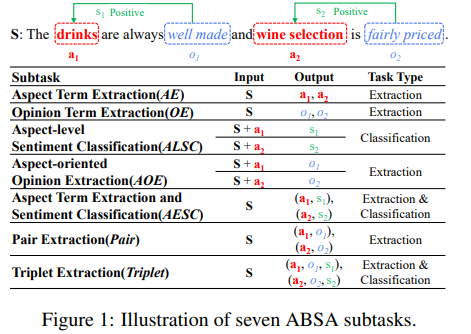
这七个子任务根据类型可以分为两种:抽取问题、分类问题。作者将这两类任务统一转换成了生成任务,作者规范了转换目标序列定义,如Triplet这个子任务目标序列为 a s a e o s o e s p < / s > a^sa^eo^so^es^p asaeosoesp,分别代表aspect开始和结束坐标(0,len-1),opinion开始和结束坐标,情感倾向tag(NEU,POS,NEG),序列结束符号 。
- 只需要输入句子S
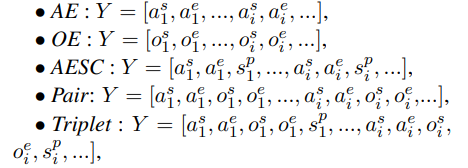
- 特别的,需要输入句子S+方面词a,作者将输入的a放在目标生成序列中,即下划线是根据输入给定的aspect监督生成的。
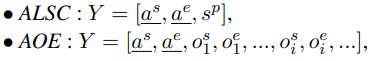
模型

模型特点
- 以BART作为生成模型
- 以生成方式统一任务方案
模型结构
- 输入层:句首加入 < s >
句尾加入 < / s > - 编码层:
首先将输入的embedding过一遍BART Encoder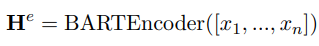
然后经过一个全连接层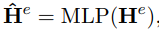
将输出与输入embedding残差链接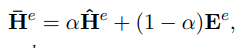
将上面向量与情感类别集合的BARTTokenEmbed拼接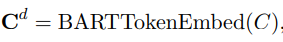
- 解码层:
将BARTEncoder的输出+(1-t-1)时刻BARTDecoder的输出作为BARTDecoder输入,由于BARTDecoder输出的全是索引下标,所以需要用一个index2token模块去转换成token输入。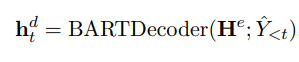
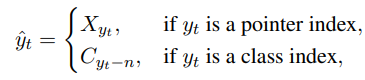
yt<n 就是原句的下表索引 X y t X_{y_t} Xyt,如果大于n则是情感类别 C y t − n C_{y_t-n} Cyt−n - 输出层:
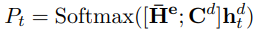
将encoder最后的向量表示拼接情感类别token的embedding,与decoder输出隐向量点乘过一层softmax做分类得到输出token索引下标
实验
度量方法
P, R, F1:一个sample正确的条件是aspect、opinoin边界完全一致,情感极性也与标签相同。
数据集
14, 15 ,16 res/lap
实验组
- 针对不同的baseline适用于不同的子任务,作者将baseline分为三大组实验比较
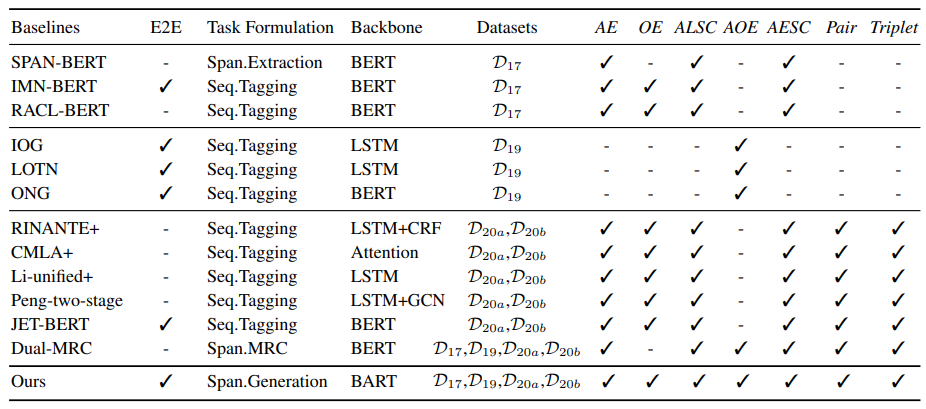
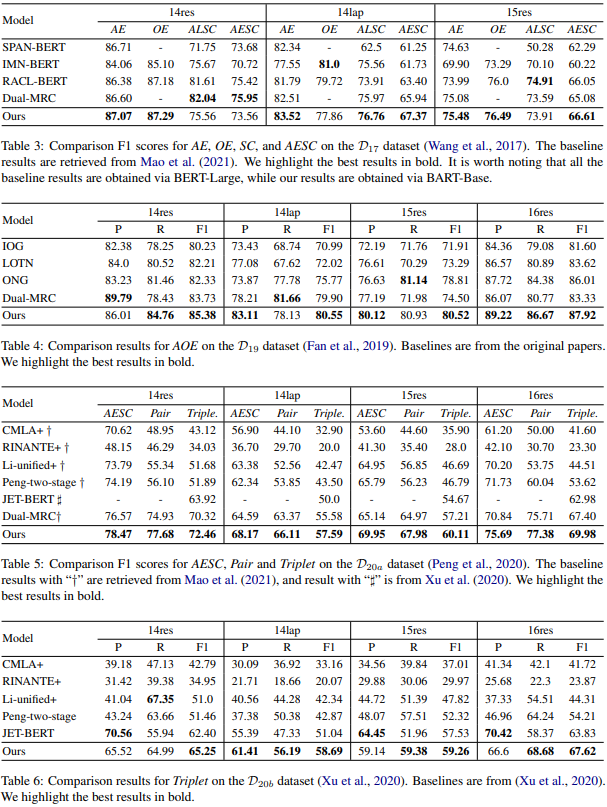
在整体上这个模型的表现还是挺好的,似乎在给定aspect的任务上(ALSC,AOE)有些时候表现不如BMRC,QA方法在给定目标的时候有比较好的表现方法。 - 作者分析模型错误的预测序列占比,所谓错误的序列分为三种:invalid size(序列长度不是5), invalid order(起始位置大于终止位置), invalid token(起始位置或终止位置不在序列下标索引范围内)
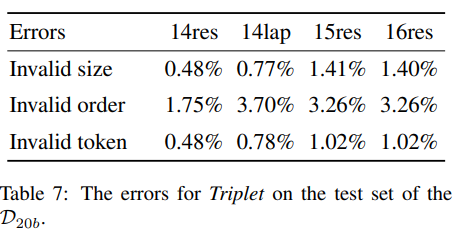
- 作者分析beam search 的搜索范围对结果的影响,实验证明影响很少
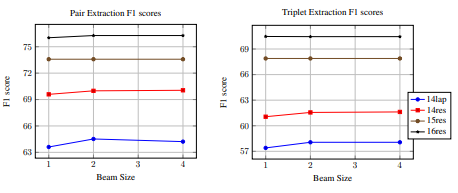


























")


")




还没有评论,来说两句吧...