论文阅读笔记:Distilling the Knowledge in a Neural Network论文阅读
- 论文原文链接 原文链接
Distilling the Knowledge in a Neural Network
作者想要解决的问题
- 在模型训练的时候,为了保证模型的精度,我们可以使用达到模型,大的数据集,花费大量的时间、存储、计算资源去训练。但是在模型实际部署的时候,往往需要考虑延迟已经部署设备的资源限制。所以在部署阶段对模型进行压缩是有必要的。
用了什么方法解决
- 作者认为一个大网络是一个许多不同小模型的集合。大网络的输出是这些小模型输出的一个平均。如果大模型的效果很好的话。那么通过与大模型产生结果一样的训练方式去训练小模型会比直接训练小模型的效果好很多。
- 所以作者提出了使用”soft target”来训练小模型。与一般的训练方法不同的是,小模型不再直接学习真实的标签,因为真实的标签出来正确的类别为1之外,其他类别都为0。而教师网络的输出”soft target”可以使得所有的类别有一个值。
1 知识蒸馏
通常对于分类任务来说,模型都希望正确模型所输出的概率最大化,所以在模型的最后一层都会有一个soft max函数。但是这会有一个副作用,就是所赋予的非正确类别概率很小。而在这些对于非正确概率预测中隐含了教师网络如何对数据进行泛化。
于是作者在soft max函数中加了温度参数T。使得教师网络的输出预测尽可能的平滑。
q i = e x p ( z i / T ) ∑ j e x p ( z j / T ) q_i=\frac{exp(z_i/T)}{\sum_jexp(z_j/T)} qi=∑jexp(zj/T)exp(zi/T)
当温度参数等于1的时候,为正常的输出。当温度参数大于1的时候,即为蒸馏。
为此在新定义的soft max函数上,计算学生网络输出与教师网络输出的交叉熵。以下是计算梯度的过程
当T足够大时:
如果岩本都是经过零均值化,那么公式可以写成以下形式
这里可以看到计算出来的梯度多了一个 1 T 2 \frac{1}{T^2} T21,所以在实际实现的过程中,需要对相对”soft target”的loss乘以T^2以保证soft target和真实标签的loss对梯度的贡献是一样的。 下图引用自引用自XMU_MIAO
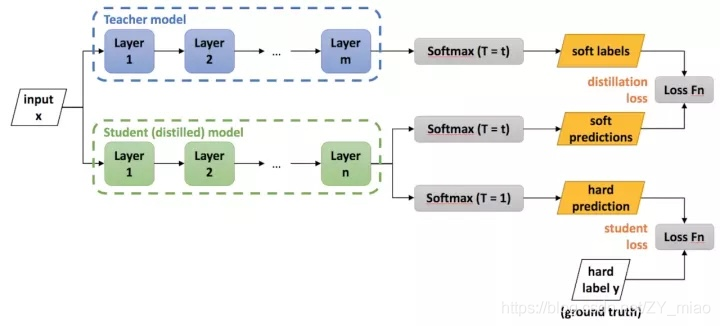
- 根据上图我们可以知道,当我们知道数据集的真实标签时,我们可以使用真实值的标签和教师网络所输出的soft target来对学生网络进行训练。
- 当我们不知道数据集的真实标签时,我们可以直接使用教师网络所输出的soft target来对学生网络进行训练。




























还没有评论,来说两句吧...