专升本计算机综合-数据结构篇
数据结构篇
- 数据结构是数据的组织形式,可以用来表征特定的对象数据。在计算机程序设计中,操作的对象是各式各样的数据,这些数据往往拥有不同的数据结构,例如数组、结构体、指针和链表等。
- 数据结构+算法+程序设计语言=程序。
- 数据结构是算法实现的基础。
1、数据结构概述
数据结构是计算机中对数据的一种存储和组织方式,同时也泛指相互之间存在一种或多种特定关系的数据的集合。
1.1 什么是数据结构?
- 数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
- 业界许多专家都对其有相关定义,具体不多做赘述……
- 笔者理解的数据结构:一个数据结构是由数据元素依据某种逻辑联系组织起来的,对数据元素间逻辑关系的描述称为数据的逻辑结构。由于数据必须在计算机内存储,数据的存储结构是其在计算机内的表示,也就是数据结构的实现形式。
1.2 一些基本概念
- 数据(Data):数据是信息的载体,能够被计算机识别、存储和加工处理,是计算机程序加工的“原材料”。
- 数据元素(Data Element):数据元素是数据的基本单位,也称为元素、结点、顶点、记录等。
- 一般来说,一个数据元素可以由若干个数据项组成,数据项是具有独立含义的最小标识单位。数据项也可称为字段、域、属性等。
- 数据结构(Data Structure):数据结构指的是数据之间的相互关系,也就是数据的组织形式。
1.3 数据结构的内容
- 数据的逻辑结构(Logical Structure):也就是数据元素(Data Element)之间的逻辑关系。数据的逻辑结构是从逻辑关系上描述数据的,与数据在计算机中如何存储无关,也就是独立于计算机的抽象概念。
- 数据的存储结构(Storage Structure):也就是数据元素(Data Element)及其逻辑关系在计算机存储器中的表示形式。
- 数据的运算:也就是能够对数据施加操作。数据的运算基础在于数据的逻辑结构上,每种逻辑结构都可以归纳一个运算的集合。
具体案例:
- 某班级学生成绩表
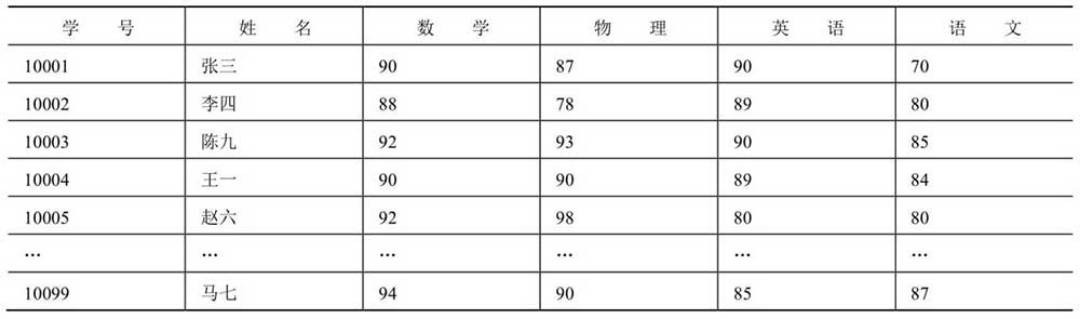
- 每一行可以看作是一个数据元素(Data Element),也可以称为记录或者结点。这个数据元素由学号、姓名、数学成绩、物理成绩、英语成绩和语文成绩等数据项构成。
这个表中的逻辑关系:
对表中任意一个结点,直接前趋(Immediate Predecessor)结点最多只有一个。直接前趋结点也就是与它相邻且在它前面的结点。
- 对表中任意一个结点,直接后继(Immediate Successor)结点最多只有一个。直接后继结点也就是与它相邻且在它后面的结点。
表中只有第一个结点没有直接前趋,也就是开始结点。
- 表中只有最后一个结点没有直接后继,也就是终端结点。
- 例如,表中“张三”所在的结点就是开始结点,“马七”所在的结点就是终端结点。表中间的“陈九”所在结点的直接前趋结点是“李四”所在的结点,表中间的“陈九”所在结点的直接后继结点是“王一”所在的结点。这些结点关系就构成了某班级学生成绩表的逻辑结构。
- 再来看一下数据的存储结构:
我们知道数据的存储结构是数据元素及其逻辑关系在计算机存储器中的表示形式。
- 这就需要采用计算机语言来进行描述,例如,是每个结点按照顺序依次存储在一片连续的存储单元中呢,还是存储在分散的空间而使用指针将这些结点链接起来呢?
- 这方面的内容将在后面进行详细讲述。
再来看一下数据的运算:
- 拿到这个表之后,会进行哪些操作呢?一般来说,主要包括如下操作:
- 查找某个学生的成绩。
对于新入学的学生,在表中增加一个结点来存放。
- 对于退学的学生,将其结点从表中删除。
其实,数据的逻辑结构、存储结构和运算是一个整体,单独地去理解这三者中的任何一个都是不全面的,这主要表现在如下两点:
- (1)同一个逻辑结构可以有不同的存储结构。
- (2)同一种逻辑结构也可以有不同的数据运算集合。
1.4 数据结构的分类
- 数据结构的分类:分为线性结构与非线性结构。
- 线性结构就是表中各个结点具有线性关系。用数据结构的语言来描述,线性结构应该包括如下几点:
- 线性结构是非空集。
- 线性结构有且仅有一个开始结点和一个终端结点。
- 线性结构所有结点都最多只有一个直接前趋结点和一个直接后继结点。
- 典型的线性结构:线性表、栈、队列、串。
非线性结构就是表中各个结点之间具有多个对应关系。用数据结构的语言来描述,非线性结构应该包括如下几点:
- 非线性结构是非空集。
- 非线性结构的一个结点可能有多个直接前趋结点和多个直接后继结点。
- 典型的非线性结构:数组、广义表、树结构、图结构。
- 数据结构的存储方式:顺序存储方式、链式存储方式、索引存储方式、散列存储方式。
- 顺序存储方式:就是在一块连续的存储区域一个接着一个地存放数据。
- 一般采用数组或结构数组来描述。
链接存储方式:不要求逻辑上相邻的结点在物理位置上相邻,结点间的逻辑关系由附加的指针字段表示。一个结点的指针字段往往指向下一个结点的存放位置。
- 一般在原数据项中增加指针类型来表示结点之间的位置关系。
索引存储方式:采用附加的索引表的方式来存储结点信息。
- 索引存储方式中索引项的一般形式如下所示:
( 关 键 字 . 地 址 ) (关键字.地址) (关键字.地址) - 其中,关键字是能够唯一标识一个结点的数据项。
- 索引存储方式还可以细分为两类:稠密索引、稀疏索引。
- 索引存储方式中索引项的一般形式如下所示:
- 散列存储方式:根据结点的关键字直接计算出该结点的存储地址的一种存储方式。
在实际应用中,需要根据具体数据结构来确定采用哪种数据结构。
1.5 数据类型
- 数据类型:就是一个值的集合以及在这些值上定义的一系列操作的总称。
抽象数据类型(ADT): 数据的组织及其相关的操作,可以看作是数据的逻辑结构及其在逻辑结构上定义的操作。
一个抽象数据类型可以定义为如下形式:
ADT 抽象数据类型名{数据对象:<数据对象的定义>数据关系:<数据关系的定义>基本操作:<基本操作的定义>} ADT 抽象数据类型名
- 抽象数据类型一般具有两个特征:数据抽象、数据封装。
1.6 常用的数据结构
- 数组:将具有相同类型的若干变量有序地组织在一起的集合。
栈(Stack): 一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。
- 栈按照后进先出的原则来存储数据,也就是说,先插入的数据将被压入栈底,最后插入的数据在栈顶,读出数据时,从栈顶开始逐个读出。
- 栈中没有数据时,称为空栈。
队列(Queue):一种只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
- 进行插入操作的一端称为队尾,进行删除操作的一端称为队头。
- 队列中没有元素时,称为空队列。
- 链表(Linked List):一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。
树(Tree):包括n个结点的有穷集合K。
- 在树结构中,有且仅有一个根结点,该结点没有前驱结点。
- 在树结构中的其他结点都有且仅有一个前驱结点,而且可以有m个后继结点,m≥0。
- 图(Graph): 一种非线性的数据结构,图在实际生活中有很多例子,比如交通运输网,地铁网络,社交网络等等都可以抽象成图结构。
- 堆(Heap):其实就是一棵完全二叉树(若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边)。
- 散列表(Hash):一个包含关键字的具有固定大小的数组,它能够以常数时间执行插入,删除和查找操作。
2、线性表
2.1 什么是线性表?
从逻辑上来看,线性表就是由n(n≥0)个数据元素a1,a2,…,an组成的有限序列。
几点说明:
- 数据元素的个数为n,也称为表的长度,当n=0时称为空表。
- 如果一个线性表非空,也就是n>0,则可以简单地记作(a1,a2,……,an)。
- 数据元素ai(1≤i≤n)表示各个元素,不同的场合,其含义也不尽相同。
线性表栗子:
- 英文字母表就是最简单的线性表,英文字母表(A,B,C,…,Z)中,每个英文字符就是一个数据元素,也称为数据结点。
- 另外,如前面所示的某班级学生成绩表也是一个线性表,其中的数据元素就是某个学生的记录,包括学号、姓名、各个科目的成绩等。
对于一个非空的线性表,具有如下所示的逻辑结构特征:
- 有且仅有一个开始结点a1,没有直接前趋结点,有且仅有一个直接后继结点a2。
- 有且仅有一个终结结点an,没有直接后继结点,有且仅有一个直接前趋结点an-1。
- 其余的内部结点ai(2≤i≤n-1)都有且仅有一个直接前趋结点ai-1和一个直接后继结点ai+1。
- 对于同一线性表,各数据元素ai必须具有相同的数据类型,即同一线性表中各数据元素具有相同的类型,每个数据元素的长度相同。
2.2 线性表的基本运算
1.初始化
- 初始化表(InitList)也就是构造一个空的线性表L。
2.计算表长
- 计算表长(ListLength)也就是计算线性表L中结点的个数
3.获取结点
- 获取结点(GetNode)就是取出线性表L中第i个结点的数据,这里1≤i≤ListLength(L)。
4.查找结点
- 查找结点(LocateNode)就是在线性表L中查找值为x的结点,并返回该结点在线性表L中的位置。如果在线性表中没有找到值为x的结点,则返回一个错误标志。这里需要注意的是,线性表中有可能含有多个与x值相同的结点,那么这时就只返回第一次查找到的结点。
5.插入结点
- 插入结点(InsertList)就是在线性表L的第i个位置上插入一个新的结点,使得其后的结点编号依次加1。这时,插入1个新结点之后,线性表L的长度将变为n+1。
6.删除结点
- 删除结点(DeleteList)就是删除线性表L中的第i个结点,使得其后的所有结点编号依次减1。这时,删除1个结点之后,线性表L的长度将变为n-1。
在计算机中线性表可以采用两种方式来保存,一种是顺序存储结构,另一种是链式存储结构。
顺序存储结构的线性表称为顺序表,链式存储的线性表称为链表。
2.3 顺序表结构
- 按照顺序存储方式存储的线性表称为顺序表。
- 该线性表的结点按照逻辑次序依次存放在计算机的一组连续的存储单元中。
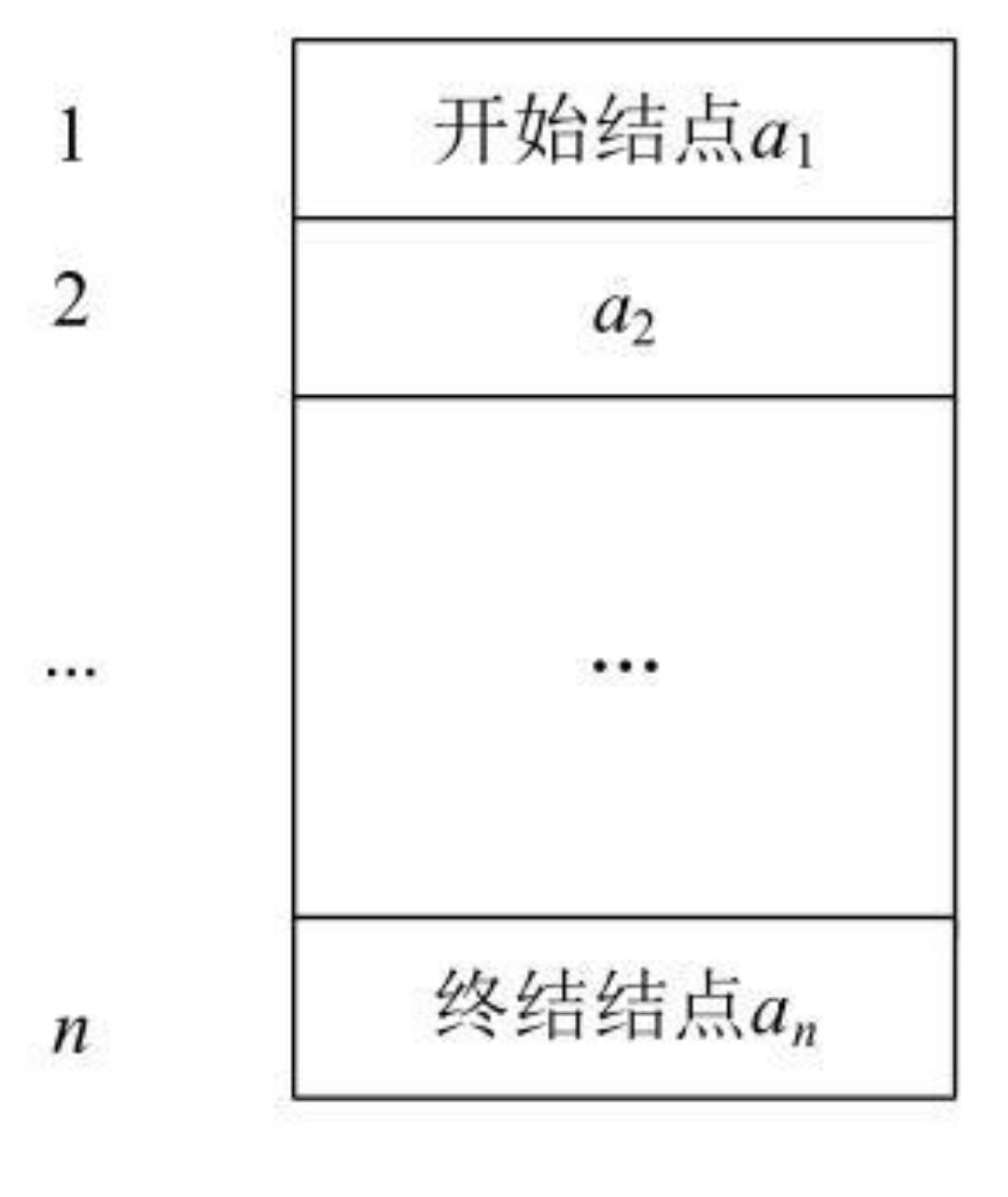
- 由于顺序表是依次存放的,只要知道了该顺序表的首地址以及每个数据元素所占用的存储长度,很容易计算出任何一个数据元素(也就是数据结点)的位置。
- 假设顺序表中所有结点的类型相同,则每个结点所占用存储空间的大小亦相同,每个结点占用c个存储单元。其中第1个单元的存储地址则是该结点的存储地址,并设顺序表中开始结点a1的存储地址(简称为基地址)是LOC(a1),那么结点ai的存储地址LOC(ai)可通过下式计算得到。
L O C ( a i ) = L O C ( a 1 ) + ( i − 1 ) ∗ c ( 1 ≤ i ≤ n ) LOC(a_i)=LOC(a_1)+(i-1)*c (1≤i≤n) LOC(ai)=LOC(a1)+(i−1)∗c (1≤i≤n)
2.4 顺序表结构的程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
define MAXLEN 100 // 定义顺序表的最大长度
typedef struct
{char kay[10]; // 结点的关键字char name[20];int age;
}DATA; // 定义结点类型
typedef struct // 定义顺序表结构
{DATA ListData[MAXLEN + 1]; // 保存顺序表的结构数组int ListLen; // 顺序表已存在的结点数量
}SLType;
// 在这里可以认为该顺序表是一个班级学生的记录。
// 其中,key为学号,name为学生的名称,age为年龄。
初始化线性表
- 创建一个空的顺序表。
- 具体代码:
void SLInit(SLType *SL) // 初始化顺序表
{SL->ListLen = 0; // 初始化为空表
}
计算顺序表的长度
- 计算线性表L中的结点个数。
- 具体代码:
int SLLength(SLType *SL)
{return (SL->ListLen); // 返回顺序表的元素数量
}
插入结点
- 在线性表第i个位置插入一个新结点,使得其后的结点编号加1。
- 具体代码:
// 本算法将实现将元素data插入到顺序表SL中的第i个位置
int SLInsert(SLType *SL, int i, DATA data)
{int j;if (SL->ListLen >= MAXLEN) // 当前存储空间已满,不能插入{printf("顺序表已满,不能插入结点! \n");return 0; // 返回0表示不能插入}if (i<1 || i > SL->ListLen - 1) // 判断i的范围是否有效{printf("插入元素序号错误,不能插入元素! \n");return 0; // 返回0,表示插入失败}for (j = SL->ListLen; j >= i; j--) // 将顺序表中的数据向后移动{SL->ListData[i + 1] = SL->ListData[i];}SL->ListData[i] = data; // 插入结点SL->ListLen++; // 顺序表长度加1return i; // 插入成功,返回i
}
追加结点
- 在线性表的末尾再增加一个数据结点。
- 具体代码:
int SLAdd(SLType *SL, DATA data) // 增加元素到顺序表尾部
{if (SL->ListLen >= MAXLEN) // 顺序表已满{printf("顺序表已满,不能再添加结点了! \n");return 0;}SL->ListData[++SL->ListLen] = data;return 1;
}
删除结点
- 删除线性表中的第i个结点,使其后所有结点编号依次减1。
- 具体代码:
// 本算法将实现删除顺序表SL中的第i个位置的元素
int SLDelete(SLType *SL, int i)
{int j;if (i<1 || i > SL->ListLen) // 判断i的范围是否有效{printf("删除结点序号错误,不能删除结点! \n");return 0; // 返回0,表示删除失败}for (j = i; j < SL->ListLen; j--) // 将顺序表中的数据向前移动{SL->ListData[i] = SL->ListData[i+1];}SL->ListLen--; // 顺序表长度减1return 1; // 删除成功,返回1
}
查找结点
- ①按序号查找结点。序号:数组的下标号。
- 具体实现:
DATA SLFindByNum(SLType SL, int i) // 根据序号返回数据元素
{if (i<1 || i > SL->ListLen + 1) // 元素序号不正确{printf("结点序号错误,不能返回结点! \n");return NULL; // 不成功,返回0}return &(SL->ListData[i]);
}
②按关键字查找结点。
- 此处以上文中的key为关键字,key为学生的学号。
- 具体实现:
DATA SLFindByCont(SLType SL, char *key) // 根据关键字查询结点
{int i;for (i = 1; i <= SL->ListLen; i++){if (strcmp(SL->ListData[i].key,key)==0) // 如果找到所需结点{return i; // 返回结点序号}}return 0; // 搜索整个顺序表后未找到,返回0
}
strcmp() 函数用于对两个字符串进行比较(区分大小写)。头文件:string.h
显示所有结点
- 扫描顺序表,输出各元素的值。
- 具体代码:
int SLAll(SLType *SL) // 显示顺序表中所有的结点
{int i;for (i = 1; i <= SL->ListLen; i++){printf("(%s, %s, %d) \n", SL->ListData[i].key, SL->ListData[i].name, SL->ListData[i].age);}return 0;
}
- 案例:对某班级学生学号、姓名和年龄数据进行顺序表操作。
完整代码:
include
include
define MAXLEN 100 // 定义顺序表的最大长度
typedef struct
{char key[10]; // 结点的关键字char name[20];int age;
}DATA; // 定义结点类型
typedef struct // 定义顺序表结构
{DATA ListData[MAXLEN + 1]; // 保存顺序表的结构数组int ListLen; // 顺序表已存在的结点数量
}SLType;
void SLInit(SLType *SL) // 初始化顺序表
{SL->ListLen = 0; // 初始化为空表
}
int SLLength(SLType *SL)
{return (SL->ListLen); // 返回顺序表的元素数量
}
// 本算法将实现将元素data插入到顺序表SL中的第i个位置
int SLInsert(SLType *SL, int i, DATA data)
{int j;if (SL->ListLen >= MAXLEN) // 当前存储空间已满,不能插入{printf("顺序表已满,不能插入结点! \n");return 0; // 返回0表示不能插入}if (i<1 || i > SL->ListLen - 1) // 判断i的范围是否有效{printf("插入元素序号错误,不能插入元素! \n");return 0; // 返回0,表示插入失败}for (j = SL->ListLen; j >= i; j--) // 将顺序表中的数据向后移动{SL->ListData[i + 1] = SL->ListData[i];}SL->ListData[i] = data; // 插入结点SL->ListLen++; // 顺序表长度加1return i; // 插入成功,返回i
}
int SLAdd(SLType *SL, DATA data) // 增加元素到顺序表尾部
{if (SL->ListLen >= MAXLEN) // 顺序表已满{printf("顺序表已满,不能再添加结点了! \n");return 0;}SL->ListData[++SL->ListLen] = data;return 1;
}
// 本算法将实现删除顺序表SL中的第i个位置的元素
int SLDelete(SLType *SL, int i)
{int j;if (i<1 || i > SL->ListLen) // 判断i的范围是否有效{printf("删除结点序号错误,不能删除结点! \n");return 0; // 返回0,表示删除失败}for (j = i; j < SL->ListLen; j--) // 将顺序表中的数据向前移动{SL->ListData[i] = SL->ListData[i+1];}SL->ListLen--; // 顺序表长度减1return 1; // 删除成功,返回1
}
DATA SLFindByNum(SLType SL, int i) // 根据序号返回数据元素
{if (i<1 || i > SL->ListLen + 1) // 元素序号不正确{printf("结点序号错误,不能返回结点! \n");return NULL; // 不成功,返回0}return &(SL->ListData[i]);
}
DATA SLFindByCont(SLType SL, char *key) // 根据关键字查询结点
{int i;for (i = 1; i <= SL->ListLen; i++){if (strcmp(SL->ListData[i].key,key)==0) // 如果找到所需结点{return i; // 返回结点序号}}return 0; // 搜索整个顺序表后未找到,返回0
}
int SLAll(SLType *SL) // 显示顺序表中所有的结点
{int i;for (i = 1; i <= SL->ListLen; i++){printf("(%s, %s, %d) \n", SL->ListData[i].key, SL->ListData[i].name, SL->ListData[i].age);}return 0;
}
int main()
{int i;SLType SL; // 定义顺序表DATA data; // 定义节点保存数据类型DATA *pdata; // 定义结点保存指针char key[10]; // 保存关键字printf("顺序表操作演示: \n");SLInit(&SL); // 初始化顺序表printf("初始化顺序表完成! \n");do { //循环添加数据结点printf("输入要添加的结点(学号 姓名 年龄): \n");fflush(stdin); // 清空输入缓冲区scanf("%s %s %d", &data.key, &data.name, &data.age);if (data.age) // 如果年龄不为0{if (!SLAdd(&SL, data)) // 若添加结点失败{break; // 退出死循环}}else { // 若年龄为0break; //退出死循环}} while (1);printf("\n顺序表中的结点顺序为:\n");SLAll(&SL); // 显示所有结点数据fflush(stdin); // 清空输入缓冲区printf("\n要取出的结点的序号:");scanf("%d", &i); // 输入结点序号pdata = SLFindByNum(&SL, i); // 按序号查找结点if (pdata) // 若返回的结点指针不为空{printf("第%d个结点为:(%s ,%s ,%d) \n", i, pdata->key, pdata->name, pdata->age);}fflush(stdin); // 清空输入缓冲区printf("\n要查找的结点的关键字:");scanf("%s", key); // 输入关键字i = SLFindByCont(&SL, key); // 按关键字查找结点,返回结点序号pdata = SLFindByNum(&SL, i); // 按序号查找结点if (pdata) // 若返回的结点指针不为空{printf("第%d个结点为:(%s ,%s ,%d) \n", i, pdata->key, pdata->name, pdata->age);}getchar();return 0;
}
顺序表结构的存储方式非常容易理解,操作也十分方便。但是顺序表结构有如下一些缺点:
- 在插入或者删除结点时,往往需要移动大量的数据,影响运行效率。
- 如果表比较大,有时难以分配足够的连续存储空间,往往导致内存分配失败,而无法存储。
为了克服顺序表结构的以上缺点,可以采用链表结构。
2.5 什么是链表结构?
- 链表结构是一种动态存储分配的结构形式,可以根据需要动态申请所需的内存单元。
- 最常用的链表结构:单链表、双向链表和循环列表。
链表中每个结点都包括如下两部分:
- 数据部分:保存的是该结点的实际数据。
- 地址部分:保存的是下一个结点的地址。
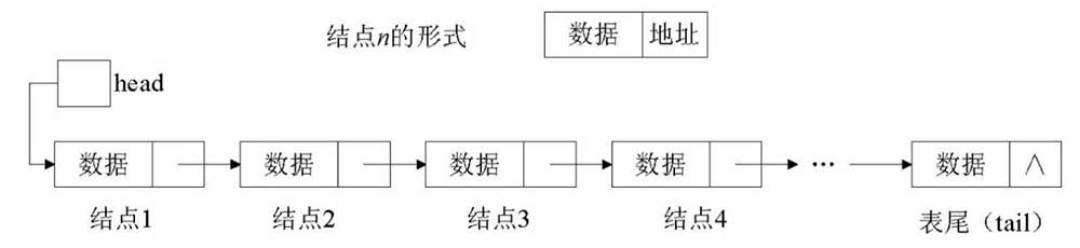
- 链表结构是由许多结点构成。
在进行链表操作时:
- 首先需要定义1个“头指针”变量(一般以head表示),该指针变量指向链表结构的第一个结点;
- 第1个结点的地址部分又指向第2个结点……直到最后一个结点;
- 最后一个结点不再指向其他结点,称为“表尾”;
- 一般在表尾的地址部分放一个空地址NULL,链表到此结束。
链表结构的优点:
- 动态数据结构:链表是一种动态数据结构,因此它可以在运行时通过分配和取消分配内存来增长和缩小。所以没有必要给出链表的初始大小。
- 易于插入和删除:在链表中进行插入和删除节点真的很容易。与数组不同,我们不必在插入或删除元素后移位元素。在链表中,我们只需要更新节点下一个指针中的地址。
- 内存利用率高:由于链表的大小可以在运行时增加或减少,因此没有内存浪费。在数组的情况下,存在大量的内存浪费,就像我们声明一个大小为10的数组并且只存储6个元素,那么浪费了4个元素的空间。链表中没有这样的问题,因为只在需要时才分配内存。
注意:用户可以malloc函数动态分配结点的存储空间,当删除某个结点时,应该使用free函数释放其占用的内存空间。
链表结构的缺点:
- 内存的使用:与数组相比,在链表中存储元素需要更多内存。因为在链表中每个节点都包含一个指针,它需要额外的内存。
- 遍历困难,不易于查询:链表中的元素或节点遍历很困难,访问元素的效率低。我们不能像索引一样随机访问任何元素。例如,如果我们想要访问位置n的节点,那么我们必须遍历它之前的所有节点。因此,访问节点所需的时间很长。
- 反向遍历困难:在链表中反向遍历非常困难。在双链表的情况下,后指针需要更容易但额外的内存因此浪费内存。
- 单链表:向上面的链式结构一样,每个结点中只包含一个指针。
- 双向链表:若每个结点包含两个指针,一个指向下一个结点,另一个指向上一个结点,这就是双向链表。
- 单循环链表:在单链表中,将终端结点的指针域NULL改为指向表头结点或开始结点即可构成单循环链表。
- 多重链的循环链表:如果将表中结点链在多个环上,将构成多重链的循环链表。
2.6 链表结构的程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
typedef struct
{char key[10]; // 关键字char name[20];int age;
}Data;
typedef struct Node // 定义链表结构
{Data nodeData; // 数据域nodeDatastruct Node *nextNode; // 指针域nextNode
}CLType;
尾插法
- 将新结点插入到当前链表的表尾。
- 由于一般情况下链表只有一个头指针head,所以要在末尾添加结点就需要从头指针head开始逐个检查,直到找到最后一个结点(即表尾)。

追加结点的操作步骤如下:
- (1)首先分配内存空间,保存新增的结点。
- (2)从头指针head开始逐个检查,直到找到最后一个结点(即表尾)。
- (3)将表尾结点的地址设置为新增结点的地址。
- (4)将新增结点的地址部分设置为空地址NULL,即新增结点成为表尾。
具体代码:
CLType CLAddEnd(CLType head, Data nodeData) // 尾插法
{CLType *node, *htemp;if (!(node = (CLType *)malloc(sizeof(CLType)))){printf("申请内存失败!\n");return NULL; // 分配内存失败}else {node->nodeData = nodeData; // 保存数据node->nextNode = NULL; // 设置结点指针为空,即为表尾if (head == NULL) // 头指针{head = node;return head;}htemp = head;while (htemp->nextNode != NULL) // 查找链表的末尾{htemp = htemp->nextNode;}htemp->nextNode = node;return head;}
}
头插法
- 将新结点插入到当前链表的表头。
插入头结点的步骤如下:
- (1)首先分配内存空间,保存新增的结点。
- (2)使新增结点指向头指针head所指向的结点。
- (3)然后使头指针head指向新增结点。

具体代码:
CLType CLAddFirst(CLType head, Data nodeData) // 头插法
{CLType *node;if (!(node = (CLType *)malloc(sizeof(CLType)))){printf("申请内存失败!\n");return NULL; // 分配内存失败}else {node->nodeData = nodeData; // 保存数据node->nextNode = head; // 指向头指针所指向的结点head=node; // 头指针指向新增结点return head;}
}
查找结点
- 在链表中查找需要的元素。
- ①按序号查找结点。序号:数组的下标号。
- 具体实现:
CLType CLFindByNum(CLType head, int i) // 根据序号返回数据元素
{int j = 1; // 计数,初始为1CLType *htemp=head->nextNode; // 头结点指针赋值给htempif (i == 0)return head; // 若i为0,返回头结点if (i < 1)return NULL; // 若i无效,返回NULLwhile (htemp && j > i) { // 从第一个结点开始查找,查找第i个结点htemp = htemp->nextNode;j++;}return htemp; // 返回第i个结点的指针
}
②按关键字查找结点。
- 具体代码:
CLType CLFindNode(CLType head, char *key) // 查找结点
{CLType *htemp;htemp = head; // 保存链表头指针while (htemp) // 若结点有效,进行查找{if (strcmp(htemp->nodeData.key, key) == 0) // 判断结点关键字与传入关键字是否相同{return htemp; //返回该结点指针}htemp = htemp->nextNode; // 处理下一结点}return NULL; // 返回空指针
}
插入结点
- 在链表中间插入结点。
插入节点操作步骤:
- (1)首先分配内存空间,保存新增的结点。
- (2)找到要插入的逻辑位置,也就是位于哪两个结点之间。
- (3)修改插入位置结点的指针,使其指向新增结点,而使新增结点指向原插入位置所指向的结点。
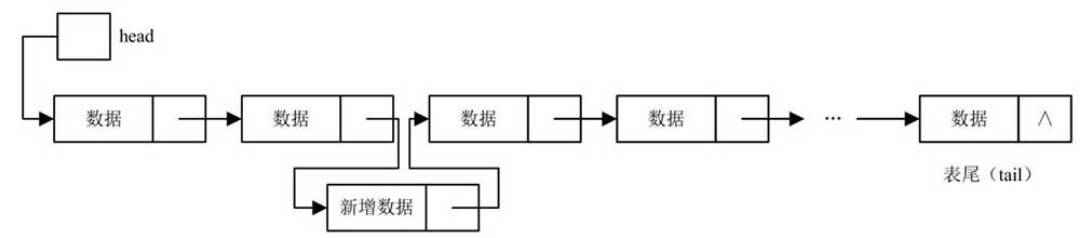
- 具体代码:
CLType CLInsertNode(CLType head, char *findkey, Data nodeData) // 插入结点
{CLType *node, *nodetemp;if (!(node = (CLType *)malloc(sizeof(CLType)))) // 分配保存结点的内容{printf("申请内存失败! \n");return 0; // 分配内存失败}node->nodeData = nodeData;nodetemp = CLFindNode(head, findkey); // 保存结点中的数据if (nodetemp) // 若找到要插入的结点{node->nextNode = nodetemp->nextNode; // 新插入结点指向关键字结点的下一结点nodetemp->nextNode = node; // 设置关键结点指向新插入结点}else {printf("未找到正确的插入位置! \n");free(node); // 释放内存}return head; // 返回头指针
}
删除结点
- 将链表中的某个结点删除。
- 删除结点的操作步骤如下:
- (1)查找需要删除的结点。
- (2)使前一结点指向当前结点的下一结点。
- (3)删除结点。

具体代码:
int CLDeleteNode(CLType head, char key)
{CLType *node, *htemp; // node保存删除结点的前一结点htemp = head;node = head;while (htemp){if (strcmp(htemp->nodeData.key, key) == 0) // 找到关键字,执行删除操作{node->nextNode = htemp->nextNode; // 使前一结点指向当前结点的下一结点free(htemp); // 释放内存return 1;}else {node=htemp; // 指向当前结点htemp = htemp->nextNode; // 指向下一结点}}return 0; // 未删除
}
计算链表的长度
- 统计链表中结点的数量。
- 具体代码:
int CLLength(CLType *head) // 计算链表长度
{CLType *htemp;int Len = 0;htemp = head;while (htemp) // 遍历链表{Len++; // 累加结点数量htemp = htemp->nextNode; // 处理下一结点}return Len; // 返回结点数量
}
显示所有结点
- 扫描顺序表,输出各元素的值。
- 具体代码:
void CLAllNode(CLType *head) // 遍历链表
{CLType *htemp;Data nodeData;htemp = head;printf("当前链表共有%d个结点。链表所有数据如下: \n", CLLength(head));while (htemp) // 循环处理链表的每个节点{nodeData = htemp->nodeData; // 获取结点数据printf("结点(%s, %s, %d) \n", nodeData.key, nodeData.name, nodeData.age);htemp = htemp->nextNode; // 处理下一结点}
}
案例:使用链表操作实现用户管理
- 具体代码:
include
include
include
typedef struct
{char key[10]; // 关键字char name[20];int age;
}Data;
typedef struct Node // 定义链表结构
{Data nodeData; // 数据域nodeDatastruct Node *nextNode; // 指针域nextNode
}CLType;
CLType CLAddEnd(CLType head, Data nodeData) // 尾插法
{CLType *node, *htemp;if (!(node = (CLType *)malloc(sizeof(CLType)))){printf("申请内存失败!\n");return NULL; // 分配内存失败}else {node->nodeData = nodeData; // 保存数据node->nextNode = NULL; // 设置结点指针为空,即为表尾if (head == NULL) // 头指针{head = node;return head;}htemp = head;while (htemp->nextNode != NULL) // 查找链表的末尾{htemp = htemp->nextNode;}htemp->nextNode = node;return head;}
}
CLType CLAddFirst(CLType head, Data nodeData) // 头插法
{CLType *node;if (!(node = (CLType *)malloc(sizeof(CLType)))){printf("申请内存失败!\n");return NULL; // 分配内存失败}else {node->nodeData = nodeData; // 保存数据node->nextNode = head; // 指向头指针所指向的结点head=node; // 头指针指向新增结点return head;}
}
CLType CLFindNode(CLType head, char *key) // 查找结点
{CLType *htemp;htemp = head; // 保存链表头指针while (htemp) // 若结点有效,进行查找{if (strcmp(htemp->nodeData.key, key) == 0) // 判断结点关键字与传入关键字是否相同{return htemp; //返回该结点指针}htemp = htemp->nextNode; // 处理下一结点}return NULL; // 返回空指针
}
CLType CLInsertNode(CLType head, char *findkey, Data nodeData) // 插入结点
{CLType *node, *nodetemp;if (!(node = (CLType *)malloc(sizeof(CLType)))) // 分配保存结点的内容{printf("申请内存失败! \n");return 0; // 分配内存失败}node->nodeData = nodeData;nodetemp = CLFindNode(head, findkey); // 保存结点中的数据if (nodetemp) // 若找到要插入的结点{node->nextNode = nodetemp->nextNode; // 新插入结点指向关键字结点的下一结点nodetemp->nextNode = node; // 设置关键结点指向新插入结点}else {printf("未找到正确的插入位置! \n");free(node); // 释放内存}return head; // 返回头指针
}
int CLDeleteNode(CLType head, char key)
{CLType *node, *htemp; // node保存删除结点的前一结点htemp = head;node = head;while (htemp){if (strcmp(htemp->nodeData.key, key) == 0) // 找到关键字,执行删除操作{node->nextNode = htemp->nextNode; // 使前一结点指向当前结点的下一结点free(htemp); // 释放内存return 1;}else {node=htemp; // 指向当前结点htemp = htemp->nextNode; // 指向下一结点}}return 0; // 未删除
}
int CLLength(CLType *head) // 计算链表长度
{CLType *htemp;int Len = 0;htemp = head;while (htemp) // 遍历链表{Len++; // 累加结点数量htemp = htemp->nextNode; // 处理下一结点}return Len; // 返回结点数量
}
void CLAllNode(CLType *head) // 遍历链表
{CLType *htemp;Data nodeData;htemp = head;printf("当前链表共有%d个结点。链表所有数据如下: \n", CLLength(head));while (htemp) // 循环处理链表的每个节点{nodeData = htemp->nodeData; // 获取结点数据printf("结点(%s, %s, %d) \n", nodeData.key, nodeData.name, nodeData.age);htemp = htemp->nextNode; // 处理下一结点}
}
int main()
{int i;CLType *node, *head=NULL;Data nodeData;char key[10], findkey[10];printf("链表测试,先输入链表中的数据,格式为:关键字 姓名 年龄 \n");do {fflush(stdin); // 清空输入缓冲区scanf("%s", nodeData.key);if (strcmp(nodeData.key, "0") == 0){break; // 若输入为0,则退出}else {scanf("%s %d", nodeData.name, &nodeData.age);head = CLAddEnd(head, nodeData); // 尾插法}} while (1);CLAllNode(head); // 显示所有结点printf("\n演示插入结点,输入插入位置的关键字:");scanf("%s", findkey); // 输入插入位置的关键字printf("输入插入结点的数据(关键字 姓名 年龄):");scanf("%s %s %d", nodeData.key, nodeData.name, &nodeData.age); // 输入插入节点的数据head = CLInsertNode(head, findkey, nodeData); // 调用插入函数CLAllNode(head); // 显示所有结点printf("\n演示删除结点,输入要删除的关键字:");fflush(stdin); // 清空输入缓冲区scanf("%s", key);CLDeleteNode(head, key); // 调用删除结点函数CLAllNode(head); // 显示所有结点printf("\n输入要查找的结点的关键字:");fflush(stdin); // 清空输入缓冲区scanf("%s", key); // 输入关键字node = CLFindNode(head, key); // 按关键字查找结点,返回结点指针if (node) // 若返回的结点指针有效{nodeData = node->nodeData; // 获取结点数据printf("关键字%s对应的结点为:(%s ,%s ,%d) \n", key, nodeData.key, nodeData.name,nodeData.age);}else { // 若结点指针无效printf("在链表中未找到关键字为%s的结点! \n", key);}return 0;
}
测试数据:
2001 admin 12
2002 subei 14
2003 wewef 13
2004 ssddf 15
2005 whhkk 16
3、栈与队列
3.1 什么是栈?
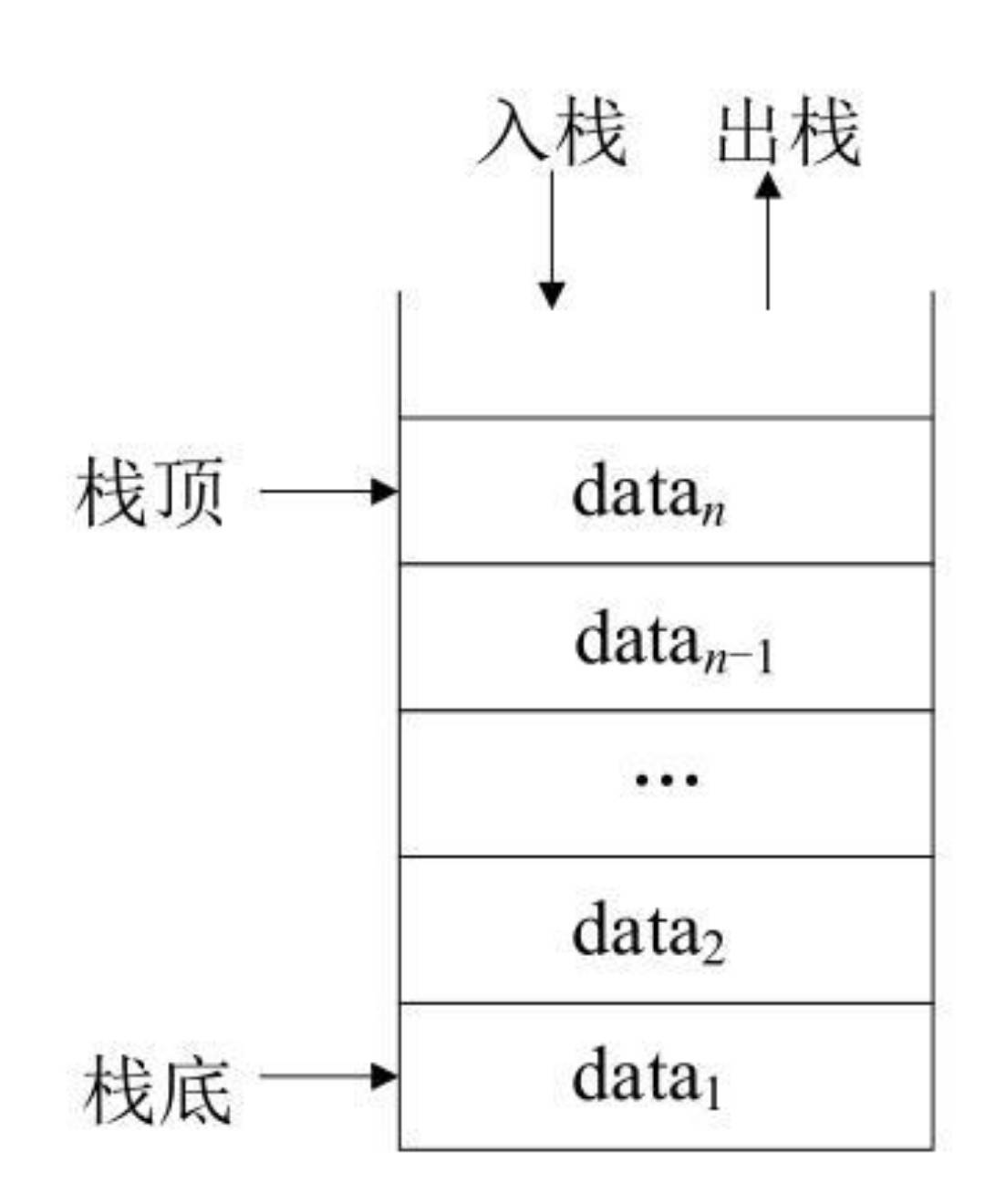
栈(Stack):只允许在一端进行插入和删除操作的线性表。
栈结构可以分为两类。
- 顺序栈结构:即使用一组地址连续的内存单元依次保存栈中的数据。在程序中,可以定义一个指定大小的结构数组来作为栈,序号为0的元素就是栈底,再定义一个变量top保存栈顶的序号即可。
- 链式栈结构:即使用链表形式保存栈中各元素的值。链表首部(head指针所指向元素)为栈顶,链表尾部(指向地址为NULL)为栈底。
在栈结构中只能在一端进行操作,该操作端称为栈顶,另一端称为栈底。也就是说,保存和取出数据都只能从栈结构的一端进行。从数据的运算角度来分析,栈结构是按照“后进先出”(Last In Firt Out,LIFO)的原则处理结点数据的。
- 栈顶(Top):允许进行插入和删除的那一端。
- 栈底(Bottom):不允许进行插入和删除的那一端。
- 空栈:不包含任何元素的空表。
栈结构在日常生活中有很多例子。例如,当仓库中堆放货物时,先来的货物放在里面,后来的货物放在外面;而要取出货物时,总是先取外面的,最后才能取到里面放的货物。也就是说,后放入货物先取出。
栈结构的基本操作:
- 入栈(Push):将数据保存到栈顶的操作。进行入栈操作前,先修改栈顶指针,使其向上移动一个元素位置,然后将数据保存到栈顶指针所指的位置。
- 出栈(Pop):将栈顶数据弹出的操作。通过修改栈顶指针,使其指向栈中的下一个元素。
- 初始化栈(InitStack):构造一个空栈 S,分配内存空间。
- 销毁栈(DestroyStack):销毁并释放栈 S 所占用的内存空间。
- 读栈顶元素(GetTop):若栈 S 非空,则用 x 返回栈顶元素。
- 判空(StackEmpty):判断一个栈 S 是否为空。若S为空,则返回true,否则返回false。
3.2 栈结构程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
define MAXLEN 50
typedef struct
{char name[10];int age;
}DATA;
typedef struct stack
{DATA data[SIZE + 1]; // 数据元素int top; // 栈顶
}StackType;
初始化栈结构
- 创建一个空的顺序栈。
- 具体操作步骤如下:
- (1)按符号常量SIZE指定的大小申请一块内存空间,用来保存栈中的数据。
- (2)设置栈顶指针的值为0,表示是一个空栈。
- 具体代码:
StackType *STInit()
{StackType *p;if (p = (StackType *)malloc(sizeof(StackType))) // 申请栈内存{p->top = 0; // 设置栈顶为0return p; // 返回指向栈的指针}return NULL;
}
判断空栈
- 判断栈是否为空。
- 具体代码:
int STIsEmpty(StackType *s) // 判断栈是否为空
{int t;t = (s->top == 0);return t;
}
判断栈满
- 判断栈结构是否为满。
- 具体代码:
int STIsFull(StackType *s) // 判断栈是否为满
{int t;t = (s->top == MAXLEN);return t;
}
清空栈
- 清空栈中的所有数据。将栈顶指针top设置为0,表示执行清空栈操作。
- 具体代码:
void STClear(StackType *s) // 清空栈
{s->top = 0;
}
释放空间
- 释放栈结构所占的内存单元。
- 使用free()函数释放所分配的内存。
- 具体代码:
void STFree(StackType *s) // 释放栈所占的空间
{if (s){free(s);}
}
入栈操作
- 将数据元素保存到栈结构。
入栈操作的具体步骤如下:
- (1)首先判断栈顶top,如果top大于或等于SIZE,则表示溢出,进行出错处理。
- (2)设置top=top+1(栈顶指针加1,指向入栈地址)。
- (3)将入栈元素保存到top指向的位置。
- 具体代码:
int PushST(StackType *s, DATA data) // 入栈操作
{if ((s->top + 1) > MAXLEN){printf("栈溢出! \n");return 0;}s->data[++s->top] = data;return 1;
}
出栈操作
- 从栈顶弹出一个数据元素。
出栈操作的具体步骤如下:
- (1)首先判断栈顶top,如果top等于0,则表示为空栈,进行出错处理。
- (2)将栈顶指针top所指位置的元素返回。
- (3)设置top=top-1,也就是使栈顶指针减1,指向栈的下一个元素,原来栈顶元素被弹出。
- 具体代码:
DATA PopST(StackType *s) // 出栈操作
{if (s->top == 0){printf("栈为空! \n");exit(0);}return (s->data[s->top--]);
}
读取栈顶数据
- 显示栈顶结点数据的内容。
- 具体代码:
DATA PeekST(StackType *s) // 读取栈顶数据
{if (s->top == 0){printf("栈为空! \n");exit(0);}return (s->data[s->top]);
}
案例:使用栈实现学生数据操作。
include
include
include
define MAXLEN 50 // 最大长度
define SIZE 100
typedef struct
{char name[10];int age;
}DATA;
typedef struct stack
{DATA data[SIZE + 1]; // 数据元素int top; // 栈顶
}StackType;
StackType *STInit()
{StackType *p;if (p = (StackType *)malloc(sizeof(StackType))) // 申请栈内存{p->top = 0; // 设置栈顶为0return p; // 返回指向栈的指针}return NULL;
}
int STIsEmpty(StackType *s) // 判断栈是否为空
{int t;t = (s->top == 0);return t;
}
int STIsFull(StackType *s) // 判断栈是否为满
{int t;t = (s->top == MAXLEN);return t;
}
void STClear(StackType *s) // 清空栈
{s->top = 0;
}
void STFree(StackType *s) // 释放栈所占的空间
{if (s){free(s);}
}
int PushST(StackType *s, DATA data) // 入栈操作
{if ((s->top + 1) > MAXLEN){printf("栈溢出! \n");return 0;}s->data[++s->top] = data;return 1;
}
DATA PopST(StackType *s) // 出栈操作
{if (s->top == 0){printf("栈为空! \n");exit(0);}return (s->data[s->top--]);
}
DATA PeekST(StackType *s) // 读取栈顶数据
{if (s->top == 0){printf("栈为空! \n");exit(0);}return (s->data[s->top]);
}
int main()
{StackType *stack;DATA data, data2;stack = STInit(); // 初始化栈printf("入栈操作: \n");printf("输入姓名 年龄进行入栈: \n");do {scanf("%s %d", data.name, &data.age);if (strcmp(data.name, "0") == 0){break; // 若输入为0,则退出}else {PushST(stack, data);}} while(1);do {printf("\n出栈操作:按任意键进行出栈操作:");getchar();data2 = PopST(stack);printf("出栈的数据是(%s ,%d) \n", data2.name, data2.age);} while (1);STFree(stack); // 释放栈所占的空间return 0;
}
测试数据:
adge 12
asdf 14
popd 15
numb 16

3.3 什么是队列?
一种操作受限的线性表,只允许在表的一端进行插入,而在表的另一端进行删除。
队列结构可以分为两类:
- 顺序队列结构:即使用一组地址连续的内存单元依次保存队列中的数据。
在程序中,可以定义一个指定大小的结构数组来作为队列。 - 链式队列结构:即使用链表形式保存队列中各元素的值。
- 顺序队列结构:即使用一组地址连续的内存单元依次保存队列中的数据。
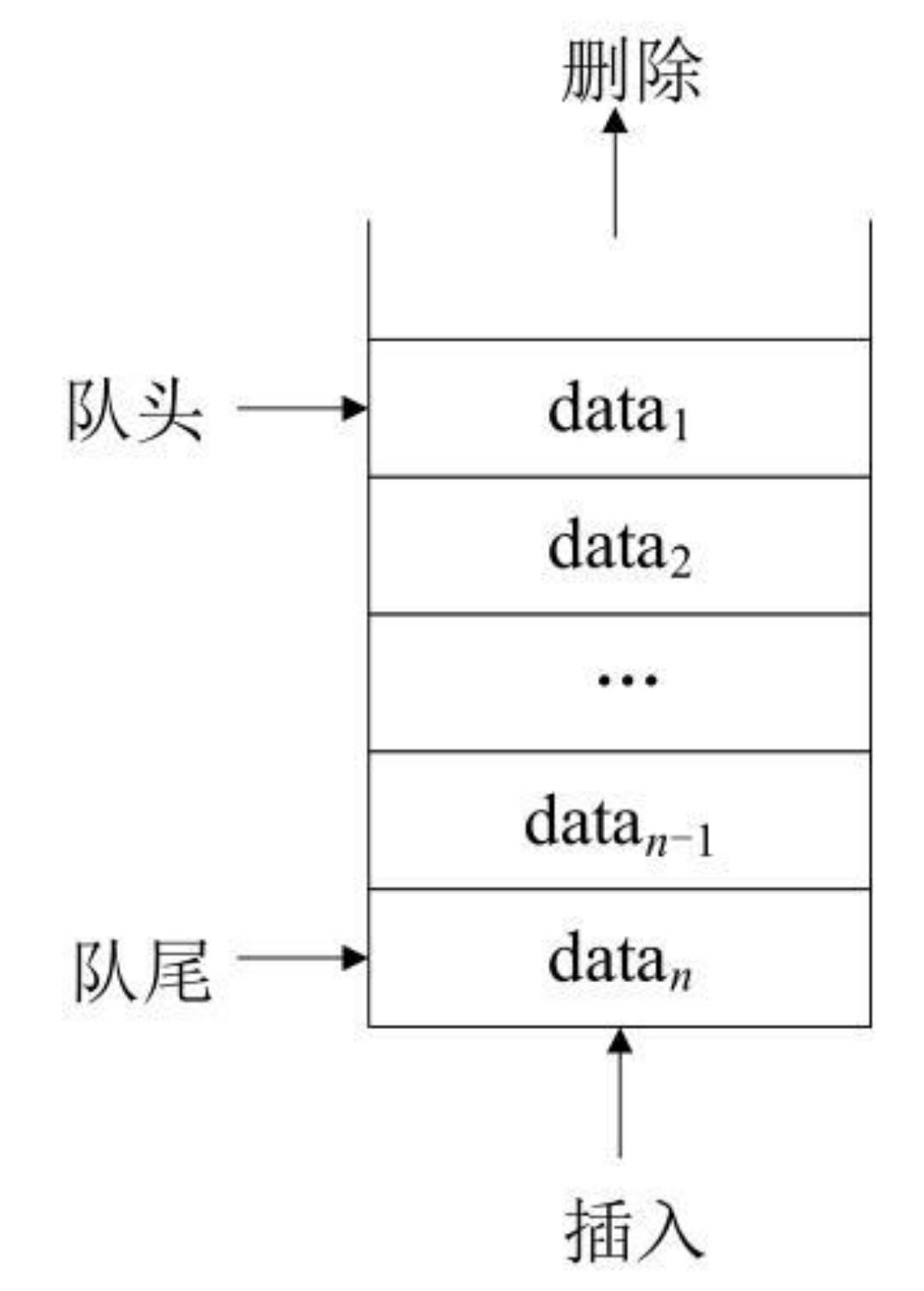
从图中可以看出,在队列结构中允许对两端进行操作,但是两端的操作不同。
- 在表的一端只能进行删除操作,称为队头;
- 在表的另一端只能进行插入操作,称为队尾。
- 如果队列中没有数据元素,则称为空队列。
- 从数据的运算角度来分析,队列结构是按照“先进先出”(First In First Out,FIFO)的原则处理结点数据。
队列结构在日常生活中有很多例子。例如银行的电子排号系统,先来的人取的号靠前,后来的人取的号靠后。这样,先来的人将最先得到服务,后来的人将后得到服务,一切按照“先来先服务”的原则。
队列结构的基本操作:
- 初始化队列(InitQueue):构造一个空队列Q。
- 销毁队列(DestroyQueue):销毁并释放队列Q所占用的内存空间。
- 入队列(EnQueue):将一个元素添加到队尾(相当于到队列最后排队等候)。
- 出队列(DeQueue):将队头的元素取出,同时删除该元素,使后一个元素成为队头。
- 读队头元素(GetHead):若队列Q非空,则将队头元素赋值给x。
- 判队列空(QueueEmpty):若队列Q为空返回true,否则返回false。
不是任何对线性表的操作都可以作为队列的操作。比如:不可以随便读取队列中的某个数据。
3.4 队列结构程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
define QUEUELEN 15
typedef struct
{char name[10];int age;
}DATA;
typedef struct
{DATA data[QUEUELEN]; //队列数组int head; // 队头int tail; // 队尾
}SQType;
初始化队列结构
- 创建一个空的顺序队列。
顺序队列的初始化操作步骤如下:
- (1)按符号常量QUEUELEN指定的大小申请一块内存空间,用来保存队列中的数据。
- (2)设置head=0和tail=0,表示是一个空栈。
- 具体代码:
SQType *SQTypeInit()
{SQType *q;if (q = (SQType *)malloc(sizeof(SQType))) // 申请内存{q->head = 0; // 设置队头q->tail = 0; // 设置队尾return q;}else {return NULL; // 返回空}
}
判断空队列
- 判断一个队列是否为空。
- 具体代码:
int SQTypeIsEmpty(SQType *q) // 判断空队列
{int temp;temp = q->head == q->tail;return (temp);
}
判断满队列
- 判断队列是否为满。
- 具体代码:
int SQTypeIsFull(SQType *q) // 判断满队列
{int temp;temp = q->tail == QUEUELEN;return (temp);
}
清空队列
- 清楚队列中的所有数据。
- 具体代码:
void SQTypeClear(SQType *q) // 清空队列
{q->head = 0; // 设置队头q->tail = 0; // 设置队尾
}
释放空间
- 释放队列所占的内存单元。
- 具体代码:
void SQTypeFree(SQType *q) // 释放队列
{if (q != NULL){free(q);}
}
入队
- 将数据元素保存到队列中。
- 入队列操作的具体步骤如下:
- (1)首先判断队列顶tail,如果tail等于QUEUELEN,则表示溢出,进行出错处理。否则执行以下操作。
- (2)设置tail=tail+1(队列顶指针加1,指向入队列地址)。
- (3)将入队列元素保存到tail指向的位置。
- 具体代码:
int InSQType(SQType *q, DATA data) // 入队列
{if (q->tail == QUEUELEN){printf("队列已满!操作失败! \n");return 0;}else {q->data[q->tail++] = data; // 将元素入队return (1);}
}
出队列
- 从队列顶端弹出数据元素。
- 出队列操作的具体步骤如下:
- (1)判断队列head,如果head等于tail,则表示为空队列,进行出错处理。否则执行下面的步骤。
- (2)从队列首部取出队头元素(实际是返回队头元素的指针)。
- (3)设修改队头head的序号,使其指向后一个元素。
- 具体代码:
DATA OutSQType(SQType q) // 出队列
{if (q->head == q->tail){printf("\n队列为空!操作失败! \n");exit(0);}else {return &(q->data[q->head++]);}
}
读取结点数据
- 读取队列中的结点的数据。读取结点数据的操作仅仅是显示队列中的数据内容。
- 具体代码:
DATA PeekSQType(SQType q) // 读取结点数据
{if (SQTypeIsEmpty(q)){printf("\n空队列! \n");return NULL;}else {return &(q->data[q->head]);}
}
计算队列的长度
- 统计队列中数据结点的个数。
- 具体代码:
int SQTypeLen(SQType *q) // 计算队列长度
{int temp;temp = q->tail - q->head;return (temp);
}
- 案例:使用队列实现学生数据操作。
具体代码:
include
define QUEUELEN 15
typedef struct
{char name[10];int age;
}DATA;
typedef struct
{DATA data[QUEUELEN]; //队列数组int head; // 队头int tail; // 队尾
}SQType;
SQType *SQTypeInit()
{SQType *q;if (q = (SQType *)malloc(sizeof(SQType))) // 申请内存{q->head = 0; // 设置队头q->tail = 0; // 设置队尾return q;}else {return NULL; // 返回空}
}
int SQTypeIsEmpty(SQType *q) // 判断空队列
{int temp;temp = q->head == q->tail;return (temp);
}
int SQTypeIsFull(SQType *q) // 判断满队列
{int temp;temp = q->tail == QUEUELEN;return (temp);
}
void SQTypeClear(SQType *q) // 清空队列
{q->head = 0; // 设置队头q->tail = 0; // 设置队尾
}
void SQTypeFree(SQType *q) // 释放队列
{if (q != NULL){free(q);}
}
int InSQType(SQType *q, DATA data) // 入队列
{if (q->tail == QUEUELEN){printf("队列已满!操作失败! \n");return 0;}else {q->data[q->tail++] = data; // 将元素入队return (1);}
}
DATA OutSQType(SQType q) // 出队列
{if (q->head == q->tail){printf("\n队列为空!操作失败! \n");exit(0);}else {return &(q->data[q->head++]);}
}
DATA PeekSQType(SQType q) // 读取结点数据
{if (SQTypeIsEmpty(q)){printf("\n空队列! \n");return NULL;}else {return &(q->data[q->head]);}
}
int SQTypeLen(SQType *q) // 计算队列长度
{int temp;temp = q->tail - q->head;return (temp);
}
int main()
{SQType *stack;DATA data, *data2;stack = SQTypeInit(); // 初始化队列printf("入队列操作: \n");printf("输入姓名 年龄进行入队操作: \n");do {scanf("%s %d", data.name, &data.age);if (strcmp(data.name, "0") == 0){break; // 若输入为0,停止入队}else {InSQType(stack, data);}} while (1);do {printf("出队操作:按任意键进行出队操作:\n");getchar();data2 = OutSQType(stack);printf("出队列的数据为(%s ,%d) \n", data2->name, data2->age);} while (1);SQTypeFree(stack); // 释放队列所占的内存空间return 0;
}
测试案例:
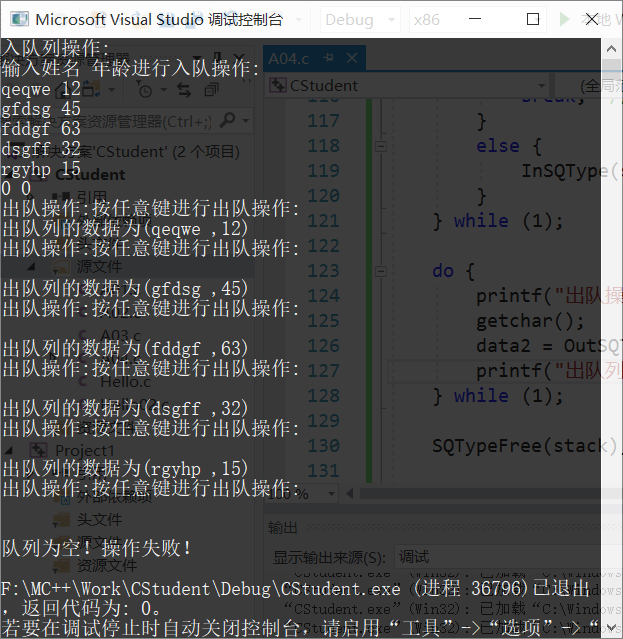
qeqwe 12
gfdsg 45
fddgf 63
dsgff 32
rgyhp 15
4、树结构
树(Tree)结构是一种描述非线性层次关系的数据结构。
4.1 什么是树?
树是n个数据结点的集合,在该集合中包含一个根结点,根结点之下则分布着一些互不交叉的子集合,这些子集合也是根结点的子树。
- 当n=0时,称为空树。
- 当n > 1时,其余结点可分为m(m > 0)个互不相交的有限集合T1, T2,…, Tm,其中每个集 合本身又是一棵树,并且称为根结点的子树。
非空树结构的基本特征:
- 有且仅有一个根节点;
- 没有后继的结点称为“叶子结点”(或终端结点);
- 有后继的结点称为“分支结点”(或非终端结点);
- 除了根节点外,任何一个结点都有且仅有一个前驱;
- 每个结点可以有0个或多个后继。
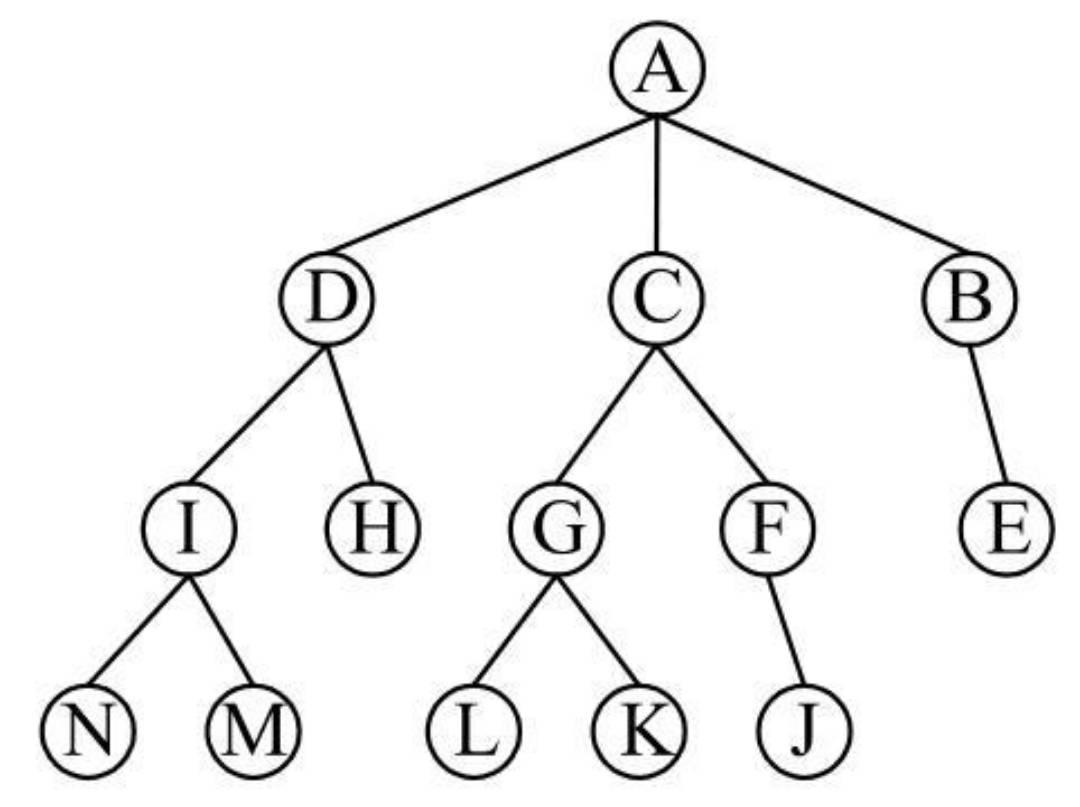
对照此图,可以知道:
- A是树的根结点;
- 根结点A有3个直接后继结点B、C和D;
- 结点B、C、D只有一个直接前驱结点A。
4.2 树的基本概念
- 父结点和子结点:每个结点的子树的根称为该结点的子结点,相应地,该结点被称为子结点的父结点。
- 兄弟结点:具有同一父结点的结点称为兄弟结点。
- 结点的度:一个结点所包含子树的数量。
- 树的度:是指该树所有结点中最大的度。
- 叶结点:树中度为零的结点称为叶结点或终端结点。
- 分支结点:树中度不为零的结点称为分支结点或非终端结点。
- 结点的层数:结点的层数从树根开始计算,根结点为第1层、依次向下为第2、3、…、n层。树是一种层次结构,每个结点都处在一定的层次上。
- 树的深度:树中结点的最大层数称为树的深度。
- 有序树:若树中各结点的子树(兄弟结点)是按一定次序从左向右安排的,称为有序树。
- 无序树:若树中各结点的子树(兄弟结点)未按一定次序安排,称为无序树。
- 森林(forest):n(n>0)棵互不相交的树的集合。
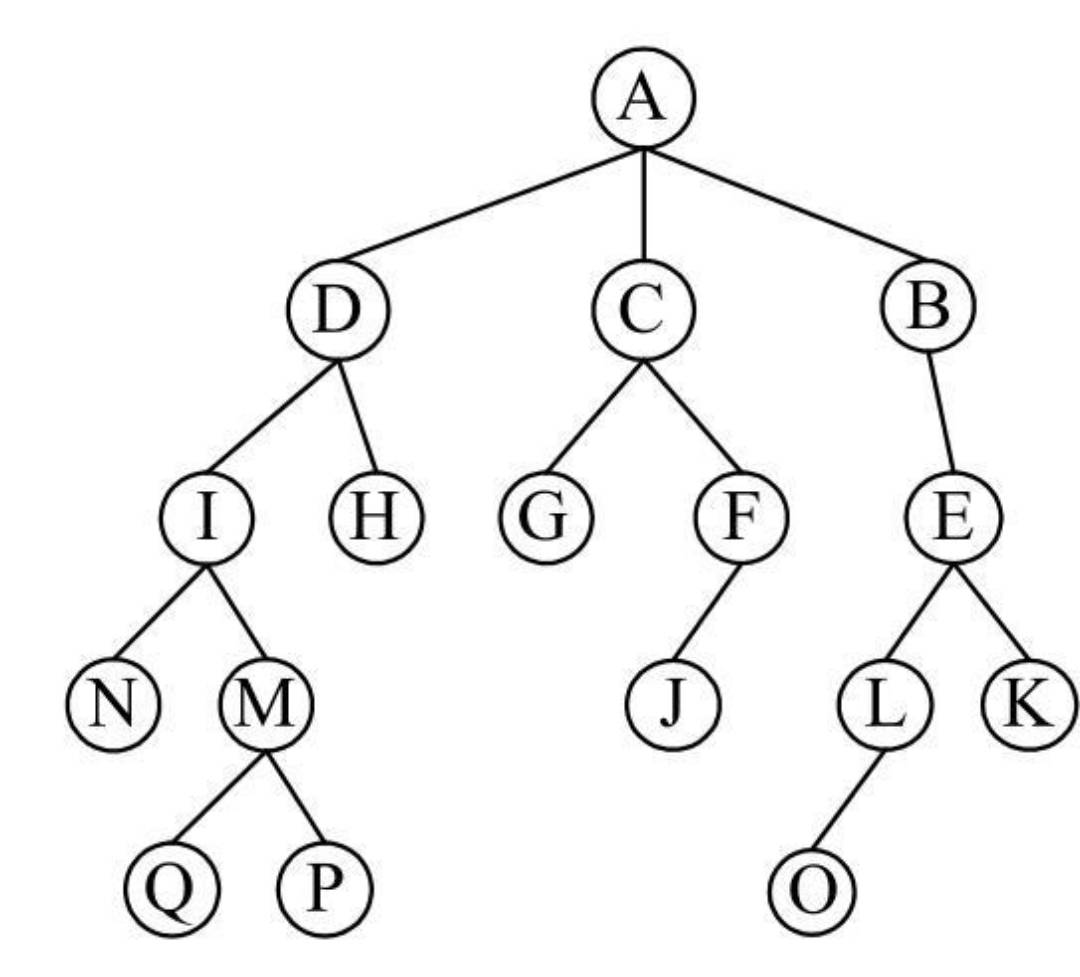
上图展示了一个基本的树结构:
- 其中,结点A为根结点。
- 结点A有3个子树。因此,结点A的度为3。
- 同理,结点E有两个子树,结点E的度为2。
- 所有结点中,结点A的度为3最大,因此整个树的度为3。
- 结点E是结点K和结点L的父结点,结点K和结点L是结点E的子结点,结点K和结点L之间为兄弟结点。
- 在这个树结构中,结点G、结点H、结点K、结点J、结点N、结点O、结点P和结点Q都是叶结点。
- 其余的都是分支结点,整个树的深度为4。
- 除去根结点A,留下的子树就构成了一个森林。
树结构一般采用层次括号法。层次括号法的基本规则如下:
- 根结点放入一对圆括号中。
- 根结点的子树由左至右的顺序放入括号中。
- 对子树做上述相同的处理。
这样,同层子树与它的根结点用圆括号括起来,同层子树之间用逗号隔开,最后用闭括号括起来按照这种方法,下图所示的树结构可以表示成如下形式:
- (A(B(E)),(C(F(J)),(G(K,L))),(D(H),(I(M,N))))
4.3 什么是二叉树?
- 二叉树是树结构的一种特殊形式,它是n个结点的集合,每个结点最多只能有两个子结点。
- 二叉树的子树仍然是二叉树。
- 二叉树一个结点上对应的两个子树分别称为左子树和右子树。
由于子树有左右之分,因此二叉树是有序树。
- 在普遍的树结构中,结点的最大度数没有限制,而二叉树结点的最大度数为2。
- 另外,树结构中没有左子树和右子树的区分,而二叉树中则有这个区别。
- 一个二叉树结构也可以是空的,此时空二叉树中没有数据结点,也就是一个空集合。
- 如果二叉树结构中仅包含一个结点,那么这也是一个二叉树,树根便是该结点自身。
依照子树的位置的个数,二叉树还有如下图所示的几种形式:
- 图(a)只有一个子结点且位于左子树位置,右子树位置为空;
- 图(b)只有一个子结点且位于右子树位置,左子树位置为空;
- 图©具有完整的两个子结点,也就是左子树和右子树都存在。

对于一般的二叉树来说,在树结构中可能包含上述的各种形式。按照上述二叉树的几种形式来看,为了研究的方便,二叉树还可以进一步细分为两种特殊的类型,满二叉树和完全二叉树。
- 对于满二叉树,就是在二叉树中除最下一层的叶结点外,每层的结点都有2个子结点。典型的满二叉树如下图所示:

- 至于完全二叉树,就是在二叉树中除二叉树最后一层外,其他各层的结点数都达到最大个数,且最后一层叶结点按照从左向右的顺序连续存在,只缺最后一层右侧若干结点。典型的完全二叉树如图2-17所示。
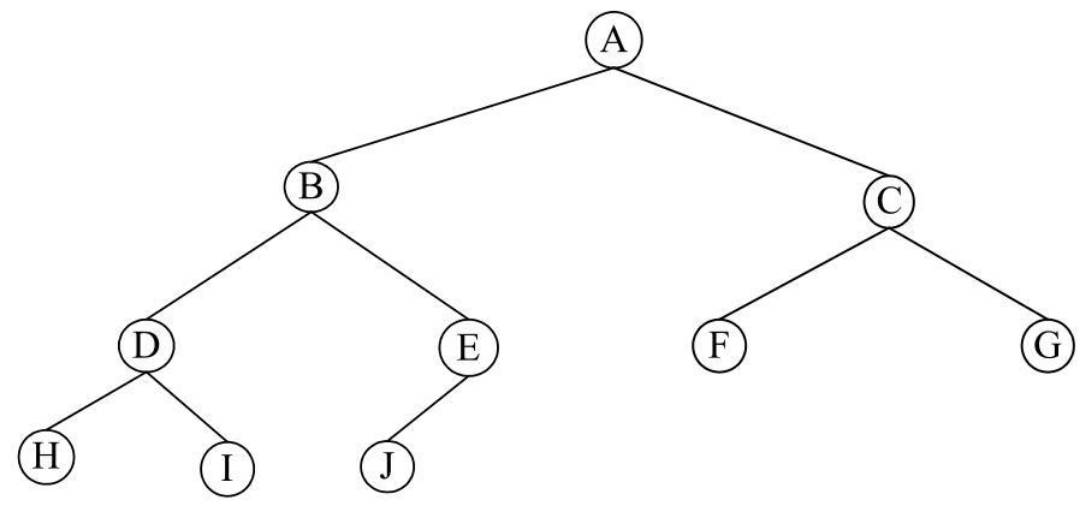
从上面的满二叉树和完全二叉树的定义可以知道,满二叉树一定是完全二叉树,而完全二叉树不一定是满二叉树,因为没有达到完全满分支的结构。
对于完全二叉树,如果树中包含n个结点,假设这些结点按照顺序方式存储。对于任意一个结点m来说,具有如下性质:
- 如果m!=1,则结点m的父结点的编号为m/2。
- 如果2m≤n,则结点m的左子树根结点的编号为2m;
- 若2m>n,则无左子树,进一步也就没有右子树。
- 如果2m+1≤n,则结点m的右子树根结点编号为2m+1;若2m+1>n,则无右子树。
- 另外,对于该完全二叉树来说,其深度为[log2n]+1。
树结构可以分为顺序存储结构和链式存储结构两种。
- 顺序存储方式是最基本的数据存储方式。
- 树结构的顺序存储一般也是采用一维结构数组来表示,关键是定义合适的次序来存放树中各个层次的数据。
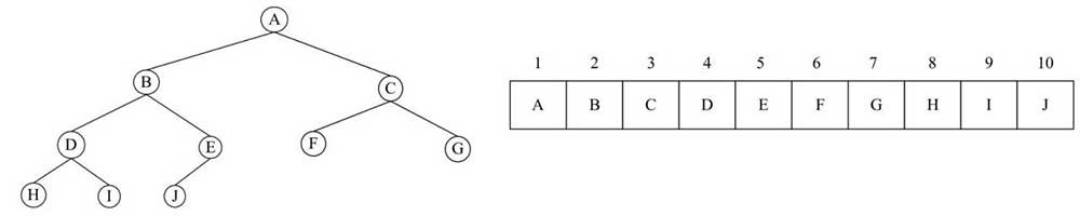
如上图,这是一个完全二叉树。
- 每个结点的数据为字符类型。
- 如果采用顺序存储方式,可以将其按层来存储。
- 即先存储根结点,然后从左至右依次存储下一层结点的数据,直到所有的结点数据完全存储。
- 右侧即为这种存储的形式。
上述完全二叉树顺序存储结构的数据定义,可以采用如下形式:
define MAXLen 100 // 最大结点数
typedef char DATA; // 元素类型
typedef DATA SeqBinTree[MAXLen];
SeqBinTree SBT; // 定义保存二叉树数组各个结点之间的位置关系:
- 对于结点D,位于数组的第4个位置,则其父结点的编号为4/2=2,也就是结点B。
- 结点D左子结点的编号为2×4=8,也就是结点H。
- 结点D右子结点的编号为2×4+1=9,也就是结点I。
- 对于非完全二叉树,为了仍然可以使用的完全二叉树的性质,往往将一个非完全二叉树填充为一个完全二叉树。
- 下图(a)为一个典型的非完全二叉树,将缺少的部分填上一个空的数据结点来构成图(b)的完全二叉树。
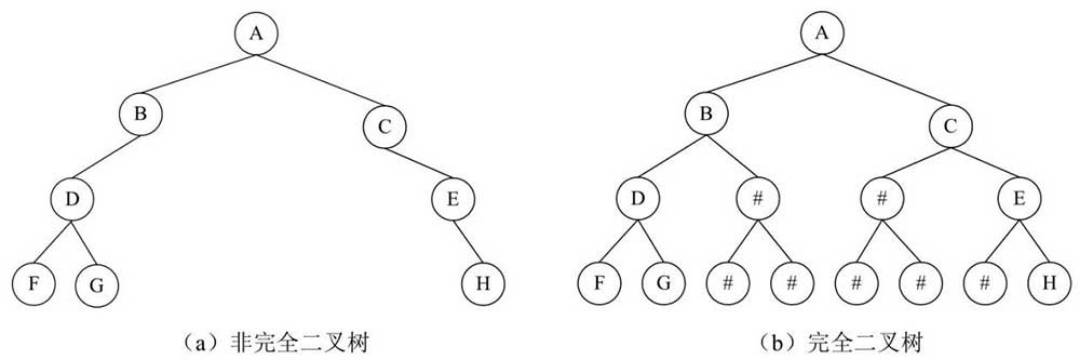
- 这样,图(b)再按照完全二叉树的顺序存储方式来存储,如下图所示:

这种存储方式最大的缺点,就是浪费存储空间,这是因为其中填充了大量的无用数据。因此,顺序存储方式一般只适用于完全二叉树的情况。对于更为一般的情况,建议采用链式存储方式。
二叉树的链式存储
- 二叉树的链式存储结构包含结点元素以及分别指向左子树和右子树的指针。
- 典型的二叉树的链式存储结构如图所示:

二叉树的链式存储结构定义示例代码如下:
typedef struct ChainTree
{DATA NodeData; // 元素数据struct ChainTree *LSonNode; // 左子树结点struct ChainTree *RSonNode; // 右子树结点
}ChinaTreeType;
ChinaTreeType *root = NULL; // 定义二叉树根结点指针
为了后续计算的方便,也可以保存一个该结点的父结点的指针。
- 此时二叉树的链式存储结构包含结点元素、指向父结点的指针以及分别指向左子树和右子树的指针。
- 这种带父结点的二叉树链式存储结构如图所示:

带父结点的二叉树链式存储结构定义示例代码如下:
typedef struct ChainTree
{DATA NodeData; // 元素数据struct ChainTree *LSonNode; // 左子树结点struct ChainTree *RSonNode; // 右子树结点struct ChainTree *ParentNode; // 父结点指针
}ChinaTreeType;
ChinaTreeType *root = NULL; // 定义二叉树根结点指针
4.4 二叉树的程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
define MAXLEN 100 // 最大长度
typedef char DATA; // 元素类型
typedef struct CBT
{DATA data; // 元素数据struct CBT* left; // 左子树结点指针struct CBT* right; // 右子树结点指针
}CBTType;
初始化二叉树
- 将一个结点设置为二叉树的根结点。
- 具体代码:
CBTType* InitTree() // 初始化二叉树的根结点
{CBTType* node;if (node = (CBTType*)malloc(sizeof(CBTType))) // 申请内存{printf("请输入一个根结点的数据:\n");scanf("%s", &node->data);node->left = NULL;node->right = NULL;if (node != NULL) // 如果根结点不为空{return node;}else {return NULL;}}return NULL;
}
查找结点
- 遍历二叉树中的每一个结点,逐个比较,当找到目标数据结点时返回该数据的结点的指针。
- 具体代码:
CBTType TreeFindNode(CBTType treeNode, DATA data) // 查找结点
{CBTType *ptr;if (treeNode == NULL){return NULL;}else {if (treeNode->data == data){return treeNode;}else {if (ptr = TreeFindNode(treeNode->left, data)) // 分别向左右子树递归查找{return ptr;}else if (ptr = TreeFindNode(treeNode->right, data)){return ptr;}else {return NULL;}}}
}
添加结点
- 在二叉树中添加结点数据,指定其父结点,以及添加的结点是左子树还是右子树。
- 具体代码:
void AddTreeNode(CBTType* treeNode) // 添加结点
{CBTType *pnode, *parent;DATA data;char menusel;if (pnode = (CBTType *)malloc(sizeof(CBTType))) // 分配内存{printf("输入二叉树的结点数据:\n");fflush(stdin); // 清空输入缓冲区scanf("%s", &pnode->data);pnode->left = NULL; // 设置左子树为空pnode->right = NULL; // 设置右子树为空printf("输入该结点的父结点数据:");fflush(stdin); // 清空输入缓冲区scanf("%s", &data);parent = TreeFindNode(treeNode, data); // 查找指定数据的结点if (!parent) // 如果未找到{printf("未找到该数据的父结点!\n");free(pnode); // 释放创建的结点内存return;}printf("1.添加该结点到左子树结点.\n2.添加该节点到右子树.\n");do {menusel = getch(); // 输入选择项menusel -= '0';if (menusel == 1 || menusel == 2){if (parent == NULL){printf("不存在父结点,请先设置父结点!\n");}else {switch (menusel){case 1: // 添加到左结点if (parent->left) // 左子树不为空{printf("左子树结点不为空!\n");}else {parent->left = pnode;}break;case 2: // 添加到右结点if (parent->right) // 右子树不为空{printf("右子树结点不为空!\n");}else {parent->right = pnode;}break;default:printf("输入了无效参数!\n");}}}} while (menusel != 1 && menusel != 2);}
}
获取左子树
- 返回当前结点的左子树的值。
- 具体代码:
CBTType TreeLeftNode(CBTType treeNode) // 获取左子树
{if (treeNode){return treeNode->left; // 返回值}else {return NULL;}
}
获取右子树
- 返回当前结点的右子树的值。
- 具体代码:
CBTType TreeRightNode(CBTType treeNode) // 获取右子树
{if (treeNode){return treeNode->right; // 返回值}else {return NULL;}
}
判断空树
- 判断二叉树结构是否为空。
- 具体代码:
CBTType TreeIsEmpty(CBTType treeNode) // 判断空树
{if (treeNode){return 0; // 返回值}else {return 1;}
}
计算二叉树的深度
- 计算二叉树中结点的最大层数。
- 具体代码:
int TreeDepth(CBTType *treeNode) // 计算二叉树深度
{int depleft, depright;if (treeNode == NULL) {return 0;}else {depleft = TreeDepth(treeNode->left); // 左子树深度depright = TreeDepth(treeNode->right); // 右子树深度if (depleft > depright){return depleft + 1;}else {return depright + 1;}}
}
清空二叉树
- 将二叉树变为空树。用递归实现。
- 具体代码:
void ClearTree(CBTType *treeNode) // 清空二叉树
{if (treeNode){ClearTree(treeNode->left); // 清空左子树ClearTree(treeNode->right); // 清空右子树free(treeNode); // 释放当前结点所占内存treeNode = NULL;}
}
显示结点数据
- 显示当前结点的数据内容。
- 具体代码:
void TreeNodeData(CBTType *p) // 显示结点数据
{printf("%c ", p->data); // 输出结点数据
}
按层遍历二叉树
- 逐个查找二叉树中的所有结点。
由于二叉树是一种层次结构。所以,可以按层来遍历整个二叉树。
- 按层遍历:先从第1层(根结点)进入队列,再从第1根结点的左右子树(第2层)进入队列……这样循环处理,即可逐层遍历。
- 具体代码:
void LevelTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 按层遍历
{CBTType *p;CBTType *q[MAXLEN]; //定义顺序栈int head = 0, tail = 0;if (treeNode) // 如果队首指针不为空{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = treeNode; // 将二叉树根指针进队}while (head != tail) // 队列不为空,进行循环{head = (head + 1) % MAXLEN; // 计算循环队列队首序号p = q[head]; // 获取队首元素TreeNodeData(p); // 处理队首元素if (p->left != NULL) // 如果结点存在左子树{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = p->left; // 将左子树指针进队}if (p->right != NULL) // 如果结点存在右子树{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = p->right; // 将右子树指针进队}}
}
按递归遍历二叉树
- 按递归遍历可分为先序遍历、中序遍历、后序遍历。
- 先序遍历:即先访问根结点,再按先序遍历左子树,最后按先序遍历右子树。先序遍历也称为先根次序遍历,简称为DLR遍历。
- 中序遍历:即先按中序遍历左子树,再访问根结点,最后按中序遍历右子树。中序遍历也称为中根次序遍历,简称为LDR遍历。
- 后序遍历:即先按后序遍历左子树,再按后序遍历右子树,最后访问根结点。后序遍历也称为后根次数遍历,简称为LRD遍历。
- 具体代码:
void DLRTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 先序遍历
{if (treeNode){TreeNodeData(treeNode); // 显示结点数据DLRTree(treeNode->left, TreeNodeData); // 先序遍历左子树DLRTree(treeNode->right, TreeNodeData); // 先序遍历右子树}
}
void LDRTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 中序遍历
{if (treeNode){LDRTree(treeNode->left, TreeNodeData); // 中序遍历左子树TreeNodeData(treeNode); // 显示结点数据LDRTree(treeNode->right, TreeNodeData); // 中序遍历右子树}
}
void LRDTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 后序遍历
{if (treeNode){LRDTree(treeNode->left, TreeNodeData); // 后序遍历左子树LRDTree(treeNode->right, TreeNodeData); // 后序遍历右子树TreeNodeData(treeNode); // 显示结点数据}
}
案例:二叉树的各种操作及四种遍历
- 具体代码:
include
include
include
define MAXLEN 100 // 最大长度
typedef char DATA; // 元素类型
typedef struct CBT
{DATA data; // 元素数据struct CBT* left; // 左子树结点指针struct CBT* right; // 右子树结点指针
}CBTType;
CBTType* InitTree() // 初始化二叉树的根结点
{CBTType* node;if (node = (CBTType*)malloc(sizeof(CBTType))) // 申请内存{printf("请输入一个根结点的数据:\n");scanf("%s", &node->data);node->left = NULL;node->right = NULL;if (node != NULL) // 如果根结点不为空{return node;}else {return NULL;}}return NULL;
}
CBTType TreeFindNode(CBTType treeNode, DATA data) // 查找结点
{CBTType *ptr;if (treeNode == NULL){return NULL;}else {if (treeNode->data == data){return treeNode;}else {if (ptr = TreeFindNode(treeNode->left, data)) // 分别向左右子树递归查找{return ptr;}else if (ptr = TreeFindNode(treeNode->right, data)){return ptr;}else {return NULL;}}}
}
void AddTreeNode(CBTType* treeNode) // 添加结点
{CBTType *pnode, *parent;DATA data;char menusel;if (pnode = (CBTType *)malloc(sizeof(CBTType))) // 分配内存{printf("输入二叉树的结点数据:\n");fflush(stdin); // 清空输入缓冲区scanf("%s", &pnode->data);pnode->left = NULL; // 设置左子树为空pnode->right = NULL; // 设置右子树为空printf("输入该结点的父结点数据:");fflush(stdin); // 清空输入缓冲区scanf("%s", &data);parent = TreeFindNode(treeNode, data); // 查找指定数据的结点if (!parent) // 如果未找到{printf("未找到该数据的父结点!\n");free(pnode); // 释放创建的结点内存return;}printf("1.添加该结点到左子树结点.\n2.添加该节点到右子树.\n");do {menusel = getch(); // 输入选择项menusel -= '0';if (menusel == 1 || menusel == 2){if (parent == NULL){printf("不存在父结点,请先设置父结点!\n");}else {switch (menusel){case 1: // 添加到左结点if (parent->left) // 左子树不为空{printf("左子树结点不为空!\n");}else {parent->left = pnode;}break;case 2: // 添加到右结点if (parent->right) // 右子树不为空{printf("右子树结点不为空!\n");}else {parent->right = pnode;}break;default:printf("输入了无效参数!\n");}}}} while (menusel != 1 && menusel != 2);}
}
CBTType TreeLeftNode(CBTType treeNode) // 获取左子树
{if (treeNode){return treeNode->left; // 返回值}else {return NULL;}
}
CBTType TreeRightNode(CBTType treeNode) // 获取右子树
{if (treeNode){return treeNode->right; // 返回值}else {return NULL;}
}
CBTType TreeIsEmpty(CBTType treeNode) // 判断空树
{if (treeNode){return 0; // 返回值}else {return 1;}
}
int TreeDepth(CBTType *treeNode) // 计算二叉树深度
{int depleft, depright;if (treeNode == NULL) {return 0;}else {depleft = TreeDepth(treeNode->left); // 左子树深度depright = TreeDepth(treeNode->right); // 右子树深度if (depleft > depright){return depleft + 1;}else {return depright + 1;}}
}
void ClearTree(CBTType *treeNode) // 清空二叉树
{if (treeNode){ClearTree(treeNode->left); // 清空左子树ClearTree(treeNode->right); // 清空右子树free(treeNode); // 释放当前结点所占内存treeNode = NULL;}
}
void TreeNodeData(CBTType *p) // 显示结点数据
{printf("%c ", p->data); // 输出结点数据
}
void LevelTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 按层遍历
{CBTType *p;CBTType *q[MAXLEN]; //定义顺序栈int head = 0, tail = 0;if (treeNode) // 如果队首指针不为空{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = treeNode; // 将二叉树根指针进队}while (head != tail) // 队列不为空,进行循环{head = (head + 1) % MAXLEN; // 计算循环队列队首序号p = q[head]; // 获取队首元素TreeNodeData(p); // 处理队首元素if (p->left != NULL) // 如果结点存在左子树{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = p->left; // 将左子树指针进队}if (p->right != NULL) // 如果结点存在右子树{tail = (tail + 1) % MAXLEN; // 计算循环队列队尾序号q[tail] = p->right; // 将右子树指针进队}}
}
void DLRTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 先序遍历
{if (treeNode){TreeNodeData(treeNode); // 显示结点数据DLRTree(treeNode->left, TreeNodeData); // 先序遍历左子树DLRTree(treeNode->right, TreeNodeData); // 先序遍历右子树}
}
void LDRTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 中序遍历
{if (treeNode){LDRTree(treeNode->left, TreeNodeData); // 中序遍历左子树TreeNodeData(treeNode); // 显示结点数据LDRTree(treeNode->right, TreeNodeData); // 中序遍历右子树}
}
void LRDTree(CBTType treeNode, void(TreeNodeData)(CBTType *p)) // 后序遍历
{if (treeNode){LRDTree(treeNode->left, TreeNodeData); // 后序遍历左子树LRDTree(treeNode->right, TreeNodeData); // 后序遍历右子树TreeNodeData(treeNode); // 显示结点数据}
}
void main()
{CBTType *root = NULL; // root为指向二叉树根结点的指针char menusel;void(*TreeNodeDatal)(); // 指向函数的指针TreeNodeDatal = TreeNodeData; // 指向具体操作的函数root = InitTree(); // 设置根元素do { // 添加结点printf("请选择菜单添加二叉树的结点!\n");printf("0.退出\t");printf("1.添加二叉树的结点!\n");menusel = getch();switch (menusel){case '1':AddTreeNode(root); // 添加结点break;case '0':break;default:break;}} while (menusel != '0');// 遍历二叉树do {printf("选择二叉树遍历序号,输入0表示退出:\n"); // 显示菜单printf("1.先序遍历DLR\t");printf("2.中序遍历LDR\t");printf("3.后序遍历LRD\t");printf("4.按层遍历\n");menusel = getch();switch (menusel){case '0':break;case '1': // 先序遍历printf("\n先序遍历结果:");DLRTree(root, TreeNodeDatal);printf("\n");break;case '2': // 中序遍历printf("\n中序遍历结果:");LDRTree(root, TreeNodeDatal);printf("\n");break;case '3': // 后序遍历printf("\n后序遍历结果:");LRDTree(root, TreeNodeDatal);printf("\n");break;case '4': // 按层遍历printf("\n按层遍历结果:");LevelTree(root, TreeNodeDatal);printf("\n");break;default:break;}} while (menusel != '0');printf("\n二叉树深度为:%d\n", TreeDepth(root)); // 二叉树深度ClearTree(root); // 清空二叉树root = NULL;
}
5、 图结构
图(Graph)结构也是一种非线性数据结构,图结构在实际生活中具有非常多的例子。例如,通信网络、交通网络、人际关系网络等都可以归结为图结构。
5.1 什么是图?
- 上文的树结构的一个基本特点:数据元素之间具有层次关系,每一层的元素可以和多个下层元素关联,但是只能和一个上层元素关联。如果把这个规则进一步扩展,也就是说,每个数据元素之间可以任意关联,这就构成了一个图结构。
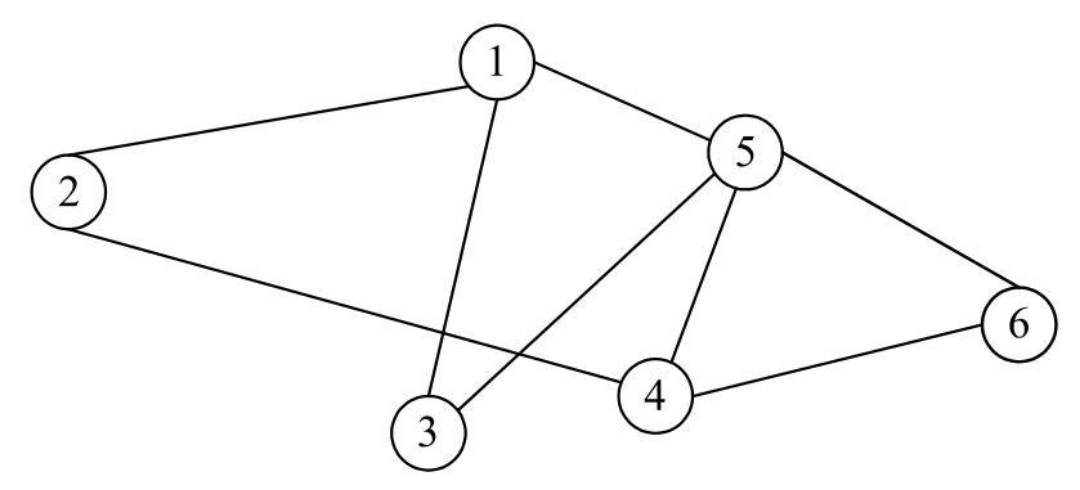
一个典型的图结构包括如下两个部分:
- 顶点(Vertex):图中的数据元素。
- 边(Edge):图中连接这些顶点的线。
所有的顶点构成一个顶点集合,所有的边构成边集合,一个完整的图结构就是由顶点集合和边集合组成。图结构在数学上一般记为如下所示的形式:
G=(V,E)或者G=(V(G),E(G))
- 其中,V(G)表示图结构中所有顶点的集合,顶点可以用不同的数字或者字母来表示。E(G)是图结构中所有边的集合,每条边由所连接的两个顶点表示。
注意:图结构中顶点集合V(G)必须为非空,即必须包含一个顶点。而图结构中边集合E(G)可以为空,此时表示没有边。
例如,对于上文所示的图结构,对应的顶点集合和边集合如下:
V(G)={ V1,V2,V3,V4,V5,V6}E(G)={ (V1,V2),(V1,V3),(V1,V5),(V2,V4),(V3,V5),(V4,V5),(V4,V6),(V5,V6)}
5.2 图的基本概念
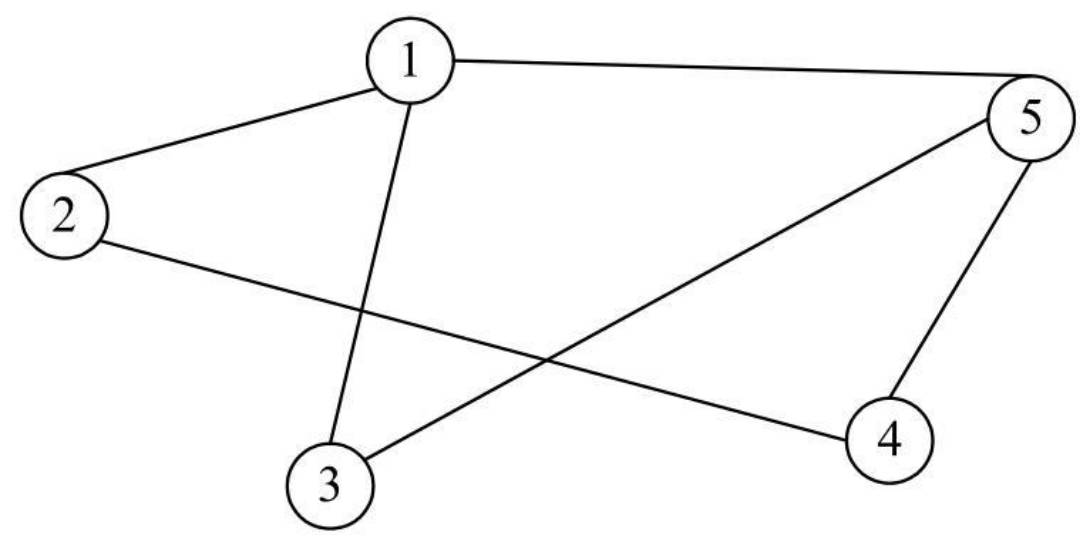
无向图:如果一个图结构中所有的边都没有方向性,这种图便被称为无向图。
- 由于无向图中的边没有方向性,在表示边时对两个顶点的顺序没有要求。例如顶点V1和顶点V5之间的边,可以表示为(V1,V5),也可以表示为(V5,V1)。
即下图对应的顶点集合和边集合如下:
V(G)={ V1,V2,V3,V4,V5}E(G)={ (V1,V2),(V1,V5),(V2,V4),(V3,V5),(V4,V5),(V1,V3)}
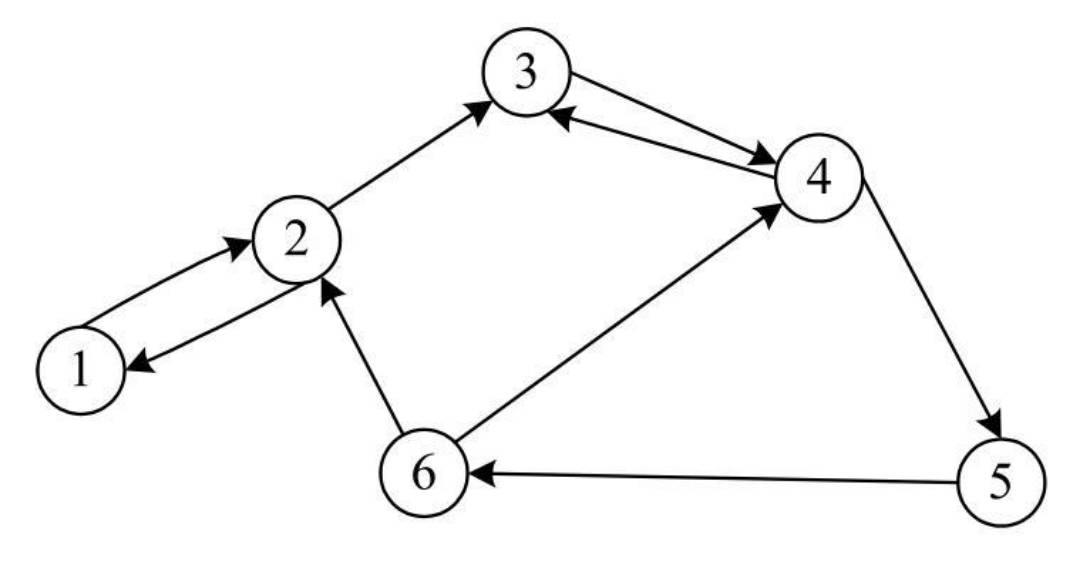
有向图:如果一个图结构中边是有方向性的,这种图便被称为有向图。
- 由于有向图中的边有方向性,所以在表示边时对两个顶点的顺序有所要求。
- 为了与无向图区分,这里采用尖括号表示有向边。
- 例如,
表示从顶点V3到顶点V4的一条边,而 表示从顶点V4到顶点V3的一条边。 和 表示的是两条不同的边。 即下图对应的顶点集合和边集合如下:
V(G)={ V1,V2,V3,V4,V5,V6}E(G)={ <V1,V2>,<V2,V1>,<V2,V3>,<V3,V4>,<V4,V3>,<V4,V5>,<V5,V6>,<V6,V4>,<V6,V2>}
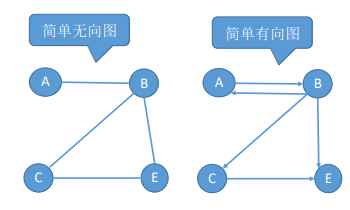
- 简单图:①不存在重复边;②不存在顶点到自身的边。
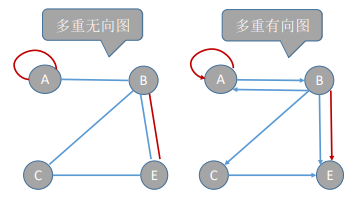
- 多重图:图G中某两个结点之间的边数多于 一条,又允许顶点通过同一条边和自己关联, 则G为多重图。
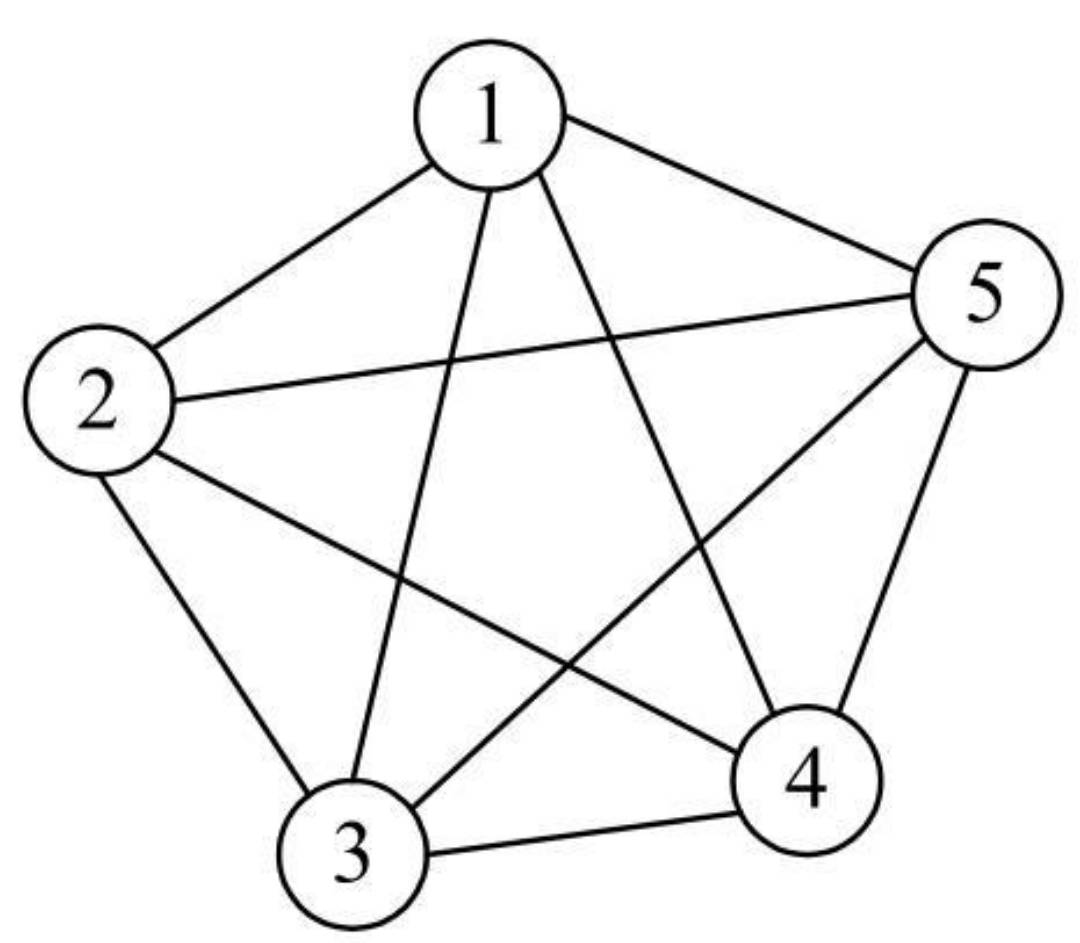
无向完全图:在无向图中,每两个顶点之间都存在一条边。
- 对于1个包含n个顶点的无向完全图,其总的边数为n(n-1)/2。
- 无向完全图如下:
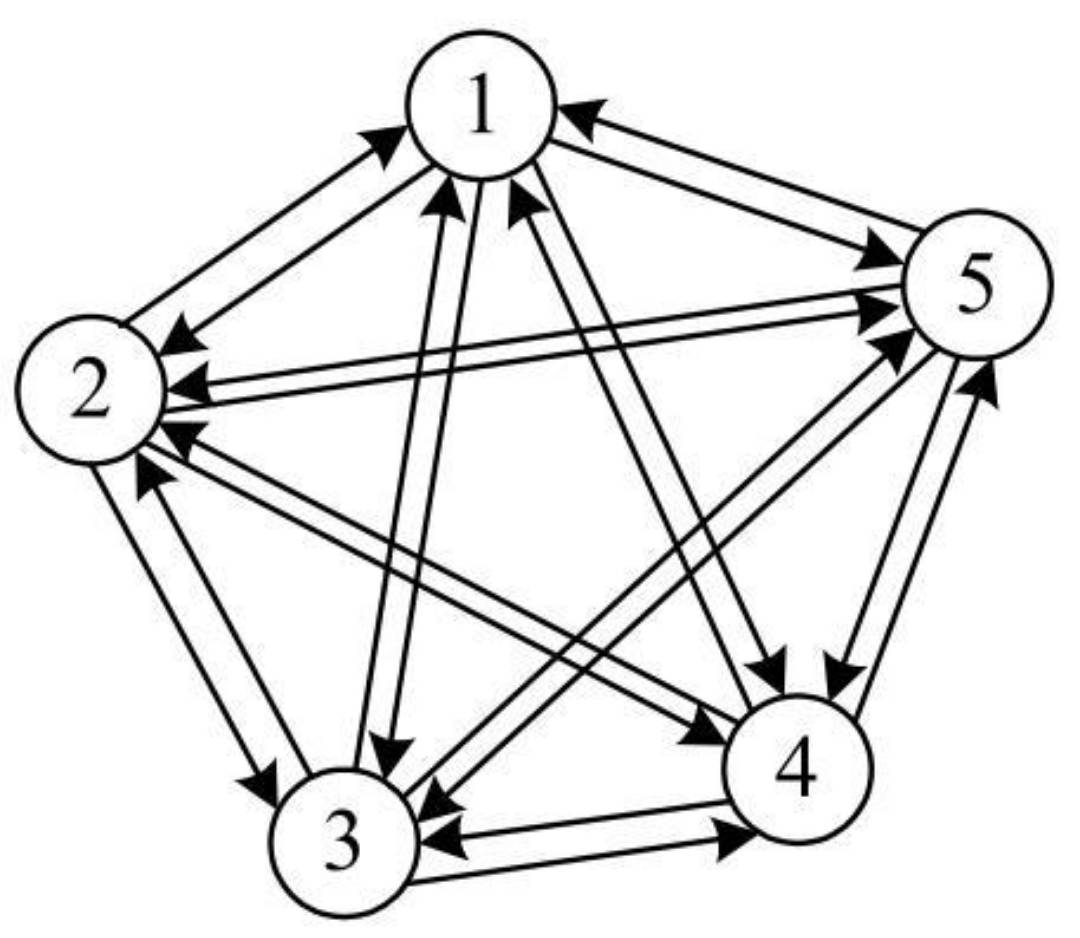
有向完全图:在有向图中,每两个顶点之间都存在方向相反的两条边。
- 对于一个包含n个顶点的有向完全图,其总的边数为n(n-1),是无向完全图的两倍,因为每两个顶点之间需要两条边。
顶点的度、入度和出度
- 连接顶点的边的数量称为顶点的度。
- 顶点的度在有向图和无向图中具有不同的意义。
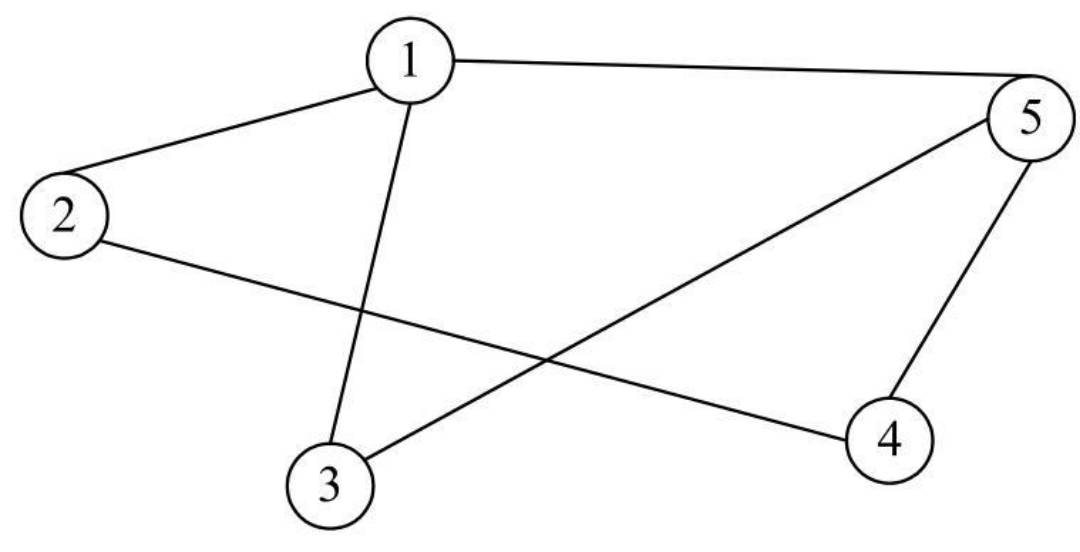
- 对于无向图,一个顶点V的度比较简单,是连接该顶点的边的数量,记为D(V)。例如,下图所示的无向图中,顶点V4的度为2,而V5的度为3。
- 对于有向图,根据连接顶点V的边的方向性,一个顶点的度有入度和出度之分。
- 入度是以该顶点为端点的入边数量,记为ID(V)。
- 出度是以该顶点为端点的出边数量,记为OD(V)。
- 在有向图中,一个顶点V的度便是入度和出度之和,即D(V)=ID(V)+OD(V)。
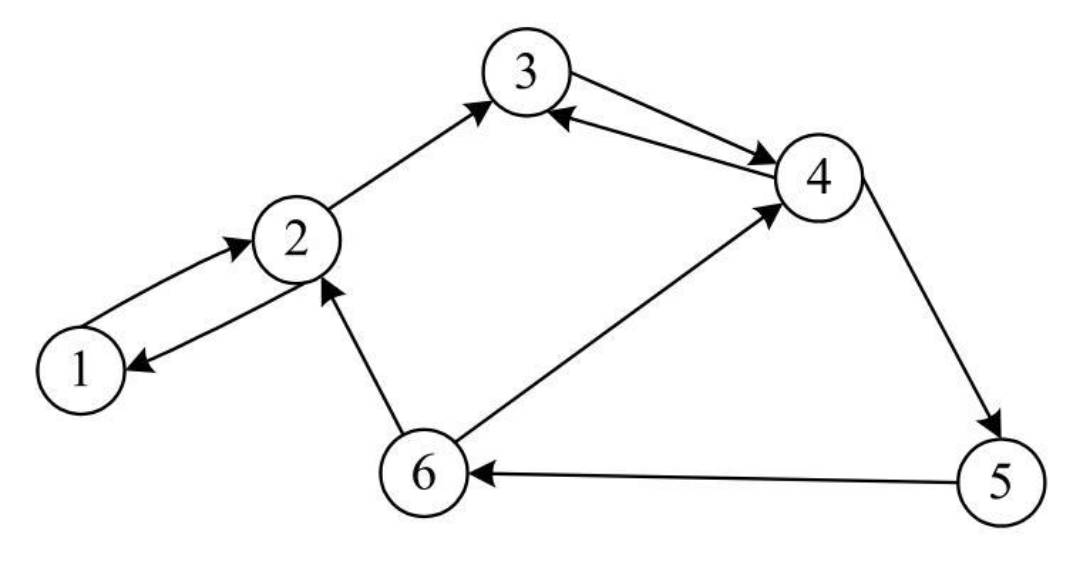
- 例如,下图所示的有向图中,顶点V3的入度为2,出度为1,因此,顶点V3的度为3。
邻接顶点:图结构中一条边的两个顶点。
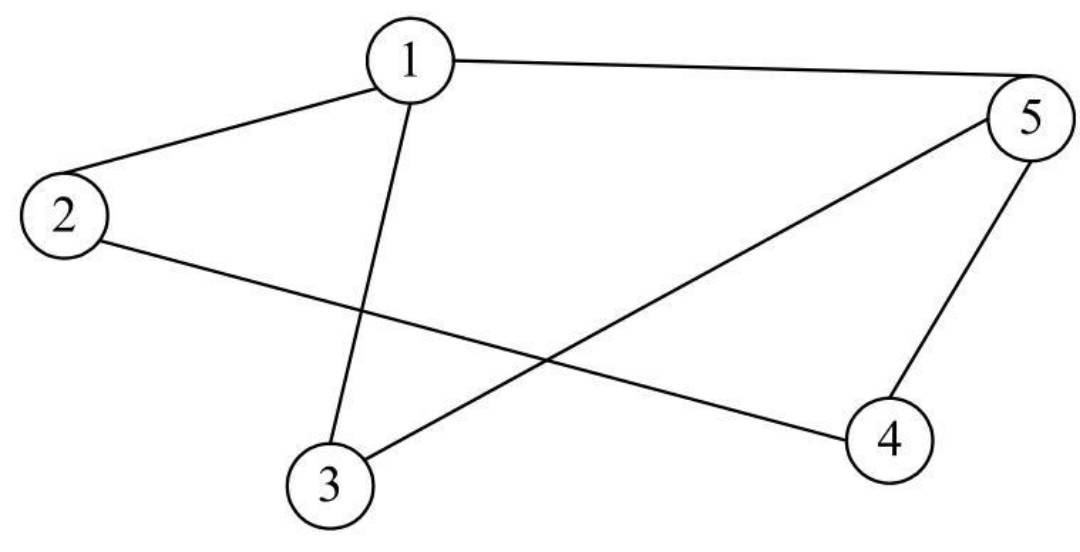
- 对于无向图,邻接顶点比较简单。例如,在下所示的无向图中,顶点V1、V5互为邻接顶点,另外,顶点V1的邻接顶点有顶点V2、顶点V3和顶点V5。
对于有向图则稍微复杂一些,根据连接顶点V的边的方向性,两个顶点分别被称为起始顶点(起点或始点)和结束顶点(终点)。有向图的邻接顶点可分为两类。
- 入边邻接顶点:连接该顶点的边中的起始顶点。例如,对于组成
这条边的两个顶点,V1是V2的入边邻接顶点。 - 出边邻接顶点:连接该顶点的边中的结束顶点。例如,对于组成
这条边的两个顶点,V2是V1的出边邻接顶点。
- 入边邻接顶点:连接该顶点的边中的起始顶点。例如,对于组成
- 子图:子图的概念类似于子集合,由于一个完整的图结构包括所有的顶点和边,因此任意一个子图的顶点和边都应该是完整图结构的子集合。
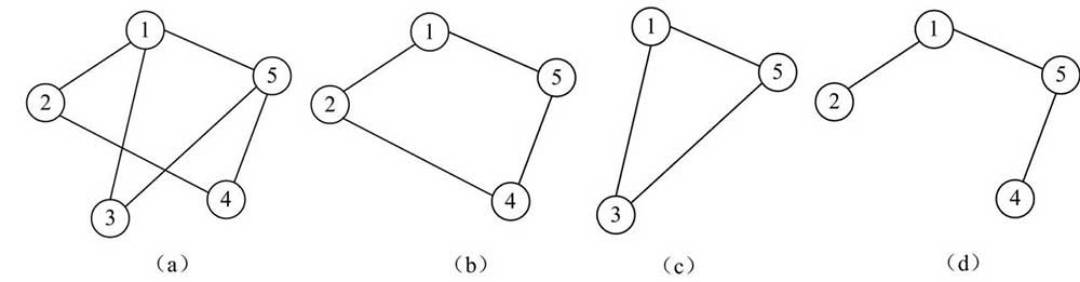
例如,下图中的图(a)为一个无向图结构,图(b)、图(c)和图(d)均为图(a)的子图。
- 这里需要强调的是,只有顶点集合是子集的,或者只有边集合是子集的,都不是子图。
路径、路径长度和回路:
- 路径就是图结构中两个顶点之间的连线,路径上边的数量称之为路径长度。
- 具体如下图,粗线部分显示的是顶点V5到V2之间的一条路径,这条路径途经的顶点为V4,途经的边依次为(V5,V4)、(V4,V2),路径长度为2。
同样,也可以在该图中找到顶点V5到V2之间的其他路径,分别如下所示:
- 路径(V5,V1)、(V1,V2),途经顶点V1,路径长度为2。
- 路径(V5,V3)、(V3,V1)、(V1,V2),途经顶点V1和V3,路径长度为3。

图结构中的路径还可以细分为如下几种形式:
- 简单路径:在图结构中,如果一条路径上顶点不重复出现,称为简单路径。
- 环:在图结构中,如果路径的第一个顶点和最后一个顶点相同,称为环,有时也称为回路。
- 简单回路:在图结构中,如果除第一个顶点和最后一个顶点相同外,其余各顶点都不重复的回路称为简单回路。
连通、连通图、连通分量:
- 如果图结构中两个顶点之间有路径,则称这两个路径是连通的。
- 如果无向图中任意两个顶点都是连通的,那么这个图便称为连通图。
- 如果无向图中包含两个顶点是不连通的,那么这个图便称为非连通图。
- 无向图的极大连通子图称为该图的连通分量。
对于一个连通图,其连通分量有且只有一个,就是该连通图自身。而对于一个非连通图,则有可能存在多个连通分量。
- 对于n个顶点的无向图G, 若G是连通图,则最少有 n-1 条边 若G是非连通图,则最多可能有
C n − 1 2 C_{n-1}^{2} Cn−12
条边。 - 例如,在下图中,图(a)为一个非连通图,因为顶点V2和顶点V3之间没有路径。这个非连通图中的连通分量包括两个,分别为图(b)和图(c)。
- 对于n个顶点的无向图G, 若G是连通图,则最少有 n-1 条边 若G是非连通图,则最多可能有

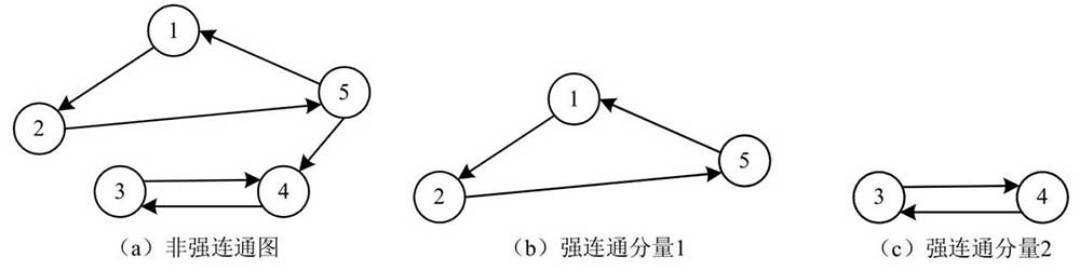
强连通图、强连通分量:
- 如果有向图中任意两个顶点都是连通的,则称该图为强连通图。
- 如果有向图中包含两个顶点不是连通的,则称该图为非强连通图。
有向图的极大强连通子图称为该图的强连通分量。
- 极大强连通子图:子图必须强连通,同时 保留尽可能多的边。
强连通图有且只有一个强连通分量,那就是该图自身。而对于一个非强连通图,则有可能存在多个强连通分量。
- 对于n个顶点的有向图G, 若G是强连通图,则最少有 n 条边(形成回路)。
- 例如,在下图中,图(a)为一个非强连通图,因为其中顶点V2和顶点V3之间没有路径。这个非强连通图中的强连通分量包括两个,分别为图(b)和图(c)。
边的权、网:
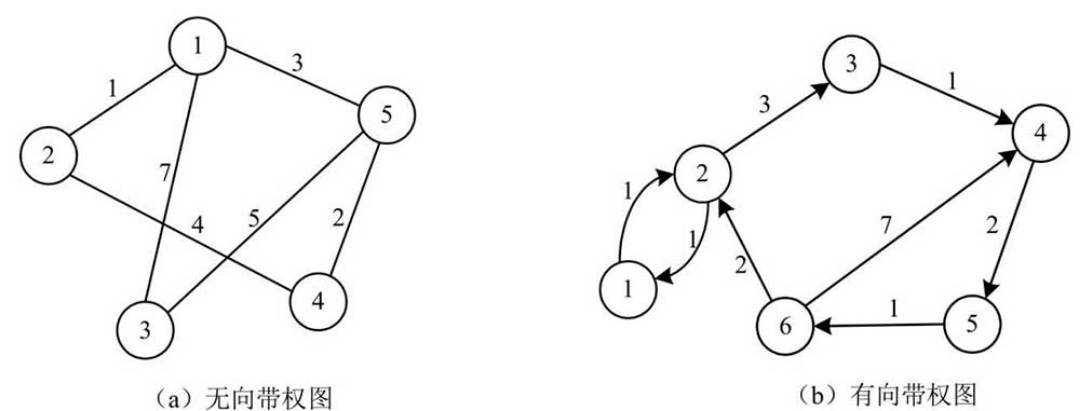
- 边的权:在一个图中,每条边都可以标上具有某种含义的数值,该数值称为该边的权值。
带权图/网:边上带有权值的图称为带权图,也称网。
- 带权路径长度:当图是带权图时,一条路径上所有边的权值之和,称为该路径的带权路径长度。
无向图中加入权值,称为无向带权图;
- 有向图中加入权值,称为有向带权图。
- 无向带权图和有向带权图如下图所示:
生成树、生成森林:
生成树: 包含图中全部顶点的一个极小连通子图。
- 极小连通子图:边尽可能的少, 但要保持连通。
- 若图中顶点数为n,则它的生成树含有 n-1 条边。对生成树而言,若砍去它的一条边,则会变成非连通 图,若加上一条边则会形成一个回路。
- 生成森林:在非连通图中,连通分量的生成树构成了非连通图的生成森林。
树、有向树
- 树:不存在回路,且连通的无向图。
- 有向树:一个顶点的入度为0,其余顶点的入度均为1的有向图,即有向树。
- n个顶点的树,必有n-1条边。n个顶点的图,若 |E|>n-1,则一定有回路。
- 边数很少的图称为稀疏图,反之称为稠密图。
5.3 图的存储结构
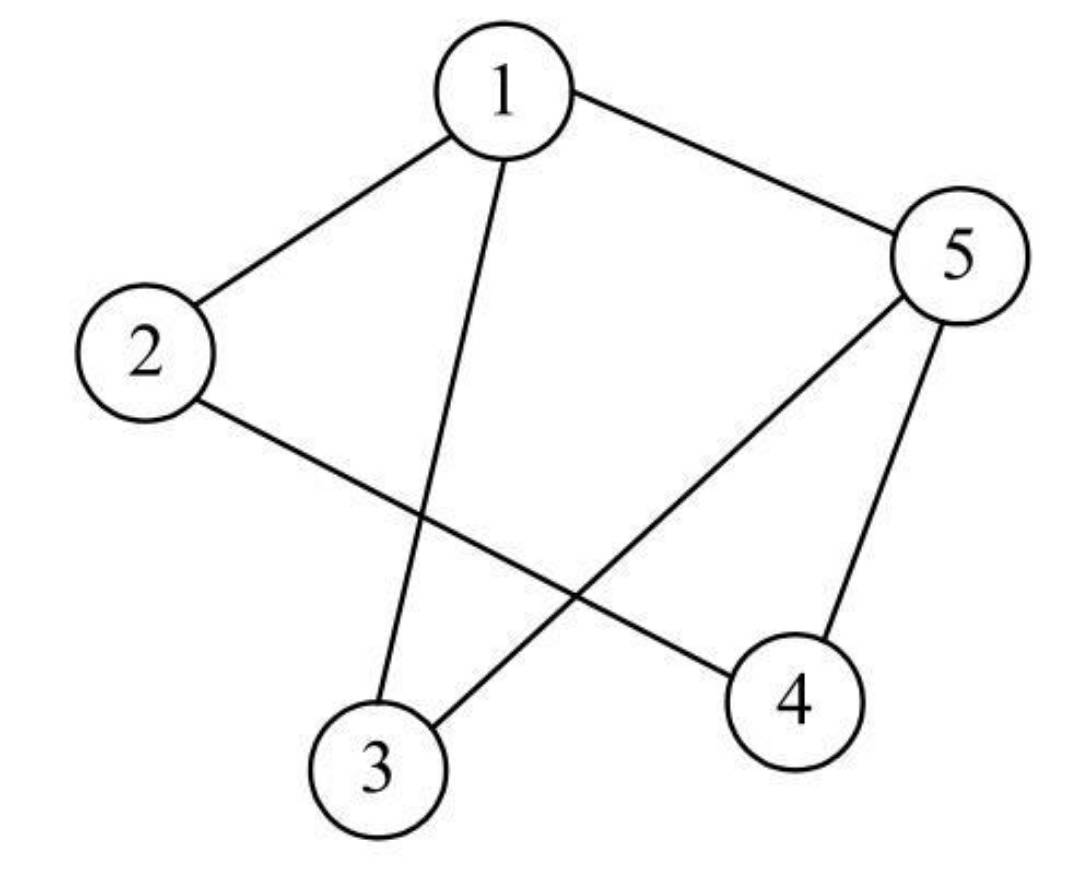
邻接矩阵
- 采用结构数组的形式来单独保存顶点信息,然后采用二维数组的形式保存顶点之间的关系。这种保存顶点之间关系的数组称为邻接矩阵(Adjacency Matrix)。
对于一个包含n个顶点的图,可以使用如下语句来声明1个数组保存顶点信息,再声明1个邻接矩阵保存边的权。
char Vertex[n]; //保存顶点信息(序号或字母)int EdgeWeight[n][n]; //邻接矩阵,保存边的权
- 对于数组Vertex,其中每一个数组元素用来保存顶点信息,可以是序号或者字母。
- 而邻接矩阵EdgeVeight用来保存边的权或者连接关系。
- 在表示连接关系时,该二维数组中的元素EdgeVeight[ i ] [ j ]=1表示(Vi,Vj)或
构成一条边,如果EdgeVeight[ i ] [ j ]=0表示(Vi,Vj)或 不构成一条边。
- 对于下图所示的无向图,可以采用一维数组来保存顶点,保存的形式如图2所示:
程序示例代码如下:
Vertex[1]=1;Vertex[2]=2;Vertex[3]=3;Vertex[4]=4;Vertex[5]=5;
- 对于邻接矩阵,可以按照下图所示的形式进行存储。
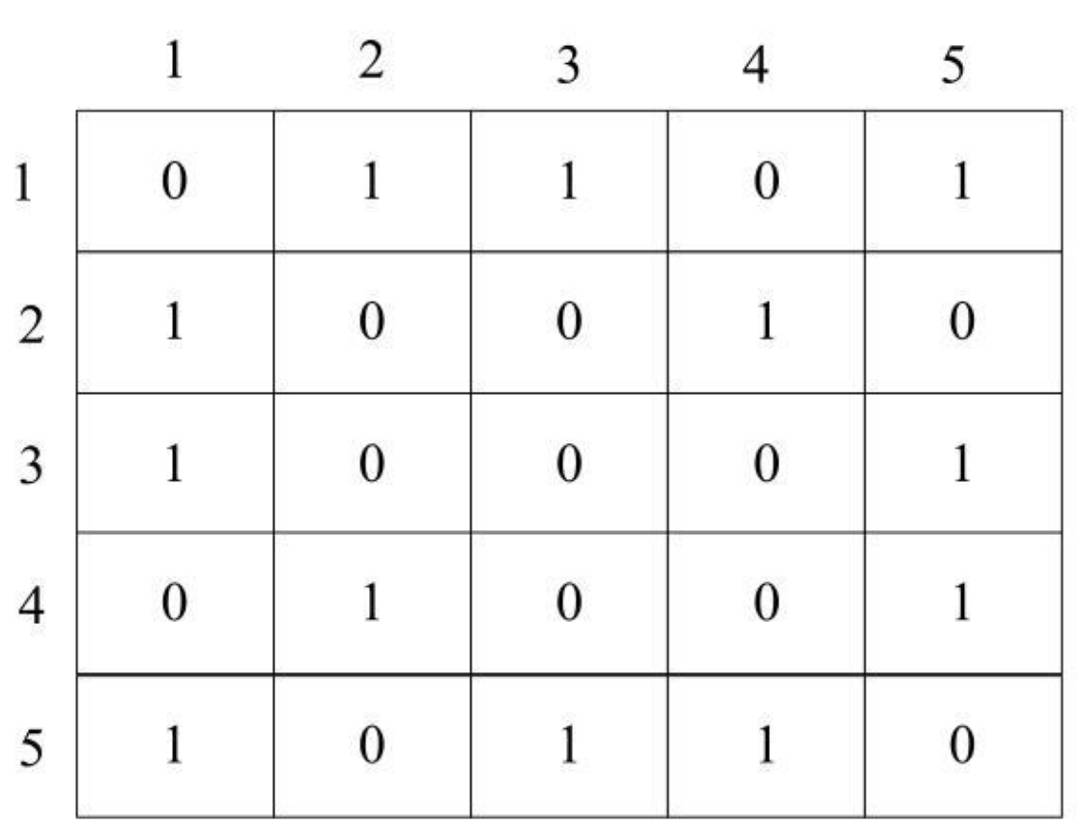
- 对于有边的两个顶点,在对应的矩阵元素中填入1。例如,V1和V3之间存在一条边,因此EdgeVeight[1] [3]中保存1,而V3和V1之间存在一条边,因此EdgeVeight[3] [1]中保存1。由此可见,对于无向图,其邻接矩阵左下角和右上角是对称的。
对于有向图,如下所示:
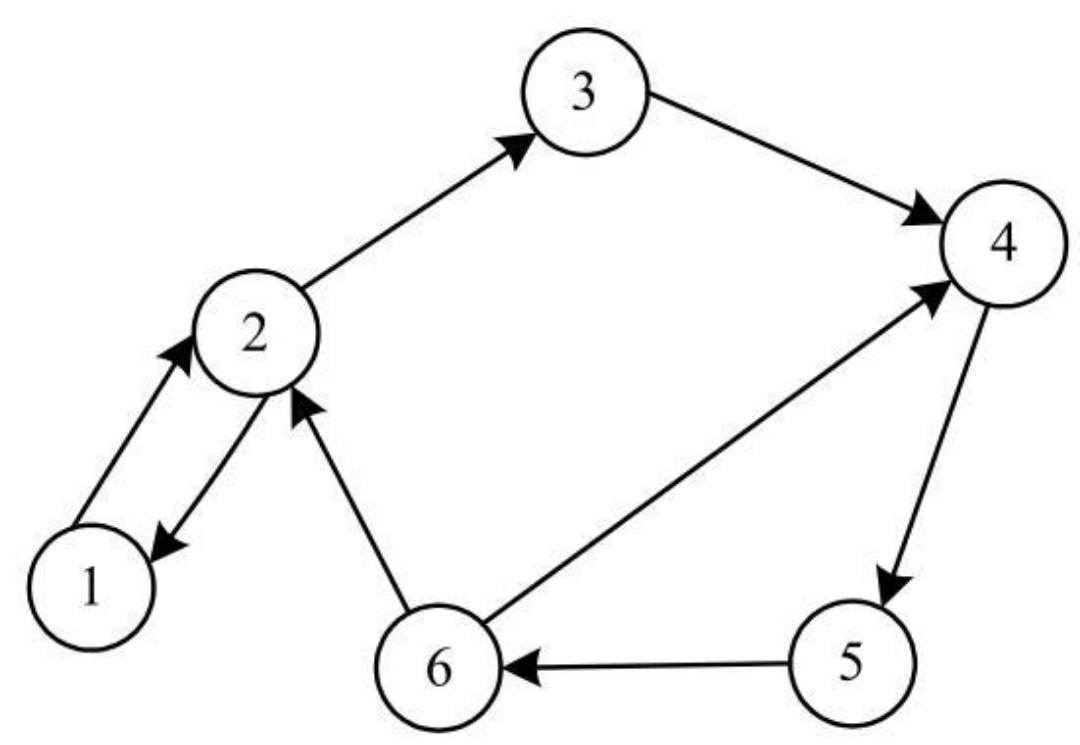
- 保存顶点的一维数组形式不变,如图1所示。而对于邻接矩阵,仍然采用二维数组,其保存形式如下图所示。对于有边的两个顶点,在对应的矩阵元素中保存1。

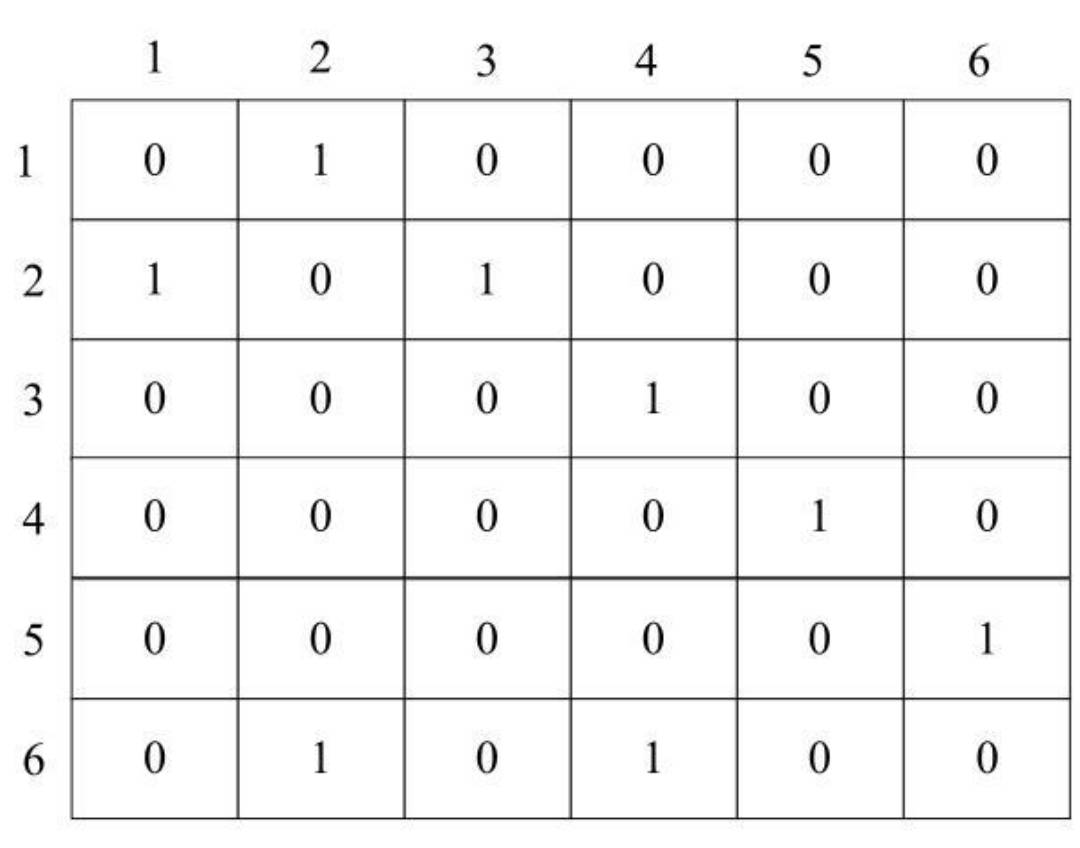
- 顶点V2到顶点V3存在一条边,因此在EdgeVeight[2] [3]中保存1,而顶点V3到顶点V2不存在边,因此在EdgeVeight[3] [2]中保存0。
对于有向带权图:
- 邻接矩阵中可以保存相应的权值。即,有边的项保存对应的权值,而无边的项则保存一个特殊的符号Z。
- 例如下图:
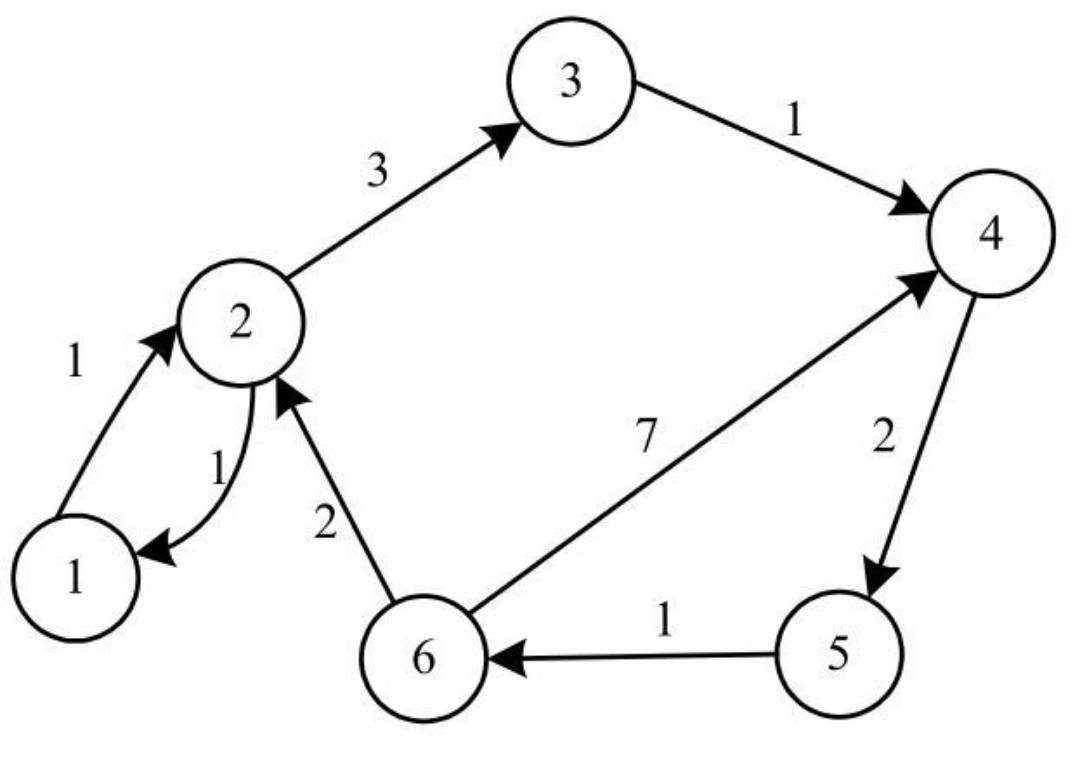
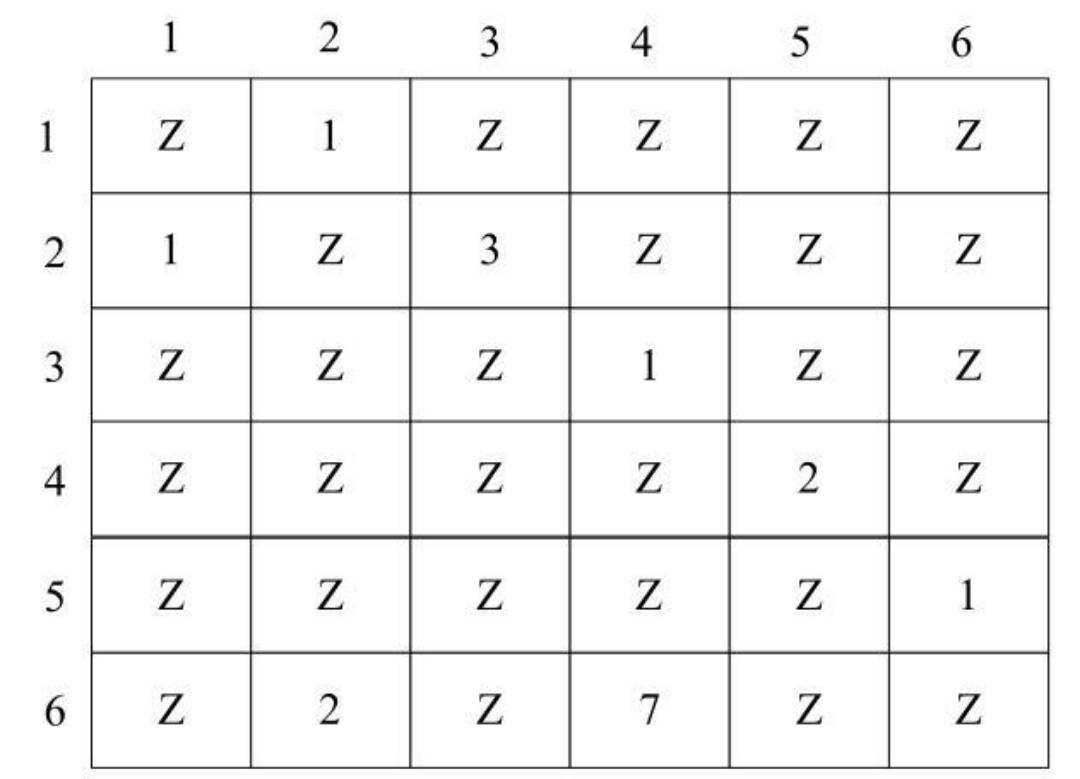
注意:在实际程序中为了保存带权值的图,需要定义一个最大值MAX,其值大于所有边的权值之和,用MAX来替代特殊的符号Z保存在二维数组中。
5.4 图的程序设计
准备工作
- 准备需要使用的变量和数据结构。
- 具体代码:
define MaxNum 20 // 图的最大顶点数
define MaxValue 65535 // 最大值(可设为一个最大整数)
typedef struct
{char Vertex[MaxNum]; // 保存顶点信息(序号或字母)int GType; // 图的类型(0:无向图,1:有向图)int VertexNum; // 顶点的数量int EdgeNum; // 边的数量int Edgeweight[MaxNum][MaxNum]; // 保存边的权int isTrav[MaxNum]; // 遍历标志
}GraphMatrix; // 定义邻接矩阵图结构
创建图
- 初始化一个图。
- 具体代码:
void CreateGraph(GraphMatrix *GM) // 创建邻接矩阵图
{int i, j, k;int weight; // 权char EstartV, EendV; // 边的起始顶点printf("输入图中各顶点信息\n");for (i = 0; i < GM->VertexNum; i++) // 输入顶点{getchar();printf("第%d个顶点:", i + 1);scanf("%c", &(GM->Vertex[i])); // 保存到各顶点数组元素中}printf("输入构成各边的顶点及权值:\n");for (k = 0; k < GM->EdgeNum; k++) // 输入边的信息{getchar();printf("第%d条边:", k + 1);scanf("%c %c %d", &EstartV, &EendV, &weight);for (i = 0; EstartV != GM->Vertex[i]; i++); // 在已有顶点中查找始点for (j = 0; EendV != GM->Vertex[j]; j++); // 在已有顶点中查找终点GM->Edgeweight[i][j] = weight; // 对应位置保存权值,表示有一条边if (GM->GType == 0) // 若是无向图{GM->Edgeweight[j][i] = weight; // 在对角位置保存权值}}
}
清空图
- 将一个图结构变成空图,即将矩阵的各元素设置为MaxValue即可。
- 具体代码:
void ClearGraph(GraphMatrix *GM)
{int i, j;for (i = 0; i < GM->VertexNum; i++) // 清空矩阵{for (j = 0; j < GM->VertexNum; j++){GM->Edgeweight[i][j] = MaxValue; // 设置矩阵中各元素的值为Maxvalue}}
}
显示图
- 显示邻接矩阵。
- 具体代码:
void OutGraph(GraphMatrix *GM) // 输出邻接矩阵
{int i, j;for (j = 0; j < GM->VertexNum; j++){printf("\t%c", GM->Vertex[j]); // 在第1行输出顶点信息}printf("\n");for (i = 0; i < GM->VertexNum; i++){printf("%c", GM->Vertex[i]);for (j = 0; j < GM->VertexNum; j++){if (GM->Edgeweight[i][j] == MaxValue) // 若权值为最大值{printf("\tZ"); // 用表示无穷大}else {printf("\t%d", GM->Edgeweight[i][j]); // 输出边的权值}}printf("\n");}
}
遍历图
- 逐个访问图中的所有顶点。
- 具体代码:
void DeepTraOne(GraphMatrix *GM, int n) // 从第n个结点开始,深度遍历图
{int i;GM->isTrav[n] = 1; // 标记该顶点已处理过printf("->%c", GM->Vertex[n]); // 输出结点数据//添加处理结点的操作for (i = 0; i < GM->VertexNum; i++){if (GM->Edgeweight[n][i] != MaxValue && !GM->isTrav[n]){DeepTraOne(GM, i); // 递归进行遍历}}
}
void DeepTraGraph(GraphMatrix *GM) // 深度优先遍历
{int i;for (i = 0; i < GM->VertexNum; i++) // 清除各顶点遍历标志{GM->isTrav[i] = 0;}printf("深度优先遍历结点:");for (i = 0; i < GM->VertexNum; i++){if (!GM->isTrav[i]) // 若该点未遍历{DeepTraOne(GM, i); // 调用函数遍历}}printf("\n");
}
案例:使用深度遍历实现图操作
- 具体代码:
include
define MaxNum 20 // 图的最大顶点数
define MaxValue 65535 // 最大值(可设为一个最大整数)
typedef struct
{char Vertex[MaxNum]; // 保存顶点信息(序号或字母)int GType; // 图的类型(0:无向图,1:有向图)int VertexNum; // 顶点的数量int EdgeNum; // 边的数量int Edgeweight[MaxNum][MaxNum]; // 保存边的权int isTrav[MaxNum]; // 遍历标志
}GraphMatrix; // 定义邻接矩阵图结构
void CreateGraph(GraphMatrix *GM) // 创建邻接矩阵图
{int i, j, k;int weight; // 权char EstartV, EendV; // 边的起始顶点printf("输入图中各顶点信息\n");for (i = 0; i < GM->VertexNum; i++) // 输入顶点{getchar();printf("第%d个顶点:", i + 1);scanf("%c", &(GM->Vertex[i])); // 保存到各顶点数组元素中}printf("输入构成各边的顶点及权值:\n");for (k = 0; k < GM->EdgeNum; k++) // 输入边的信息{getchar();printf("第%d条边:", k + 1);scanf("%c %c %d", &EstartV, &EendV, &weight);for (i = 0; EstartV != GM->Vertex[i]; i++); // 在已有顶点中查找始点for (j = 0; EendV != GM->Vertex[j]; j++); // 在已有顶点中查找终点GM->Edgeweight[i][j] = weight; // 对应位置保存权值,表示有一条边if (GM->GType == 0) // 若是无向图{GM->Edgeweight[j][i] = weight; // 在对角位置保存权值}}
}
void ClearGraph(GraphMatrix *GM)
{int i, j;for (i = 0; i < GM->VertexNum; i++) // 清空矩阵{for (j = 0; j < GM->VertexNum; j++){GM->Edgeweight[i][j] = MaxValue; // 设置矩阵中各元素的值为Maxvalue}}
}
void OutGraph(GraphMatrix *GM) // 输出邻接矩阵
{int i, j;for (j = 0; j < GM->VertexNum; j++){printf("\t%c", GM->Vertex[j]); // 在第1行输出顶点信息}printf("\n");for (i = 0; i < GM->VertexNum; i++){printf("%c", GM->Vertex[i]);for (j = 0; j < GM->VertexNum; j++){if (GM->Edgeweight[i][j] == MaxValue) // 若权值为最大值{printf("\tZ"); // 用表示无穷大}else {printf("\t%d", GM->Edgeweight[i][j]); // 输出边的权值}}printf("\n");}
}
void DeepTraOne(GraphMatrix *GM, int n) // 从第n个结点开始,深度遍历图
{int i;GM->isTrav[n] = 1; // 标记该顶点已处理过printf("->%c", GM->Vertex[n]); // 输出结点数据//添加处理结点的操作for (i = 0; i < GM->VertexNum; i++){if (GM->Edgeweight[n][i] != MaxValue && !GM->isTrav[n]){DeepTraOne(GM, i); // 递归进行遍历}}
}
void DeepTraGraph(GraphMatrix *GM) // 深度优先遍历
{int i;for (i = 0; i < GM->VertexNum; i++) // 清除各顶点遍历标志{GM->isTrav[i] = 0;}printf("深度优先遍历结点:");for (i = 0; i < GM->VertexNum; i++){if (!GM->isTrav[i]) // 若该点未遍历{DeepTraOne(GM, i); // 调用函数遍历}}printf("\n");
}
void main()
{GraphMatrix GM; // 定义保存邻接表结构的图printf("输入生成图的类型:");scanf("%d", &GM.GType); // 图的种类printf("输入图的顶点数量:");scanf("%d", &GM.VertexNum); // 输入图顶点数printf("输入图的边数量:");scanf("%d", &GM.EdgeNum); // 输入图边数ClearGraph(&GM); // 清空图CreateGraph(&GM); // 生成邻接表结构的图printf("该图的邻接矩阵数据如下:\n");OutGraph(&GM); // 输出邻接矩阵DeepTraGraph(&GM); // 深度优先搜索遍历图
}
参考文献
- [1]. 2020年王道考研数据结构考研复习指导.王道论坛
- [2]. C/C++常用算法手册(第三版).刘亚冬
- [3]. 数据结构(C语言版).严蔚敏(黑版)
- [4]. 算法笔记.胡凡
- [5]. 数据结构习题与解析(第3版).李春葆
- [6]. 数据结构与算法(C语言版).胡明
全文仅用于个人备考复习,不可商用。






























还没有评论,来说两句吧...