【python实现网络爬虫21】天眼查企业数据获取
天眼查企业数据获取
- 目标网址及爬取要求
- 网页过渡
- 具体数据的获取
- 扩展及全部代码
手动反爬虫: 原博地址
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
如若转载,请标明出处,谢谢!
1. 目标网址及爬取要求
根据搜索进行相应公司具体信息数据的爬取,第一步是进入天眼查的官网,然后输入公司的名称,然后在返回数据默认评分第一位的公司点击进入后呈现的结果就是要爬取的内容,这里以小米公司为例
第一步:打开天眼查网站主页
第二步: 输入小米后回车确认,然后滚动条下拉找到匹配的公司
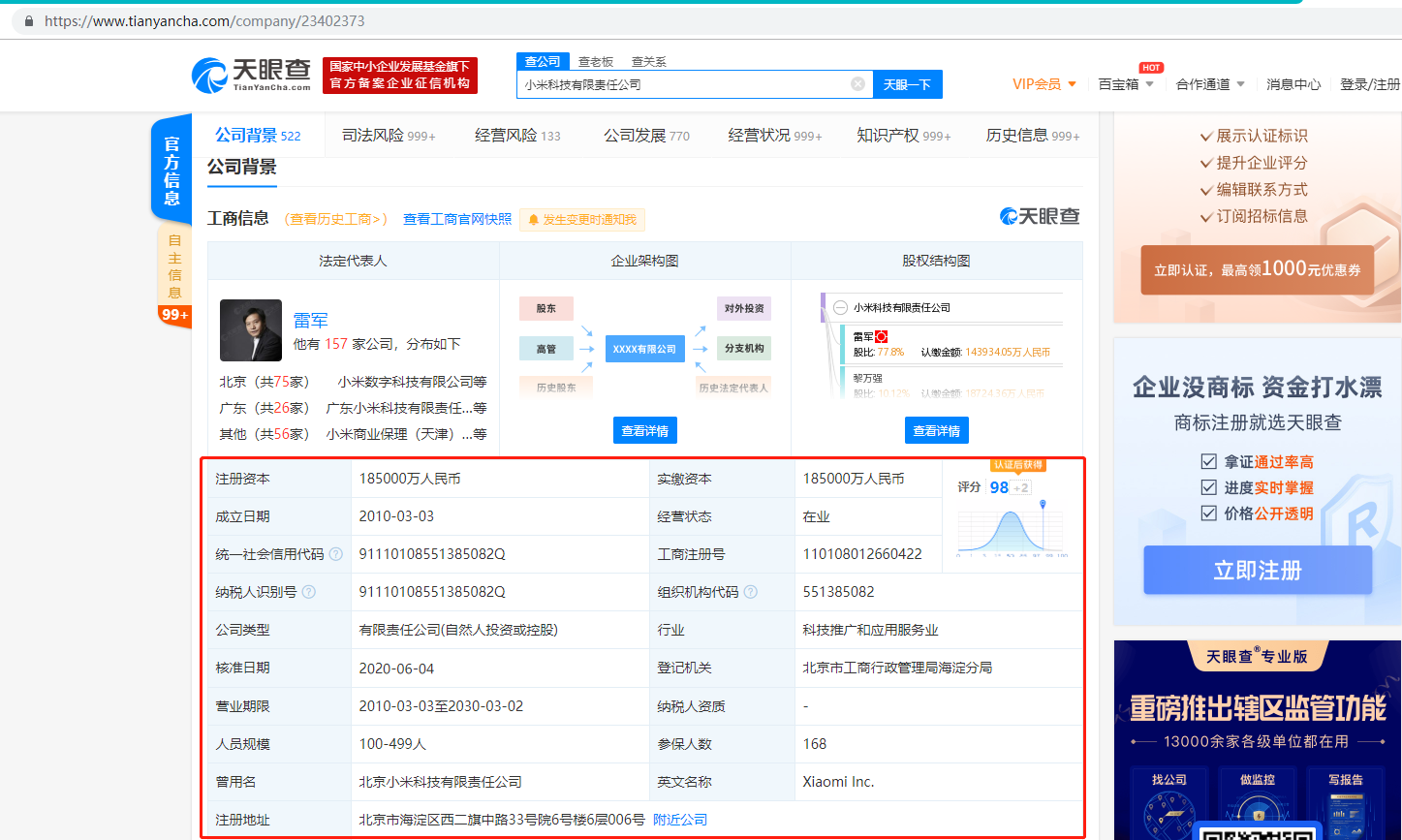
第三步,点击进入公司,查看详情,最后爬取下面红色框线中的内容
2. 网页过渡
由于存在翻页的现象,因此要想获得具体的数据,需要首先进入过渡网页(搜索结果页面),然后提取该网页中包含我们要爬取信息的url(公司页面),最后再进入该url对应的网址下请求信息
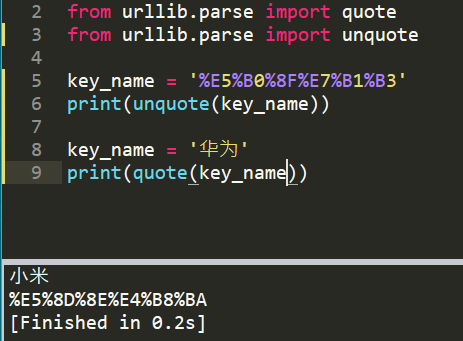
这里进入天眼查主页后,输入 “小米” 后回车确认,把跳转后的网址复制粘贴到编辑器中发现会被自动转码,因此要实现根据用户输入的公司名称进行具体数据的爬取,就要进行汉字的转码识别

这里使用quote和unquote模块进行转码和解码,比如进行小米,华为两个词语的解码和转码,如下
因此请求过渡界面的代码如下:(注意添加自己的cookie和header)
headers = {'Cookie': 'aliyungf_tc=AQAAAAEVaWaoZwkALukNq6/ruqDOSG3n; csrfToken=VtbnK1tn9NoUb0fUqHVlS0Xc; jsid=SEM-BAIDU-PZ0824-SY-000001; bannerFlag=false; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1600135387; show_activity_id_4=4; _gid=GA1.2.339666032.1600135387; relatedHumanSearchGraphId=23402373; relatedHumanSearchGraphId.sig=xQxyUIDqVdMkulWk5m_htP28Pzw8_eM8tUMIyK4_qqs; refresh_page=0; RTYCID=69cd6d574b1c4116995bab3fd96a9466; CT_TYCID=a870d4ebb91849b094668d1d969c7702; token=899079c4b21e4d22916083d22f72e1e3; _utm=dac53239b45f49709262be264fd289f3; cloud_token=bb4c875aed794641966b7f7536187e80; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1600147199; _gat_gtag_UA_123487620_1=1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}key_word = '小米'url = 'https://www.tianyancha.com/search?key={}'.format(quote(key_word))html = requests.get(url,headers = headers)soup = BeautifulSoup(html.text,'lxml')info = soup.select('.result-list .content a')[0]company_name = info.textcompany_url = info['href']print(company_name,company_url)
输出结果为:(正常获取要爬取网址的名称和url)
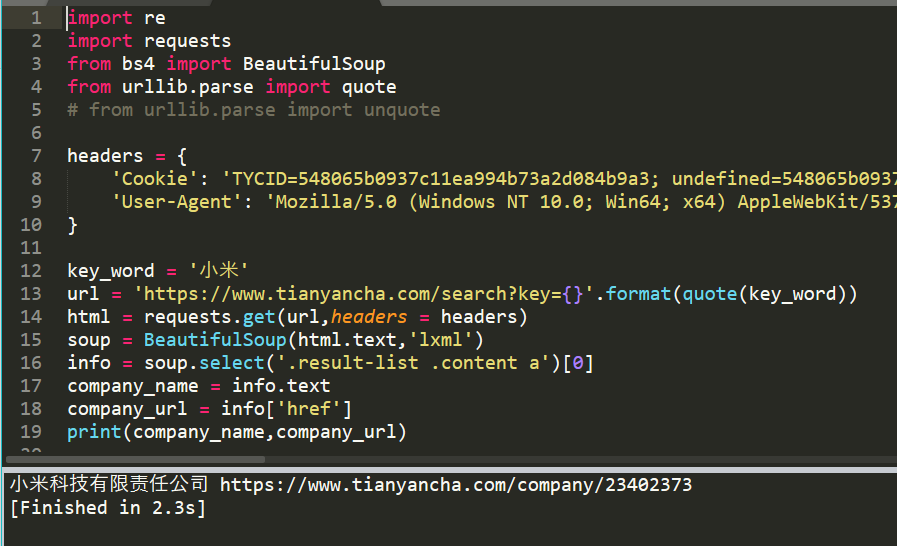
3. 具体数据的获取
还是基于获取的company_url,再次发起requests请求,然后解析数据即可,重点在于解析标签信息,如下
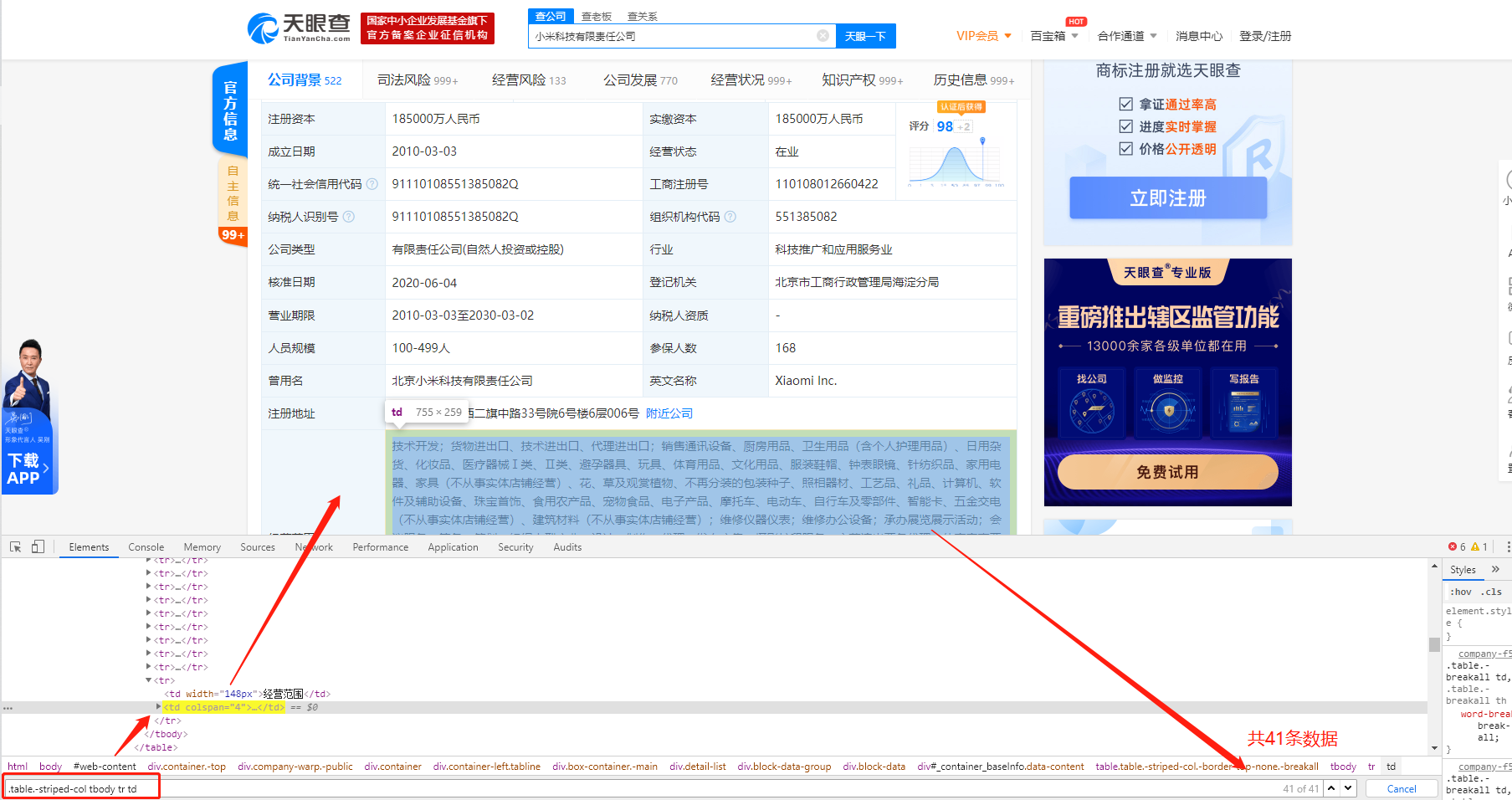
因此遍历循环获得的标签后就可以提取数据了,代码如下,顺便也可以在爬取数据的同时将数据保存在本地,由于数据是一条条获取的这里使用追加的模式进行写入。
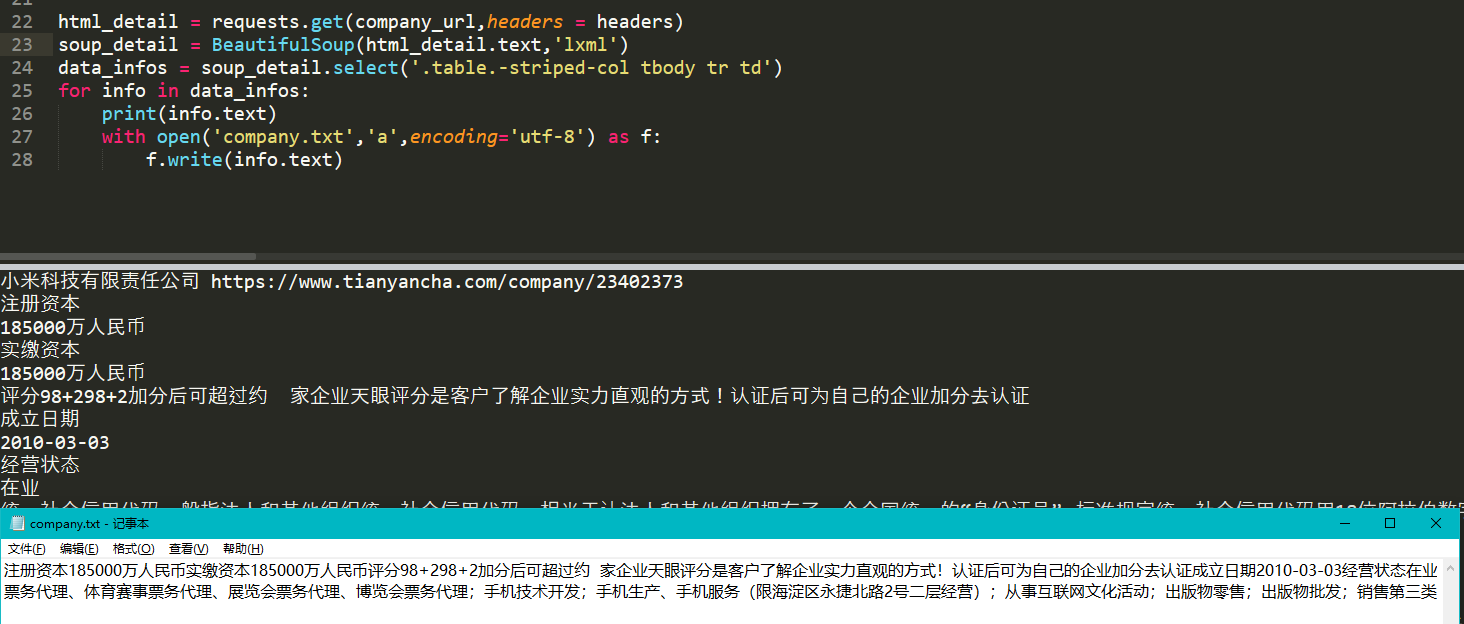
html_detail = requests.get(company_url,headers = headers)soup_detail = BeautifulSoup(html_detail.text,'lxml')data_infos = soup_detail.select('.table.-striped-col tbody tr td')for info in data_infos:print(info.text)with open('company.txt','a',encoding='utf-8') as f:f.write(info.text)
输出的结果为:(截取部分结果)
4. 扩展及全部代码
上述进行了单个的公司数据的获取,也可以进行多个或者批量的数据获取,只需要将公司的名称存成列表的形式 然后再遍历就可以了,这里以“华为”、“小米”、“知乎”为例,进行数据获取并写入到txt文本中进行换行保存
key_words = ['小米','华为','知乎']for key_word in key_words:url = 'https://www.tianyancha.com/search?key={}'.format(quote(key_word))html = requests.get(url,headers = headers)soup = BeautifulSoup(html.text,'lxml')info = soup.select('.result-list .content a')[0]company_name = info.textcompany_url = info['href']print(company_name,company_url)html_detail = requests.get(company_url,headers = headers)soup_detail = BeautifulSoup(html_detail.text,'lxml')data_infos = soup_detail.select('.table.-striped-col tbody tr td')with open('company.txt','a+',encoding='utf-8') as f:f.write('\n'+company_name + " : " + '\n')for info in data_infos:print(info.text)f.write(info.text)
输出的结果为:(可以发现第一行是多一行换行符的,有点强迫症,可以通过添加计数器来消除,可知只在第一行有,就可以设置num,如果num为0也就是写入第一个数据时候,换行符为0即可)

完善的全部代码如下:
import reimport requestsfrom bs4 import BeautifulSoupfrom urllib.parse import quoteheaders = {'Cookie': 'csrfToken=VtbnK1tn9NoUb0fUqHVlS0Xc; jsid=SEM-BAIDU-PZ0824-SY-000001; bannerFlag=false; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1600135387; show_activity_id_4=4; _gid=GA1.2.339666032.1600135387; relatedHumanSearchGraphId=23402373; relatedHumanSearchGraphId.sig=xQxyUIDqVdMkulWk5m_htP28Pzw8_eM8tUMIyK4_qqs; refresh_page=0; RTYCID=69cd6d574b1c4116995bab3fd96a9466; CT_TYCID=a870d4ebb91849b094668d1d969c7702; token=899079c4b21e4d22916083d22f72e1e3; _utm=dac53239b45f49709262be264fd289f3; cloud_token=bb4c875aed794641966b7f7536187e80; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1600147199; _gat_gtag_UA_123487620_1=1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}key_words = ['小米','华为','知乎']num = 0for key_word in key_words:url = 'https://www.tianyancha.com/search?key={}'.format(quote(key_word))html = requests.get(url,headers = headers)soup = BeautifulSoup(html.text,'lxml')info = soup.select('.result-list .content a')[0]company_name = info.textcompany_url = info['href']print(company_name,company_url)html_detail = requests.get(company_url,headers = headers)soup_detail = BeautifulSoup(html_detail.text,'lxml')data_infos = soup_detail.select('.table.-striped-col tbody tr td')with open('company.txt','a+',encoding='utf-8') as f:if num != 0:num = 1f.write('\n'*num+company_name + " : " + '\n')for info in data_infos:print(info.text)f.write(info.text)num += 1
输出的结果为:(空换行符的问题就解决了)

注:另外程序可以直接封装函数,通过传递一个列表数据然后生成本地的数据文件(也可以把数据数据形成一个字符串,然后遍历),这样做的好处在于通过pandas处理数据,提取要爬取数据的公司的列表然后直接传递到这个函数中就可以实现根据要求的批量数据进行天眼查上的数据获取了
demo部分代码如下:(只是部分代码,要想获得天眼查中批量的数据还是需要一些其他的技巧,比如动态ip设置)
import Companydef searchData(name,dic_h,dic_c):print(f'正在搜索:{name}')name_quote = quote(name)url = f'https://www.tianyancha.com/search?key={name}'html = requests.get(url, headers = dic_h,cookies = dic_c)soup = BeautifulSoup(html.text,'lxml')campany = soup.select('div.header a')[0]href = campany['href']print(href)return hrefcompanys = Company.companydata_list = []error_list = []i = 1for company in companys:try:dic = { }print('爬取第{}次数据'.format(i))i += 1dic['公司名称'] = companydic['url'] = searchData(company,dic_h,dic_c,ips)data_list.append(dic)except:print('信息爬取失败')error_list.append(company)data = pd.DataFrame(data_list)data.to_excel('final.xlsx',index = False)data_error = pd.DataFrame(error_list)data_error.to_excel('error.xlsx',index = False)
Company模块就是把所有公司的名称放置在该文件中并赋值为company变量,部分内容截图如下




























——OBS权限配置")
- CAN协议错误帧")

")



还没有评论,来说两句吧...