【论文阅读】Improving Document-level Relation Extraction via Contextualizing Mention Representations and W
ICKG 2020
作者提供的源代码
Improving Document-level Relation Extraction via Contextualizing Mention Representations and Weighting Mention Pairs
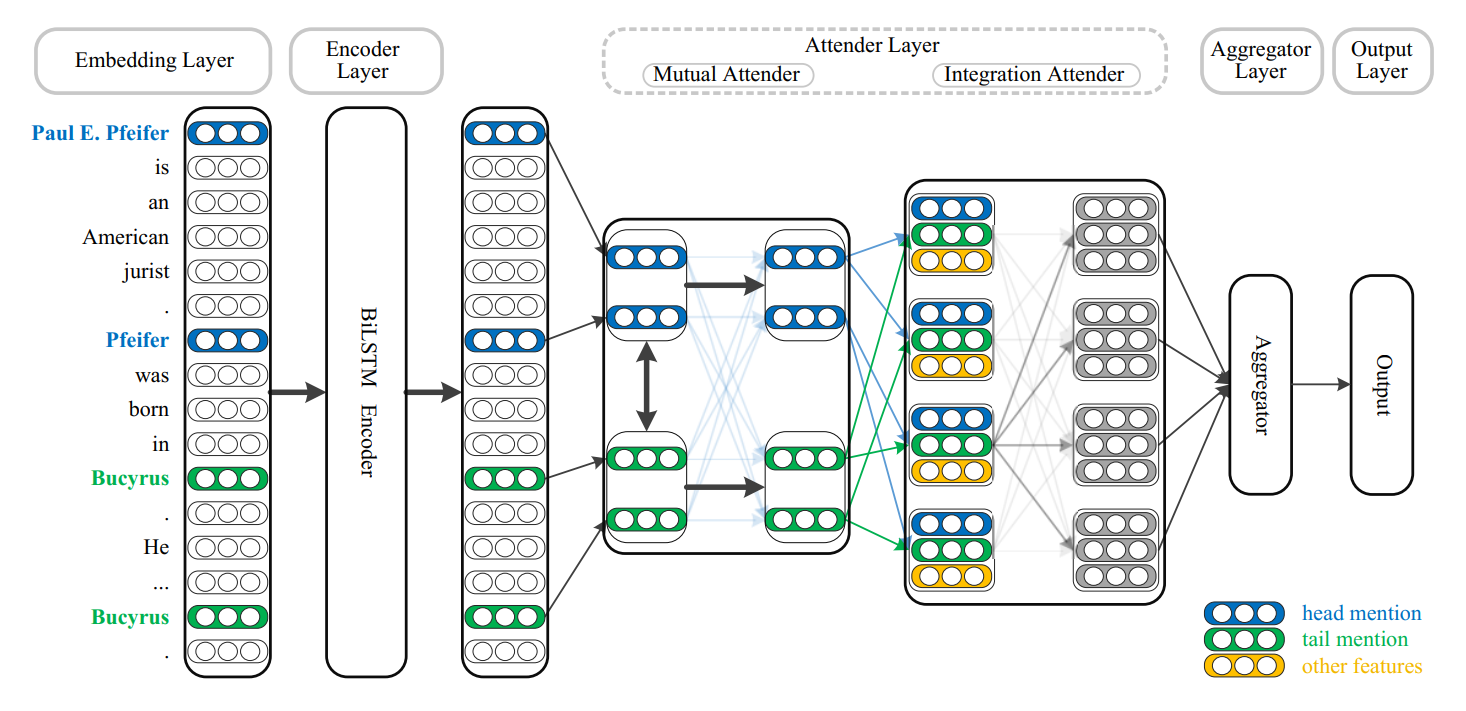
1. embedding层
每一个单词搞成word embedding,实体类型embedding,共指embedding,这三者的拼接。
将对应于同一实体的提及赋值为相同的实体id,并将实体id映射到向量中作为共指embedding。
2. encode层
把上一层的embedding送入N层堆叠的BILSTM,将BILSTM最后一层的输出送入线性层,用Relu激活一下。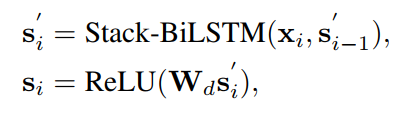
3. Attender 层
说白了都是用单层的transformer实现的。
共同Attender

H是头实体的表示,T是尾实体的表示,因此获得上下文的表示。
集成Attender
负责对实体提及的表示,进行加权,融合。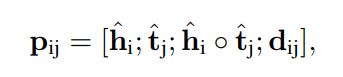
圈圈表示element-wise按位相乘。
Dij表示实体提及的距离
通过自注意,集成attender可以识别出重要的实体提及,给他赋予较高权重。
4. 聚合层和输出层
由于一个实体可以有多个实体提及,这里使用多实例学习的方案,去整合所有实体提及对的预测结果。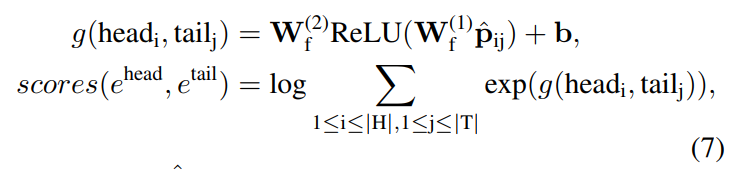
首先使用多层感知机MLP对实体提及对的表示投影到每个关系的分数,然后使用 l o g S u m E x p logSumExp logSumExp函数将对应提及对的关系得分相加。
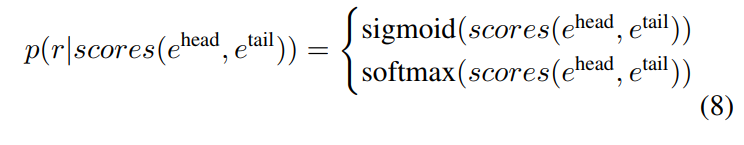
对于多标签数据集,使用 s i g m o i d sigmoid sigmoid生成每种关系的可能性。
对于其他数据集,则使用 s o f t m a x softmax softmax生成所有关系类型的分布。

























")


还没有评论,来说两句吧...