数据库生存曲线_生存曲线居然能够批量绘制了
写在前面
相信很多小伙伴在看文献的时候总是能够看到作者拿一张figure放置多个生存曲线图,不知道大家想过没有,如果作者一张小图一张小图的画,那可能图还没有画完就直接开始拍桌子了。肯定为了提升科研的效率,我们还是希望把这些重复的工作都交给计算机不厌其烦地去做,然后留更多的时间给我们自己享受生活。好啦,言归正传,我们开始今天批量生存曲线绘制的讲解。
1、代码演示
经过前面两期专栏的处理(没有跟上的同学赶快去前两期专栏看看,打牢基础才能走得更远),我们现在已经得到了单因素COX回归的结果。
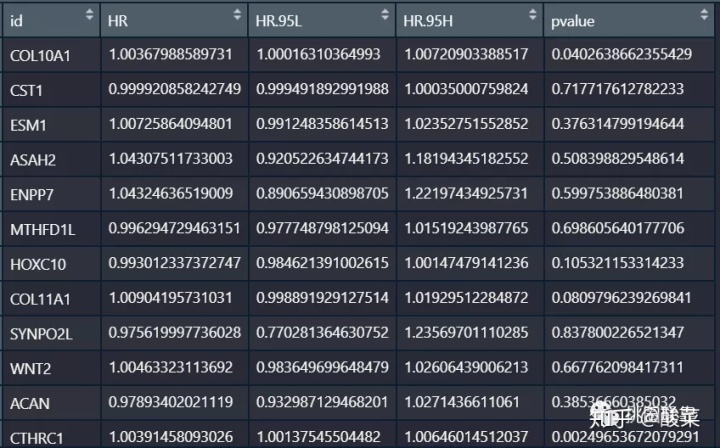
接下来我们筛选p值小于0.05的基因进行保留,这里我们使用dplyr包中的filter函数进行过滤:

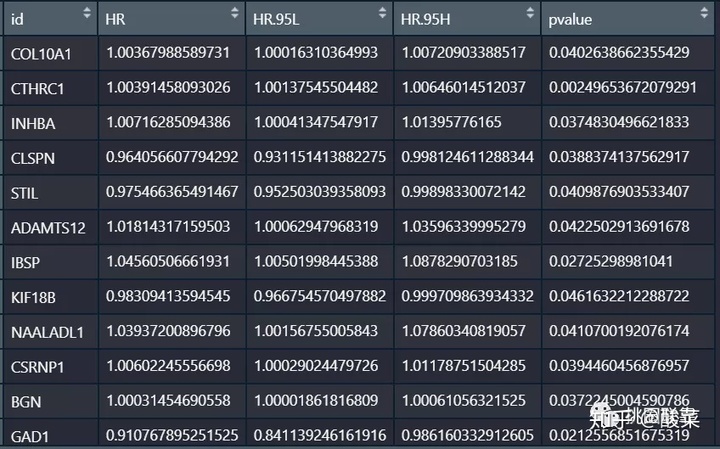
接着我们把单因素COX回归有意义的基因再提取出来,因为刚刚得到的是数据库,我们把第一列取出来即可:


得到了单因素COX回归有显著统计学意义的基因之后,我们就要开始进行生存曲线绘制即K-M分析,关于K-M分析和COX回归到底有啥区别,大家可以参考风师兄在生信下篇段位3有详细的讲解。如果用我自己的实用的理解那就是,COX分析筛选变量太多的话我们就再加上K-M分析再筛选一次,相当于双重过滤标准;但是如果你COX回归筛选之后就只有几个基因了,那就没有必要再用K-M分析去筛选了,因为筛选了完了你可能就没有基因了。
接下来我们从单因素COX回归的数据框中把pvalue小于0.05的基因提取出来,这里我们使用dplyr包中的select函数,注意这里要记得使用all_off函数把向量放在函数里面,这样才能提取对应的列:

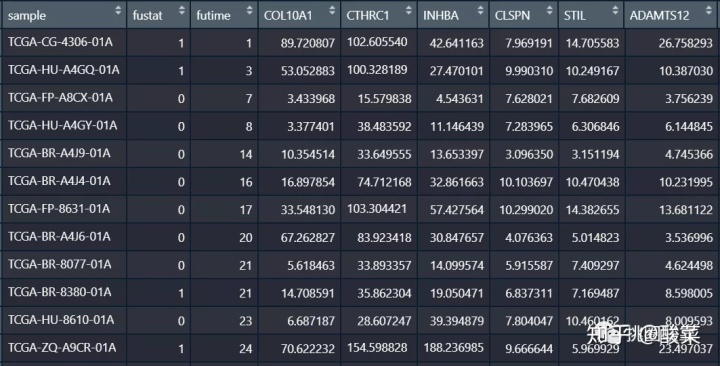
接下来我们进行生存曲线的绘制,首先绘制生存曲线,我们首先需要解压两个强大的包,survival包和survminer包。

首先为了降低难度,我们先来进行一条生存生存曲线的绘制,我们先提取一个基因的表达量:

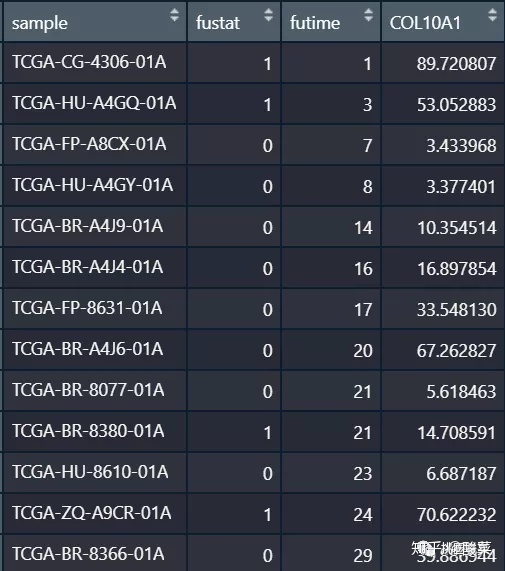
然后我们构建一个分组文件,根据基因表达量的中位值进行高低两组的划分:

然后我们计算高低表达两组之间的生存的p值大小:
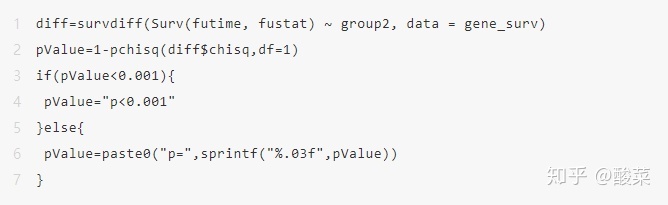
接下来拟合一个生存函数,这里我们使用survfit函数进行拟合:

最后我们使用ggsurvplot函数来绘制生存曲线,代码参考来自于生信体系课下篇,需要进一步学习的同学可以参看我们的生信体系课,里面有更多丰富的知识等待大家。

一张可用于文章发表的生存曲线图就绘制好了:
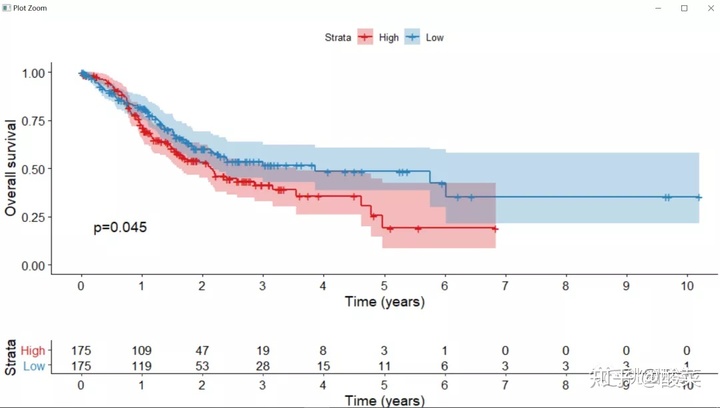
虽然一张绘制好了,但是我们本期的问题还没有解决,我们不仅要一张,我们要很多张。套用一句经典的话就是,只要小孩子才做选择,成年人是全部都要,而且越多越好,图多了我们才有选择的余地。
接下来我们进行批量绘制,批量绘制的原理无非就是循环,而循环就是一列一列循环,然后每一列绘制一个生存曲线。


写在最后
每次在跑循环的时候总感觉就是在收获财富,因为每跑一张图,就有可能放到论文里面,然后构成一个完成的figure,希望大家也能和我有同样的感受!希望继续继续关注我们,希望大家都能在这里学有所获,收到满满的干货,好啦,这期的内容就到这里啦,我们下周日再见~
作者:先锋宇
本文首发于“ 解螺旋”微信公众号
转载请注明:解螺旋·临床医生科研成长平台



























")






还没有评论,来说两句吧...