论文详解Memory Efficient Incremental learning through feature adaptation. ECCV2020 基于增量特征映射
ECCV2020,由Google Research提出。
看标题是基于样本回放的方法。如何在网络变化之后,将旧特征映射到新特征。
类似的方法例如SDC,Semantic Drift Composition。
SDC: SDC论文详解Semantic Drift Compensation for Class-Incremental Learning. CVPR 2020
目录
1.贡献点
1.1 基于rehearsal方法的分类
1.2 贡献点
2.框架
2.1 特征提取+分类器
2.2 蒸馏Loss
2.3 Feature Adaptation
2.4 feature adaptation network
2.5 Memory尺寸的降低
- 实验
3.1 存储效率
3.2 准确率
- 评价
1.贡献点
模型不存储样本,只存储样本提取出的feature. 本文通过多层感知机实现feature的新适应。
1.1 基于rehearsal方法的分类
基于rehearsal的方法分为如下几类:
- Non-rehearsal: 即不需要rehearsal, 例如LwF直接用新旧网络之间进行知识蒸馏,不需要存储旧样本。
- Exemplars: 直接存储原始图片,例如iCARL(Incremental Classifier and Representation Learning),直接将原始图片存储为exemplars.
- Generated images: 利用GANs生成fake images
- Feature based methods: 基于特征存储的方法,直接利用memory存储网络特征。
1.2 贡献点
- 如何在特征提取网络变化之后,对应的存储的旧特征也应该发生变化,本文用多层感知机模拟这种映射。
- 本文方法存储负担对比同类方法极小
- 性能达到SOTA
2.框架
如图所示,模型根据新图片提取出特征,同时需要对旧特征进行适应。因为相应的增量模型发生了变化,旧存储的特征也会发生变化。
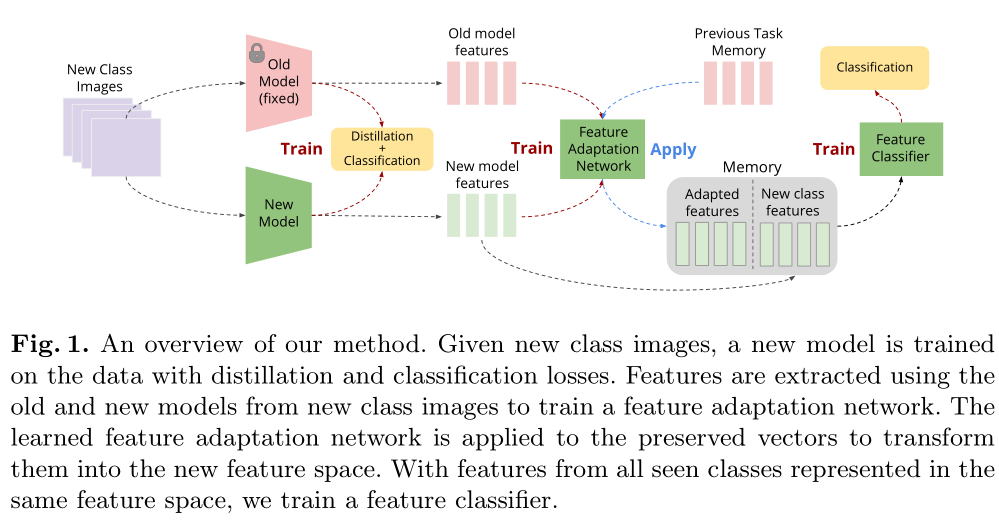
2.1 特征提取+分类器
依然是非常常见的,特征提取模块加上分类器模块。假定特征提取模块是hΘ(), 分类器模块是gW(), 非常常见的结构就是:
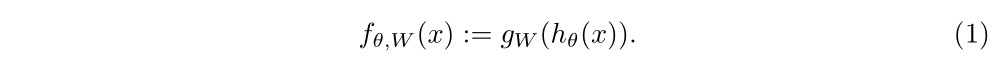
对应的loss,比如交叉熵Loss:

这个模型结构太常见了,特征提取模块加上分类器模块,几乎所有的论文都用了这种模式,并且把这个模式解释了一遍,但是不确定是谁最先提出来的。
2.2 蒸馏Loss
基于输出的Knowledge Distillation以及基于feature的Feature Distillation
利用旧模型的输出蒸馏新模型的输出:
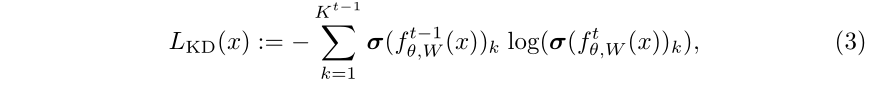
最终模型性能是交叉熵加上蒸馏Loss,例如LwF采用的方法:
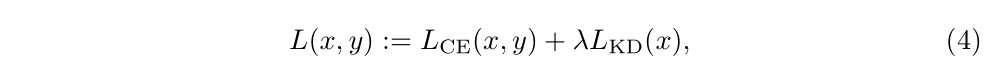
这个是基于分类器输出的蒸馏,也有基于特征的蒸馏:
基于特征的蒸馏多采用cos相似度:
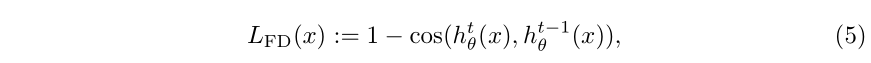
最终的Loss可以将交叉熵Loss、蒸馏Loss、feature的蒸馏Loss相结合:
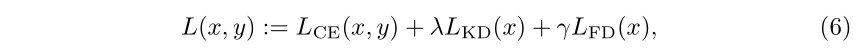
两种蒸馏Loss用于保持旧知识.这里作者提到另一种蒸馏Loss,attention Distillation Loss:
Learning without memorizing. In: CVPR (2019)
2.3 Feature Adaptation
假定第一个任务的数据集X1,提取出的特征为V1:
存储在memory之中的特征是M1=V1
task t=2的时候,提取出的特征是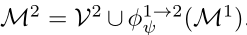
此时,M1和V2是用不同的特征提取模块提取出来的。因为提取V2时候的特征提取模块在提取V1的特征提取模块的基础上进行了更新,因此不是同一个特征提取模块。
因此需要将对应的M1进行转换才能获得M2
同理,第t个任务的特征需要在t-1个任务的基础上进行更新:

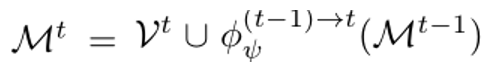
以上几个模块是基于Feature based methods的通用流程。下面作者提出了自己的创新
2.4 feature adaptation network
假定特征适应网络是ф,特征适应网络需要能将上一个task t-1训练的模型映射到下一个task t,

假定t-1任务的特征提取模块提取出的特征是v^hat,t的特征提取模块提取出的特征是v
网络训练的Loss如下:
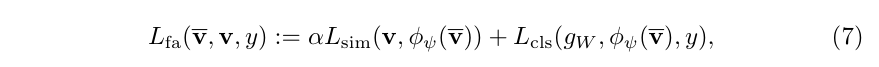
loss分为两个部分,第一个部分是相近loss,需要旧特征v^hat在映射之后尽可能的接近新特征v,这部分用cos相似度来近似。
另一个Loss是分类Loss,用新特征提取模块映射之后的特征在分类网络的输出,需要与任务标签一致。
2.5 Memory尺寸的降低
本文用贪心算法的herding算法选取保留的特征。因为该算法已经比较成型,论文没有详述该算法的理论。该算法也是iCaRL采用的算法。iCaRL: Incremental classifier and representation learning. In: CVPR (2017)
3. 实验
3.1 存储效率
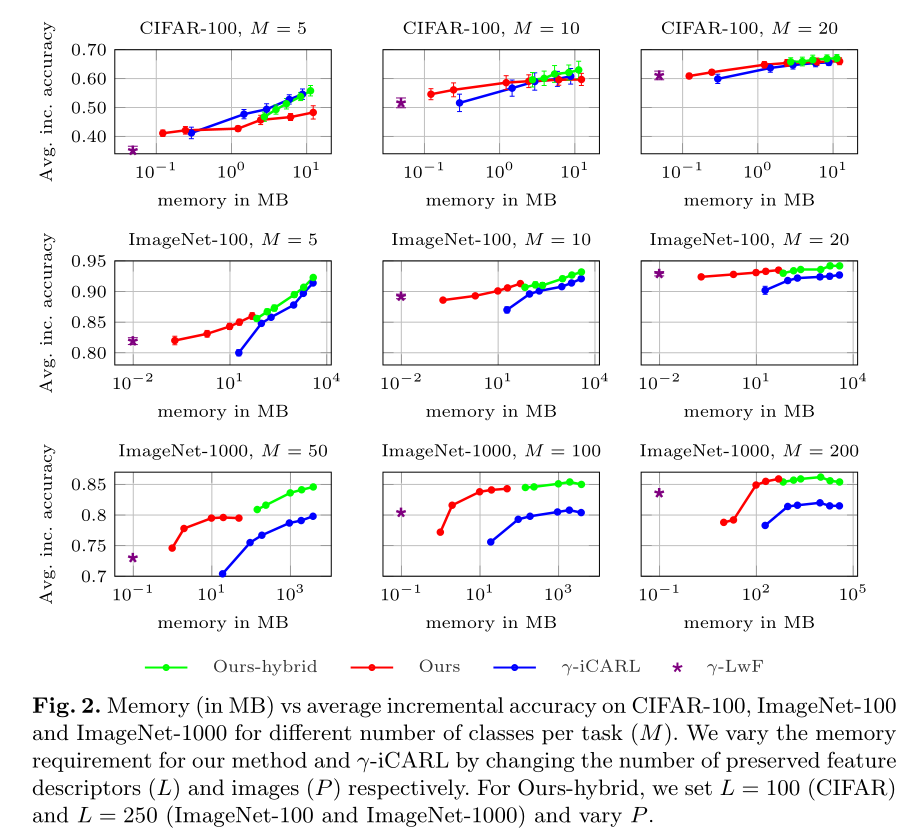
LwF不是基于rehearsal的方法,所以不需要memory size,同时准确率偏低。
iCARL是基于rehearsal的方法,但是因为没有本文的特征适应网络,所以同样的的memory大小之下,本文方法更优。
ours-hybrid不采用herding算法的特征选取,因此memory占用较多。
3.2 准确率
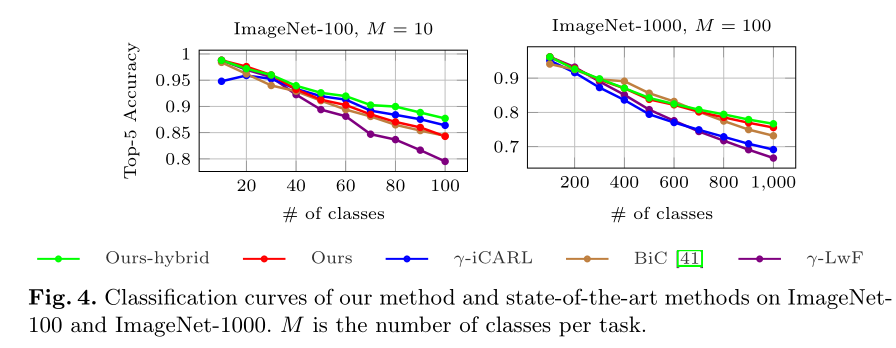
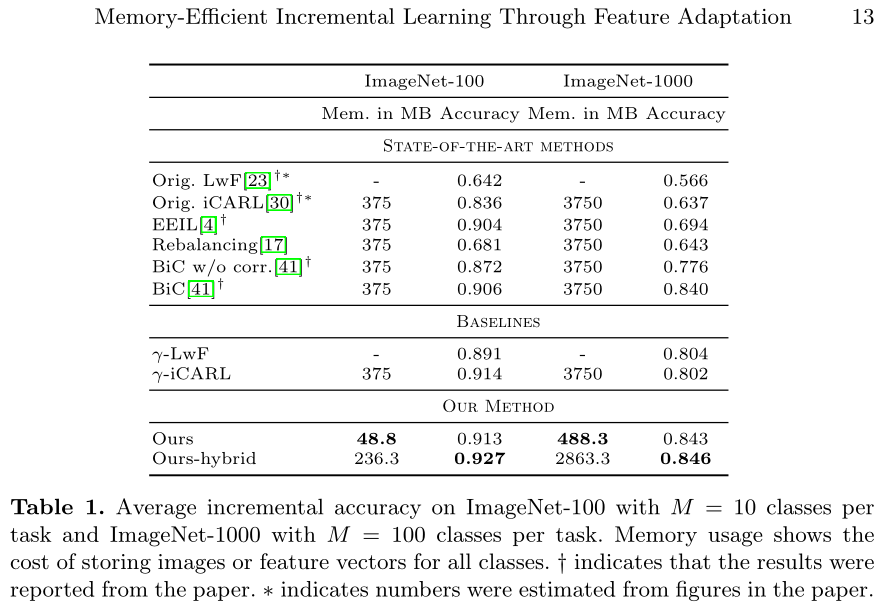
本文与同类型方法对比,达到SOTA
4. 评价
本文思路与SDC比较相近,都是旧任务对新任务的存储特征做映射。
SDC直接按均值的偏移估算特征的偏移。
本文用CNN模型来学习偏移,对旧特征进行映射。
不过,本文可以像SDC那样,给一个实际的偏移量和网络预测的偏移量的差距的实验,更加直观一些。
因为本论文和SDC是同时期论文,因此没有与SDC进行比较,同时,本文需要多训练一个特征迁移网络,并且每个旧任务到新任务都需要训练。具有额外的训练开销和模型开销,但是性能上应该是优于SDC的。




























还没有评论,来说两句吧...