Few Shot Incremental Learning with Continually Evolved Classifiers论文详解 基于持续进化分类器的小样本类别增量学习CVPR2021
Few Shot Incremental Learning with Continually Evolved Classifiers
CVPR2021,由新加坡南洋理工大学
本文利用Graph即图模型,将拓扑结构与增量模型向结合,从而取得不错的效果。
类似论文,均是基于双阶段的增量模型,一个是特征提取模块,另一个是分类器模块。
对于Rehearsal的方法而言,特征提取模块可能一起更新。
对于本文的方法而言,特征提取模块一旦初始训练好,就固定下来,只更新分类器模块。本文的分类器模块与GAT(Graph Attention Network)相结合。
基于拓扑结构的增量学习:
CVPR2020 ,FSCIL Few-shot Class Incremental Learning。将NG网络运用到增量学习之中。
FSCIL论文详解 Few-Shot Class-Incremental Learning, CVPR2020_祥瑞的技术博客-CSDN博客
ECCV2020,TPCIL,本篇,Topology Preserving Class-Incremental learning,同样的框架,即CNN+拓扑结构,部分内容换了一个写法。
基于拓扑的增量学习Topology Preserving Class-Incremental learning论文详解ECCV2020_祥瑞的技术博客-CSDN博客
CVPR2021与本篇非常类似,Few-Shot Incremental Learning with Continually Evolved Classifiers,南洋理工大学提出,也是运用Graph的知识,将GAT(Graph Attention Network)用于增量学习。
Few Shot Incremental Learning with Continually Evolved Classifiers论文详解 基于持续进化分类器的小样本类别增量学习CVPR2021_祥瑞的技术博客-CSDN博客
本文地址:
[2104.03047] Few-Shot Incremental Learning with Continually Evolved Classifiers (arxiv.org)
另一篇论文地址:
[2103.16788] DER: Dynamically Expandable Representation for Class Incremental Learning (arxiv.org)
目录
1.贡献点
- 方法
2.1 模型框架
2.1 CEC(continually evolved classifier)
2.2 算法流程
2.3 Pseudo Incremental Learning
3.实验
3.1 可视化
3.2 方法对比
4.总结
1.贡献点
本文依然解决Few-shot class incremental learning(FSCIL)问题,从两个方面来进行解决:
特征提取模块与分类器解耦,每次增量任务只更新分类器。特征提取模块是pretrain好的backbone, 分类器是non-parameter的class mean classifier(个人猜测类似于NCM)
为了使得分类器适用于所有类别,本文提出Continually Evolved Classifier (CEC),将graph模型应用于分类器。
多个数据集上SOTA
2. 方法
2.1 模型框架
对FSCIL问题,base数据大量,inc数据较少,因此用base数据训练backbone即可。用calssfier来试应增量任务的变化。
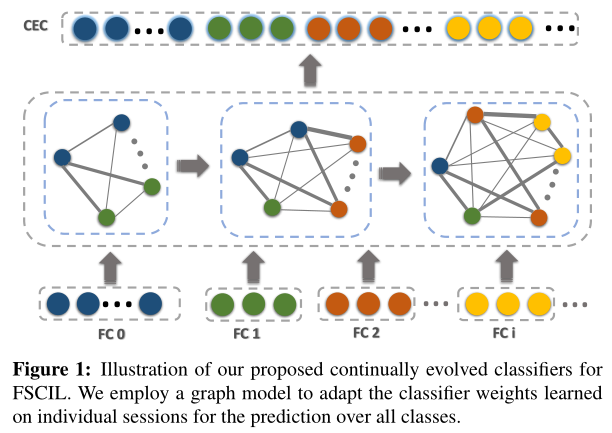
即使对旧任务,学到了很好的分类边界,但是因为新任务的到来,旧模型的决策边界可能不好用了。因此本文引入新的Continually Evolved Classifier (CEC)来进行适应。将Graph Attention Network(GAT,ICML2018)图注意力模型。引入到此模型之中。从而实现了
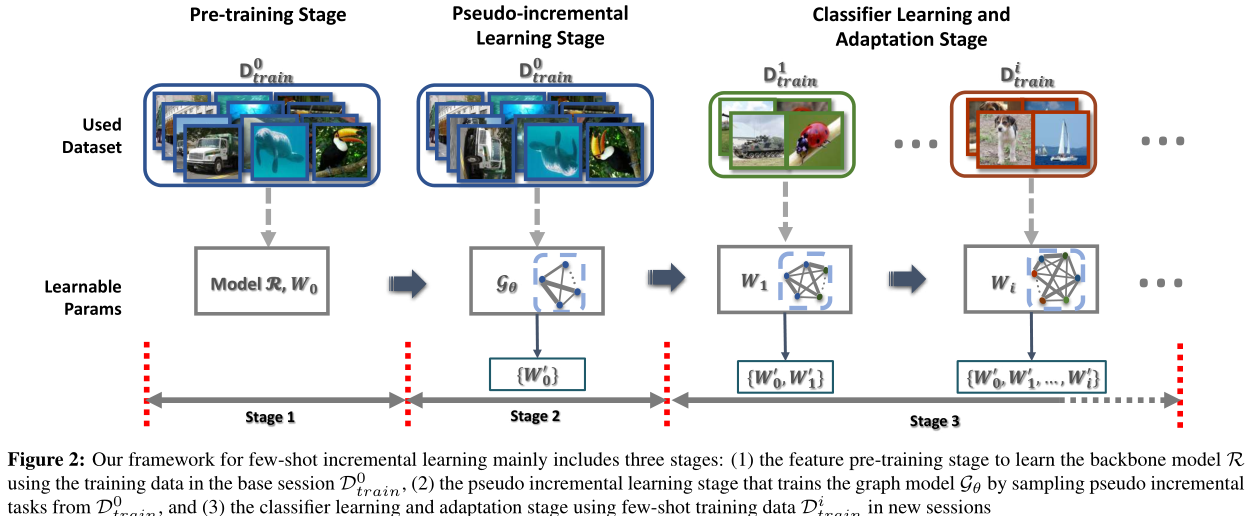
先用base数据D**0train 训练获得backbone R
训练获得backbone R 的权重,
的权重,
然后利用base数据作为伪增量,训练Graph模型获得权重{ W**0},
随着增量任务的到来,Graph模型的节点和权重随之增加,权重增加为{ W0,W1},再增加到{ W0,W1,…,W**i}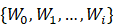
2.1 CEC(continually evolved classifier)
前NI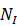 个任务,模型分类器学到的权重为:
个任务,模型分类器学到的权重为:
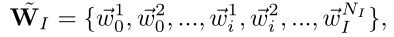
对于CNN模型而言:上标从1到NI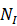 分别表示增量任务,下标从0到NI
分别表示增量任务,下标从0到NI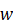 分别表示类别。w**ic
分别表示类别。w**ic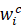 表示第i
表示第i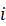 个增量任务中区分类别c的权重。这里采用CNN的模型权重W
个增量任务中区分类别c的权重。这里采用CNN的模型权重W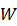 是为了后面与Graph模型进行区分。模型总权重W权重由w即每个增量任务中每个类别的权重构成,意味着每个增量任务从1到NI,每个类别都会有一个权重。
是为了后面与Graph模型进行区分。模型总权重W权重由w即每个增量任务中每个类别的权重构成,意味着每个增量任务从1到NI,每个类别都会有一个权重。
作者把GAT运用于其中。
- GAT的节点是基于注意力机制进行集合,利用拓扑关系,节点间的连接关系具有不变的特性,利于保持旧知识
- GAT模型可以增加节点,且不改变其他的节点,新任务可以利用旧任务训练好的GAT
关于GAT的知识,因为涉及到Graph的知识,因此较为繁琐,作者也适当进行了规避,这里不多做介绍,这里只介绍GAT如何对权重进行处理:
这里只介绍GAT如何对权重进行处理:
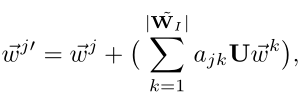
U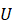 表示线性变换矩阵,wk
表示线性变换矩阵,wk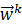 示对所有的k分类的任务,都可以通过线性变换和一个注意力系数的线性相加,更新获得第j
示对所有的k分类的任务,都可以通过线性变换和一个注意力系数的线性相加,更新获得第j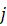 个任务权重wj’
个任务权重wj’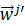 .
.
GAT的作用就是获得线性变换矩阵U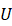 和注意力系数ajk
和注意力系数ajk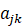 。通过此公式我们可以看出,分类器的权重其实经过了更新,这个更新过程是新权重除了新训练所得的权重之外,分类器旧权重也进行了线性变换和注意力机制的更新。
。通过此公式我们可以看出,分类器的权重其实经过了更新,这个更新过程是新权重除了新训练所得的权重之外,分类器旧权重也进行了线性变换和注意力机制的更新。
2.2 算法流程

输入:
根据基础任务数据D**0train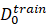 训练所得的backbone模型R
训练所得的backbone模型R ,以及一个随机初始化的GAT模型Gθ
,以及一个随机初始化的GAT模型Gθ
增量任务到来之后,只需要对新增任务训练分类器W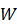 , 然后训练GAT模型,用GAT模型的输出平衡分类器各个类别之间的关系。
, 然后训练GAT模型,用GAT模型的输出平衡分类器各个类别之间的关系。
2.3 Pseudo Incremental Learning
见算法流程中步骤5-8,本文将旋转这个数据增强的手段当作了贡献点之一,起名叫做Pseudo Incremental Learning.(PIL)
作者通过旋转的样本增扩(PIL),然后将样本分为了support set和query set,(类似于训练集和验证集,在Graph神经网络之中,这两个集合的作用可能不太一样),support set用于训练分类器,训练好的分类器用query set训练GAT网络。
关于PIL这个流程的作用,效果巨大,通过后续实验可见图6,可能与GAT的某些特性有关:
加入了PIL之后,网络准确率提升巨大。
3.实验
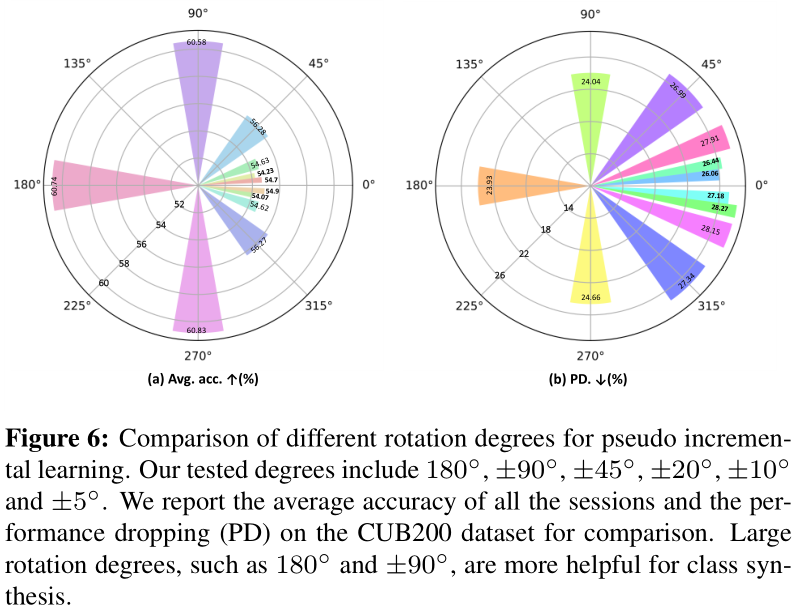
3.1 可视化
通过t-SNE可视化,新类的学习过程,特征空间上的点分的更开。
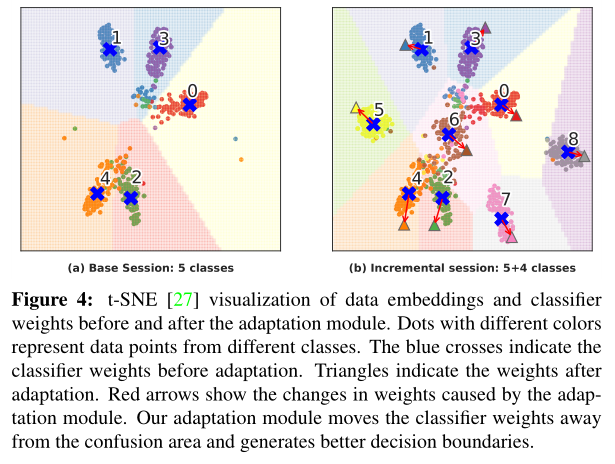
3.2 方法对比
性能达到SOTA
4.总结
A+B, A是小样本增量学习FSCIL,B是图注意力网络GAT,本文将两个结合起来凑贡献点。
中间加入了一些trick提升准确率,以使得模型达到SOTA,例如旋转的样本增扩,起名为Pseudo Incremental Learning。

























")




 AutowiredAnnotationBeanPostProcessor")



还没有评论,来说两句吧...