学术不端擦边球 Incremental Few-Shot Object Detection,CVPR 2020 小样本增量目标检测 论文详解
三星AI研究所发表在CVPR2020上的文章。解决小样本增量目标检测问题。
不过读完发现此文完全抄袭 ICCV 2019的这篇:基于检测任务的小样本增量学习 Few-shot Object Detection via Feature Reweighting. ICCV 2019论文详解
ICCV2019比此文早了一年半左右即挂了Arxiv,此文仅仅将上篇文章的YOLOv2换为了CentreNet,换了数据集,其他几乎没有变化,抄的如此简单赤裸。
目录
1.贡献点
2.结构框架
2.1 特征提取
2.2 类别生成器
3.实验
1.贡献点
定义了iFSD(incremental Few-Shot Detection),小样本增量目标检测问题。(这个小样本增量学习被提出过)
本文提出了ONCE(OpeN-ended Centre nEt)框架,用于解决iFSD问题。模型由两部分优化构成:CentreNet目标检测器,和基于类别的编码生成模型,这个生成模型不是GAN中的生成器,而是一个生成卷积核的生成器,用于生成卷积核与CentreNet中的feature-map进行卷积进行特征提取。这个编码生成器也是抄了Few-shot Object Detection via Feature Reweighting. ICCV 2019 的方法,换了个名字。
2.结构框架
本文选用CentreNet作为本文的检测模型,因为它具有以下优点:
高效的单阶段目标检测模型,能够在效率和准确率之间达到较好的平衡。优于SSD、RetinaNet、YOLO
运用基于类别的模型范式,可以通过plug-in manner解决增量中的新增类。(近似可以理解为,随着增量类别的增多,最后的目标检测层的结构可以随之增加)
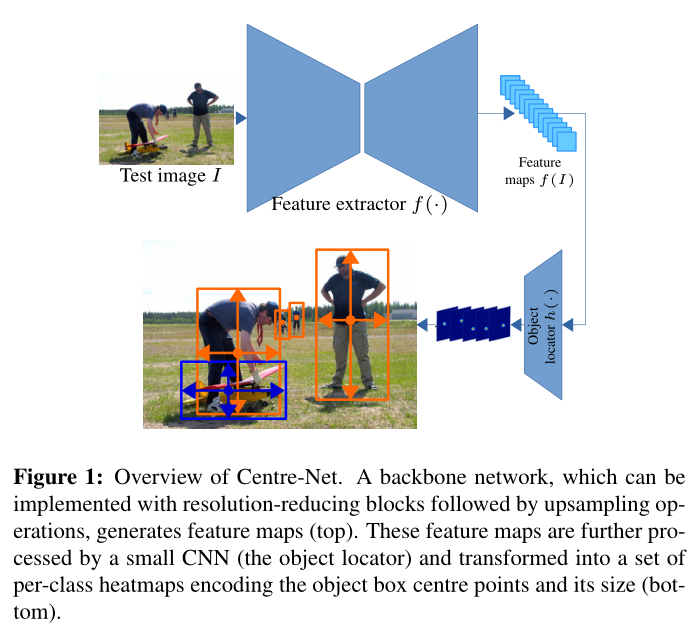
模型分为两个阶段,一个是特征提取阶段,用于提取特征,另一个是目标检测阶段,用小型的CNN预测目标检测结果。(注意,目标检测中的单阶段与这里的两个阶段的定义并不相同。目标检测任务中的双阶段相当于两个模型,一个模型用于给出备选框,另一个用于给备选框进行选择。目标检测中的单阶段是模型直接根据feature-map生成备选框,所以虽然CentreNet具有两个阶段,但是在目标检测阶段的定义中,依然是目标检测单阶段的目标检测模型。)
本文的ONCE模型,具有两个部分构成:
- 特征提取模块(Feature Extractor),用于提取图片特征,这个模块被原始任务和增量任务共享。
- 目标检测模块(Object Locator),根据提取出的特征进行分类,这个模块根据任务的特征进行预测。
2.1 特征提取
本文的ONCE框架主要依据CentreNet,分为两个阶段。首先训练特征提取模块f(),目标检测模块h()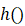 ,给定输入图片I∈**Rh\w*3,经过特征提取模块之后获得feature-map,m=f(I)
,给定输入图片I∈**Rh\w*3,经过特征提取模块之后获得feature-map,m=f(I)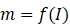 ,I∈Rhr*wr*c
,I∈Rhr*wr*c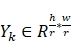 ,其尺寸是hr*wr*c,分别是宽、高和通道数。对应的目标检测模块h()
,其尺寸是hr*wr*c,分别是宽、高和通道数。对应的目标检测模块h()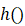 需要训练出一个卷积核ck=*R1\1*c*用于获得类别heatmap:
需要训练出一个卷积核ck=*R1\1*c*用于获得类别heatmap:
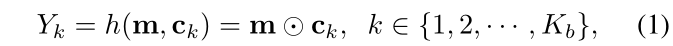
其中,下标k表示类别数量,一共有Kb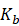 类。Yk
类。Yk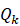 的尺寸是Yk∈Rhr**wr,即相当于对feature-map上的每个像素点预测出一个针对类别k
的尺寸是Yk∈Rhr**wr,即相当于对feature-map上的每个像素点预测出一个针对类别k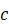 的概率。同理,目标检测阶段的模型h()还需要获得预测框中心点输出O∈Rhr*wr*2
的概率。同理,目标检测阶段的模型h()还需要获得预测框中心点输出O∈Rhr*wr*2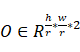 和尺寸输出S∈Rhr*wr*2
和尺寸输出S∈Rhr*wr*2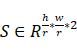 。这些输出均是基于特征提取模块的结果m=f(I)*
。这些输出均是基于特征提取模块的结果m=f(I)*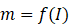 获得。这点与YOLO非常相近。
获得。这点与YOLO非常相近。
2.2 类别生成器
这个类别生成器不是GAN中的生成器,类别生成器g()用于生成类别向量c(即上文公式(1)中用于与feature-map进行卷积,获得该类别heatmap的向量)。关于类别生成器本文运用meta-learning的方法,将对应的任务分为support set Q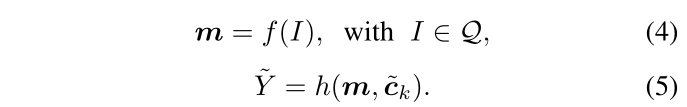 和query-set S,对于第k类的类别生成器的训练方法:
和query-set S,对于第k类的类别生成器的训练方法:
本文根据S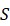 中的k
中的k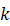 类Sk
类Sk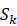 获得生成类别向量ck,
获得生成类别向量ck,
然后在Q上的第k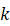 类进行验证,最小化Qk在模型输出的误差。
类进行验证,最小化Qk在模型输出的误差。
这里我们可以发现,这里引入了元学习的概念,即YOLO用于类别预测的卷积核c是直接通过模型训练获得的,这里的用于预测类别预测的卷积核c是通过类别生成器g()通过元学习的方法生成的。
新类到来时的训练流程:
新类到来后,划分为support set Q和query-set S,通过元学习的方法,根据公式(3)(4),训练好类别生成器g(),然后利用g()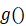 生成的类别向量对模型进行预测,从而适应了增量训练的过程。
生成的类别向量对模型进行预测,从而适应了增量训练的过程。
3.实验
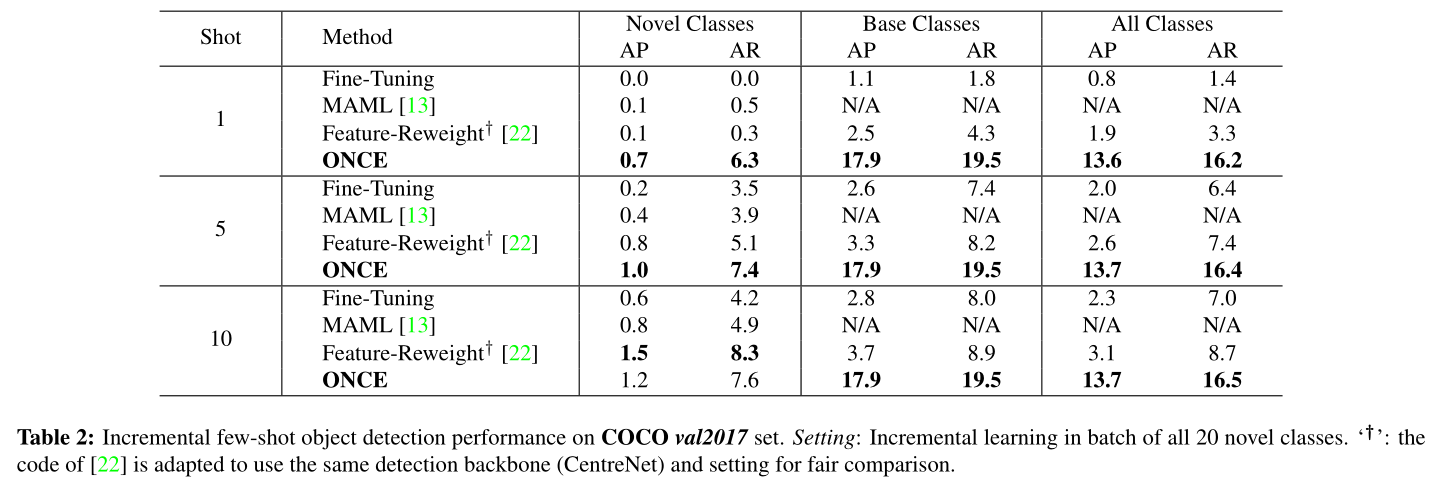
可以看出,尽管ONCE取得了SOTA的实验效果,但是在COCO数据集上的性能依然非常低。究其原因,可能有三点,
- COCO数据集本身较难,
- 增量学习在检测任务中具有一定的挑战性。
- Few-shot的增量学习具有一定的难度。
但是本文运用元学习的方法,将单阶段的目标检测模型与双阶段的增量任务相结合。方法几乎完全抄袭了2019年的论文,仅仅将其中的YOLOv2换为CentreNet,




























还没有评论,来说两句吧...