睿智的目标检测33——Keras搭建Efficientdet目标检测平台
睿智的目标检测33——Keras搭建Efficientdet目标检测平台
- 学习前言
- 什么是Efficientdet目标检测算法
- 源码下载
- Efficientdet实现思路
- 一、预测部分
- 1、主干网络介绍
- 2、BiFPN加强特征提取
- 3、从特征获取预测结果
- 4、预测结果的解码
- 5、在原图上进行绘制
- 二、训练部分
- 1、真实框的处理
- 2、利用处理完的真实框与对应图片的预测结果计算loss
- a、控制正负样本的权重
- b、控制容易分类和难分类样本的权重
- c、两种权重控制方法合并
- 训练自己的Efficientdet模型
- 一、数据集的准备
- 二、数据集的处理
- 三、开始网络训练
- 四、训练结果预测
学习前言
一起来看看Efficientdet的keras实现吧,顺便训练一下自己的数据。
什么是Efficientdet目标检测算法
最近,谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果。
源码下载
https://github.com/bubbliiiing/efficientdet-keras
喜欢的可以点个star噢。
Efficientdet实现思路
一、预测部分
1、主干网络介绍

Efficientdet采用Efficientnet作为主干特征提取网络。EfficientNet-B0对应Efficientdet-D0;EfficientNet-B1对应Efficientdet-D1;以此类推。
EfficientNet模型具有很独特的特点,这个特点是参考其它优秀神经网络设计出来的。经典的神经网络特点如下:
1、利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取。
2、改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征,提升宽度。
3、通过增大输入图片的分辨率也可以使得网络可以学习与表达的东西更加丰富,有利于提高精确度。
EfficientNet就是将这三个特点结合起来,通过一起缩放baseline模型(MobileNet中就通过缩放α实现缩放模型,不同的α有不同的模型精度,α=1时为baseline模型;ResNet其实也是有一个baseline模型,在baseline的基础上通过改变图片的深度实现不同的模型实现),同时调整深度、宽度、输入图片的分辨率完成一个优秀的网络设计。
在EfficientNet模型中,其使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
假设想使用 2N倍的计算资源,我们可以简单的对网络深度扩大αN倍、宽度扩大βN 、图像尺寸扩大γN倍,这里的α,β,γ都是由原来的小模型上做微小的网格搜索决定的常量系数。
如图为EfficientNet的设计思路,从三个方面同时拓充网络的特性。
本博客以Efficientnet-B0和Efficientdet-D0为例,进行Efficientdet的解析。
Efficientnet-B0由1个Stem+16个大Blocks堆叠构成,16个大Blocks可以分为1、2、2、3、3、4、1个Block。Block的通用结构如下,其总体的设计思路是Inverted residuals结构和残差结构,在3x3或者5x5网络结构前利用1x1卷积升维,在3x3或者5x5网络结构后增加了一个关于通道的注意力机制,最后利用1x1卷积降维后增加一个大残差边。
整体结构如下:
最终获得三个有效特征层传入到BIFPN当中进行下一步的操作。
import collectionsimport mathimport stringfrom keras import backend, layersMOMENTUM = 0.99EPSILON = 1e-3#-------------------------------------------------## 一共七个大结构块,每个大结构块都有特定的参数#-------------------------------------------------#BlockArgs = collections.namedtuple('BlockArgs', ['kernel_size', 'num_repeat', 'input_filters', 'output_filters','expand_ratio', 'id_skip', 'strides', 'se_ratio'])BlockArgs.__new__.__defaults__ = (None,) * len(BlockArgs._fields)DEFAULT_BLOCKS_ARGS = [BlockArgs(kernel_size=3, num_repeat=1, input_filters=32, output_filters=16,expand_ratio=1, id_skip=True, strides=[1, 1], se_ratio=0.25),BlockArgs(kernel_size=3, num_repeat=2, input_filters=16, output_filters=24,expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),BlockArgs(kernel_size=5, num_repeat=2, input_filters=24, output_filters=40,expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),BlockArgs(kernel_size=3, num_repeat=3, input_filters=40, output_filters=80,expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),BlockArgs(kernel_size=5, num_repeat=3, input_filters=80, output_filters=112,expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25),BlockArgs(kernel_size=5, num_repeat=4, input_filters=112, output_filters=192,expand_ratio=6, id_skip=True, strides=[2, 2], se_ratio=0.25),BlockArgs(kernel_size=3, num_repeat=1, input_filters=192, output_filters=320,expand_ratio=6, id_skip=True, strides=[1, 1], se_ratio=0.25)]#-------------------------------------------------## Kernel的初始化器#-------------------------------------------------#CONV_KERNEL_INITIALIZER = {'class_name': 'VarianceScaling','config': {'scale': 2.0,'mode': 'fan_out','distribution': 'normal'}}#-------------------------------------------------## Swish激活函数#-------------------------------------------------#def get_swish():def swish(x):return x * backend.sigmoid(x)return swish#-------------------------------------------------## Dropout层#-------------------------------------------------#def get_dropout():class FixedDropout(layers.Dropout):def _get_noise_shape(self, inputs):if self.noise_shape is None:return self.noise_shapesymbolic_shape = backend.shape(inputs)noise_shape = [symbolic_shape[axis] if shape is None else shapefor axis, shape in enumerate(self.noise_shape)]return tuple(noise_shape)return FixedDropout#-------------------------------------------------## 该函数的目的是保证filter的大小可以被8整除#-------------------------------------------------#def round_filters(filters, width_coefficient, depth_divisor):filters *= width_coefficientnew_filters = int(filters + depth_divisor / 2) // depth_divisor * depth_divisornew_filters = max(depth_divisor, new_filters)if new_filters < 0.9 * filters:new_filters += depth_divisorreturn int(new_filters)#-------------------------------------------------## 计算模块的重复次数#-------------------------------------------------#def round_repeats(repeats, depth_coefficient):return int(math.ceil(depth_coefficient * repeats))def mb_conv_block(inputs, block_args, activation, drop_rate=None, prefix=''):Dropout = get_dropout()#-------------------------------------------------## 利用Inverted residuals# part1 利用1x1卷积进行通道数上升#-------------------------------------------------#filters = block_args.input_filters * block_args.expand_ratioif block_args.expand_ratio != 1:x = layers.Conv2D(filters, 1,padding='same',use_bias=False,kernel_initializer=CONV_KERNEL_INITIALIZER,name=prefix + 'expand_conv')(inputs)x = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=prefix + 'expand_bn')(x)x = layers.Activation(activation, name=prefix + 'expand_activation')(x)else:x = inputs#------------------------------------------------------## 如果步长为2x2的话,利用深度可分离卷积进行高宽压缩# part2 利用3x3卷积对每一个channel进行卷积#------------------------------------------------------#x = layers.DepthwiseConv2D(block_args.kernel_size,strides=block_args.strides,padding='same',use_bias=False,depthwise_initializer=CONV_KERNEL_INITIALIZER,name=prefix + 'dwconv')(x)x = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=prefix + 'bn')(x)x = layers.Activation(activation, name=prefix + 'activation')(x)#------------------------------------------------------## 完成深度可分离卷积后# 对深度可分离卷积的结果施加注意力机制#------------------------------------------------------#if 0 < block_args.se_ratio <= 1:num_reduced_filters = max(1, int(block_args.input_filters * block_args.se_ratio))se_tensor = layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x)se_tensor = layers.Reshape((1, 1, filters), name=prefix + 'se_reshape')(se_tensor)#------------------------------------------------------## 通道先压缩后上升,最后利用sigmoid将值固定到0-1之间#------------------------------------------------------#se_tensor = layers.Conv2D(num_reduced_filters, 1,activation=activation,padding='same',use_bias=True,kernel_initializer=CONV_KERNEL_INITIALIZER,name=prefix + 'se_reduce')(se_tensor)se_tensor = layers.Conv2D(filters, 1,activation='sigmoid',padding='same',use_bias=True,kernel_initializer=CONV_KERNEL_INITIALIZER,name=prefix + 'se_expand')(se_tensor)x = layers.multiply([x, se_tensor], name=prefix + 'se_excite')#------------------------------------------------------## part3 利用1x1卷积进行通道下降#------------------------------------------------------#x = layers.Conv2D(block_args.output_filters, 1,padding='same',use_bias=False,kernel_initializer=CONV_KERNEL_INITIALIZER,name=prefix + 'project_conv')(x)x = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=prefix + 'project_bn')(x)#------------------------------------------------------## part4 如果满足残差条件,那么就增加残差边#------------------------------------------------------#if block_args.id_skip and all(s == 1 for s in block_args.strides) and block_args.input_filters == block_args.output_filters:if drop_rate and (drop_rate > 0):x = Dropout(drop_rate,noise_shape=(None, 1, 1, 1),name=prefix + 'drop')(x)x = layers.add([x, inputs], name=prefix + 'add')return xdef EfficientNet(width_coefficient,depth_coefficient,drop_connect_rate=0.2,depth_divisor=8,blocks_args=DEFAULT_BLOCKS_ARGS,inputs=None,**kwargs):activation = get_swish(**kwargs)img_input = inputs#-------------------------------------------------## 创建stem部分#-------------------------------------------------#x = img_inputx = layers.Conv2D(round_filters(32, width_coefficient, depth_divisor), 3,strides=(2, 2),padding='same',use_bias=False,kernel_initializer=CONV_KERNEL_INITIALIZER,name='stem_conv')(x)x = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name='stem_bn')(x)x = layers.Activation(activation, name='stem_activation')(x)features = []#-------------------------------------------------## 计算总的efficient_block的数量#-------------------------------------------------#block_num = 0num_blocks_total = sum(block_args.num_repeat for block_args in blocks_args)#------------------------------------------------------------------------------## 对结构块参数进行循环、一共进行7个大的结构块。# 每个大结构块下会重复小的efficient_block#------------------------------------------------------------------------------#for idx, block_args in enumerate(blocks_args):assert block_args.num_repeat > 0#-------------------------------------------------## 对使用到的参数进行更新#-------------------------------------------------#block_args = block_args._replace(input_filters = round_filters(block_args.input_filters, width_coefficient, depth_divisor),output_filters = round_filters(block_args.output_filters, width_coefficient, depth_divisor),num_repeat = round_repeats(block_args.num_repeat, depth_coefficient))# 计算drop_ratedrop_rate = drop_connect_rate * float(block_num) / num_blocks_totalx = mb_conv_block(x, block_args,activation=activation,drop_rate=drop_rate,prefix='block{}a_'.format(idx + 1))block_num += 1if block_args.num_repeat > 1:#-------------------------------------------------## 对使用到的参数进行更新#-------------------------------------------------#block_args = block_args._replace(input_filters=block_args.output_filters, strides=[1, 1])for bidx in range(block_args.num_repeat - 1):# 计算drop_ratedrop_rate = drop_connect_rate * float(block_num) / num_blocks_totalx = mb_conv_block(x, block_args,activation = activation,drop_rate = drop_rate,prefix = 'block{}{}_'.format(idx + 1, string.ascii_lowercase[bidx + 1]))block_num += 1if idx < len(blocks_args) - 1 and blocks_args[idx + 1].strides[0] == 2:features.append(x)elif idx == len(blocks_args) - 1:features.append(x)return featuresdef EfficientNetB0(inputs=None, **kwargs):return EfficientNet(1.0, 1.0, inputs=inputs, **kwargs)def EfficientNetB1(inputs=None, **kwargs):return EfficientNet(1.0, 1.1, inputs=inputs, **kwargs)def EfficientNetB2(inputs=None, **kwargs):return EfficientNet(1.1, 1.2, inputs=inputs, **kwargs)def EfficientNetB3(inputs=None, **kwargs):return EfficientNet(1.2, 1.4, inputs=inputs, **kwargs)def EfficientNetB4(inputs=None, **kwargs):return EfficientNet(1.4, 1.8, inputs=inputs, **kwargs)def EfficientNetB5(inputs=None, **kwargs):return EfficientNet(1.6, 2.2, inputs=inputs, **kwargs)def EfficientNetB6(inputs=None, **kwargs):return EfficientNet(1.8, 2.6, inputs=inputs, **kwargs)def EfficientNetB7(inputs=None, **kwargs):return EfficientNet(2.0, 3.1, inputs=inputs, **kwargs)
2、BiFPN加强特征提取
BiFPN简单来讲是一个加强版本的FPN,上图是BiFPN,下图是普通的FPN,大家可以看到,与普通的FPN相比,BiFPN的FPN构建更加复杂,中间还增加了许多连接。
构建BiFPN可以分为多步:
1、获得P3_in、P4_in、P5_in、P6_in、P7_in,通过主干特征提取网络,我们已经可以获得P3、P4、P5,还需要进行两次下采样获得P6、P7。
P3、P4、P5在经过1x1卷积调整通道数后,就可以作为P3_in、P4_in、P5_in了,在构建BiFPN的第一步,需要构建两个P4_in、P5_in(原版是这样设计的)。
实现代码如下:
_, _, C3, C4, C5 = features# 第一次BIFPN需要 下采样 与 降通道 获得 p3_in p4_in p5_in p6_in p7_in#-----------------------------下采样 与 降通道----------------------------#P3_in = C3P3_in = layers.Conv2D(num_channels, kernel_size=1, padding='same',name=f'fpn_cells/cell_{id}/fnode3/resample_0_0_8/conv2d')(P3_in)P3_in = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,name=f'fpn_cells/cell_{id}/fnode3/resample_0_0_8/bn')(P3_in)P4_in = C4P4_in_1 = layers.Conv2D(num_channels, kernel_size=1, padding='same',name=f'fpn_cells/cell_{id}/fnode2/resample_0_1_7/conv2d')(P4_in)P4_in_1 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,name=f'fpn_cells/cell_{id}/fnode2/resample_0_1_7/bn')(P4_in_1)P4_in_2 = layers.Conv2D(num_channels, kernel_size=1, padding='same',name=f'fpn_cells/cell_{id}/fnode4/resample_0_1_9/conv2d')(P4_in)P4_in_2 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,name=f'fpn_cells/cell_{id}/fnode4/resample_0_1_9/bn')(P4_in_2)P5_in = C5P5_in_1 = layers.Conv2D(num_channels, kernel_size=1, padding='same',name=f'fpn_cells/cell_{id}/fnode1/resample_0_2_6/conv2d')(P5_in)P5_in_1 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,name=f'fpn_cells/cell_{id}/fnode1/resample_0_2_6/bn')(P5_in_1)P5_in_2 = layers.Conv2D(num_channels, kernel_size=1, padding='same',name=f'fpn_cells/cell_{id}/fnode5/resample_0_2_10/conv2d')(P5_in)P5_in_2 = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON,name=f'fpn_cells/cell_{id}/fnode5/resample_0_2_10/bn')(P5_in_2)P6_in = layers.Conv2D(num_channels, kernel_size=1, padding='same', name='resample_p6/conv2d')(C5)P6_in = layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name='resample_p6/bn')(P6_in)P6_in = layers.MaxPooling2D(pool_size=3, strides=2, padding='same', name='resample_p6/maxpool')(P6_in)P7_in = layers.MaxPooling2D(pool_size=3, strides=2, padding='same', name='resample_p7/maxpool')(P6_in)#-------------------------------------------------------------------------#
2、在获得P3_in、P4_in_1、P4_in_2、P5_in_1、P5_in_2、P6_in、P7_in之后需要对P7_in进行上采样,上采样后与P6_in堆叠获得P6_td;之后对P6_td进行上采样,上采样后与P5_in_1进行堆叠获得P5_td;之后对P5_td进行上采样,上采样后与P4_in_1进行堆叠获得P4_td;之后对P4_td进行上采样,上采样后与P3_in进行堆叠获得P3_out。
实现代码如下:
#--------------------------构建BIFPN的上下采样循环-------------------------#P7_U = layers.UpSampling2D()(P7_in)P6_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode0/add')([P6_in, P7_U])P6_td = layers.Activation(lambda x: tf.nn.swish(x))(P6_td)P6_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode0/op_after_combine5')(P6_td)P6_U = layers.UpSampling2D()(P6_td)P5_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode1/add')([P5_in_1, P6_U])P5_td = layers.Activation(lambda x: tf.nn.swish(x))(P5_td)P5_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode1/op_after_combine6')(P5_td)P5_U = layers.UpSampling2D()(P5_td)P4_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode2/add')([P4_in_1, P5_U])P4_td = layers.Activation(lambda x: tf.nn.swish(x))(P4_td)P4_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode2/op_after_combine7')(P4_td)P4_U = layers.UpSampling2D()(P4_td)P3_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode3/add')([P3_in, P4_U])P3_out = layers.Activation(lambda x: tf.nn.swish(x))(P3_out)P3_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode3/op_after_combine8')(P3_out)#-------------------------------------------------------------------------#
3、在获得P3_out、P4_td、P4_in_2、P5_td、P5_in_2、P6_in、P6_td、P7_in之后,之后需要对P3_out进行下采样,下采样后与P4_td、P4_in_2堆叠获得P4_out;之后对P4_out进行下采样,下采样后与P5_td、P5_in_2进行堆叠获得P5_out;之后对P5_out进行下采样,下采样后与P6_in、P6_td进行堆叠获得P6_out;之后对P6_out进行下采样,下采样后与P7_in进行堆叠获得P7_out。
实现代码如下:
#--------------------------构建BIFPN的上下采样循环-------------------------#P3_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P3_out)P4_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode4/add')([P4_in_2, P4_td, P3_D])P4_out = layers.Activation(lambda x: tf.nn.swish(x))(P4_out)P4_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode4/op_after_combine9')(P4_out)P4_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P4_out)P5_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode5/add')([P5_in_2, P5_td, P4_D])P5_out = layers.Activation(lambda x: tf.nn.swish(x))(P5_out)P5_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode5/op_after_combine10')(P5_out)P5_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P5_out)P6_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode6/add')([P6_in, P6_td, P5_D])P6_out = layers.Activation(lambda x: tf.nn.swish(x))(P6_out)P6_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode6/op_after_combine11')(P6_out)P6_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P6_out)P7_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode7/add')([P7_in, P6_D])P7_out = layers.Activation(lambda x: tf.nn.swish(x))(P7_out)P7_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode7/op_after_combine12')(P7_out)#-------------------------------------------------------------------------#
4、将获得的P3_out、P4_out、P5_out、P6_out、P7_out作为P3_in、P4_in、P5_in、P6_in、P7_in,重复2、3步骤进行堆叠即可,对于Effiicientdet B0来讲,还需要重复2次,需要注意P4_in_1和P4_in_2此时不需要分开了,P5也是。
实现代码如下:
P3_in, P4_in, P5_in, P6_in, P7_in = featuresP7_U = layers.UpSampling2D()(P7_in)P6_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode0/add')([P6_in, P7_U])P6_td = layers.Activation(lambda x: tf.nn.swish(x))(P6_td)P6_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode0/op_after_combine5')(P6_td)P6_U = layers.UpSampling2D()(P6_td)P5_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode1/add')([P5_in, P6_U])P5_td = layers.Activation(lambda x: tf.nn.swish(x))(P5_td)P5_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode1/op_after_combine6')(P5_td)P5_U = layers.UpSampling2D()(P5_td)P4_td = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode2/add')([P4_in, P5_U])P4_td = layers.Activation(lambda x: tf.nn.swish(x))(P4_td)P4_td = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode2/op_after_combine7')(P4_td)P4_U = layers.UpSampling2D()(P4_td)P3_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode3/add')([P3_in, P4_U])P3_out = layers.Activation(lambda x: tf.nn.swish(x))(P3_out)P3_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode3/op_after_combine8')(P3_out)P3_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P3_out)P4_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode4/add')([P4_in, P4_td, P3_D])P4_out = layers.Activation(lambda x: tf.nn.swish(x))(P4_out)P4_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode4/op_after_combine9')(P4_out)P4_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P4_out)P5_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode5/add')([P5_in, P5_td, P4_D])P5_out = layers.Activation(lambda x: tf.nn.swish(x))(P5_out)P5_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode5/op_after_combine10')(P5_out)P5_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P5_out)P6_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode6/add')([P6_in, P6_td, P5_D])P6_out = layers.Activation(lambda x: tf.nn.swish(x))(P6_out)P6_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode6/op_after_combine11')(P6_out)P6_D = layers.MaxPooling2D(pool_size=3, strides=2, padding='same')(P6_out)P7_out = wBiFPNAdd(name=f'fpn_cells/cell_{id}/fnode7/add')([P7_in, P6_D])P7_out = layers.Activation(lambda x: tf.nn.swish(x))(P7_out)P7_out = SeparableConvBlock(num_channels=num_channels, kernel_size=3, strides=1,name=f'fpn_cells/cell_{id}/fnode7/op_after_combine12')(P7_out)
3、从特征获取预测结果
通过第二部的重复运算,我们获得了P3_out, P4_out, P5_out, P6_out, P7_out。
为了和普通特征层区分,我们称之为有效特征层,将这五个有效的特征层传输过ClassNet+BoxNet就可以获得预测结果了。
对于Efficientdet-B0来讲:
ClassNet采用3次64通道的卷积和1次num_anchors x num_classes的卷积,num_anchors指的是该特征层所拥有的先验框数量,num_classes指的是网络一共对多少类的目标进行检测。
BoxNet采用3次64通道的卷积和1次num_anchors x 4的卷积,num_anchors指的是该特征层所拥有的先验框数量,4指的是先验框的调整情况。
需要注意的是,每个特征层所用的ClassNet是同一个ClassNet;每个特征层所用的BoxNet是同一个BoxNet。
其中:
num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。**
num_anchors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
实现代码为:
#------------------------------------------## 获得回归预测结果# 该部分会对先验框进行调整获得预测框#------------------------------------------#class BoxNet:def __init__(self, width, depth, num_anchors=9, name='box_net', **kwargs):self.name = nameself.width = widthself.depth = depthself.num_anchors = num_anchorsoptions = {'kernel_size': 3,'strides': 1,'padding': 'same','bias_initializer': 'zeros','depthwise_initializer': initializers.RandomNormal(stddev=0.01),'pointwise_initializer': initializers.RandomNormal(stddev=0.01),}self.convs = [layers.SeparableConv2D(filters=width, name=f'{self.name}/box-{i}', **options) for i in range(depth)]self.head = layers.SeparableConv2D(filters=num_anchors * 4, name=f'{self.name}/box-predict', **options)self.bns = [[layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=f'{self.name}/box-{i}-bn-{j}') for j inrange(3, 8)] for i in range(depth)]self.relu = layers.Lambda(lambda x: tf.nn.swish(x))self.reshape = layers.Reshape((-1, 4))def call(self, inputs):feature, level = inputsfor i in range(self.depth):feature = self.convs[i](feature)feature = self.bns[i][level](feature)feature = self.relu(feature)outputs = self.head(feature)outputs = self.reshape(outputs)return outputs#------------------------------------------## 获得分类预测结果# 该部分会判断先验框对应的物体种类#------------------------------------------#class ClassNet:def __init__(self, width, depth, num_classes=20, num_anchors=9, name='class_net', **kwargs):self.name = nameself.width = widthself.depth = depthself.num_classes = num_classesself.num_anchors = num_anchorsoptions = {'kernel_size': 3,'strides': 1,'padding': 'same','depthwise_initializer': initializers.RandomNormal(stddev=0.01),'pointwise_initializer': initializers.RandomNormal(stddev=0.01),}self.convs = [layers.SeparableConv2D(filters=width, bias_initializer='zeros', name=f'{self.name}/class-{i}', **options) for i in range(depth)]self.head = layers.SeparableConv2D(filters=num_classes * num_anchors, bias_initializer=AnchorProbability(probability=0.01), name=f'{self.name}/class-predict', **options)self.bns = [[layers.BatchNormalization(momentum=MOMENTUM, epsilon=EPSILON, name=f'{self.name}/class-{i}-bn-{j}') for jin range(3, 8)] for i in range(depth)]self.relu = layers.Lambda(lambda x: tf.nn.swish(x))self.reshape = layers.Reshape((-1, num_classes))self.activation = layers.Activation('sigmoid')def call(self, inputs):feature, level = inputsfor i in range(self.depth):feature = self.convs[i](feature)feature = self.bns[i][level](feature)feature = self.relu(feature)outputs = self.head(feature)outputs = self.reshape(outputs)outputs = self.activation(outputs)return outputs
4、预测结果的解码
我们通过对每一个特征层的处理,可以获得三个内容,分别是:
num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。**
num_anchors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。
每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的9个框。
我们利用 num_anchors x 4的卷积 与 每一个有效特征层对应的先验框 获得框的真实位置。
每一个有效特征层对应的先验框就是,如图所示的作用:
每一个有效特征层将整个图片分成与其长宽对应的网格,如P3的特征层就是将整个图像分成64x64个网格;然后从每个网格中心建立9个先验框,一共64x64x9个,36864个先验框。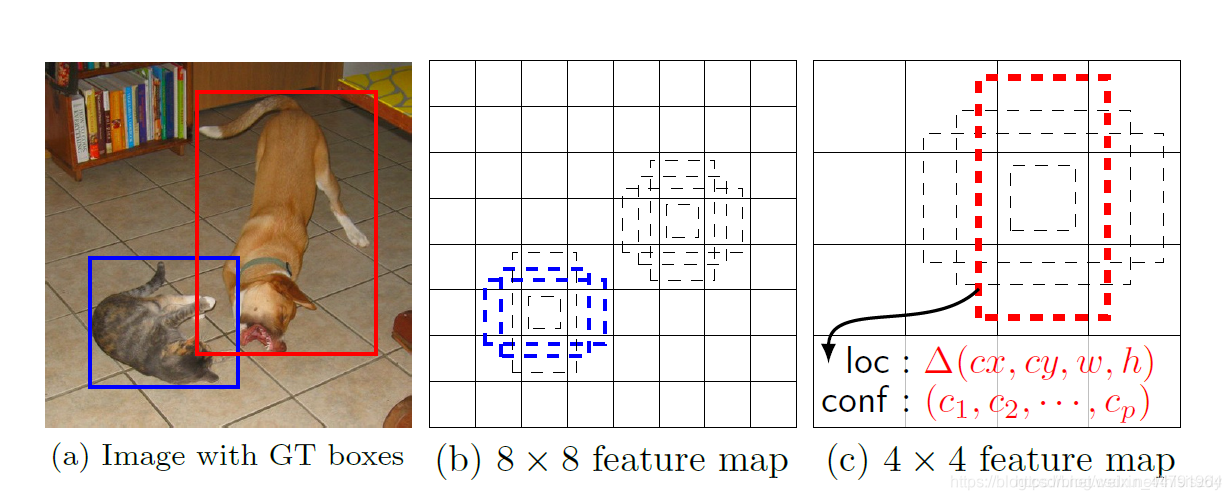
先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,Efficientdet利用3次64通道的卷积+num_anchors x 4的卷积的结果对先验框进行调整。
num_anchors x 4中的num_anchors表示了这个网格点所包含的先验框数量,其中的4表示了框的左上角xy轴,右下角xy的调整情况。
Efficientdet解码过程就是将对应的先验框的左上角和右下角进行位置的调整,调整完的结果就是预测框的位置了。
当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选这一部分基本上是所有目标检测通用的部分。
1、取出每一类得分大于confidence_threshold的框和得分。
2、利用框的位置和得分进行非极大抑制。
实现代码如下:
import numpy as npimport tensorflow as tfimport keras.backend as Kclass BBoxUtility(object):def __init__(self, num_classes, nms_thresh=0.45, top_k=300):self.num_classes = num_classesself._nms_thresh = nms_threshself._top_k = top_kself.boxes = K.placeholder(dtype='float32', shape=(None, 4))self.scores = K.placeholder(dtype='float32', shape=(None,))self.nms = tf.image.non_max_suppression(self.boxes, self.scores, self._top_k, iou_threshold=self._nms_thresh)self.sess = K.get_session()def bbox_iou(self, b1, b2):b1_x1, b1_y1, b1_x2, b1_y2 = b1[0], b1[1], b1[2], b1[3]b2_x1, b2_y1, b2_x2, b2_y2 = b2[:, 0], b2[:, 1], b2[:, 2], b2[:, 3]inter_rect_x1 = np.maximum(b1_x1, b2_x1)inter_rect_y1 = np.maximum(b1_y1, b2_y1)inter_rect_x2 = np.minimum(b1_x2, b2_x2)inter_rect_y2 = np.minimum(b1_y2, b2_y2)inter_area = np.maximum(inter_rect_x2 - inter_rect_x1, 0) * \np.maximum(inter_rect_y2 - inter_rect_y1, 0)area_b1 = (b1_x2-b1_x1)*(b1_y2-b1_y1)area_b2 = (b2_x2-b2_x1)*(b2_y2-b2_y1)iou = inter_area/np.maximum((area_b1+area_b2-inter_area),1e-6)return ioudef efficientdet_correct_boxes(self, box_xy, box_wh, input_shape, image_shape, letterbox_image):#-----------------------------------------------------------------## 把y轴放前面是因为方便预测框和图像的宽高进行相乘#-----------------------------------------------------------------#box_yx = box_xy[..., ::-1]box_hw = box_wh[..., ::-1]input_shape = np.array(input_shape)image_shape = np.array(image_shape)if letterbox_image:#-----------------------------------------------------------------## 这里求出来的offset是图像有效区域相对于图像左上角的偏移情况# new_shape指的是宽高缩放情况#-----------------------------------------------------------------#new_shape = np.round(image_shape * np.min(input_shape/image_shape))offset = (input_shape - new_shape)/2./input_shapescale = input_shape/new_shapebox_yx = (box_yx - offset) * scalebox_hw *= scalebox_mins = box_yx - (box_hw / 2.)box_maxes = box_yx + (box_hw / 2.)boxes = np.concatenate([box_mins[..., 0:1], box_mins[..., 1:2], box_maxes[..., 0:1], box_maxes[..., 1:2]], axis=-1)boxes *= np.concatenate([image_shape, image_shape], axis=-1)return boxesdef decode_boxes(self, mbox_loc, anchors):# 获得先验框的宽与高anchor_width = anchors[:, 2] - anchors[:, 0]anchor_height = anchors[:, 3] - anchors[:, 1]# 获得先验框的中心点anchor_center_x = 0.5 * (anchors[:, 2] + anchors[:, 0])anchor_center_y = 0.5 * (anchors[:, 3] + anchors[:, 1])# 真实框距离先验框中心的xy轴偏移情况decode_bbox_center_x = mbox_loc[:, 0] * anchor_widthdecode_bbox_center_x += anchor_center_xdecode_bbox_center_y = mbox_loc[:, 1] * anchor_heightdecode_bbox_center_y += anchor_center_y# 真实框的宽与高的求取decode_bbox_width = np.exp(mbox_loc[:, 2])decode_bbox_width *= anchor_widthdecode_bbox_height = np.exp(mbox_loc[:, 3])decode_bbox_height *= anchor_height# 获取真实框的左上角与右下角decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_widthdecode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_heightdecode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_widthdecode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height# 真实框的左上角与右下角进行堆叠decode_bbox = np.concatenate((decode_bbox_xmin[:, None],decode_bbox_ymin[:, None],decode_bbox_xmax[:, None],decode_bbox_ymax[:, None]), axis=-1)# 防止超出0与1decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0)return decode_bboxdef decode_box(self, predictions, anchors, image_shape, input_shape, letterbox_image, confidence=0.5):#---------------------------------------------------## 获得回归预测结果#---------------------------------------------------#mbox_loc = predictions[0]#---------------------------------------------------## 获得种类的置信度#---------------------------------------------------#mbox_conf = predictions[1]results = [None for _ in range(len(mbox_loc))]#----------------------------------------------------------------------------------------------------------------## 对每一张图片进行处理,由于在predict.py的时候,我们只输入一张图片,所以for i in range(len(mbox_loc))只进行一次#----------------------------------------------------------------------------------------------------------------#for i in range(len(mbox_loc)):#--------------------------------## 利用回归结果对先验框进行解码#--------------------------------#decode_bbox = self.decode_boxes(mbox_loc[i], anchors)#--------------------------------------------------## 判断置信度与非极大抑制的过程与视频有一定的差距# 整体思想相差不大,可以参考注释进行阅读#--------------------------------------------------#class_conf = np.expand_dims(np.max(mbox_conf[i], 1), -1)class_pred = np.expand_dims(np.argmax(mbox_conf[i], 1), -1)#--------------------------------## 判断置信度是否大于门限要求#--------------------------------#conf_mask = (class_conf >= confidence)[:, 0]#--------------------------------## 将预测结果进行堆叠#--------------------------------#detections = np.concatenate((decode_bbox[conf_mask], class_conf[conf_mask], class_pred[conf_mask]), 1)unique_labels = np.unique(detections[:,-1])#-------------------------------------------------------------------## 对种类进行循环,# 非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,# 对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。#-------------------------------------------------------------------#for c in unique_labels:#------------------------------------------## 获得某一类得分筛选后全部的预测结果#------------------------------------------#detections_class = detections[detections[:, -1] == c]#------------------------------------------## 使用官方自带的非极大抑制会速度更快一些!#------------------------------------------#idx = self.sess.run(self.nms, feed_dict={self.boxes: detections_class[:, :4], self.scores: detections_class[:, 4]})max_detections = detections_class[idx]# #------------------------------------------## # 非官方的实现部分# # 获得某一类得分筛选后全部的预测结果# #------------------------------------------## detections_class = detections[detections[:, -1] == c]# scores = detections_class[:, 4]# #------------------------------------------## # 根据得分对该种类进行从大到小排序。# #------------------------------------------## arg_sort = np.argsort(scores)[::-1]# detections_class = detections_class[arg_sort]# max_detections = []# while np.shape(detections_class)[0]>0:# #-------------------------------------------------------------------------------------## # 每次取出得分最大的框,计算其与其它所有预测框的重合程度,重合程度过大的则剔除。# #-------------------------------------------------------------------------------------## max_detections.append(detections_class[0])# if len(detections_class) == 1:# break# ious = self.bbox_iou(max_detections[-1], detections_class[1:])# detections_class = detections_class[1:][ious < self._nms_thresh]results[i] = max_detections if results[i] is None else np.concatenate((results[i], max_detections), axis = 0)if results[i] is not None:results[i] = np.array(results[i])box_xy, box_wh = (results[i][:, 0:2] + results[i][:, 2:4])/2, results[i][:, 2:4] - results[i][:, 0:2]results[i][:, :4] = self.efficientdet_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)return results
5、在原图上进行绘制
通过第三步,我们可以获得预测框在原图上的位置,而且这些预测框都是经过筛选的。这些筛选后的框可以直接绘制在图片上,就可以获得结果了。
二、训练部分
1、真实框的处理
从预测部分我们知道,每个特征层的预测结果,num_anchors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
也就是说,我们直接利用Efficientdet网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于Efficientdet网络的预测结果的。我们需要把图片输入到当前的Efficientdet网络中,得到预测结果;同时还需要把真实框的信息,进行编码,这个编码是把真实框的位置信息格式转化为Efficientdet预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的预测结果应该是怎么样的。
从预测结果获得真实框的过程被称作解码,而从真实框获得预测结果的过程就是编码的过程。
因此我们只需要将解码过程逆过来就是编码过程了。
实现代码如下:
def encode_box(self, box, return_iou=True):#---------------------------------------------## 计算当前真实框和先验框的重合情况#---------------------------------------------#iou = self.iou(box)ignored_box = np.zeros((self.num_anchors, 1))#---------------------------------------------------## 找到处于忽略门限值范围内的先验框#---------------------------------------------------#assign_mask_ignore = (iou > self.ignore_threshold) & (iou < self.overlap_threshold)ignored_box[:, 0][assign_mask_ignore] = iou[assign_mask_ignore]encoded_box = np.zeros((self.num_anchors, 4 + return_iou))#---------------------------------------------## 找到每一个真实框,重合程度较高的先验框#---------------------------------------------#assign_mask = iou > self.overlap_threshold#---------------------------------------------## 如果没有一个先验框重合度大于self.overlap_threshold# 则选择重合度最大的为正样本#---------------------------------------------#if not assign_mask.any():assign_mask[iou.argmax()] = True#---------------------------------------------## 利用iou进行赋值#---------------------------------------------#if return_iou:encoded_box[:, -1][assign_mask] = iou[assign_mask]#---------------------------------------------## 找到对应的先验框#---------------------------------------------#assigned_anchors = self.anchors[assign_mask]#---------------------------------------------## 逆向编码,将真实框转化为efficientdet预测结果的格式# 先计算真实框的中心与长宽#---------------------------------------------#box_center = 0.5 * (box[:2] + box[2:])box_wh = box[2:] - box[:2]#---------------------------------------------## 再计算重合度较高的先验框的中心与长宽#---------------------------------------------#assigned_anchors_center = (assigned_anchors[:, 0:2] + assigned_anchors[:, 2:4]) * 0.5assigned_anchors_wh = (assigned_anchors[:, 2:4] - assigned_anchors[:, 0:2])#------------------------------------------------## 逆向求取efficientdet应该有的预测结果# 先求取中心的预测结果,再求取宽高的预测结果#------------------------------------------------#encoded_box[:, :2][assign_mask] = box_center - assigned_anchors_centerencoded_box[:, :2][assign_mask] /= assigned_anchors_whencoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_anchors_wh)return encoded_box.ravel(), ignored_box.ravel()
利用上述代码我们可以获得,真实框对应的所有的iou较大先验框,并计算了真实框对应的所有iou较大的先验框应该有的预测结果。
但是由于原始图片中可能存在多个真实框,可能同一个先验框会与多个真实框重合度较高,我们只取其中与真实框重合度最高的就可以了。
因此我们还要经过一次筛选,将上述代码获得的真实框对应的所有的iou较大先验框的预测结果中,iou最大的那个真实框筛选出来。
通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的。
实现代码如下:
def assign_boxes(self, boxes):#---------------------------------------------------## assignment分为3个部分# :4 的内容为网络应该有的回归预测结果# 4:-1 的内容为先验框所对应的种类,默认为背景# -1 的内容为当前先验框是否包含目标#---------------------------------------------------#assignment = np.zeros((self.num_anchors, 4 + 1 + self.num_classes + 1))assignment[:, 4] = 0.0assignment[:, -1] = 0.0if len(boxes) == 0:return assignment#---------------------------------------------------## 对每一个真实框都进行iou计算#---------------------------------------------------#apply_along_axis_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4])encoded_boxes = np.array([apply_along_axis_boxes[i, 0] for i in range(len(apply_along_axis_boxes))])ingored_boxes = np.array([apply_along_axis_boxes[i, 1] for i in range(len(apply_along_axis_boxes))])#---------------------------------------------------## 在reshape后,获得的ingored_boxes的shape为:# [num_true_box, num_anchors, 1] 其中1为iou#---------------------------------------------------#ingored_boxes = ingored_boxes.reshape(-1, self.num_anchors, 1)ignore_iou = ingored_boxes[:, :, 0].max(axis=0)ignore_iou_mask = ignore_iou > 0assignment[:, 4][ignore_iou_mask] = -1assignment[:, -1][ignore_iou_mask] = -1#---------------------------------------------------## 在reshape后,获得的encoded_boxes的shape为:# [num_true_box, num_anchors, 4+1]# 4是编码后的结果,1为iou#---------------------------------------------------#encoded_boxes = encoded_boxes.reshape(-1, self.num_anchors, 5)#---------------------------------------------------## [num_anchors]求取每一个先验框重合度最大的真实框#---------------------------------------------------#best_iou = encoded_boxes[:, :, -1].max(axis=0)best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)best_iou_mask = best_iou > 0best_iou_idx = best_iou_idx[best_iou_mask]#---------------------------------------------------## 计算一共有多少先验框满足需求#---------------------------------------------------#assign_num = len(best_iou_idx)# 将编码后的真实框取出encoded_boxes = encoded_boxes[:, best_iou_mask, :]assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4]#----------------------------------------------------------## 4代表为背景的概率,设定为0,因为这些先验框有对应的物体#----------------------------------------------------------#assignment[:, 4][best_iou_mask] = 1assignment[:, 5:-1][best_iou_mask] = boxes[best_iou_idx, 4:]#----------------------------------------------------------## -8表示先验框是否有对应的物体#----------------------------------------------------------#assignment[:, -1][best_iou_mask] = 1# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的return assignment
focal会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.4-0.5之间的先验框进行忽略。
2、利用处理完的真实框与对应图片的预测结果计算loss
loss的计算分为两个部分:
1、Smooth Loss:获取所有正标签的框的预测结果的回归loss。
2、Focal Loss:获取所有未被忽略的种类的预测结果的交叉熵loss。
由于在Efficientdet的训练过程中,正负样本极其不平衡,即 存在对应真实框的先验框可能只有若干个,但是不存在对应真实框的负样本却有上万个,这就会导致负样本的loss值极大,因此引入了Focal Loss进行正负样本的平衡。
Focal loss是何恺明大神提出的一种新的loss计算方案。其具有两个重要的特点。
- 控制正负样本的权重
- 控制容易分类和难分类样本的权重
正负样本的概念如下:
一张图像可能生成成千上万的候选框,但是其中只有很少一部分是包含目标的的,有目标的就是正样本,没有目标的就是负样本。
容易分类和难分类样本的概念如下:
假设存在一个二分类,样本1属于类别1的pt=0.9,样本2属于类别1的pt=0.6,显然前者更可能是类别1,其就是容易分类的样本;后者有可能是类别1,所以其为难分类样本。
如何实现权重控制呢,请往下看:
a、控制正负样本的权重
如下是常用的交叉熵loss,以二分类为例: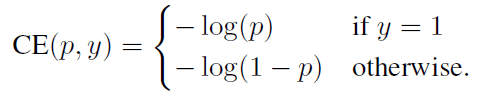
我们可以利用如下Pt简化交叉熵loss。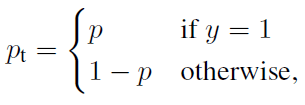
此时: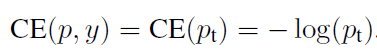
想要降低负样本的影响,可以在常规的损失函数前增加一个系数αt。与Pt类似,当label=1的时候,αt=α;当label=otherwise的时候,αt=1 - α,a的范围也是0到1。此时我们便可以通过设置α实现控制正负样本对loss的贡献。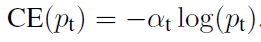
其中: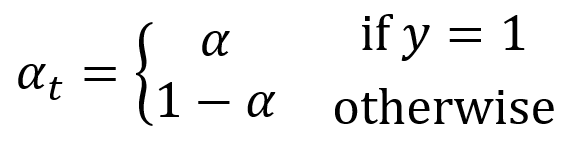
分解开就是: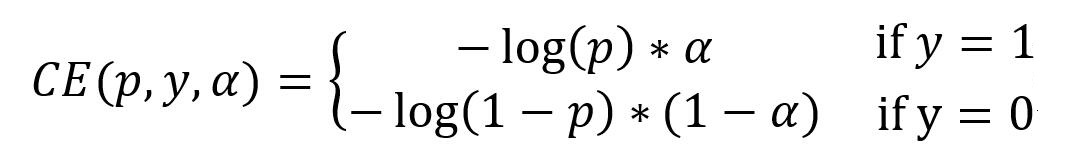
b、控制容易分类和难分类样本的权重
按照刚才的思路,一个二分类,样本1属于类别1的pt=0.9,样本2属于类别1的pt=0.6,也就是 是某个类的概率越大,其越容易分类 所以利用1-Pt就可以计算出其属于容易分类或者难分类。
具体实现方式如下。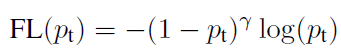
其中:
( 1 − p t ) γ (1-p_{t})^{γ} (1−pt)γ
称为调制系数(modulating factor)
1、当pt趋于0的时候,调制系数趋于1,对于总的loss的贡献很大。当pt趋于1的时候,调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,可以通过调整γ实现调制系数的改变。
c、两种权重控制方法合并
通过如下公式就可以实现控制正负样本的权重和控制容易分类和难分类样本的权重。
实现代码如下:
import tensorflow as tffrom keras import backend as Kdef focal(alpha=0.25, gamma=2.0):def _focal(y_true, y_pred):#---------------------------------------------------## y_true [batch_size, num_anchor, num_classes+1]# y_pred [batch_size, num_anchor, num_classes]#---------------------------------------------------#labels = y_true[:, :, :-1]#---------------------------------------------------## -1 是需要忽略的, 0 是背景, 1 是存在目标#---------------------------------------------------#anchor_state = y_true[:, :, -1]classification = y_pred# 找出存在目标的先验框indices = tf.where(K.not_equal(anchor_state, -1))labels = tf.gather_nd(labels, indices)classification = tf.gather_nd(classification, indices)# 计算每一个先验框应该有的权重alpha_factor = K.ones_like(labels) * alphaalpha_factor = tf.where(K.equal(labels, 1), alpha_factor, 1 - alpha_factor)focal_weight = tf.where(K.equal(labels, 1), 1 - classification, classification)focal_weight = alpha_factor * focal_weight ** gamma# 将权重乘上所求得的交叉熵cls_loss = focal_weight * K.binary_crossentropy(labels, classification)# 标准化,实际上是正样本的数量normalizer = tf.where(K.equal(anchor_state, 1))normalizer = K.cast(K.shape(normalizer)[0], K.floatx())normalizer = K.maximum(K.cast_to_floatx(1.0), normalizer)# 将所获得的loss除上正样本的数量loss = K.sum(cls_loss) / normalizerreturn lossreturn _focaldef smooth_l1(sigma=3.0):sigma_squared = sigma ** 2def _smooth_l1(y_true, y_pred):#---------------------------------------------------## y_true [batch_size, num_anchor, 4+1]# y_pred [batch_size, num_anchor, 4]#---------------------------------------------------#regression = y_predregression_target = y_true[:, :, :-1]anchor_state = y_true[:, :, -1]# 找出存在目标的先验框indices = tf.where(K.equal(anchor_state, 1))regression = tf.gather_nd(regression, indices)regression_target = tf.gather_nd(regression_target, indices)# 计算smooth L1损失regression_diff = regression - regression_targetregression_diff = K.abs(regression_diff)regression_loss = tf.where(K.less(regression_diff, 1.0 / sigma_squared),0.5 * sigma_squared * K.pow(regression_diff, 2),regression_diff - 0.5 / sigma_squared)# 将所获得的loss除上正样本的数量normalizer = K.maximum(1, K.shape(indices)[0])normalizer = K.cast(normalizer, dtype=K.floatx())return K.sum(regression_loss) / normalizer / 4return _smooth_l1
训练自己的Efficientdet模型
首先前往Github下载对应的仓库,下载完后利用解压软件解压,之后用编程软件打开文件夹。
注意打开的根目录必须正确,否则相对目录不正确的情况下,代码将无法运行。
一定要注意打开后的根目录是文件存放的目录。
一、数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过Github连接下载VOC12+07的数据集尝试下。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
此时数据集的摆放已经结束。
二、数据集的处理
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的2007_train.txt以及2007_val.txt,需要用到根目录下的voc_annotation.py。
voc_annotation.py里面有一些参数需要设置。
分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path
'''annotation_mode用于指定该文件运行时计算的内容annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txtannotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txtannotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt'''annotation_mode = 0'''必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息与训练和预测所用的classes_path一致即可如果生成的2007_train.txt里面没有目标信息那么就是因为classes没有设定正确仅在annotation_mode为0和2的时候有效'''classes_path = 'model_data/voc_classes.txt''''trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1仅在annotation_mode为0和1的时候有效'''trainval_percent = 0.9train_percent = 0.9'''指向VOC数据集所在的文件夹默认指向根目录下的VOC数据集'''VOCdevkit_path = 'VOCdevkit'
classes_path用于指向检测类别所对应的txt,以voc数据集为例,我们用的txt为:
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
三、开始网络训练
通过voc_annotation.py我们已经生成了2007_train.txt以及2007_val.txt,此时我们可以开始训练了。
训练的参数较多,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的classes_path。
classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样!训练自己的数据集必须要修改!
修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
其它参数的作用如下:
#--------------------------------------------------------## 训练前一定要修改classes_path,使其对应自己的数据集#--------------------------------------------------------#classes_path = 'model_data/voc_classes.txt'#----------------------------------------------------------------------------------------------------------------------------## 权值文件请看README,百度网盘下载。数据的预训练权重对不同数据集是通用的,因为特征是通用的。# 预训练权重对于99%的情况都必须要用,不用的话权值太过随机,特征提取效果不明显,网络训练的结果也不会好。# 训练自己的数据集时提示维度不匹配正常,预测的东西都不一样了自然维度不匹配## 如果想要断点续练就将model_path设置成logs文件夹下已经训练的权值文件。# 当model_path = ''的时候不加载整个模型的权值。## 此处使用的是整个模型的权重,因此是在train.py进行加载的。# 如果想要让模型从主干的预训练权值开始训练,则设置model_path为主干网络的权值,此时仅加载主干。# 如果想要让模型从0开始训练,则设置model_path = '',Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。# 一般来讲,从0开始训练效果会很差,因为权值太过随机,特征提取效果不明显。#----------------------------------------------------------------------------------------------------------------------------#model_path = 'model_data/efficientdet-d0-voc.h5'#---------------------------------------------------------------------## 用于选择所使用的模型的版本,0-7#---------------------------------------------------------------------#phi = 0#------------------------------------------------------## 输入的shape大小#------------------------------------------------------#input_shape = [image_sizes[phi], image_sizes[phi]]#---------------------------------------------------------------------## 可用于设定先验框的大小,默认的anchors_size,大多数情况下都是通用的!# 如果想要检测小物体,可以修改anchors_size# 一般调小浅层先验框的大小就行了!因为浅层负责小物体检测!#---------------------------------------------------------------------#anchors_size = [32, 64, 128, 256, 512]#----------------------------------------------------## 训练分为两个阶段,分别是冻结阶段和解冻阶段。# 显存不足与数据集大小无关,提示显存不足请调小batch_size。# 受到BatchNorm层影响,batch_size最小为2,不能为1。#----------------------------------------------------##----------------------------------------------------## 冻结阶段训练参数# 此时模型的主干被冻结了,特征提取网络不发生改变# 占用的显存较小,仅对网络进行微调#----------------------------------------------------#Init_Epoch = 0Freeze_Epoch = 50Freeze_batch_size = 8Freeze_lr = 1e-3#----------------------------------------------------## 解冻阶段训练参数# 此时模型的主干不被冻结了,特征提取网络会发生改变# 占用的显存较大,网络所有的参数都会发生改变#----------------------------------------------------#UnFreeze_Epoch = 100Unfreeze_batch_size = 4Unfreeze_lr = 1e-4#------------------------------------------------------## 是否进行冻结训练,默认先冻结主干训练后解冻训练。#------------------------------------------------------#Freeze_Train = True#------------------------------------------------------## 用于设置是否使用多线程读取数据,0代表关闭多线程# 开启后会加快数据读取速度,但是会占用更多内存# keras里开启多线程有些时候速度反而慢了许多# 在IO为瓶颈的时候再开启多线程,即GPU运算速度远大于读取图片的速度。#------------------------------------------------------#num_workers = 0#----------------------------------------------------## 获得图片路径和标签#----------------------------------------------------#train_annotation_path = '2007_train.txt'val_annotation_path = '2007_val.txt'
四、训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。
我们首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。



























")
MySQL Protocol和Read调用栈")





还没有评论,来说两句吧...