大数据技术之kettle(2)——练习三个基本操作
一、同一数据库两表数据关联更新
实现效果:把stu1的数据按id同步到stu2,stu2有相同id则更新数据
步骤:
1.在mysql中创建两张表:
mysql>create database kettle;
mysql>use kettle;
mysql>create table stu1 (id int ,name varchar(20),age int);
mysql>create table stu2 (id int ,name varchar(20));
2.往两张表中插入一些数据:
mysql>insert into stu1 values(1001,’zhangsan’,20),(1002,’lisi’,18),(1003,’wangwu’,23);
mysql>insert into stu2 values(1001,’wukong’);
3.在kettle中新建转换,点击左上角文件—新建—转换到核心对象界面,点击输入,找到表输入拖拽到中间

4.双击表输入,在数据库连接中配置mysql数据库连接(注意jar包mysql-connector-java-5.1.34-bin.jar要放在kettle的lib文件夹中)
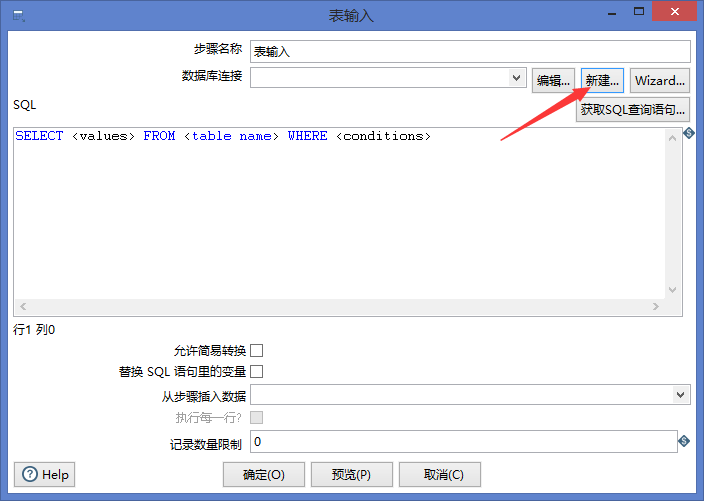
输入完信息后点击测试,显示正确连接。

5.sql语句中输入select * from stu1;
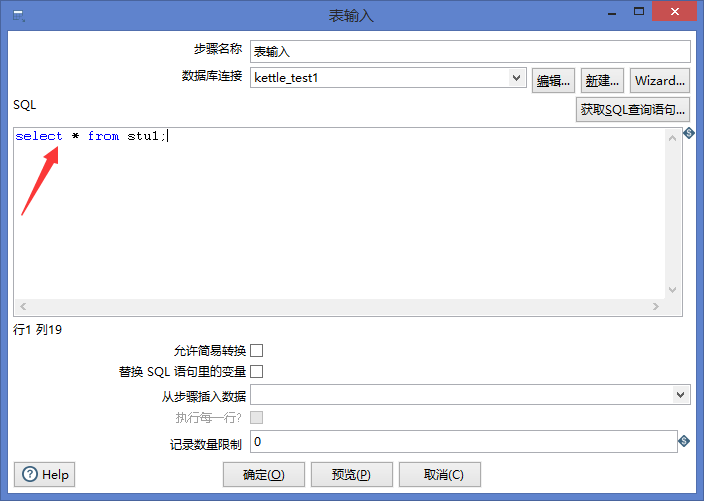
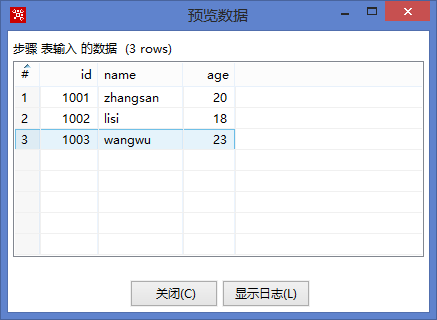
点击预览可以看到数据
6.在输出中找到插入/更新组件拖拽到中间,点住表输入shift+鼠标左键连接到插入/更新组件上

双击插入/更新,点击目标表浏览,选择stu2
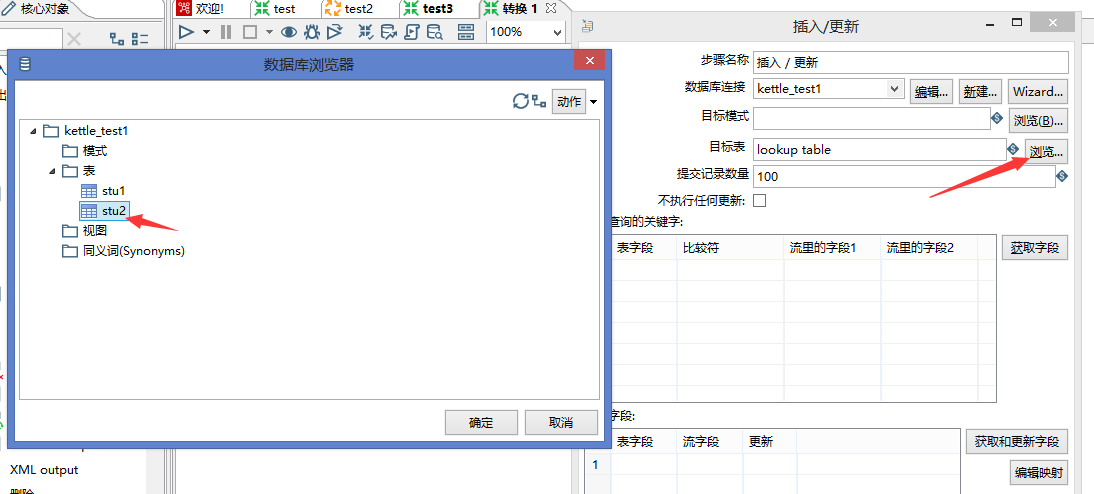
点击获取字段获取到3个字段
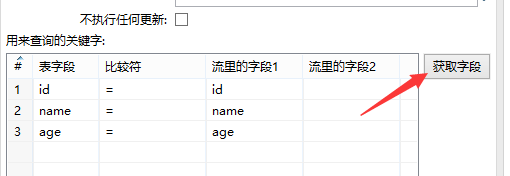
由于stu1与stu2通过id关联,故删除name和age字段,然后点击编辑映射,编辑2个表之间的映射
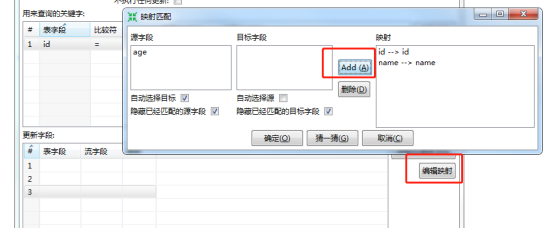
确定后如图:
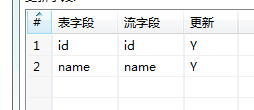
更新处,修改id的属性为n,确定。然后保存运行,到数据库中查看结果。
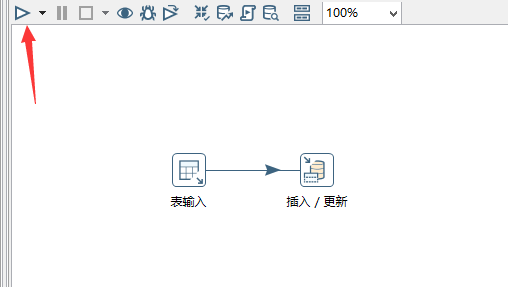
最后生成了一个文件,如下:
二、使用作业执行生成的转换文件
实现效果:使用作业执行“一”中的转换,并且额外在表stu2中添加一条数据
步骤:
新建一个作业
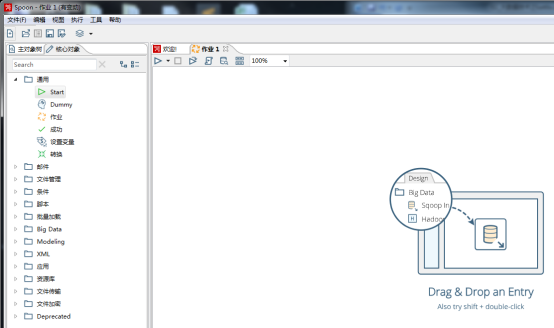
点击通用将start拖拽到作业中

将转换拖拽过来,将start与转换相连接
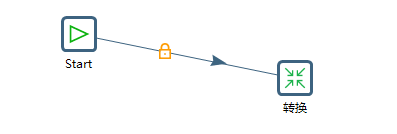
双击转换,选择之前做好的job
左侧脚本中选择sql组件拖拽过来并连接
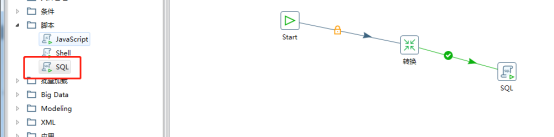
新建连接配置mysql数据库,并写插入sql语句
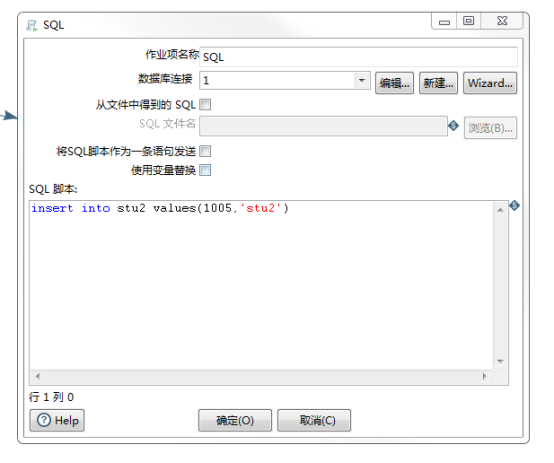
确定,保存job并执行
三、将A数据库中的a表经过ETL过程导入B数据库中
sql语句地址:https://pan.baidu.com/s/1Eba9TEO3UO9Fjaz522VONw
实现效果:将hr数据库中的employees表,经过ETL过程,导入到scott数据库中;将列FIRST_NAME和LAST_NAME相连,中间用空格隔开,取名为“NAME”;将列PHONE_NUMBER中的区号加上括号(例如515.123.4567改为(515)123.4567),列名不变;在scott数据库中,该表的列名不变,表名改为dw_dim_employees。
实现步骤:
1.双击桌面的 图标进入到kettle的Transformation界面,双击转换切换到操作界面
在核心对象目录树下找到输入,点击前面的展开三角,找到表输入组件拖入到右侧工作区
同样的在输出中,找到表输出拖入到右侧工作区;在转换中找到字段选择拖入到右侧工作区。
2.将这3个组件连接起来,先选中表输入,Shift+鼠标左键拖拽到字段选择上,再选中字段选择同样的Shift+鼠标左键拖拽到表输出上并选定为主输出步骤。
3.双击表输入,数据库连接处点击新建,连接名称填写hr,连接类型选择mysql。。。与“上边一中的操作一致”
4.点击下面测试,弹出正确连接数据库hr,点击确定保存设置
在表输入的SQL框中输入如下SQL语句
SELECT EMPLOYEE_ID, CONCAT(FIRST_NAME, ' ', LAST_NAME) AS NAME, CONCAT('(', SUBSTR(PHONE_NUMBER, 1, 3), ')', SUBSTR(PHONE_NUMBER, 5)) AS PHONE_NUMBER, HIRE_DATE, JOB_ID, SALARY, COMMISSION_PCT, NAGER_ID, DEPARTMENT_IDFROM employees
点击预览数据,确认无误后点击确定关闭
5.双击字段选择,点击获取选择的字段,得到10个字段后点击确定关闭
双击表输出,依然在数据库连接处点击新建
在数据库连接界面填入如下信息:回到表输出界面,在目标表中填写表名:dw_dim_employees,勾选指定数据库字段,点击下面数据库字段点击获取字段。
点击右下角SQL按钮,点击启动
弹出保存提示,选择是,找到一个文件路径(如桌面/项目脚本),为job起个名字
运行成功
转载于 //www.cnblogs.com/ssyh/p/11443714.html
//www.cnblogs.com/ssyh/p/11443714.html




























还没有评论,来说两句吧...