tensorflow 2.0 深度学习(第四部分 循环神经网络)
" class="reference-link">
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
tensorflow 2.0 深度学习(第一部分 part1)
tensorflow 2.0 深度学习(第一部分 part2)
tensorflow 2.0 深度学习(第一部分 part3)
tensorflow 2.0 深度学习(第二部分 part1)
tensorflow 2.0 深度学习(第二部分 part2)
tensorflow 2.0 深度学习(第二部分 part3)
tensorflow 2.0 深度学习 (第三部分 卷积神经网络 part1)
tensorflow 2.0 深度学习 (第三部分 卷积神经网络 part2)
tensorflow 2.0 深度学习(第四部分 循环神经网络)
tensorflow 2.0 深度学习(第五部分 GAN生成神经网络 part1)
tensorflow 2.0 深度学习(第五部分 GAN生成神经网络 part2)
tensorflow 2.0 深度学习(第六部分 强化学习)
基础知识



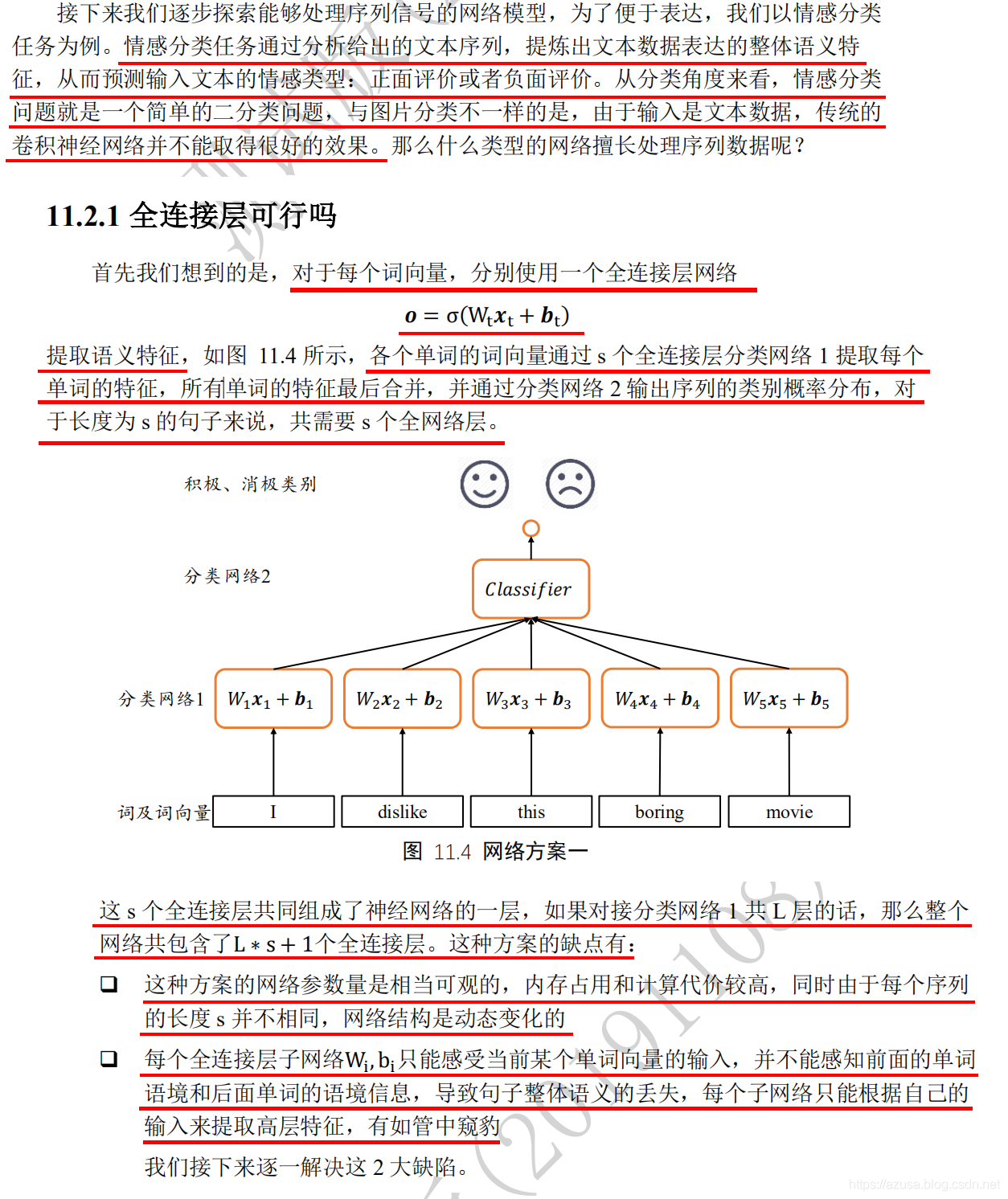

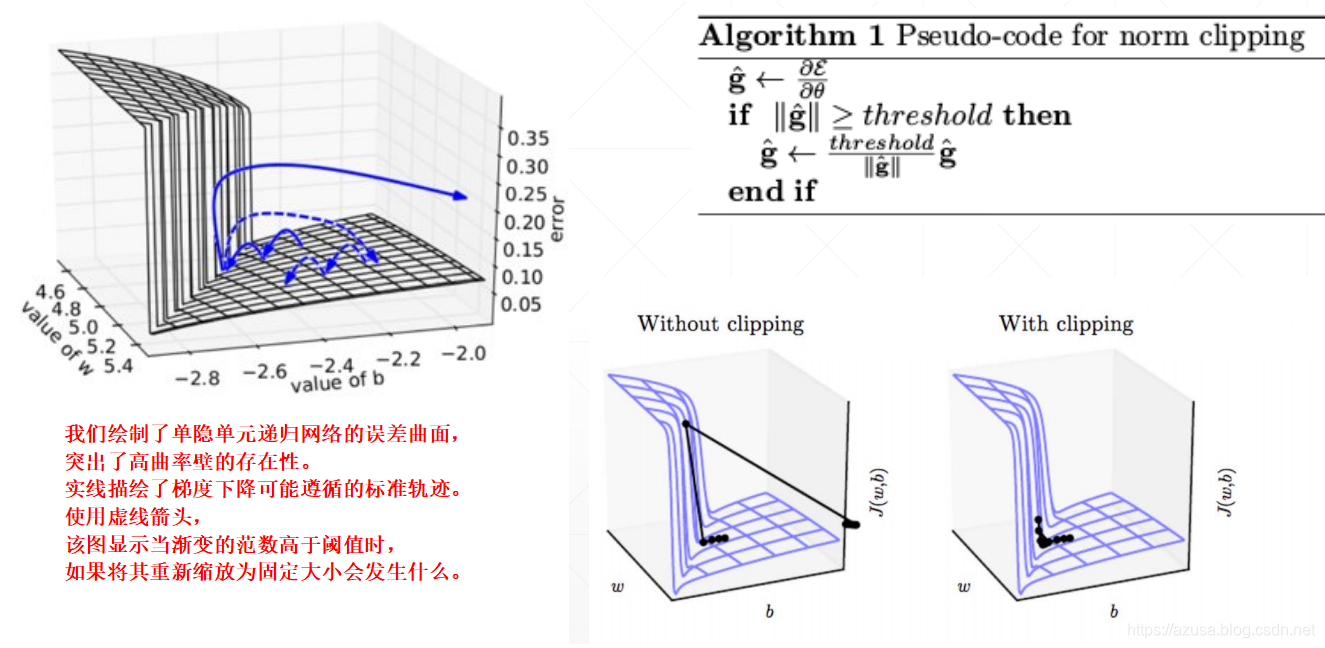
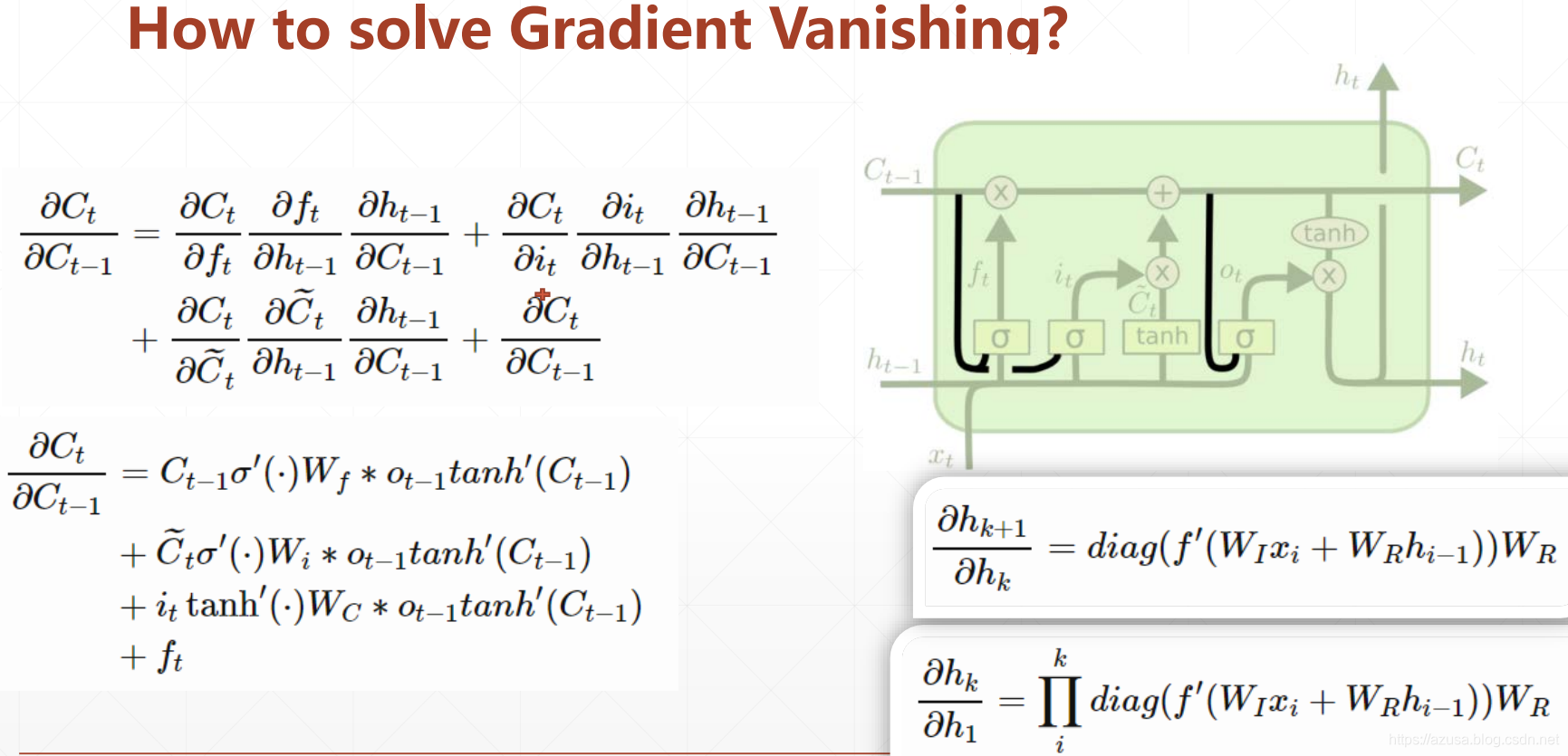
梯度传播相关原理
" class="reference-link">梯度传播原理
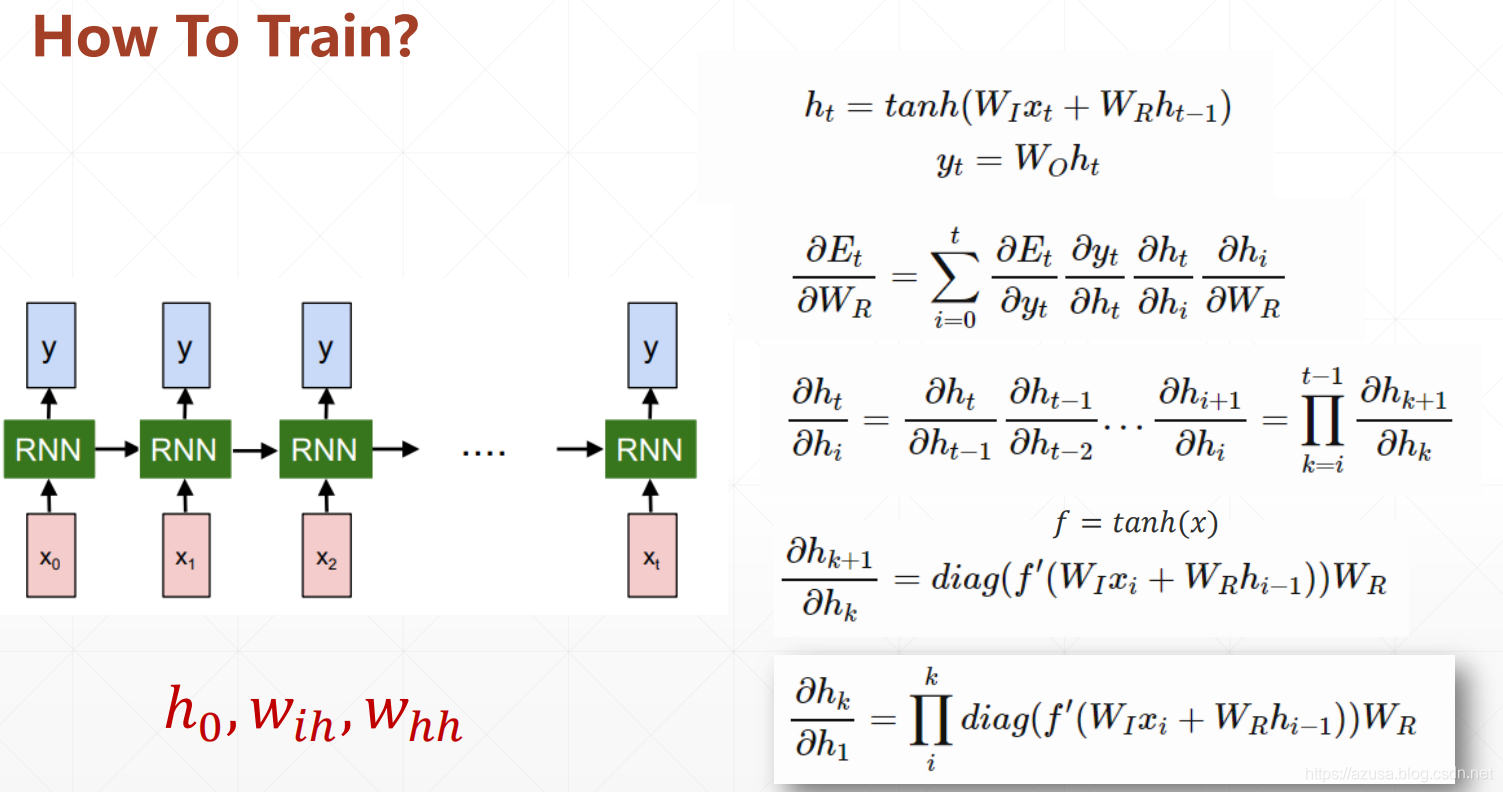
" class="reference-link">梯度弥散、梯度爆炸
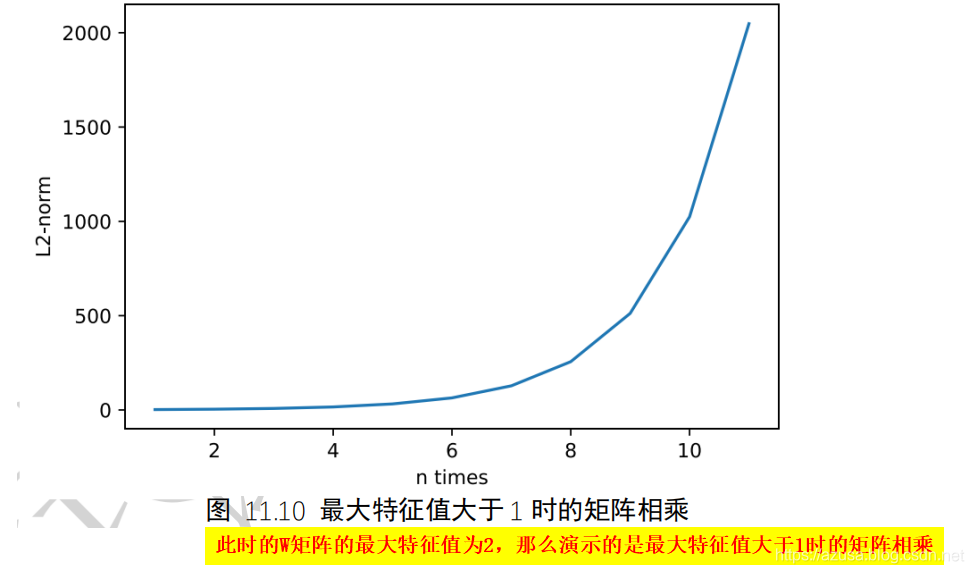
>>> import tensorflow as tf>>> W = tf.ones([2,2]) # 任意创建某矩阵>>> W<tf.Tensor: id=2, shape=(2, 2), dtype=float32, numpy=array([[1., 1.],[1., 1.]], dtype=float32)>>>> tf.linalg.eigh(W)(<tf.Tensor: id=3, shape=(2,), dtype=float32, numpy=array([0., 2.], dtype=float32)>,<tf.Tensor: id=4, shape=(2, 2), dtype=float32, numpy=array([[-0.70710677, 0.70710677],[ 0.70710677, 0.70710677]], dtype=float32)>)>>> tf.linalg.eigh(W)[0] # 计算特征值:此时的W矩阵的最大特征值为2,那么下面演示的是最大特征值大于1时的矩阵相乘<tf.Tensor: id=5, shape=(2,), dtype=float32, numpy=array([0., 2.], dtype=float32)>>>> tf.linalg.eigh(W)[1]<tf.Tensor: id=8, shape=(2, 2), dtype=float32, numpy=array([[-0.70710677, 0.70710677],[ 0.70710677, 0.70710677]], dtype=float32)>>>> val = [W]>>> val[<tf.Tensor: id=2, shape=(2, 2), dtype=float32, numpy=array([[1., 1.],[1., 1.]], dtype=float32)>]>>> for i in range(10): # 矩阵相乘 n 次方... val.append([val[-1]@W])...>>> val[<tf.Tensor: id=2, shape=(2, 2), dtype=float32, numpy=array([[1., 1.],[1., 1.]], dtype=float32)>,[<tf.Tensor: id=9, shape=(2, 2), dtype=float32, numpy=array([[2., 2.],[2., 2.]], dtype=float32)>],[<tf.Tensor: id=11, shape=(1, 2, 2), dtype=float32, numpy=array([[[4., 4.],[4., 4.]]], dtype=float32)>],[<tf.Tensor: id=13, shape=(1, 1, 2, 2), dtype=float32, numpy=array([[[[8., 8.],[8., 8.]]]], dtype=float32)>],[<tf.Tensor: id=15, shape=(1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[16., 16.],[16., 16.]]]]], dtype=float32)>],[<tf.Tensor: id=17, shape=(1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[32., 32.],[32., 32.]]]]]], dtype=float32)>],[<tf.Tensor: id=19, shape=(1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[64., 64.],[64., 64.]]]]]]], dtype=float32)>],[<tf.Tensor: id=21, shape=(1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[128., 128.],[128., 128.]]]]]]]], dtype=float32)>],[<tf.Tensor: id=23, shape=(1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[256., 256.],[256., 256.]]]]]]]]], dtype=float32)>],[<tf.Tensor: id=25, shape=(1, 1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[[512., 512.],[512., 512.]]]]]]]]]], dtype=float32)>],[<tf.Tensor: id=27, shape=(1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[[[1024., 1024.],[1024., 1024.]]]]]]]]]]], dtype=float32)>]]>>> l = list(map(lambda x:x,val)) #map遍历val中的每个array到list中作为list的每个元素>>> len(l)11>>> norm = list(map(lambda x:tf.norm(x).numpy(),val)) #tf.norm(x)默认执行L2的tf.norm(x,ord=2)等同于tf.sqrt(tf.reduce_sum(tf.square(a)))>>> len(norm)11>>> norm[2.0, 4.0, 8.0, 16.0, 32.0, 64.0, 128.0, 256.0, 512.0, 1024.0, 2048.0]>>> m = list(map(lambda x:tf.sqrt(tf.reduce_sum(tf.square(x))),val)) #tf.norm(x)默认执行L2的tf.norm(x,ord=2)等同于tf.sqrt(tf.reduce_sum(tf.square(a)))>>> m[<tf.Tensor: id=130, shape=(), dtype=float32, numpy=2.0>,<tf.Tensor: id=135, shape=(), dtype=float32, numpy=4.0>,<tf.Tensor: id=140, shape=(), dtype=float32, numpy=8.0>,<tf.Tensor: id=145, shape=(), dtype=float32, numpy=16.0>,<tf.Tensor: id=150, shape=(), dtype=float32, numpy=32.0>,<tf.Tensor: id=155, shape=(), dtype=float32, numpy=64.0>,<tf.Tensor: id=160, shape=(), dtype=float32, numpy=128.0>,<tf.Tensor: id=165, shape=(), dtype=float32, numpy=256.0>,<tf.Tensor: id=170, shape=(), dtype=float32, numpy=512.0>,<tf.Tensor: id=175, shape=(), dtype=float32, numpy=1024.0>,<tf.Tensor: id=180, shape=(), dtype=float32, numpy=2048.0>]>>> from matplotlib import pyplot as plt>>> plt.plot(range(1,12),norm)[<matplotlib.lines.Line2D object at 0x0000025773D525C8>]>>> plt.show()>>> eigenvalues = tf.linalg.eigh(W)>>> eigenvalues #此时的 W 矩阵最大特征值是 0.8(<tf.Tensor: id=14, shape=(2,), dtype=float32, numpy=array([0. , 0.8], dtype=float32)>,<tf.Tensor: id=15, shape=(2, 2), dtype=float32,numpy=array([[-0.70710677, 0.70710677],[ 0.70710677, 0.70710677]], dtype=float32)>)
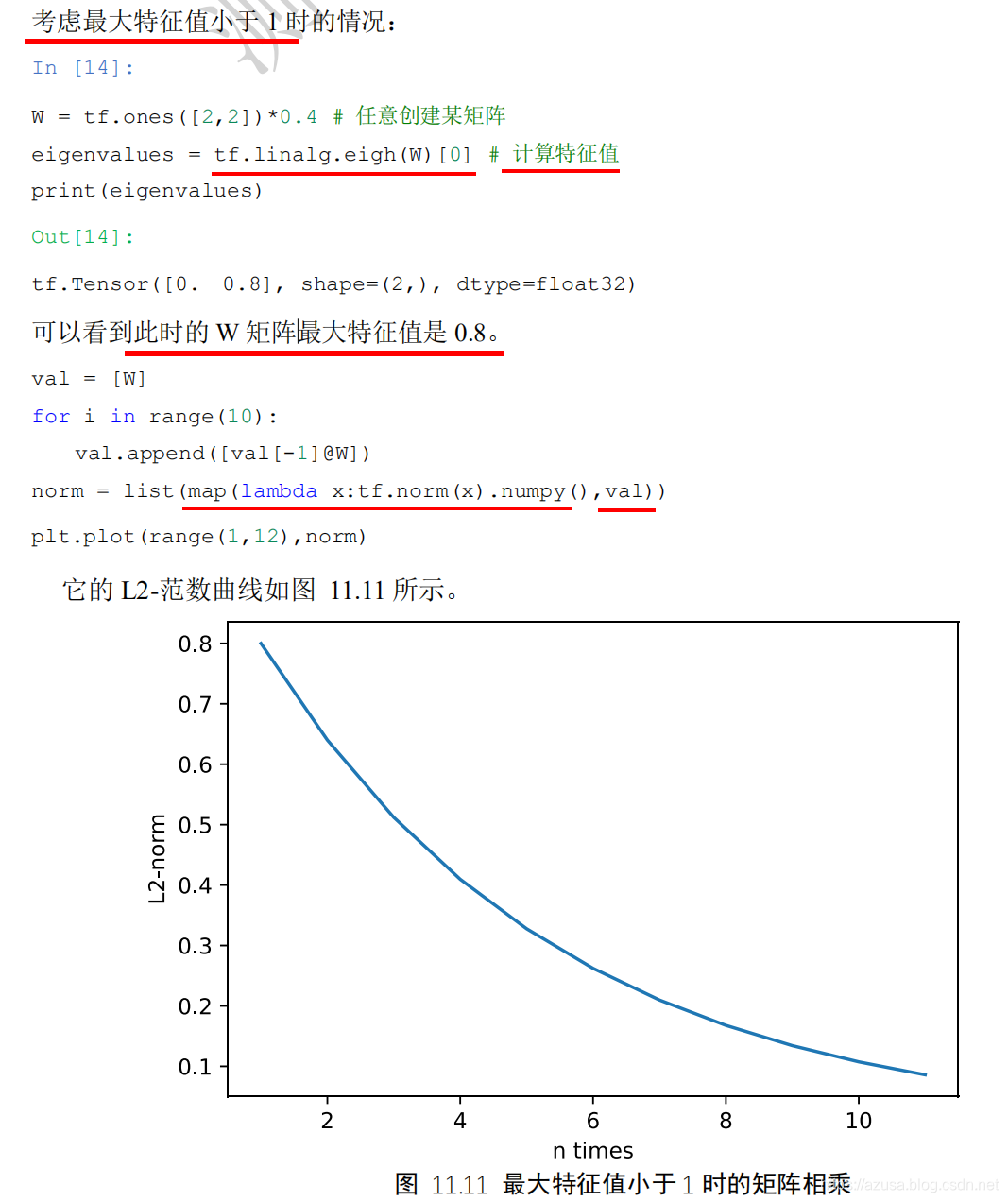
>>> import tensorflow as tf>>> from matplotlib import pyplot as plt>>> W = tf.ones([2,2])*0.4 # 任意创建某矩阵>>> W<tf.Tensor: id=185, shape=(2, 2), dtype=float32, numpy=array([[0.4, 0.4],[0.4, 0.4]], dtype=float32)>>>> tf.linalg.eigh(W)(<tf.Tensor: id=186, shape=(2,), dtype=float32, numpy=array([0. , 0.8], dtype=float32)>,<tf.Tensor: id=187, shape=(2, 2), dtype=float32, numpy=array([[-0.70710677, 0.70710677],[ 0.70710677, 0.70710677]], dtype=float32)>)>>> eigenvalues = tf.linalg.eigh(W)[0] # 计算特征值:此时的W矩阵的最大特征值为0.8,那么下面演示的是最大特征值小于1时的矩阵相乘>>> eigenvalues<tf.Tensor: id=188, shape=(2,), dtype=float32, numpy=array([0. , 0.8], dtype=float32)>>>> val = [W]>>> for i in range(10):... val.append([val[-1]@W])...>>> val[<tf.Tensor: id=185, shape=(2, 2), dtype=float32, numpy=array([[0.4, 0.4],[0.4, 0.4]], dtype=float32)>,[<tf.Tensor: id=190, shape=(2, 2), dtype=float32, numpy=array([[0.32000002, 0.32000002],[0.32000002, 0.32000002]], dtype=float32)>],[<tf.Tensor: id=192, shape=(1, 2, 2), dtype=float32, numpy=array([[[0.256, 0.256],[0.256, 0.256]]], dtype=float32)>],[<tf.Tensor: id=194, shape=(1, 1, 2, 2), dtype=float32, numpy=array([[[[0.20480001, 0.20480001],[0.20480001, 0.20480001]]]], dtype=float32)>],[<tf.Tensor: id=196, shape=(1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[0.16384001, 0.16384001],[0.16384001, 0.16384001]]]]], dtype=float32)>],[<tf.Tensor: id=198, shape=(1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[0.13107201, 0.13107201],[0.13107201, 0.13107201]]]]]], dtype=float32)>],[<tf.Tensor: id=200, shape=(1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[0.10485762, 0.10485762],[0.10485762, 0.10485762]]]]]]], dtype=float32)>],[<tf.Tensor: id=202, shape=(1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[0.08388609, 0.08388609],[0.08388609, 0.08388609]]]]]]]], dtype=float32)>],[<tf.Tensor: id=204, shape=(1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[0.06710888, 0.06710888],[0.06710888, 0.06710888]]]]]]]]], dtype=float32)>],[<tf.Tensor: id=206, shape=(1, 1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[[0.0536871, 0.0536871],[0.0536871, 0.0536871]]]]]]]]]], dtype=float32)>],[<tf.Tensor: id=208, shape=(1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2), dtype=float32, numpy=array([[[[[[[[[[[0.04294968, 0.04294968],[0.04294968, 0.04294968]]]]]]]]]]], dtype=float32)>]]>>> norm = list(map(lambda x:tf.norm(x).numpy(),val))>>> norm[0.8, 0.64000005, 0.512, 0.40960002, 0.32768002, 0.26214403, 0.20971523, 0.16777219, 0.13421775, 0.107374206, 0.08589937]>>> plt.plot(range(1,12),norm)[<matplotlib.lines.Line2D object at 0x000002577AACD888>]>>> plt.show()

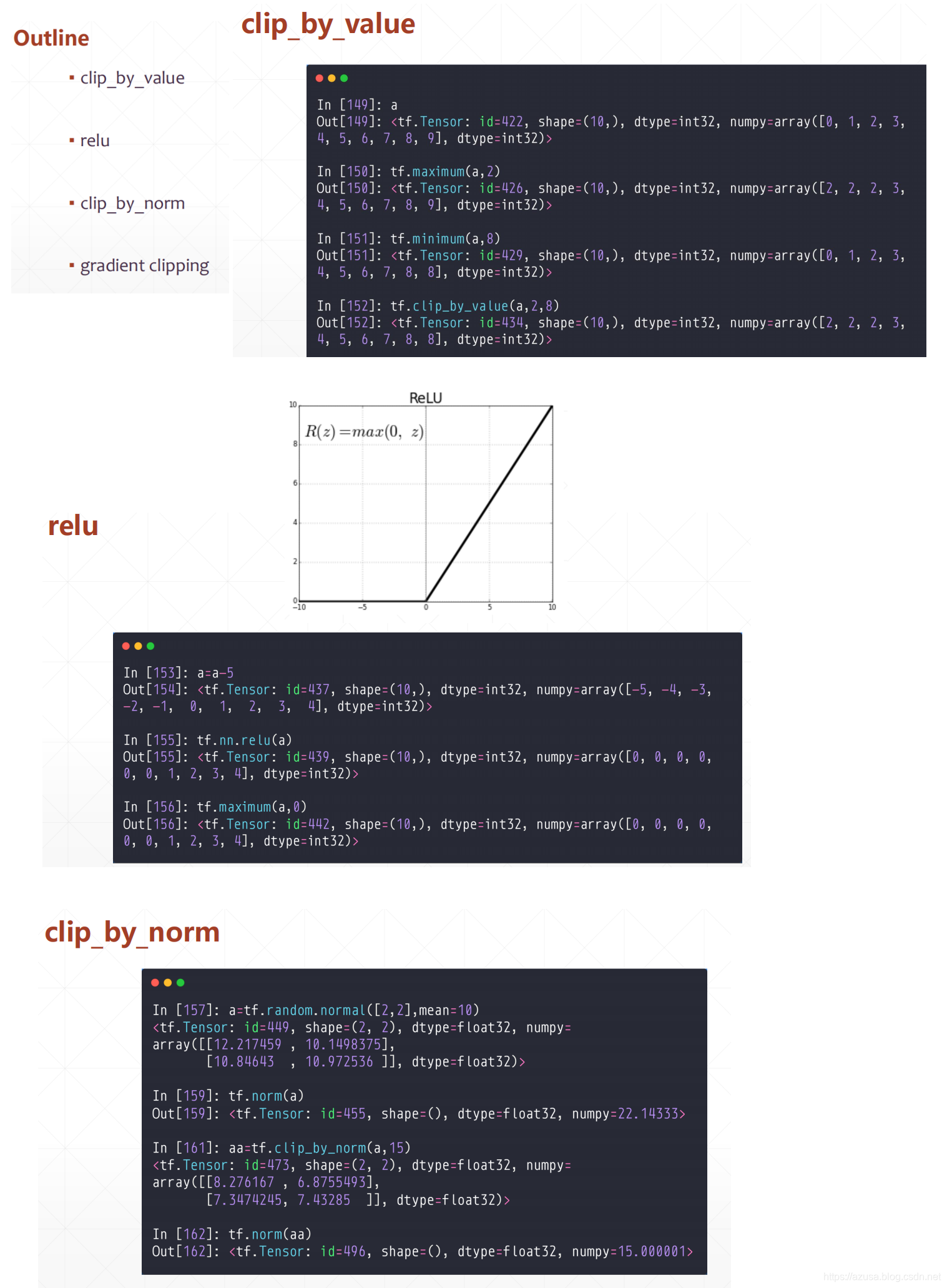
梯度裁剪(clip_by_value、clip_by_norm、clip_by_global_norm)
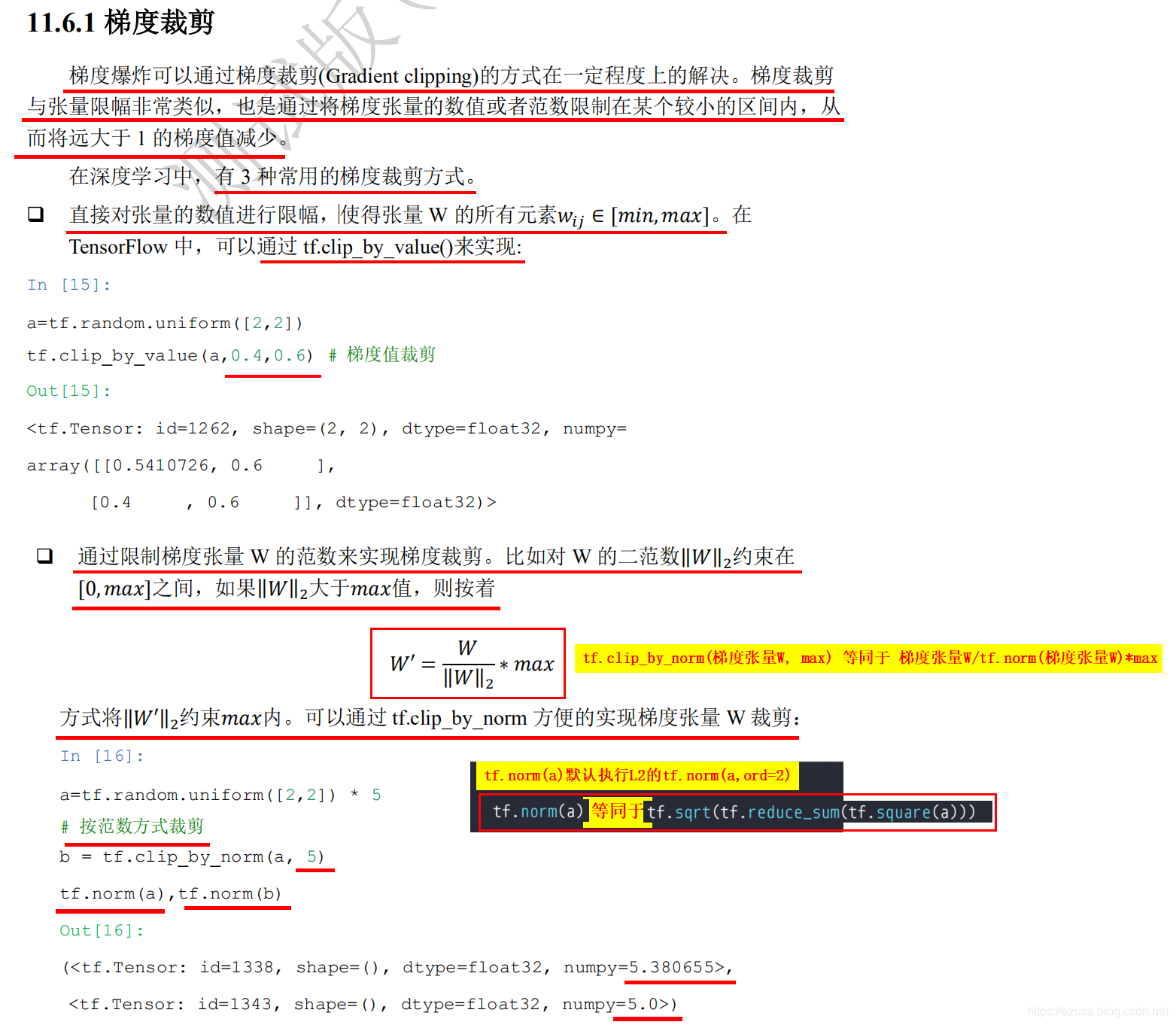
>>> a=tf.random.uniform([2,2]) * 5>>> a<tf.Tensor: id=356, shape=(2, 2), dtype=float32, numpy=array([[1.5947735, 2.6630645],[3.2025905, 3.669492 ]], dtype=float32)>>>> tf.norm(a)<tf.Tensor: id=361, shape=(), dtype=float32, numpy=5.7755494>>>> # 按范数方式裁剪... b = tf.clip_by_norm(a, 5) #tf.clip_by_norm(梯度张量W, max) 等同于 梯度张量W/tf.norm(梯度张量W)*max>>> b<tf.Tensor: id=378, shape=(2, 2), dtype=float32, numpy=array([[1.3806249, 2.3054643],[2.772542 , 3.176747 ]], dtype=float32)>>>> tf.norm(b)<tf.Tensor: id=383, shape=(), dtype=float32, numpy=5.0>>>> a1 = a/tf.norm(a)*5 #梯度张量W/tf.norm(梯度张量W)*max 等同于 tf.clip_by_norm(梯度张量W, max)>>> tf.norm(a1)<tf.Tensor: id=409, shape=(), dtype=float32, numpy=5.0000005>
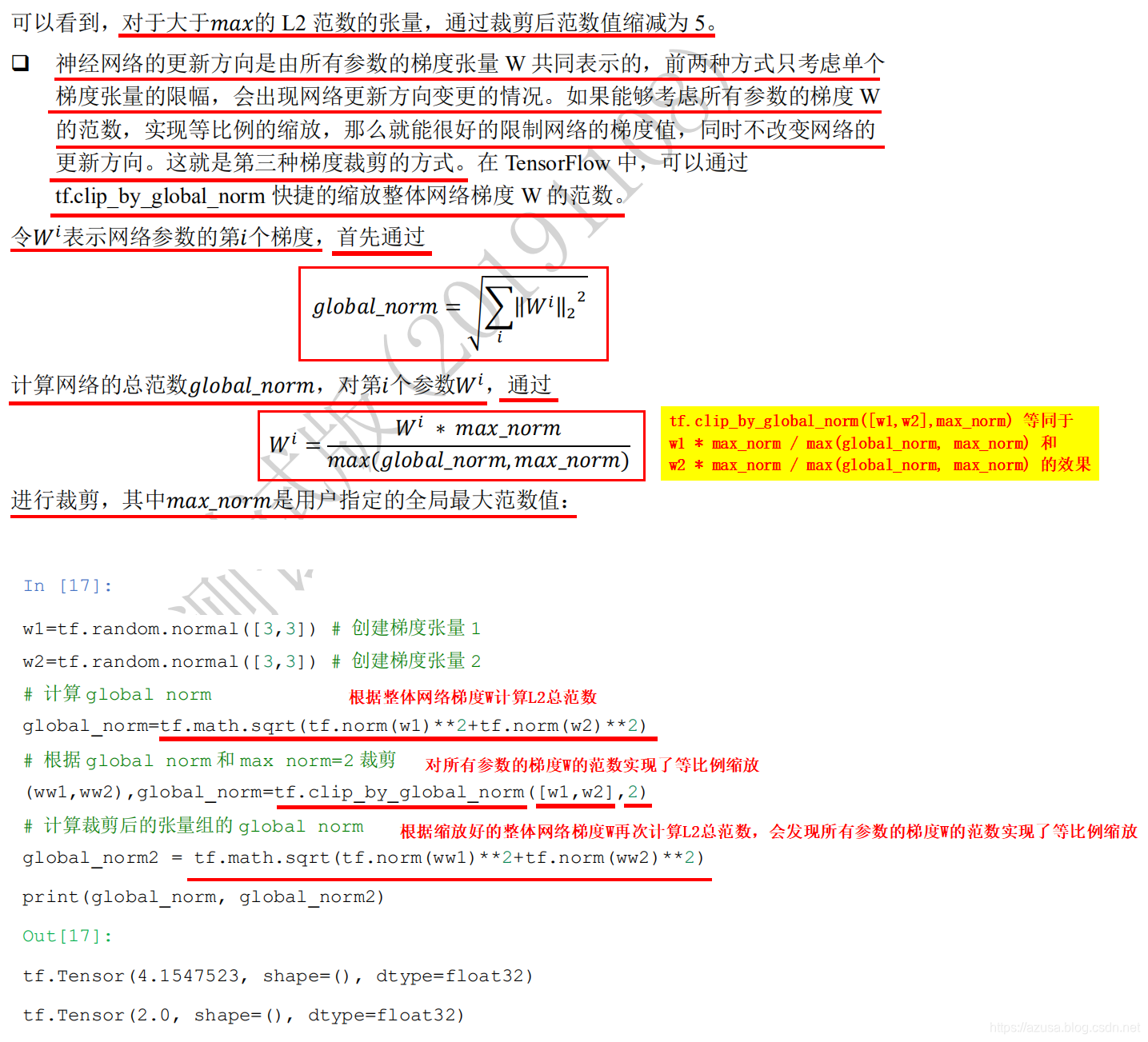
>>> import tensorflow as tf>>> w1=tf.random.normal([3,3]) # 创建梯度张量 1>>> w2=tf.random.normal([3,3]) # 创建梯度张量 2>>> w1<tf.Tensor: id=480, shape=(3, 3), dtype=float32, numpy=array([[-0.6576707 , -0.90442616, 0.34582302],[-1.7328235 , -2.1596272 , 0.4980505 ],[-0.05848425, 0.3528551 , 0.11080291]], dtype=float32)>>>> w2<tf.Tensor: id=486, shape=(3, 3), dtype=float32, numpy=array([[ 0.08453857, -0.2454122 , -0.67583424],[ 0.32974792, -1.3895415 , -0.3052706 ],[-0.37487552, -0.9419025 , -0.86943924]], dtype=float32)>>>> # 计算“还没实现等比例缩放的”所有参数的梯度W的范数global_norm... global_norm = tf.math.sqrt(tf.norm(w1)**2+tf.norm(w2)**2)>>> global_norm<tf.Tensor: id=502, shape=(), dtype=float32, numpy=3.7236474>>>> # 根据 max_norm=2 裁剪,返回“对所有参数的梯度W的范数实现了等比例缩放的新的”梯度W 和 原有的“还没实现等比例缩放的”所有参数的梯度W的范数global_norm... (ww1,ww2),global_norm = tf.clip_by_global_norm([w1,w2],2)>>> ww1<tf.Tensor: id=522, shape=(3, 3), dtype=float32, numpy=array([[-0.35324 , -0.4857743 , 0.18574423],[-0.93071294, -1.1599525 , 0.2675068 ],[-0.03141234, 0.18952121, 0.0595131 ]], dtype=float32)>>>> ww2<tf.Tensor: id=523, shape=(3, 3), dtype=float32, numpy=array([[ 0.04540632, -0.1318128 , -0.3629958 ],[ 0.17711017, -0.74633354, -0.16396321],[-0.20134856, -0.5059032 , -0.46698257]], dtype=float32)>>>> global_norm<tf.Tensor: id=510, shape=(), dtype=float32, numpy=3.7236474>>>> # 计算"实现了等比例缩放(裁剪后)的"所有参数的梯度W的范数global_norm... global_norm2 = tf.math.sqrt(tf.norm(ww1)**2+tf.norm(ww2)**2)>>> print(global_norm, global_norm2) #tf.Tensor(4.073522, shape=(), dtype=float32) tf.Tensor(2.0000002, shape=(), dtype=float32)>>> # 计算“还没实现等比例缩放的”所有参数的梯度W的范数global_norm... global_norm = tf.math.sqrt(tf.norm(w1)**2+tf.norm(w2)**2)>>> global_norm<tf.Tensor: id=502, shape=(), dtype=float32, numpy=3.7236474>>>> max_norm = 2#tf.clip_by_global_norm([w1,w2],max_norm) 等同于 w1 * max_norm / max(global_norm, max_norm) 和 w2 * max_norm / max(global_norm, max_norm) 的效果>>> ww1 = w1 * max_norm / max(global_norm, max_norm)>>> ww2 = w2 * max_norm / max(global_norm, max_norm)>>> ww1<tf.Tensor: id=586, shape=(3, 3), dtype=float32, numpy=array([[-0.35324004, -0.48577434, 0.18574424],[-0.930713 , -1.1599526 , 0.2675068 ],[-0.03141235, 0.18952121, 0.05951311]], dtype=float32)>>>> ww2<tf.Tensor: id=591, shape=(3, 3), dtype=float32, numpy=array([[ 0.04540633, -0.13181281, -0.36299583],[ 0.17711018, -0.74633354, -0.16396323],[-0.20134856, -0.5059032 , -0.4669826 ]], dtype=float32)>>>> global_norm2 = tf.math.sqrt(tf.norm(ww1)**2+tf.norm(ww2)**2)>>> global_norm2<tf.Tensor: id=607, shape=(), dtype=float32, numpy=1.9999998>>>> import tensorflow as tf>>> w1=tf.random.normal([3,3])>>> w2=tf.random.normal([3,3])>>> w1<tf.Tensor: id=5, shape=(3, 3), dtype=float32, numpy=array([[-0.3745235 , -0.54776704, -0.6978908 ],[-0.48667282, -1.9662677 , 1.2693951 ],[-1.6218463 , -1.3147658 , 1.1985897 ]], dtype=float32)>#tf.norm(a)默认为执行L2范数的tf.norm(a. ord=2),等同于tf.sqrt(tf.reduce_sum(tf.square(a)))#计算裁剪前的网络参数θ的总范数global_norm:所有裁剪前的网络参数θ的L2范数tf.norm(θ)的平方和,然后开方sqrt>>> global_norm=tf.math.sqrt(tf.norm(w1)**2+tf.norm(w2)**2)>>> global_norm #4.7265425<tf.Tensor: id=27, shape=(), dtype=float32, numpy=4.7265425>#通过tf.clip_by_global_norm([θ],MAX_norm)裁剪后,网络参数的梯度组的总范数缩减到MAX_norm=2#clip_by_global_norm返回裁剪后的List[参数θ] 和 裁剪前的梯度总范数和global_norm 的2个对象>>> (ww1,ww2),global_norm=tf.clip_by_global_norm([w1,w2],2) #梯度裁剪一般在计算出梯度后、梯度更新之前进行>>> ww1<tf.Tensor: id=47, shape=(3, 3), dtype=float32, numpy=array([[-0.15847673, -0.2317834 , -0.29530713],[-0.20593184, -0.832011 , 0.53713477],[-0.6862717 , -0.556333 , 0.50717396]], dtype=float32)>>>> ww2<tf.Tensor: id=48, shape=(3, 3), dtype=float32, numpy=array([[ 0.03117203, -0.7264457 , 0.32293826],[ 0.5894358 , 0.87403387, 0.04680141],[ 0.0015509 , 0.15240058, 0.05759645]], dtype=float32)>>>> global_norm<tf.Tensor: id=35, shape=(), dtype=float32, numpy=4.7265425>#计算裁剪后的网络参数θ的总范数global_norm:所有裁剪后的网络参数θ的L2范数tf.norm(θ)的平方和,然后开方sqrt>>> global_norm2 = tf.math.sqrt(tf.norm(ww1)**2+tf.norm(ww2)**2)>>> global_norm2<tf.Tensor: id=64, shape=(), dtype=float32, numpy=1.9999998>>>> print(global_norm, global_norm2)tf.Tensor(4.7265425, shape=(), dtype=float32) tf.Tensor(1.9999998, shape=(), dtype=float32)

import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import datasets, layers, optimizersimport osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'print(tf.__version__)(x, y), _ = datasets.mnist.load_data()x = tf.convert_to_tensor(x, dtype=tf.float32) / 50. #标准化/归一化y = tf.convert_to_tensor(y)y = tf.one_hot(y, depth=10) #真实标签one-hot化print('x:', x.shape, 'y:', y.shape)#构建批量大小和epoch训练次数train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128).repeat(30)x,y = next(iter(train_db)) #获取生成器并调用next遍历第一个批量大小的数据print('sample:', x.shape, y.shape)# print(x[0], y[0])def main():# 784 => 512 第一层权重[输入神经元数, 输出神经元数],偏置[输出神经元数]w1, b1 = tf.Variable(tf.random.truncated_normal([784, 512], stddev=0.1)), tf.Variable(tf.zeros([512]))# 512 => 256 第二层权重[输入神经元数, 输出神经元数],偏置[输出神经元数]w2, b2 = tf.Variable(tf.random.truncated_normal([512, 256], stddev=0.1)), tf.Variable(tf.zeros([256]))# 256 => 10 第三层权重[输入神经元数, 输出神经元数],偏置[输出神经元数]w3, b3 = tf.Variable(tf.random.truncated_normal([256, 10], stddev=0.1)), tf.Variable(tf.zeros([10]))optimizer = optimizers.SGD(lr=0.01) #SGD随机梯度下降优化算法#每次遍历训练集生成器的一个批量大小数据for step, (x,y) in enumerate(train_db):# [b, 28, 28] => [b, 784] 展平x = tf.reshape(x, (-1, 784))#构建梯度记录环境with tf.GradientTape() as tape:# layer1.h1 = x @ w1 + b1h1 = tf.nn.relu(h1)# layer2h2 = h1 @ w2 + b2h2 = tf.nn.relu(h2)# outputout = h2 @ w3 + b3# out = tf.nn.relu(out)# compute loss# [b, 10] - [b, 10] 均方差mse = mean(sum(y-out)^2) 预测值与真实值之差的平方的平均值loss = tf.square(y-out)# [b, 10] => [b] 计算每个样本的平均误差loss = tf.reduce_mean(loss, axis=1)# [b] => scalar 总误差除以样本数loss = tf.reduce_mean(loss)#1.求导,tape.gradient(y,[参数θ])求参数θ相对于y的梯度信息# dy_dw = tape.gradient(y, [w])#2.通过tape.gradient(loss,[参数θ])函数求得网络参数θ的梯度信息# grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])# compute gradients。根据loss 求w1, w2, w3, b1, b2, b3的梯度值 用于后面继续更新对应的模型参数θ。grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])# print('==before==')# for g in grads: #计算所有裁剪前的网络参数θ的梯度值的L2范数tf.norm(a),等同于tf.norm(a. ord=2)、tf.sqrt(tf.reduce_sum(tf.square(a)))# print(tf.norm(g)) #tf.norm(a)默认为执行L2范数tf.norm(a. ord=2),等同于tf.sqrt(tf.reduce_sum(tf.square(a)))#通过tf.clip_by_global_norm([θ],MAX_norm)裁剪后,网络参数的梯度组的总范数缩减到MAX_norm=15#clip_by_global_norm返回裁剪后的List[参数θ] 和 裁剪前的梯度总范数和global_norm 的2个对象grads, _ = tf.clip_by_global_norm(grads, 15) #梯度裁剪一般在计算出梯度后、梯度更新之前进行# print('==after==')# for g in grads: #计算所有裁剪后的网络参数θ的梯度值的L2范数tf.norm(a),等同于tf.norm(a. ord=2)、tf.sqrt(tf.reduce_sum(tf.square(a)))# print(tf.norm(g)) #tf.norm(a)默认为执行L2的tf.norm(a. ord=2),等同于tf.sqrt(tf.reduce_sum(tf.square(a)))#优化器规则,根据 模型参数θ = θ - lr * grad 更新网络参数# update w' = w - lr*gradoptimizer.apply_gradients(zip(grads, [w1, b1, w2, b2, w3, b3]))if step % 100 == 0:print(step, 'loss:', float(loss))if __name__ == '__main__':main()W = tf.ones([2,2]) #任意创建某矩阵eigenvalues = tf.linalg.eigh(W)[0] # 计算特征值eigenvaluesval = [W]# 矩阵相乘n次方for i in range(10):val.append([val[-1]@W])# 计算L2范数norm = list(map(lambda x:tf.norm(x).numpy(),val))plt.plot(range(1,12),norm)plt.xlabel('n times')plt.ylabel('L2-norm')plt.savefig('w_n_times_1.svg')W = tf.ones([2,2])*0.4 # 任意创建某矩阵eigenvalues = tf.linalg.eigh(W)[0] # 计算特征值print(eigenvalues)val = [W]for i in range(10):val.append([val[-1]@W])norm = list(map(lambda x:tf.norm(x).numpy(),val))plt.plot(range(1,12),norm)plt.xlabel('n times')plt.ylabel('L2-norm')plt.savefig('w_n_times_0.svg')a=tf.random.uniform([2,2])tf.clip_by_value(a,0.4,0.6) # 梯度值裁剪a=tf.random.uniform([2,2]) * 5# 按范数方式裁剪b = tf.clip_by_norm(a, 5)tf.norm(a),tf.norm(b)w1=tf.random.normal([3,3]) # 创建梯度张量1w2=tf.random.normal([3,3]) # 创建梯度张量2# 计算global normglobal_norm=tf.math.sqrt(tf.norm(w1)**2+tf.norm(w2)**2)# 根据global norm和max norm=2裁剪(ww1,ww2),global_norm=tf.clip_by_global_norm([w1,w2],2)# 计算裁剪后的张量组的global normglobal_norm2 = tf.math.sqrt(tf.norm(ww1)**2+tf.norm(ww2)**2)print(global_norm, global_norm2)with tf.GradientTape() as tape:logits = model(x) # 前向传播loss = criteon(y, logits) # 误差计算# 计算梯度值grads = tape.gradient(loss, model.trainable_variables)grads, _ = tf.clip_by_global_norm(grads, 25) # 全局梯度裁剪# 利用裁剪后的梯度张量更新参数optimizer.apply_gradients(zip(grads, model.trainable_variables))

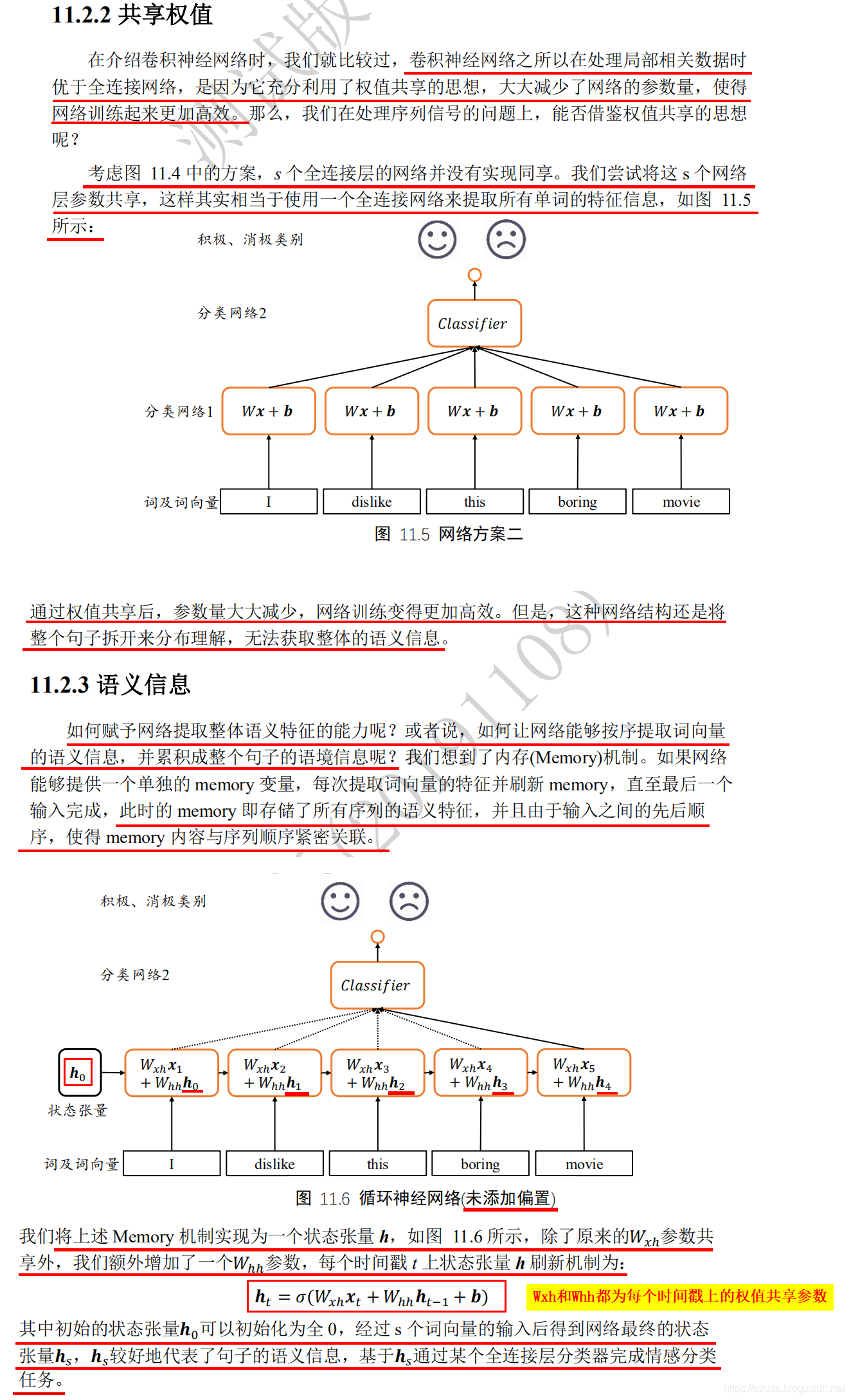
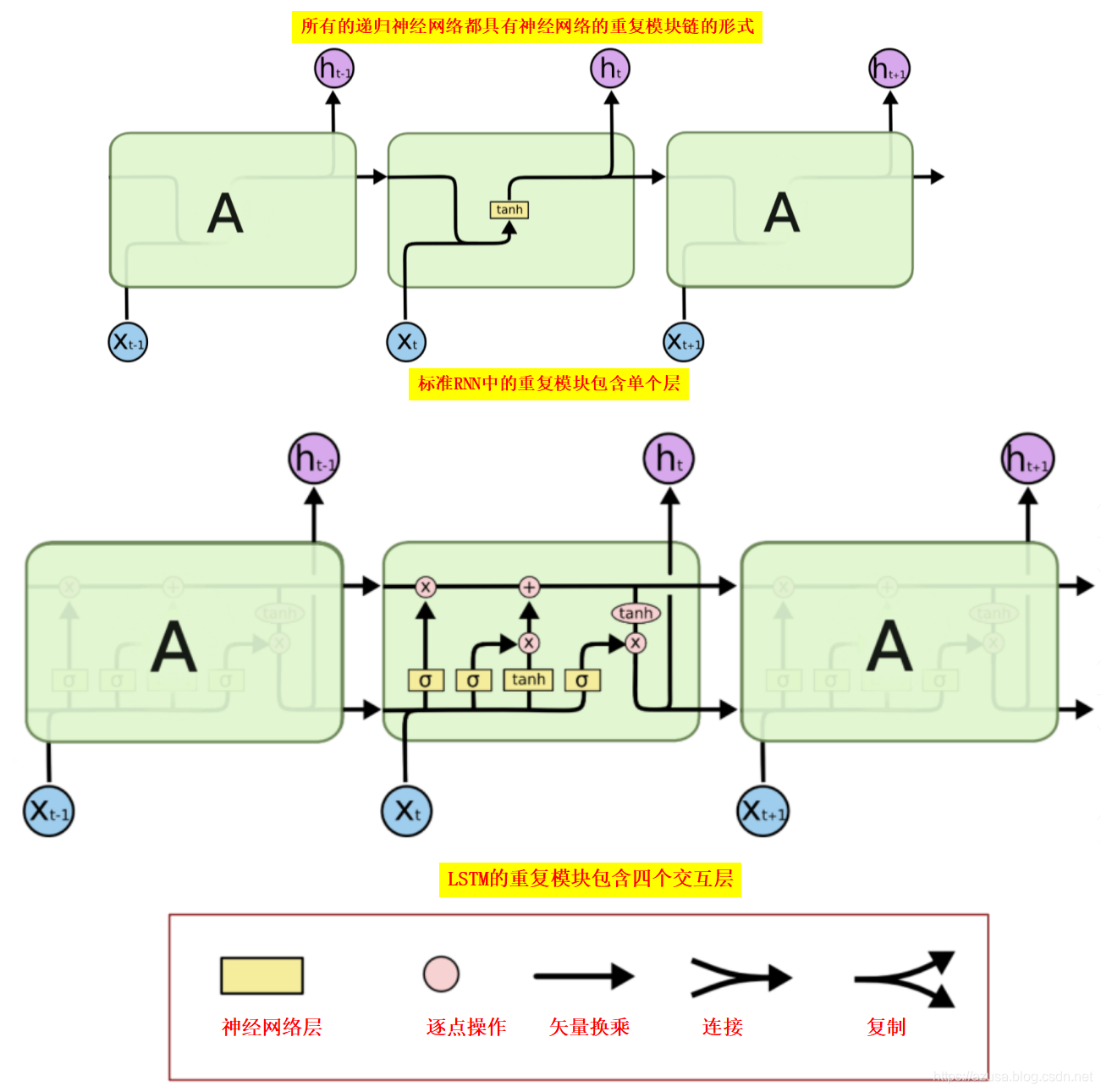
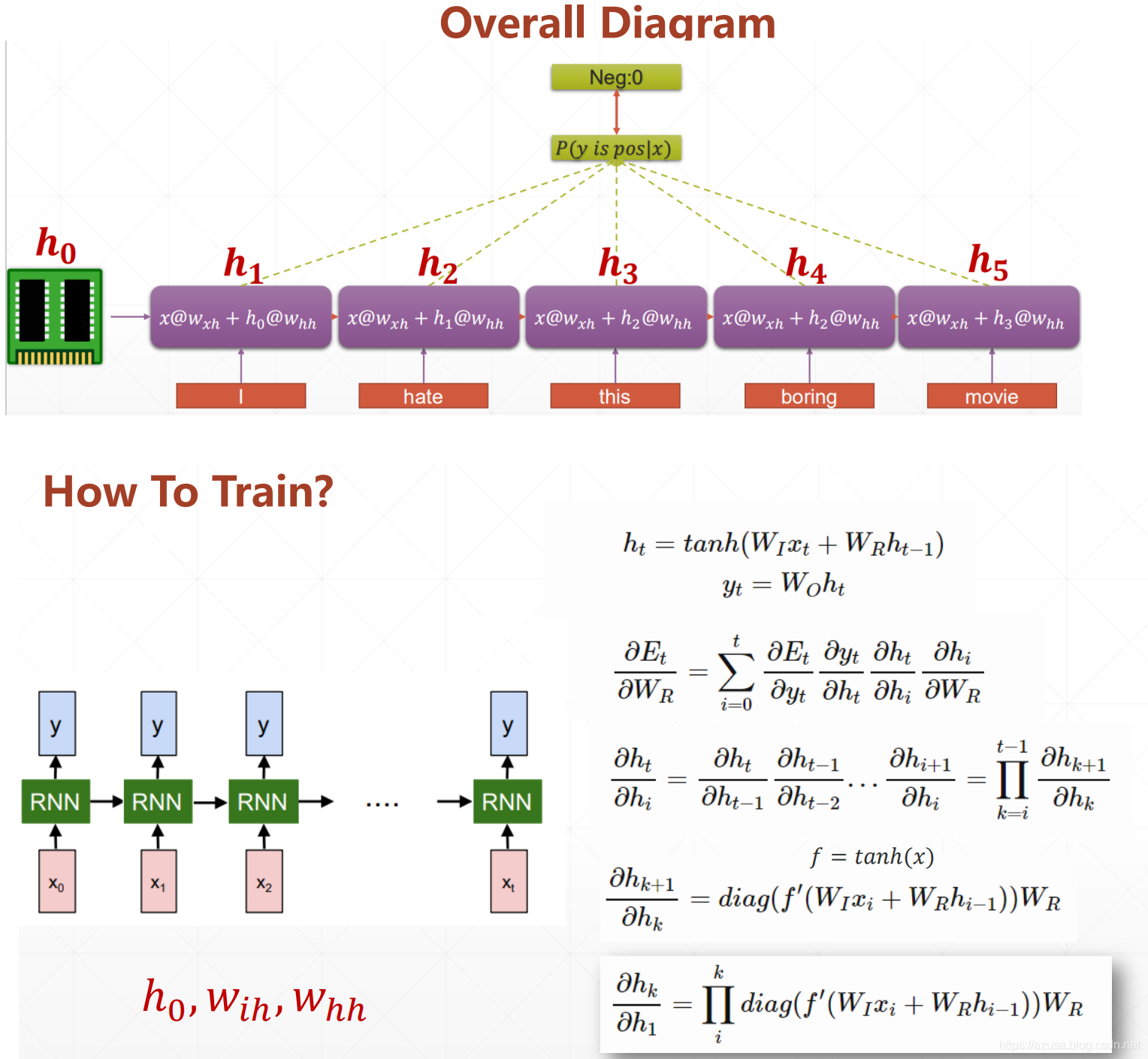
各种循环神经网络
" class="reference-link">SimpleRNNCell
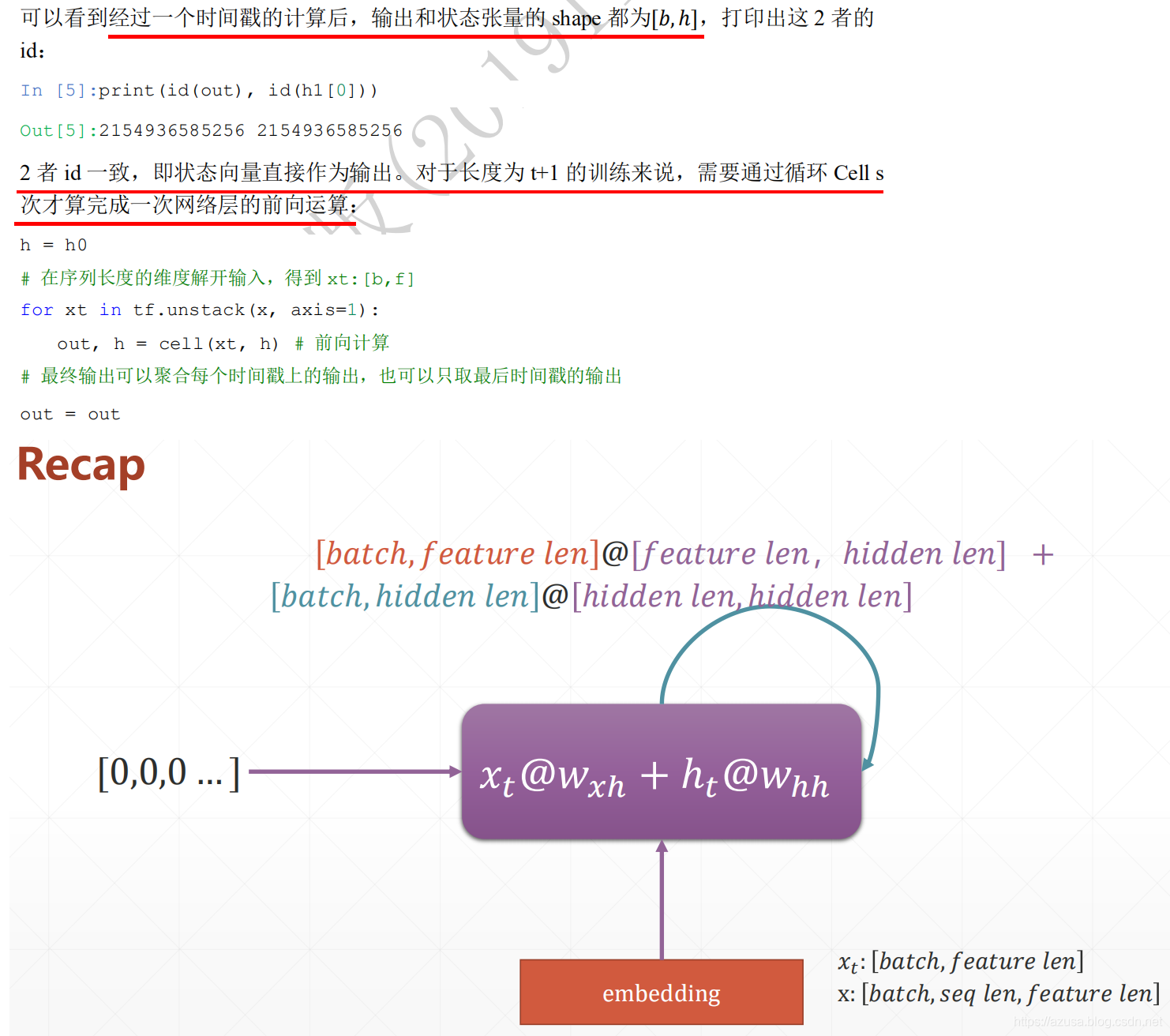
import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import datasets, layers, optimizers#状态向量特征长度h=3cell = layers.SimpleRNNCell(3)#不需要指定序列长度s,默认为None即可。时间戳t的输入特征长度f/词向量特征长度f=4cell.build(input_shape=(None,4))#SimpleRNNCell内部维护了3个张量,kernel为Wxh(时间戳t的输入特征长度f, 状态向量特征长度h),shape为(4, 3),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h),shape为(3, 3),bias为偏置b(状态向量特征长度h,),shape为(3,)#前向计算:ht = Wxh * Xt + Whh * ht-1 + b = (4, 3) * Xt + (3, 3) * ht-1 + (3,)cell.trainable_variables#[<tf.Variable 'kernel:0' shape=(4, 3) dtype=float32, numpy=# array([[ 0.08301067, -0.46076387, 0.15347064],# [-0.1890313 , 0.60186946, -0.85642815],# [ 0.5622045 , -0.07674742, -0.80009407],# [ 0.5321919 , -0.44575736, -0.3680237 ]], dtype=float32)>,# <tf.Variable 'recurrent_kernel:0' shape=(3, 3) dtype=float32, numpy=# array([[ 0.9972923 , 0.07062273, -0.02049942],# [-0.06413236, 0.69885963, -0.7123779 ],# [ 0.03598386, -0.71176374, -0.7014966 ]], dtype=float32)>,# <tf.Variable 'bias:0' shape=(3,) dtype=float32, numpy=# array([0., 0., 0.], dtype=float32)>]#初始化状态向量h0(批量大小b,状态向量特征长度h),shape=(4, 64)h0 = [tf.zeros([4, 64])]#输入序列数据(b,s,f),即序列数量b=4,序列长度s=80,时间戳t的输入特征长度f/词向量特征长度f=100,shape=(4, 80, 100)x = tf.random.normal([4, 80, 100])#按 x[:,i,:] 或 for xt in tf.unstack(x, axis=1) 方式可以从[序列数量b, 序列长度s, 词向量特征长度f]中获取 s个[序列数量b, 词向量特征长度f],#即一个序列中有N个单词数,那么就遍历N次,每次遍历同时获取批量多个序列中的同一个时间戳上的单词,当遍历次数等于序列长度s时才算完成一次网络层的前向计算#即每次需要把(批量大小b, 词向量特征长度f)输入到SimpleRNNCell中,序列数量b=4,输入特征f=100,shape=(4, 100)#即每次输入数据到SimpleRNNCell中时,输入所有序列数据中同一个时间戳t的数据,对于长度为t+1的训练来说,需要遍历等同于序列长度s的次数才算完成一次网络层的前向计算xt = x[:,0,:] #取第一个时间戳的输入x0(4, 100) 即xt为(批量大小b, 词向量特征长度f)# 构建输入特征 f=100,序列长度 s=80,状态向量长度h=64 的Cellcell = layers.SimpleRNNCell(64)#SimpleRNNCell内部维护了3个张量,kernel为Wxh(时间戳t的输入特征长度f, 状态向量特征长度h),shape为(100, 64),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h),shape为(64, 64),bias为偏置b(状态向量特征长度h,),shape为(64,)#前向计算,输入批量序列中同一个时间戳t的字符数据xt和状态向量h0:ht = Wxh * Xt + Whh * ht-1 + b = (100, 64) * (4, 100) + (64, 64) * (4, 64) + (64,)#对于长度为t+1的训练来说,需要遍历等同于序列长度s的次数才算完成一次网络层的前向计算out, h1 = cell(xt, h0)#输出ot和状态向量ht的shape都为(批量大小b, 状态向量特征长度h),即(4, 64)。#并且两者id一致,代表两者都指向为同一个内存空间的变量值,即状态向量ht直接作为输出ot。print(out.shape, h1[0].shape) #(4, 64) (4, 64)print(id(out), id(h1[0])) #1863500704760 1863500704760h = h0# 在序列长度的维度解开输入,得到 xt:[批量大小b, 时间戳t的输入特征长度f]# 即一个序列中有N个单词数,那么就遍历N次,每次遍历同时获取批量多个序列中的同一个时间戳上的单词,当遍历次数等于序列长度s时才算完成一次网络层的前向计算# 对于长度为t+1的训练来说,需要遍历等同于序列长度s的次数才算完成一次网络层的前向计算for xt in tf.unstack(x, axis=1):# 前向计算,输入批量序列中同一个时间戳t的字符数据xt和状态向量h:ht = Wxh * Xt + Whh * ht-1 + bout, h = cell(xt, h)# 最终输出可以聚合每个时间戳上的输出,也可以只取最后时间戳的输出# 最终输出可以把每个时间戳t上的输出ot进行聚合再输出,或者只输出最后一个时间戳t的输出otout = out


多层SimpleRNNCell网络

import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import datasets, layers, optimizersx = tf.random.normal([4,80,100])# 构建 2 个 Cell,先 cell0,后 cell1cell0 = layers.SimpleRNNCell(64)cell1 = layers.SimpleRNNCell(64)h0 = [tf.zeros([4,64])] # cell0 的初始状态向量h1 = [tf.zeros([4,64])] # cell1 的初始状态向量for xt in tf.unstack(x, axis=1):print("xt:",xt.shape) #(4, 100) [序列数量b, 词向量特征长度f]#第一层RNN 每次接收的是 [序列数量b, 词向量特征长度f]的序列数据,也即是批量序列数据中同一个时间戳的单词的词向量特征长度f#第二层RNN 每次接收的是 第一层RNN输出的 [序列数量b, 状态向量特征长度h],也即是每个时间戳上的网络输出Ot,而网络输出Ot可以是直接等于状态向量ht,#或者也可以是对状态向量ht做一个线性变换Ot=Who*ht得到每个时间戳上的网络输出Ot。# xtw 作为输入,输出为 out0out0, h0 = cell0(xt, h0)print("out0:",out0.shape, h0[0].shape) #(4, 64) (4, 64) [序列数量b, 状态向量特征长度h]# 上一个 cell 的输出 out0 作为本 cell 的输入out1, h1 = cell1(out0, h1)print("out1:",out1.shape, h1[0].shape) #(4, 64) (4, 64) [序列数量b, 状态向量特征长度h]


import osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'import tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layerstf.random.set_seed(22)np.random.seed(22)assert tf.__version__.startswith('2.')batchsz = 128total_words = 10000max_review_len = 80embedding_len = 100(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)# x_train:[b, 80]# x_test: [b, 80]x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):def __init__(self, units):super(MyRNN, self).__init__()# [b, 64]self.state0 = [tf.zeros([batchsz, units])]self.state1 = [tf.zeros([batchsz, units])]# 将文本转换为嵌入表示# [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# [b, 80, 100] , h_dim: 64# RNN: cell1 ,cell2, cell3# SimpleRNNself.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)# fc, [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = layers.Dense(1)def call(self, inputs, training=None):"""net(x) net(x, training=True) :train modenet(x, training=False): test:param inputs: [b, 80]:param training::return:"""# [b, 80]x = inputs# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute# [b, 80, 100] => [b, 64]state0 = self.state0state1 = self.state1for word in tf.unstack(x, axis=1): # word: [b, 100]# h1 = x*wxh+h0*whh# out0: [b, 64]out0, state0 = self.rnn_cell0(word, state0, training)# out1: [b, 64]out1, state1 = self.rnn_cell1(out0, state1, training)# out: [b, 64] => [b, 1]x = self.outlayer(out1)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64epochs = 4model = MyRNN(units)model.compile(optimizer = keras.optimizers.Adam(0.001),loss = tf.losses.BinaryCrossentropy(),metrics=['accuracy'], experimental_run_tf_function=False)model.fit(db_train, epochs=epochs, validation_data=db_test)model.evaluate(db_test)if __name__ == '__main__':main()import osos.environ['TF_CPP_MIN_LOG_LEVEL']='2'import tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layerstf.random.set_seed(22)np.random.seed(22)assert tf.__version__.startswith('2.')batchsz = 128total_words = 10000max_review_len = 80embedding_len = 100(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)# x_train:[b, 80]# x_test: [b, 80]x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):def __init__(self, units):super(MyRNN, self).__init__()# 将文本转换为嵌入表示# [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# [b, 80, 100] , h_dim: 64self.rnn = keras.Sequential([layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),layers.SimpleRNN(units, dropout=0.5, unroll=True)])# fc, [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = layers.Dense(1)def call(self, inputs, training=None):"""net(x) net(x, training=True) :train modenet(x, training=False): test:param inputs: [b, 80]:param training::return:"""# [b, 80]x = inputs# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute# x: [b, 80, 100] => [b, 64]x = self.rnn(x,training=training)# out: [b, 64] => [b, 1]x = self.outlayer(x)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64epochs = 4model = MyRNN(units)# model.build(input_shape=(4,80))# model.summary()model.compile(optimizer = keras.optimizers.Adam(0.001),loss = tf.losses.BinaryCrossentropy(),metrics=['accuracy'])model.fit(db_train, epochs=epochs, validation_data=db_test)model.evaluate(db_test)if __name__ == '__main__':main()
SimpleRNN

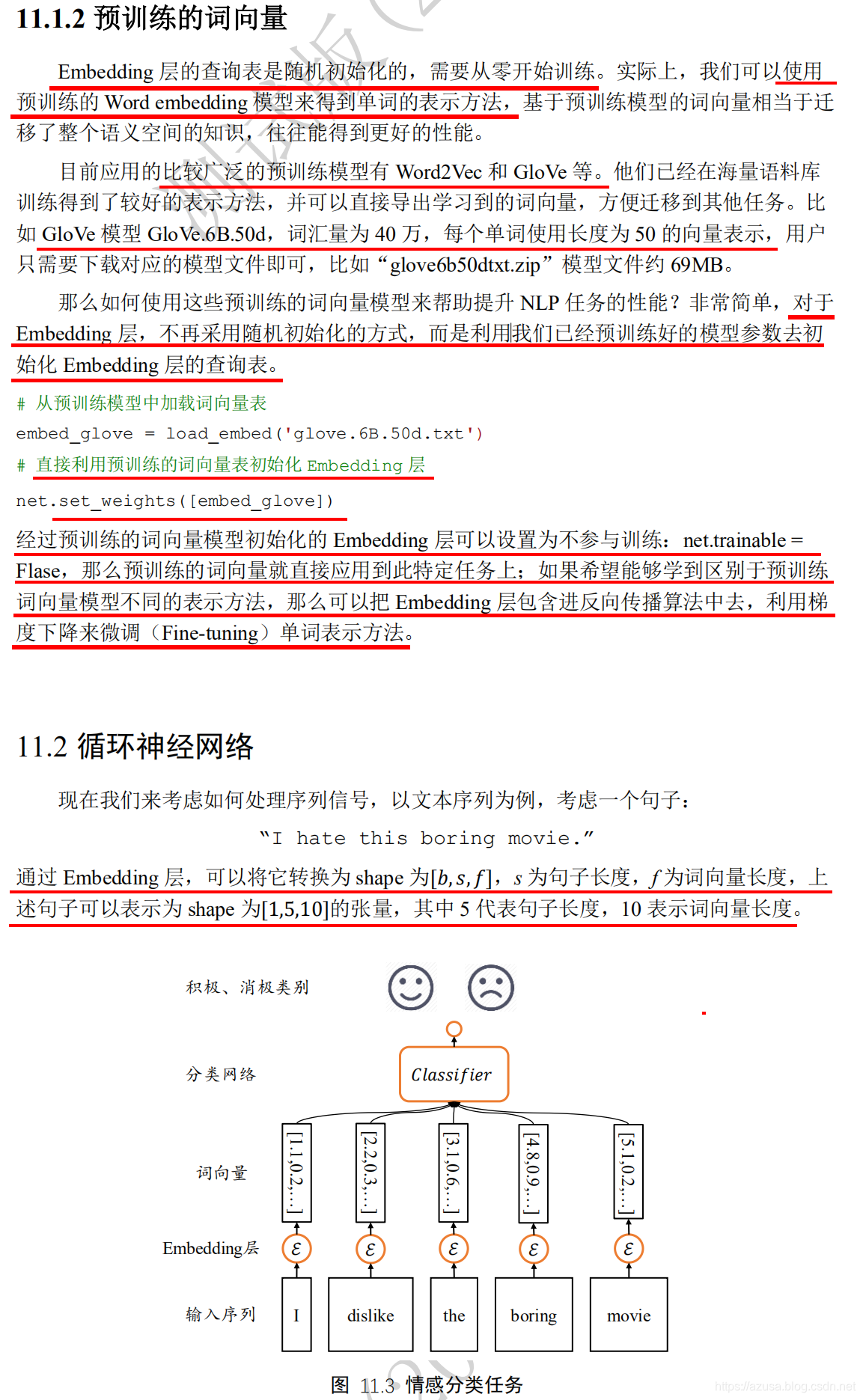
情感分类任务的网络结构



#初始化状态向量h0(批量大小b,状态向量特征长度h/units),此处即[b, 64][tf.zeros([batchsz, units])]# 词向量编码 [b, 80] => [b, 80, 100]layers.Embedding(total_words, embedding_len, input_length=max_review_len)total_words = 10000:词汇表大小input_length = max_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f,即时间戳t的输入特征长度f#状态向量特征长度h/units=64#xt为(批量大小b, 词向量特征长度f)。SimpleRNNCell内部维护了3个张量,kernel为Wxh(词向量特征长度f, 状态向量特征长度h),shape为(100, 64),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h),shape为(64, 64),bias为偏置b(状态向量特征长度h,),shape为(64,)#前向计算,输入批量序列中同一个时间戳t的字符数据xt和状态向量h0:ht = Wxh * Xt + Whh * ht-1 + b = (100, 64)*(b, 100)+(64, 64)*[b, 64]+(64,)=>[b, 64]layers.SimpleRNNCell(units, dropout=0.5)#构建分类网络,用于将 CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = layers.Dense(1)

1.按照 x[:,i,:] 或 for xt in tf.unstack(x, axis=1) 方式对[序列数量b, 序列长度s, 词向量特征长度f]数据进行遍历时,一共可以遍历出 s个[序列数量b, 词向量特征长度f],即一个序列中有N个单词数,那么就遍历N次,每次遍历同时获取批量多个序列中的同一个时间戳上的单词,当遍历次数等于序列长度s时才算完成一次网络层的前向计算。2.第一层RNN 每次接收的是 [序列数量b, 词向量特征长度f]的序列数据,也即是批量序列数据中同一个时间戳的单词的词向量特征长度f第二层RNN 每次接收的是 第一层RNN输出的 [序列数量b, 状态向量特征长度h],也即是每个时间戳上的网络输出Ot,而网络输出Ot可以是直接等于状态向量ht,或者也可以是对状态向量ht做一个线性变换Ot=Who*ht得到每个时间戳上的网络输出Ot。
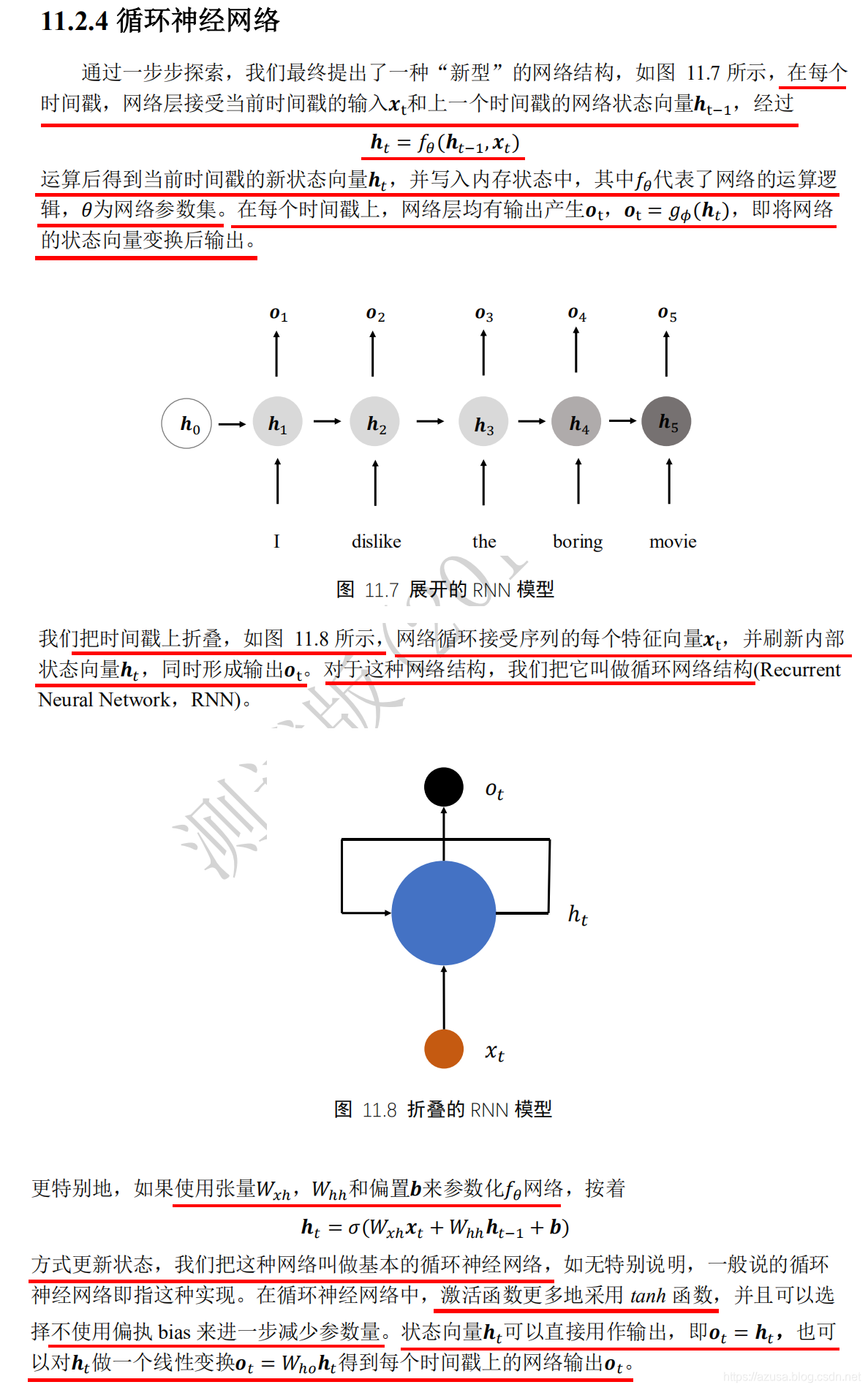
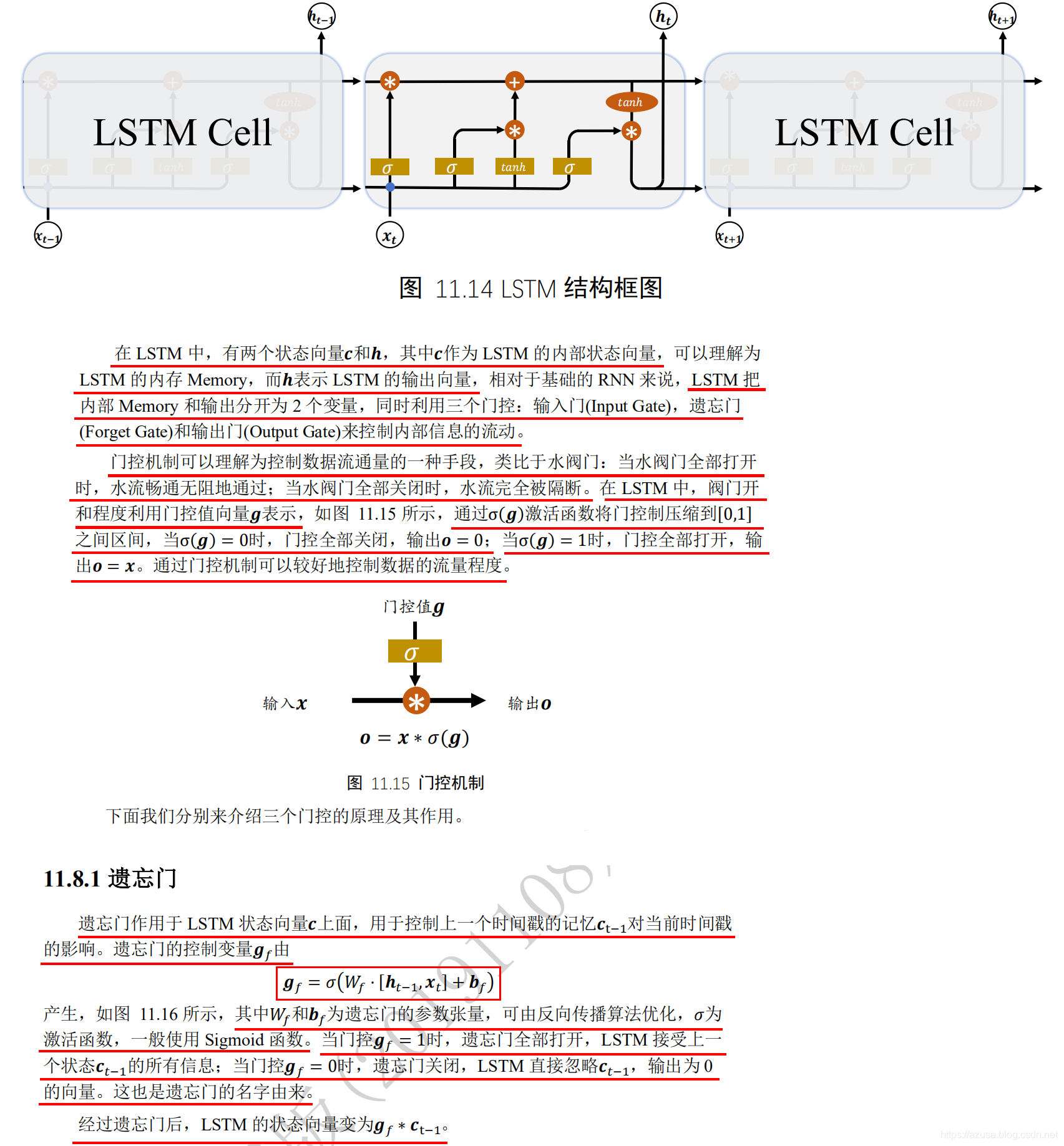
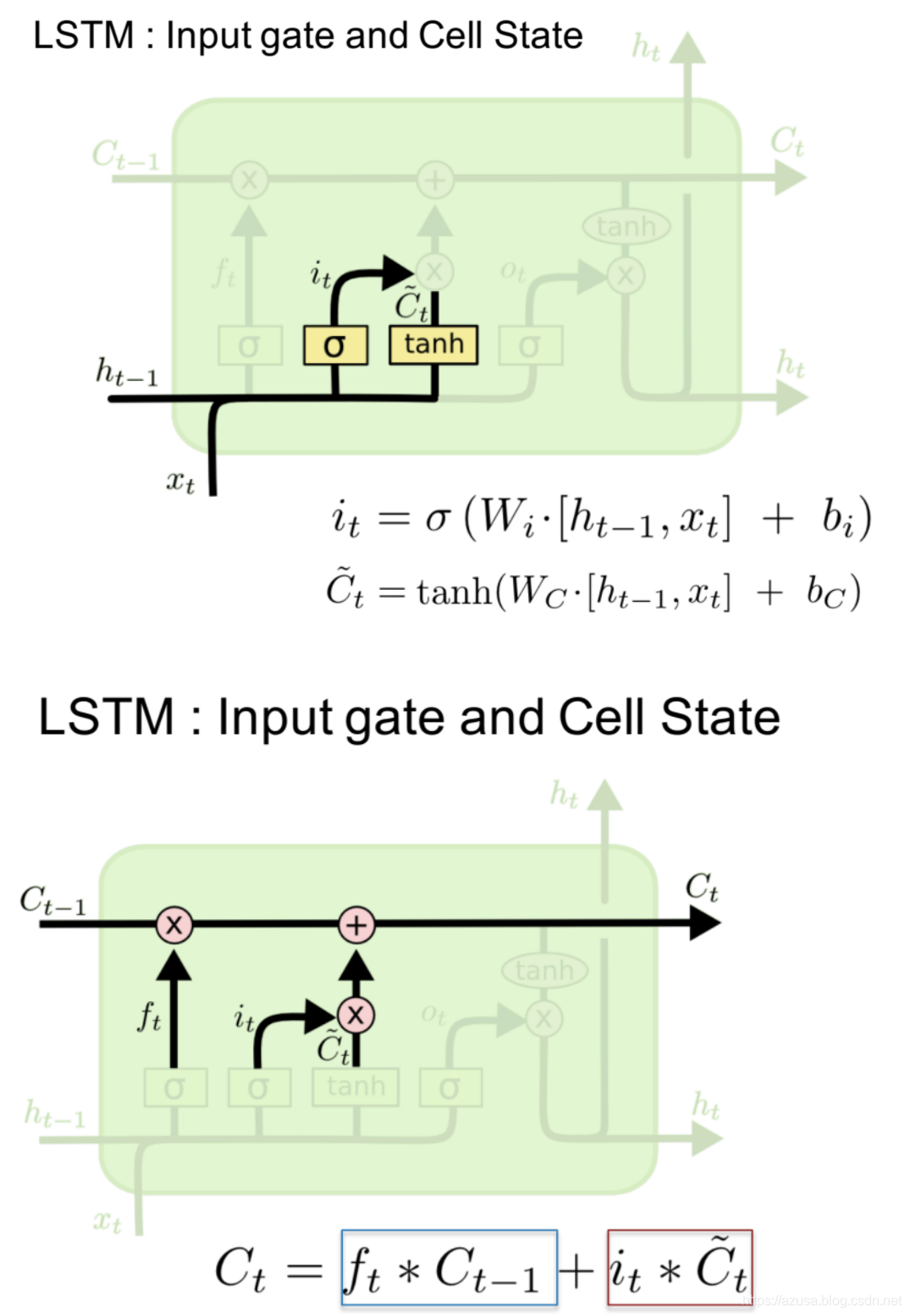
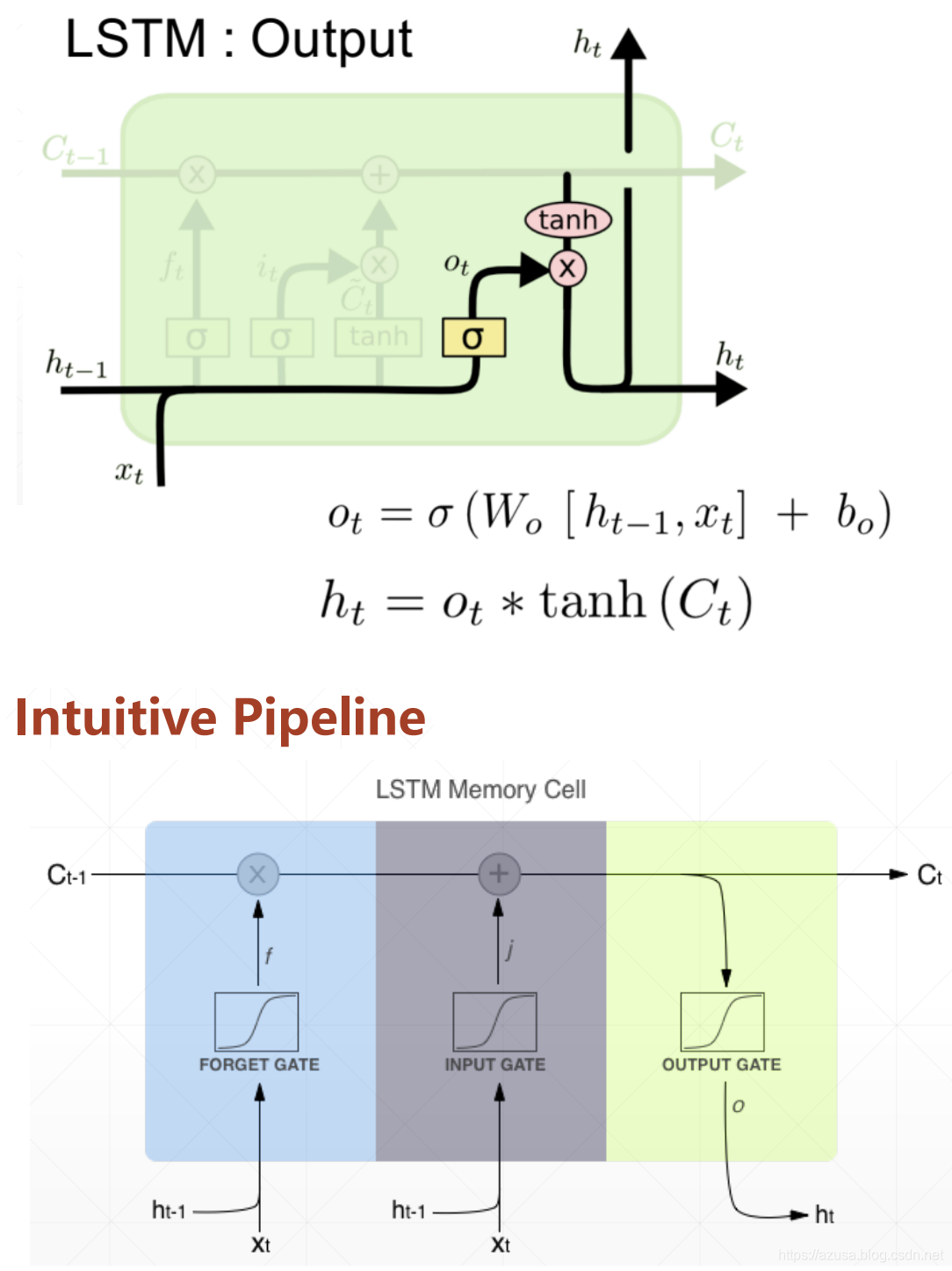
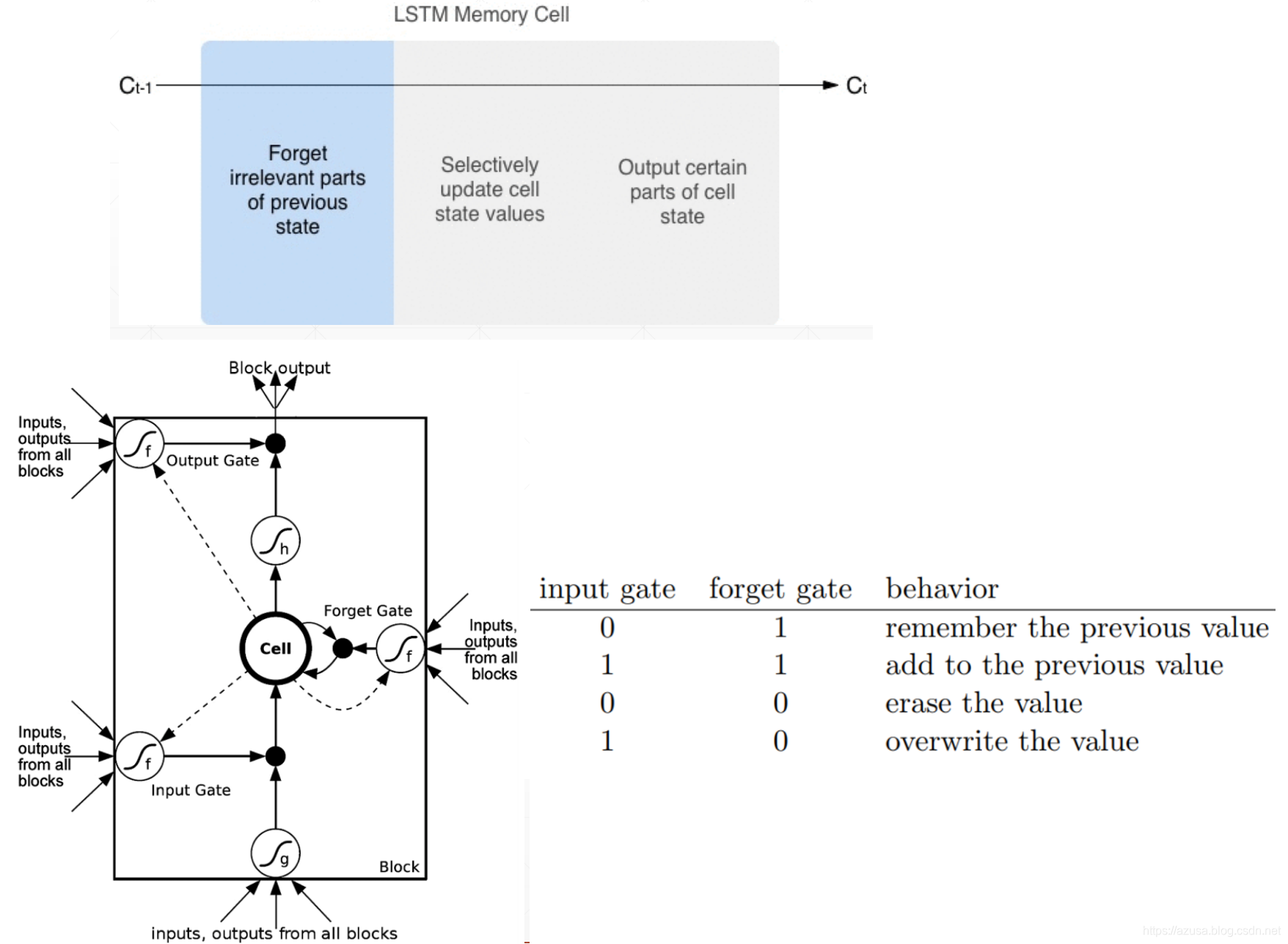
LSTM


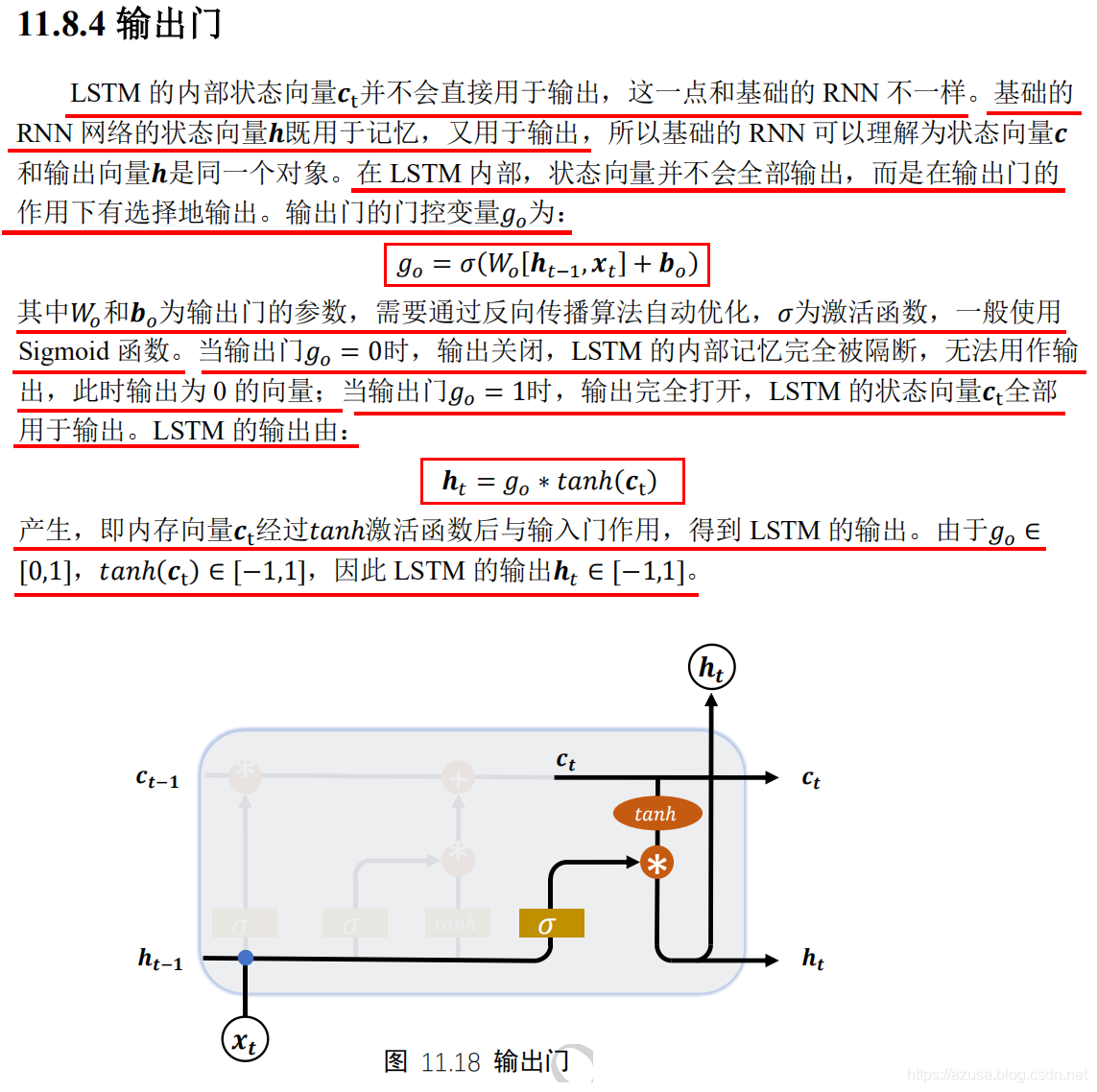

import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import datasets, layers, optimizers#[序列数量b, 序列长度s, 词向量特征长度f]x = tf.random.normal([2,80,100])# 得到一个时间戳的输入,从[序列数量b, 序列长度s, 词向量特征长度f]中获取 s个[序列数量b, 词向量特征长度f]xt = x[:,0,:]xt.shape #TensorShape([2, 100])# 创建 Cellcell = layers.LSTMCell(64)# 初始化状态和输出 List[h,c],状态向量h和c的形状均都是[批量大小b, 状态向量特征长度h]state = [tf.zeros([2,64]),tf.zeros([2,64])]# 前向计算out, state = cell(xt, state) #state为List[h,c],out和List的第一个元素h都是相同的id(out),id(state[0]),id(state[1])#遍历批量序列中的每一个时间戳,遍历次数和时间戳数量一致,每次遍历的时间戳的形状为[序列数量b, 词向量特征长度f]for xt in tf.unstack(x, axis=1):out, state = cell(xt, state)layer = layers.LSTM(64)out = layer(x) #[批量大小b,状态向量特征长度h]out.shape #TensorShape([2, 64])layer = layers.LSTM(64, return_sequences=True)out = layer(x) #[批量大小b,序列长度s,状态向量特征长度h]out.shape #TensorShape([2, 80, 64])
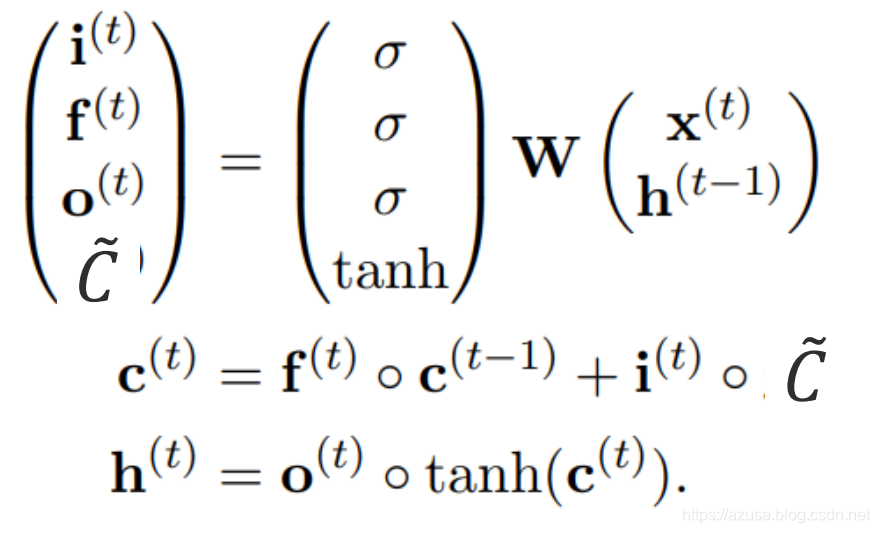

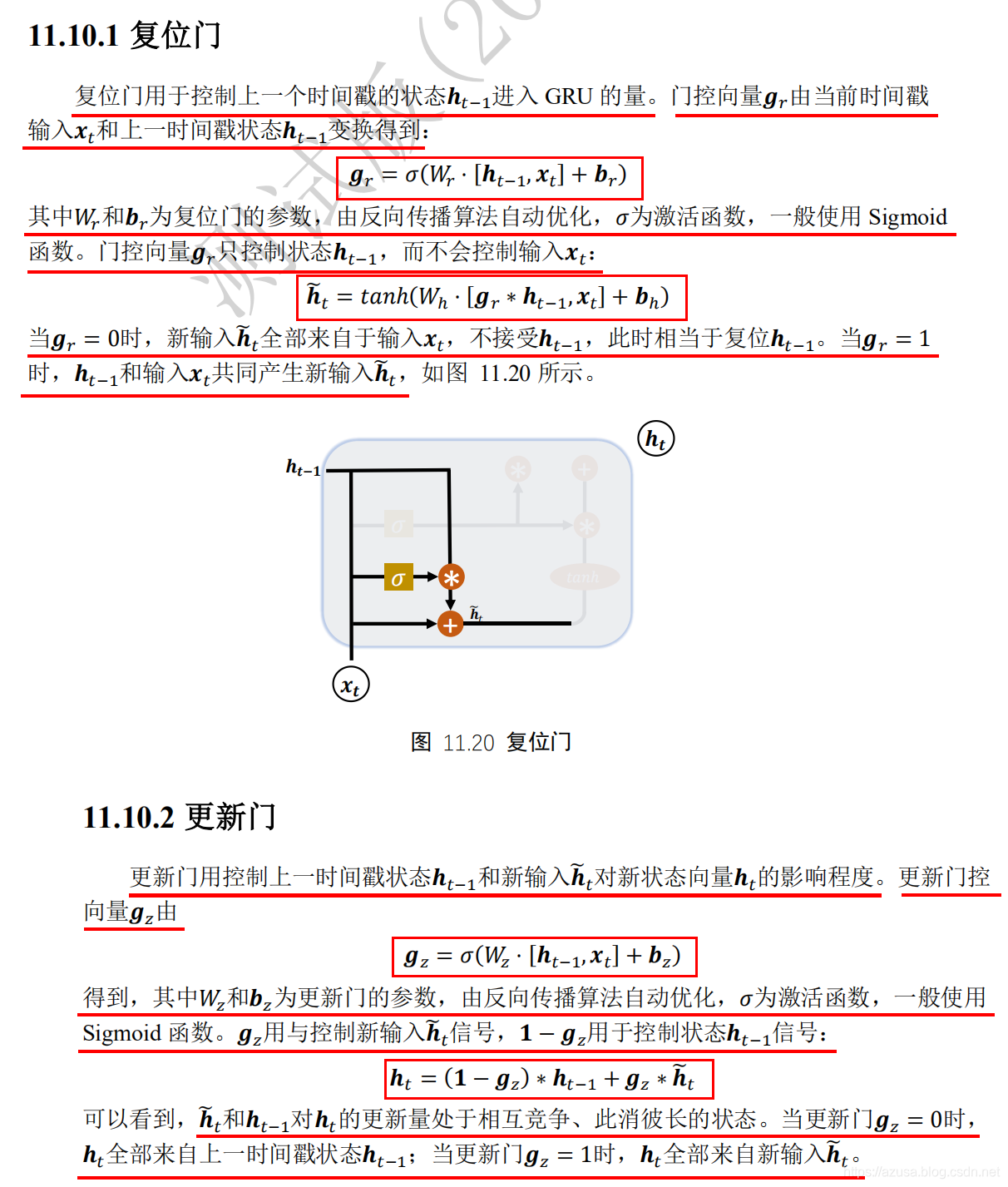
" class="reference-link">GRU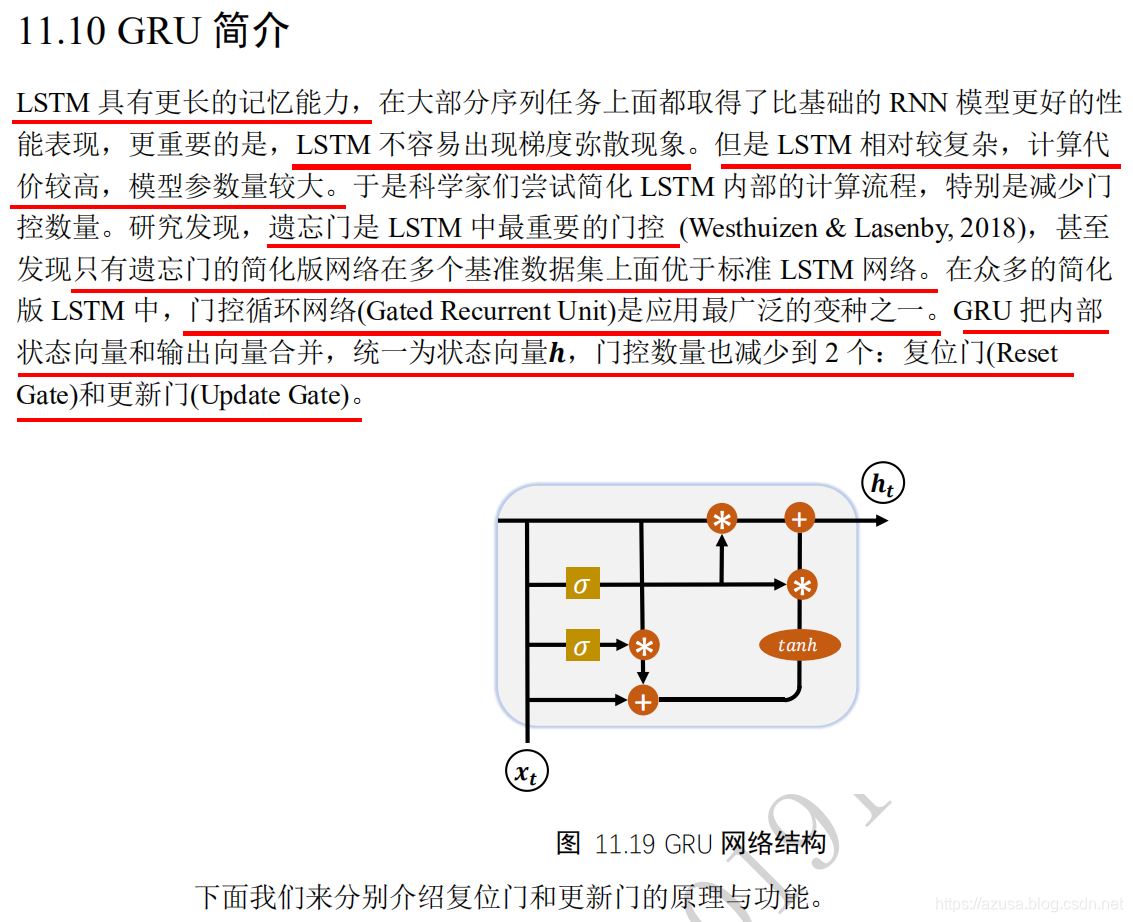

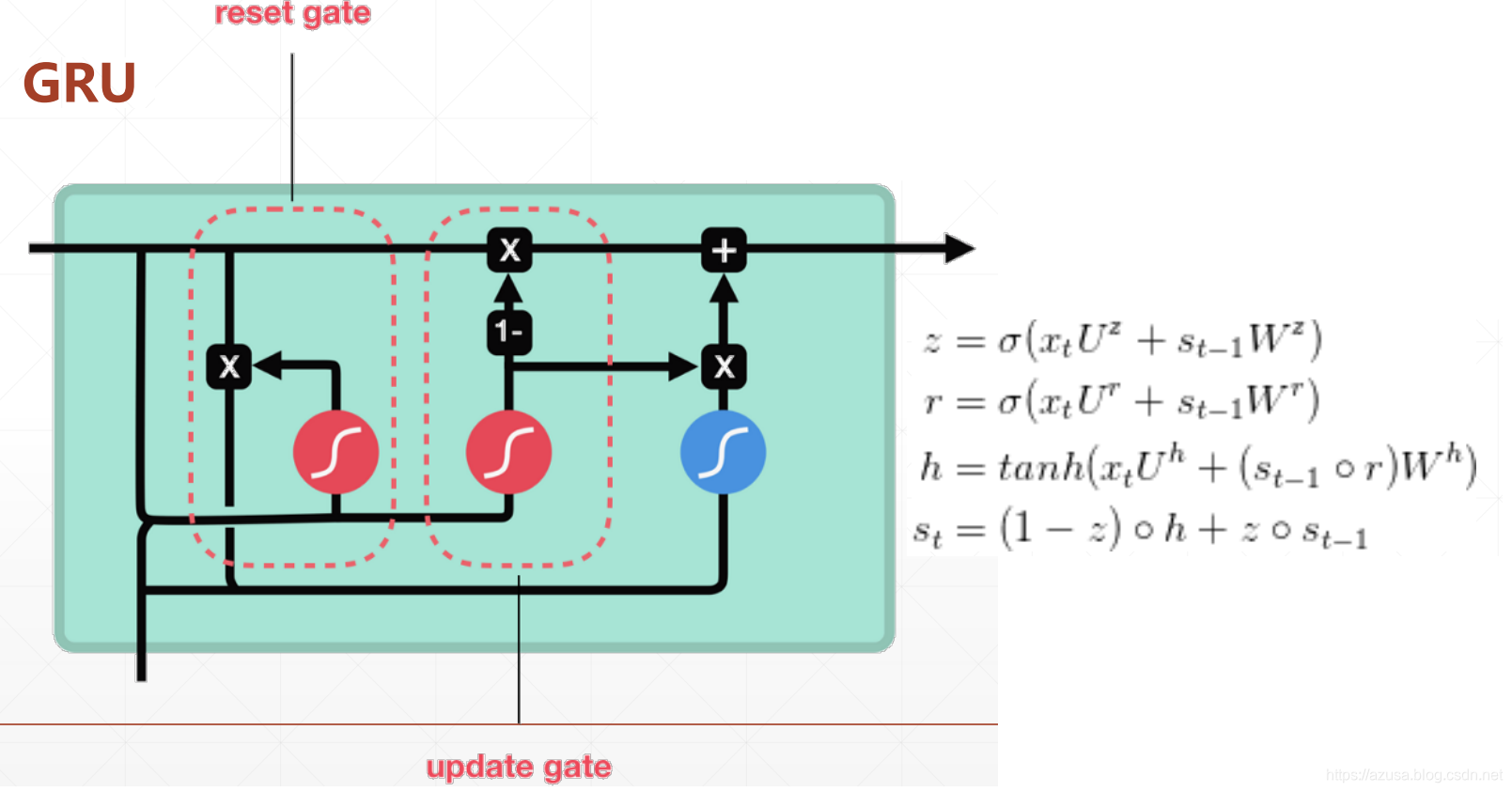
LSTM/GRU情感分类问题



import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as pltx = tf.range(10)x = tf.random.shuffle(x)# 创建共10个单词,每个单词用长度为4的向量表示的层net = layers.Embedding(10, 4) #[词汇表大小, 词向量特征长度f]out = net(x)outout.shape #TensorShape([10, 4]) 即[词汇表大小, 词向量特征长度f]net.embeddingsnet.embeddings.shape #TensorShape([10, 4]) 即[词汇表大小, 词向量特征长度f]net.embeddings.trainable #Truenet.trainable = False# 从预训练模型中加载词向量表embed_glove = load_embed('glove.6B.50d.txt')# 直接利用预训练的词向量表初始化Embedding层net.set_weights([embed_glove])cell = layers.SimpleRNNCell(3) #状态向量特征长度hcell.build(input_shape=(None,4)) #input_shape=(序列数量,序列长度)#SimpleRNNCell内部维护了3个张量,kernel为Wxh(词向量特征长度f, 状态向量特征长度h),shape为(4, 3),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h),shape为(3, 3),bias为偏置b(状态向量特征长度h,),shape为(3,)cell.trainable_variables#[<tf.Variable 'kernel:0' shape=(4, 3) dtype=float32, numpy=#array(。。。, dtype=float32)>,#<tf.Variable 'recurrent_kernel:0' shape=(3, 3) dtype=float32, numpy=#array(。。。, dtype=float32)>,#<tf.Variable 'bias:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>]# 初始化状态向量h0 = [tf.zeros([4, 64])] #[词向量特征长度f, 状态向量特征长度h]x = tf.random.normal([4, 80, 100]) #[序列数量b,序列长度s,词向量特征长度f]xt = x[:,0,:] #批量序列的第一个时间戳/单词的形状 [序列数量b,词向量特征长度f]# 构建词向量特征长度f=100,序列长度s=80,状态向量长度h=64的 Cellcell = layers.SimpleRNNCell(64)out, h1 = cell(xt, h0) # 前向计算,out和h1均为同一个状态向量print(out.shape, h1[0].shape) #(4, 64) (4, 64)print(id(out), id(h1[0])) #2310103532472 2310103532472h = h0# 在序列长度的维度解开输入,得到xt:[b,f] [序列数量b,词向量特征长度f]for xt in tf.unstack(x, axis=1):out, h = cell(xt, h) # 前向计算# 最终输出可以聚合每个时间戳上的输出,也可以只取最后时间戳的输出out = outx = tf.random.normal([4,80,100]) #[序列数量b,序列长度s,词向量特征长度f]xt = x[:,0,:] # 取第一个时间戳的输入x0 [序列数量b,词向量特征长度f]# 构建2个Cell,先cell0,后cell1cell0 = layers.SimpleRNNCell(64) #状态向量长度h=64cell1 = layers.SimpleRNNCell(64)h0 = [tf.zeros([4,64])] # cell0的初始状态向量 [批量大小b,状态向量特征长度h]h1 = [tf.zeros([4,64])] # cell1的初始状态向量out0, h0 = cell0(xt, h0)out1, h1 = cell1(out0, h1)for xt in tf.unstack(x, axis=1):# xtw作为输入,输出为out0out0, h0 = cell0(xt, h0)# 上一个cell的输出out0作为本cell的输入out1, h1 = cell1(out0, h1)print(x.shape)# 保存上一层的所有时间戳上面的输出middle_sequences = []# 计算第一层的所有时间戳上的输出,并保存for xt in tf.unstack(x, axis=1):out0, h0 = cell0(xt, h0)middle_sequences.append(out0)# 计算第二层的所有时间戳上的输出# 如果不是末层,需要保存所有时间戳上面的输出for xt in middle_sequences:out1, h1 = cell1(xt, h1)layer = layers.SimpleRNN(64) #状态向量长度h=64x = tf.random.normal([4, 80, 100]) #[序列数量b,序列长度s,词向量特征长度f]out = layer(x)out.shapelayer = layers.SimpleRNN(64, return_sequences=True) #返回所有时间戳上的输出out = layer(x)out# 构建2层RNN网络# 除最末层外,都需要返回所有时间戳的输出net = keras.Sequential([layers.SimpleRNN(64, return_sequences=True),layers.SimpleRNN(64),])out = net(x)x = tf.random.normal([2,80,100])#[序列数量b,序列长度s,词向量特征长度f]xt = x[:,0,:] # 得到一个时间戳的输入 [序列数量b,词向量特征长度f]cell = layers.LSTMCell(64) # 创建Cell #状态向量长度h=64# 初始化状态和输出List,[h,c]state = [tf.zeros([2,64]),tf.zeros([2,64])] #[批量大小b,状态向量特征长度h]out, state = cell(xt, state) # 前向计算id(out),id(state[0]),id(state[1]) #(2316639101352, 2316639101352, 2316639102232) out和List的第一个元素h都是相同的net = layers.LSTM(4) #状态向量长度h=4net.build(input_shape=(None,5,3)) #input_shape=[序列数量b,序列长度s,词向量特征长度f]#LSTM内部维护了3个张量,kernel为Wxh(词向量特征长度f, 状态向量特征长度h*4),shape为(3, 16),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h*4),shape为(4, 16),bias为偏置b(状态向量特征长度h*4,),shape为(16,)net.trainable_variables#[<tf.Variable 'kernel:0' shape=(3, 16) dtype=float32, numpy=#array(。。。, dtype=float32)>,#<tf.Variable 'recurrent_kernel:0' shape=(4, 16) dtype=float32, numpy=#array(。。。, dtype=float32)>,#<tf.Variable 'bias:0' shape=(16,) dtype=float32, numpy=#array(。。。, dtype=float32)>]net = layers.GRU(4) #状态向量长度h=4net.build(input_shape=(None,5,3)) #input_shape=[序列数量b,序列长度s,词向量特征长度f]#GRU内部维护了3个张量,kernel为Wxh(词向量特征长度f, 状态向量特征长度h*3),shape为(3, 12),#recurrent_kernel为Whh(状态向量特征长度h, 状态向量特征长度h*3),shape为(4, 12),bias为偏置b(状态向量特征长度h*3,),shape为(12,)net.trainable_variables[<tf.Variable 'kernel:0' shape=(3, 12) dtype=float32, numpy=array(。。。, dtype=float32)>,<tf.Variable 'recurrent_kernel:0' shape=(4, 12) dtype=float32, numpy=array(。。。, dtype=float32)>,<tf.Variable 'bias:0' shape=(2, 12) dtype=float32, numpy=array(。。。, dtype=float32)>]# 初始化状态向量h = [tf.zeros([2,64])]cell = layers.GRUCell(64) # 新建GRU Cellfor xt in tf.unstack(x, axis=1):out, h = cell(xt, h)out.shapeimport osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词#x_train/x_test实际为25000个list列表,x_train中的每个list列表中有218个数字(单词),x_test中的每个list列表中有218个数字(单词)(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape) #(25000,) 218 (25000,)print(x_test.shape, len(x_test[0]), y_test.shape) #(25000,) 68 (25000,)x_train[0] #这个list列表中有218个数字(单词)# 数字编码表:字典中的key为单词,value为索引word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)#把数字编码表(字典)中的每个key(单词)对应的value(索引值)加3word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表:key(单词)换到value的位置,value(索引值)换到key的位置reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])#根据翻转的数字编码表(字典) 通过序列数据(每个list列表)中的每个数字(索引值) 获取其对应的单词def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])#根据该list列表中的所有数字(索引值)获取其对应的单词decode_review(x_train[8])print('Indexing word vectors.')embeddings_index = {}#GLOVE_DIR = r'C:\Users\z390\Downloads\glove6b50dtxt'GLOVE_DIR = r'F:\人工智能\学习资料\GloVe 词嵌入'with open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'),encoding='utf-8') as f:for line in f:values = line.split()word = values[0] #获取单词coefs = np.asarray(values[1:], dtype='float32')#获取单词对应的训练好的词向量特征值embeddings_index[word] = coefs #单词作为key,单词对应的权重矩阵值作为valueprint('Found %s word vectors.' % len(embeddings_index)) #Found 400000 word vectors.len(embeddings_index.keys()) #400000len(word_index.keys()) #88588MAX_NUM_WORDS = total_words # 词汇表大小N_vocab# prepare embedding matrixnum_words = min(MAX_NUM_WORDS, len(word_index))embedding_matrix = np.zeros((num_words, embedding_len)) #[词汇表大小, 词向量特征长度f]applied_vec_count = 0for word, i in word_index.items(): #遍历每个key(单词)和对应的value(索引值)if i >= MAX_NUM_WORDS:continueembedding_vector = embeddings_index.get(word) #根据key(单词)获取对应的训练好的词向量特征值# print(word,embedding_vector)if embedding_vector is not None:# words not found in embedding index will be all-zeros.embedding_matrix[i] = embedding_vector #key为单词对应的索引值,value为单词对应的训练好的词向量特征值applied_vec_count += 1#9793 (10000, 100) 即[词汇表大小, 词向量特征长度f]print(applied_vec_count, embedding_matrix.shape)# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)#x_train shape: (25000, 80) tf.Tensor(1, shape=(), dtype=int64) tf.Tensor(0, shape=(), dtype=int64)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))#x_test shape: (25000, 80)print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# total_words 词汇表大小# input_length = max_review_len 句子最大长度s,大于的句子部分将截断,小于的将填充# embedding_len 词向量特征长度f,即时间戳t的输入特征长度f# 在获得了词汇表后,利用词汇表初始化 Embedding 层即可,并设置 Embedding 层不参与梯度优化,设置trainable=False不参与梯度更新# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len, trainable=False)# input_shape=[序列数量b,序列长度s]self.embedding.build(input_shape=(None,max_review_len))# 直接利用预训练的词向量表初始化 Embedding 层self.embedding.set_weights([embedding_matrix])# 构建RNNself.rnn = keras.Sequential([layers.LSTM(units, dropout=0.5, return_sequences=True),layers.LSTM(units, dropout=0.5)])# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(32),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100] [序列数量b,序列长度s,词向量特征长度f]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]x = self.rnn(x)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(x,training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 512 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.Adam(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# 构建RNNself.rnn = keras.Sequential([layers.LSTM(units, dropout=0.5, return_sequences=True),layers.LSTM(units, dropout=0.5)])# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(32),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]x = self.rnn(x)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(x,training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 32 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.Adam(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# 构建RNNself.rnn = keras.Sequential([layers.GRU(units, dropout=0.5, return_sequences=True),layers.GRU(units, dropout=0.5)])# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(32),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]x = self.rnn(x)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(x,training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 32 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.Adam(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 512 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# 构建RNNself.rnn = keras.Sequential([layers.SimpleRNN(units, dropout=0.5, return_sequences=True),layers.SimpleRNN(units, dropout=0.5)])# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(32),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]x = self.rnn(x)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(x,training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.Adam(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# [b, 64],构建Cell初始化状态向量,重复使用self.state0 = [tf.zeros([batchsz, units])]self.state1 = [tf.zeros([batchsz, units])]# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len,input_length=max_review_len)# 构建2个Cellself.rnn_cell0 = layers.GRUCell(units, dropout=0.5)self.rnn_cell1 = layers.GRUCell(units, dropout=0.5)# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(units),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]state0 = self.state0state1 = self.state1for word in tf.unstack(x, axis=1): # word: [b, 100]out0, state0 = self.rnn_cell0(word, state0, training)out1, state1 = self.rnn_cell1(out0, state1, training)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(out1, training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.RMSprop(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# [b, 64],构建Cell初始化状态向量,重复使用self.state0 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]self.state1 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)# 构建2个Cellself.rnn_cell0 = layers.LSTMCell(units, dropout=0.5)self.rnn_cell1 = layers.LSTMCell(units, dropout=0.5)# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(units),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]state0 = self.state0state1 = self.state1for word in tf.unstack(x, axis=1): # word: [b, 100]out0, state0 = self.rnn_cell0(word, state0, training)out1, state1 = self.rnn_cell1(out0, state1, training)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(out1,training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.RMSprop(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom tensorflow.keras import layers, losses, optimizers, Sequentialtf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')batchsz = 128 # 批量大小total_words = 10000 # 词汇表大小N_vocabmax_review_len = 80 # 句子最大长度s,大于的句子部分将截断,小于的将填充embedding_len = 100 # 词向量特征长度f# 加载IMDB数据集,此处的数据采用数字编码,一个数字代表一个单词(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)print(x_train.shape, len(x_train[0]), y_train.shape)print(x_test.shape, len(x_test[0]), y_test.shape)x_train[0]# 数字编码表word_index = keras.datasets.imdb.get_word_index()# for k,v in word_index.items():# print(k,v)word_index = {k:(v+3) for k,v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2 # unknownword_index["<UNUSED>"] = 3# 翻转编码表reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])def decode_review(text):return ' '.join([reverse_word_index.get(i, '?') for i in text])decode_review(x_train[8])# x_train:[b, 80]# x_test: [b, 80]# 截断和填充句子,使得等长,此处长句子保留句子后面的部分,短句子在前面填充x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)# 构建数据集,打散,批量,并丢掉最后一个不够batchsz的batchdb_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))db_test = db_test.batch(batchsz, drop_remainder=True)print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))print('x_test shape:', x_test.shape)class MyRNN(keras.Model):# Cell方式构建多层网络def __init__(self, units):super(MyRNN, self).__init__()# [b, 64],构建Cell初始化状态向量,重复使用self.state0 = [tf.zeros([batchsz, units])]self.state1 = [tf.zeros([batchsz, units])]# 词向量编码 [b, 80] => [b, 80, 100]self.embedding = layers.Embedding(total_words, embedding_len,input_length=max_review_len)# 构建2个Cellself.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)# 构建分类网络,用于将CELL的输出特征进行分类,2分类# [b, 80, 100] => [b, 64] => [b, 1]self.outlayer = Sequential([layers.Dense(units),layers.Dropout(rate=0.5),layers.ReLU(),layers.Dense(1)])def call(self, inputs, training=None):x = inputs # [b, 80]# embedding: [b, 80] => [b, 80, 100]x = self.embedding(x)# rnn cell compute,[b, 80, 100] => [b, 64]state0 = self.state0state1 = self.state1for word in tf.unstack(x, axis=1): # word: [b, 100]out0, state0 = self.rnn_cell0(word, state0, training)out1, state1 = self.rnn_cell1(out0, state1, training)# 末层最后一个输出作为分类网络的输入: [b, 64] => [b, 1]x = self.outlayer(out1, training)# p(y is pos|x)prob = tf.sigmoid(x)return probdef main():units = 64 # RNN状态向量长度fepochs = 50 # 训练epochsmodel = MyRNN(units)# 装配model.compile(optimizer = optimizers.RMSprop(0.001),loss = losses.BinaryCrossentropy(),metrics=['accuracy'])# 训练和验证model.fit(db_train, epochs=epochs, validation_data=db_test)# 测试model.evaluate(db_test)if __name__ == '__main__':main()import osimport tensorflow as tfimport numpy as npfrom tensorflow import kerastf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')# 确定随机种子的可重复性np.random.seed(7)# 加载数据集,但只保留前n个单词,其余的为零top_words = 10000# 截断和填充输入序列max_review_length = 80(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data(num_words=top_words)# X_train = tf.convert_to_tensor(X_train)# y_train = tf.one_hot(y_train, depth=2)print('Pad sequences (samples x time)')x_train = keras.preprocessing.sequence.pad_sequences(X_train, maxlen=max_review_length)x_test = keras.preprocessing.sequence.pad_sequences(X_test, maxlen=max_review_length)print('x_train shape:', x_train.shape)print('x_test shape:', x_test.shape)class RNN(keras.Model):def __init__(self, units, num_classes, num_layers):super(RNN, self).__init__()# self.cells = [keras.layers.LSTMCell(units) for _ in range(num_layers)]# self.rnn = keras.layers.RNN(self.cells, unroll=True)self.rnn = keras.layers.LSTM(units, return_sequences=True)self.rnn2 = keras.layers.LSTM(units)# self.cells = (keras.layers.LSTMCell(units) for _ in range(num_layers))# self.rnn = keras.layers.RNN(self.cells, return_sequences=True, return_state=True)# self.rnn = keras.layers.LSTM(units, unroll=True)# self.rnn = keras.layers.StackedRNNCells(self.cells)# 总共有1000个单词,每个单词都将嵌入到100长度的向量中,最大句子长度是80字self.embedding = keras.layers.Embedding(top_words, 100, input_length=max_review_length)self.fc = keras.layers.Dense(1)def call(self, inputs, training=None, mask=None):# print('x', inputs.shape)# [b, sentence len] => [b, sentence len, word embedding]x = self.embedding(inputs)# print('embedding', x.shape)x = self.rnn(x)x = self.rnn2(x)# print('rnn', x.shape)x = self.fc(x)print(x.shape)return xdef main():units = 64num_classes = 2batch_size = 32epochs = 20model = RNN(units, num_classes, num_layers=2)model.compile(optimizer=keras.optimizers.Adam(0.001),loss=keras.losses.BinaryCrossentropy(from_logits=True),metrics=['accuracy'])# trainmodel.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,validation_data=(x_test, y_test), verbose=1)# evaluate on test setscores = model.evaluate(x_test, y_test, batch_size, verbose=1)print("Final test loss and accuracy :", scores)if __name__ == '__main__':main()



RNNColorbot
import os, six, timeimport tensorflow as tfimport numpy as npfrom tensorflow import kerasfrom matplotlib import pyplot as pltfrom utils import load_dataset, parsefrom model import RNNColorbottf.random.set_seed(22)np.random.seed(22)os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'assert tf.__version__.startswith('2.')def test(model, eval_data):"""计算评估数据的平均损失,应该是一个Dataset"""avg_loss = keras.metrics.Mean()for (labels, chars, sequence_length) in eval_data:predictions = model((chars, sequence_length), training=False)avg_loss.update_state(keras.losses.mean_squared_error(labels, predictions))print("eval/loss: %.6f" % avg_loss.result().numpy())def train_one_epoch(model, optimizer, train_data, log_interval, epoch):"""使用优化器对train_data建模"""for step, (labels, chars, sequence_length) in enumerate(train_data):with tf.GradientTape() as tape:predictions = model((chars, sequence_length), training=True)loss = keras.losses.mean_squared_error(labels, predictions)loss = tf.reduce_mean(loss)grads = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(grads, model.trainable_variables))if step % 100 == 0:print(epoch, step, 'loss:', float(loss))SOURCE_TRAIN_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/archive/extras/colorbot/data/train.csv"SOURCE_TEST_URL = "https://raw.githubusercontent.com/random-forests/tensorflow-workshop/master/archive/extras/colorbot/data/test.csv"def main():batchsz = 64rnn_cell_sizes = [256, 128]epochs = 40data_dir = os.path.join('.', "data")train_data = load_dataset(data_dir=data_dir, url=SOURCE_TRAIN_URL, batch_size=batchsz)eval_data = load_dataset(data_dir=data_dir, url=SOURCE_TEST_URL, batch_size=batchsz)model = RNNColorbot(rnn_cell_sizes=rnn_cell_sizes,label_dimension=3,keep_prob=0.5)optimizer = keras.optimizers.Adam(0.01)for epoch in range(epochs):start = time.time()train_one_epoch(model, optimizer, train_data, 50, epoch)end = time.time()# print("train/time for epoch #%d: %.2f" % (epoch, end - start))if epoch % 10 == 0:test(model, eval_data)print("Colorbot is ready to generate colors!")while True:try:color_name = six.moves.input("Give me a color name (or press enter to exit): ")except EOFError:returnif not color_name:return_, chars, length = parse(color_name)(chars, length) = (tf.identity(chars), tf.identity(length))chars = tf.expand_dims(chars, 0)length = tf.expand_dims(length, 0)preds = tf.unstack(model((chars, length), training=False)[0])# 预测不能为负,因为它们是由ReLU layer层生成的# 但是,它们可能大于1clipped_preds = tuple(min(float(p), 1.0) for p in preds)rgb = tuple(int(p * 255) for p in clipped_preds)print("rgb:", rgb)data = [[clipped_preds]]plt.imshow(data)plt.title(color_name)plt.savefig(color_name+'.png')if __name__ == "__main__":main()import os, six, timeimport tensorflow as tfimport numpy as npfrom tensorflow import kerasimport urllibdef parse(line):"""分析colors dataset中的行"""# dataset的每一行以逗号分隔,格式为 color_name, r, g, b# 所以“items”是一个列表 [color_name, r, g, b].items = tf.string_split([line], ",").valuesrgb = tf.strings.to_number(items[1:], out_type=tf.float32) / 255.# 将颜色名称表示为一个one-hot编码字符序列color_name = items[0]chars = tf.one_hot(tf.io.decode_raw(color_name, tf.uint8), depth=256)# RNN需要序列长度length = tf.cast(tf.shape(chars)[0], dtype=tf.int64)return rgb, chars, lengthdef maybe_download(filename, work_directory, source_url):"""从源url下载数据,除非它已经在这里了Args:filename: 字符串,目录中文件的名称。work_directory: 字符串,工作目录的路径。source_url: 如果文件不存在则从URL去下载。Returns:result文件的路径。"""if not tf.io.gfile.exists(work_directory):tf.io.gfile.makedirs(work_directory)filepath = os.path.join(work_directory, filename)if not tf.io.gfile.exists(filepath):temp_file_name, _ = urllib.request.urlretrieve(source_url)tf.io.gfile.copy(temp_file_name, filepath)with tf.io.gfile.GFile(filepath) as f:size = f.size()print("Successfully downloaded", filename, size, "bytes.")return filepathdef load_dataset(data_dir, url, batch_size):"""将路径处的颜色数据加载到PaddedDataset中"""# 将数据下载到url到data_dir/basename(url)中。dataset 有一个header# 行(color_name, r, g, b) 后跟逗号分隔的行。path = maybe_download(os.path.basename(url), data_dir, url)# 此命令链通过以下方式加载我们的数据:# 1. 跳过header (.skip(1))# 2. 分析后续行(.map(parse))# 3. shuffle 数据(.shuffle(...))# 3. 将数据分组到填充的批中 (.padded_batch(...)).dataset = tf.data.TextLineDataset(path).skip(1).map(parse).shuffle(buffer_size=10000).padded_batch(batch_size, padded_shapes=([None], [None, None], []))return datasetimport tensorflow as tffrom tensorflow import kerasclass RNNColorbot(keras.Model):"""在实值向量标签上回归的多层(LSTM)RNN"""def __init__(self, rnn_cell_sizes, label_dimension, keep_prob):"""构造一个 RNNColorbotArgs:rnn_cell_sizes: 表示RNN中每个LSTM单元大小的整数列表; rnn_cell_sizes[i] 是第i层单元的大小label_dimension: 要回归的labels的长度keep_prob: (1 - dropout 概率); dropout应用于每个LSTM层的输出"""super(RNNColorbot, self).__init__(name="")self.rnn_cell_sizes = rnn_cell_sizesself.label_dimension = label_dimensionself.keep_prob = keep_probself.cells = [keras.layers.LSTMCell(size) for size in rnn_cell_sizes]self.relu = keras.layers.Dense(label_dimension, activation=tf.nn.relu)def call(self, inputs, training=None):"""实现RNN逻辑和预测生成Args:inputs: 元组(字符,序列长度), 其中chars是一个由一个one-hot编码的颜色名组成的batch,表示为一个张量,其维度为[batch_size, time_steps, 256] 和 序列长度,将每个字符序列(color name)的长度保持为一个张量,其维度为[batch_size]training: 调用是否在training 期间发生Returns:通过传递字符产生的 通过多层RNN并将ReLU应用到最终隐藏状态而产生的维度张量[batch_size, label_dimension]。"""(chars, sequence_length) = inputs# 变换第一和第二维度,使字符具有形状 [time_steps, batch_size, dimension].chars = tf.transpose(chars, [1, 0, 2])# 外环在RNN的各个层之间循环;内环执行特定层的时间步。batch_size = int(chars.shape[1])for l in range(len(self.cells)): # for each layercell = self.cells[l]outputs = []# h_zero, c_zerostate = (tf.zeros((batch_size, self.rnn_cell_sizes[l])),tf.zeros((batch_size, self.rnn_cell_sizes[l])))# 取消堆栈输入以获取批列表,每个时间步一个。chars = tf.unstack(chars, axis=0)for ch in chars: # for each time stampoutput, state = cell(ch, state)outputs.append(output)# 这一层的输出是下一层的输入。# [t, b, h]chars = tf.stack(outputs, axis=0)if training:chars = tf.nn.dropout(chars, self.keep_prob)# 为每个示例提取正确的输出(即隐藏状态)。此批中的所有字符序列都被填充到相同的固定长度,以便它们可以很容易地通过上述RNN循环输入# `sequence_length`向量告诉我们字符序列的真实长度,让我们为每个序列获取由其非填充字符生成的隐藏状态。batch_range = [i for i in range(batch_size)]# stack [64] with [64] => [64, 2]indices = tf.stack([sequence_length - 1, batch_range], axis=1)# [t, b, h]# print(chars.shape)hidden_states = tf.gather_nd(chars, indices)# print(hidden_states.shape)return self.relu(hidden_states)


































还没有评论,来说两句吧...