强化学习笔记+代码(五):Double-DQN、Dueling DQN结构原理和Agent实现
本文主要整理和参考了李宏毅的强化学习系列课程和莫烦python的强化学习教程
本系列主要分几个部分进行介绍
- 强化学习背景介绍
- SARSA算法原理和Agent实现
- Q-learning算法原理和Agent实现
- DQN算法原理和Agent实现(tensorflow)
- Double-DQN、Dueling DQN算法原理和Agent实现(tensorflow)
- Policy Gradients算法原理和Agent实现(tensorflow)
- Actor-Critic、A2C、A3C算法原理和Agent实现(tensorflow)
一、Why Double-DQN
先回顾一下DQN算法
实际上DQN算出的状态s动作a的价值经常是被高估的,为什么这么说呢,因为里面核心是求 Q ∗ ( s , a ) = r + γ m a x [ Q ( s ′ , a ′ ) ] Q_*(s,a)=r+γmax[Q(s’,a’)] Q∗(s,a)=r+γmax[Q(s′,a′)],其中 Q ( s ′ , a ′ ) Q(s’,a’) Q(s′,a′)是一个随机变量,那么 Q ( s ′ , a ′ ) Q(s’,a’) Q(s′,a′)就是不稳定的。而在算法中,我们每次都要取 m a x [ Q ( s ′ , a ′ ) ] max[Q(s’,a’)] max[Q(s′,a′)],当有一串Q(s’,a’)时,我们总是选择最高的。这就导致了DQN算出的状态s动作a的价值经常是被高估的。下图展示了四个游戏中DQN的表现: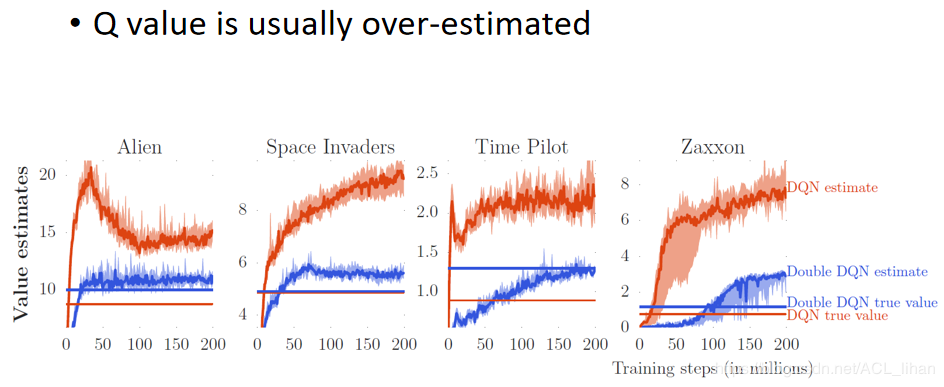
橙色的曲线代表DQN估测的Q-value,橙色的直线代表DQN训练出来的policy实际中获得的Q-value,可以看出DQN估测的Q-value通常是被高度的。
蓝色的曲线代表Double DQN估测的Q-value,蓝色的直线代表Double DQN训练出来的policy实际中获得的Q-value。可以看出Double DQN估计出的Q-value要更符合现实。
那么什么是Double DQN呢?实际上就是将DQN的 Q ∗ ( s , a ) = r + γ m a x [ Q ( s ′ , a ′ ) ] Q_*(s,a)=r+γmax[Q(s’,a’)] Q∗(s,a)=r+γmax[Q(s′,a′)](这是DQN被高度的原因)的形式进行改动,变为如下形式:
其中红色框和蓝色框的 Q Q Q来自不同的network。可以看到算法利用 m a x [ Q ( s t + 1 , a ) ] max[Q(s_{t+1},a)] max[Q(st+1,a)]选出了 s t + 1 s_{t+1} st+1时刻价值最高的动作,再将得到的动作 a t + 1 a_{t+1} at+1和状态 s t + 1 s_{t+1} st+1带入另一个network的 Q ′ ( s , a ) Q’(s,a) Q′(s,a)算出价值,作为最终的跟更新时使用的价值。
这个公式的理解是非常直观的,就好比病人去医院检查心脏病,第一次检查出很高患有心脏病。为了确认这个判断是否正确,此时最好的方法就是找另一个医生再检查一次。
实际上:即便Q过估计了某个值,只要Q’没有高估,最后的结果还是正常的;即便Q’高估了某个值,只要Q没有选到那个action,最后的结果还是正常的.
我们并不去找真正去找另一个神经网络Q’。因为在DQN中我们已经有了两个结构一样的神经网络,一个是eval network,一个是target network。
此次只需要将先用eval network估计出 m a x [ Q ( s t + 1 , a ) ] max[Q(s_{t+1},a)] max[Q(st+1,a)],在将选出的动和 s t + 1 s_{t+1} st+1作带入target network进行求解即可。
二、 Double-DQN的Agent编写
Double-DQN的agent编写与DQN几乎一样只是在求q估计的时候先用eval network求出价值最大的动作,再讲这个动作带入target network。
之前在DQN中使用的公式为
q_target[batch_index, eval_act_index]=reward+self.gamma * np.max(q_next, axis=1)
现在改为:
#用t+1的状态带入eval network先选出动作action_value = self.sess.run(self.q_eval, feed_dict={self.s: batch_memory[:, -self.n_features:]})#维度为[batch_size, 1]action = np.argmax(action_value, axis=1)q_target[batch_index, eval_act_index]=reward+self.gamma * q_next[batch_index, action]
完整agent代码如下:
class Double_DeepQNetwork(object):#replace_target_iter为更新target network的步数,防止target network和eval network差别过大#memory_size为buffer储存记忆上线,方便使用以前记忆学习def __init__(self, n_actions, n_features,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9,replace_target_iter=300,memory_size=500,batch_size=32,e_greedy_increment=None,output_graph=False):self.n_actions = n_actionsself.n_features = n_featuresself.lr = learning_rateself.gamma = reward_decayself.epsilon_max = e_greedy # epsilon后面奖励对前面的递减参数self.replace_target_iter = replace_target_iter # 更换 target_net 的步数self.memory_size = memory_size # 记忆上限self.batch_size = batch_size # 每次更新时从 memory 里面取多少记忆出来self.epsilon_increment = e_greedy_increment # epsilon 的增量#epsilon = 0等于0时,后面的奖励创传不到前面,前面的状态就开启随机探索模式self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max # 是否开启探索模式, 并逐步减少探索次数# 记录学习次数 (用于判断是否更换 target_net 参数)self.learn_step_counter = 0# 初始化全 0 记忆 [s, a, r, s_], 实际上feature为状态的维度,n_features*2分别记录s和s_,+2记录a和rself.memory = np.zeros((self.memory_size, n_features*2+2))self._build_net()#替换 target net 的参数t_params = tf.get_collection('target_net_params') #提取 target_net 的参数e_params = tf.get_collection('eval_net_params') # 提取 eval_net 的参数#将eval_network中每一个variable的值赋值给target network的对应变量self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] #更新 target_net 参数self.sess = tf.Session()if output_graph:tf.summary.FileWriter("logs/", self.sess.graph)self.sess.run(tf.global_variables_initializer())#用于记录# 记录所有 cost 变化self.cost_his = []#李宏毅老师克重的relpay buffer,通过以往的记忆中不断训练#这是DQN变为off-policy的核心def store_transition(self, s, a, r, s_):#如果DeepQNetwork中定义了memory_counter,进行记忆存储if not hasattr(self, 'memory_counter'):self.memory_counter = 0#记录一条 [s, a, r, s_] 记录transition = np.hstack((s, [a, r], s_))#总 memory 大小是固定的, 如果超出总大小, 旧 memory 就被新 memory 替换index = self.memory_counter % self.memory_size #类似hashmap赋值思想self.memory[index, :] = transition #进行替换self.memory_counter += 1#建立神经网络#此处建立两个申请网络,一个为target network,用于得到q现实。一个为eval_network,用于得到q估计#target network和eval_network结构一样,target network用比较老的参数,eval_network为真正训练的神经网络def _build_net(self):tf.reset_default_graph() #清空计算图#创建eval神经网络,及时提升参数self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # 用来接收 observation,即神经网络的输入self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # q_target的值, 这个之后会通过计算得到,神经网络的输出#eval_net域下的变量with tf.variable_scope('eval_net'):#c_names用于在一定步数之后更新target network#GLOBAL_VARIABLES作用是collection默认加入所有的Variable对象,用于共享c_names = ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES]n_l1 = 10 #n_l1为network隐藏层神经元的个数w_initializer = tf.random_normal_initializer(0.,0.3)b_initializer = tf.constant_initializer(0.1)#eval_network第一层全连接神经网络with tf.variable_scope('l1'):w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)l1 = tf.nn.relu(tf.matmul(self.s, w1)+b1)#eval_network第二层全连接神经网络with tf.variable_scope('l1'):w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)#求出q估计值,长度为n_actions的向量self.q_eval = tf.matmul(l1, w2) + b2with tf.variable_scope('loss'): # 求误差#使用平方误差self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))with tf.variable_scope('train'): # 梯度下降optimizer = tf.train.RMSPropOptimizer(self.lr)self._train_op = optimizer.minimize(self.loss)#创建target network,输入选择一个action后的状态s_,输出q_targetself.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # 接收下个 observationwith tf.variable_scope('target_net'):c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]# target_net 的第一层fc, collections 是在更新 target_net 参数时会用到with tf.variable_scope('l1'):w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)# target_net 的第二层fcwith tf.variable_scope('l2'):w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)#申请网络输出self.q_next = tf.matmul(l1, w2) + b2print(self.q_next)def choose_action(self, observation):#根据observation(state)选行为#使用eval network选出state下的行为估计#将observation的shape变为(1, size_of_observation),行向量变为列向量才能与NN维度统一observation = observation[np.newaxis, :]if np.random.uniform() < self.epsilon:action_value = self.sess.run(self.q_eval, feed_dict={self.s:observation})action = np.argmax(action_value)else:action = np.random.randint(0, self.n_actions) #随机选择return actiondef learn(self):if self.learn_step_counter % self.replace_target_iter ==0:self.sess.run(self.replace_target_op)print('\ntarget_params_replaced\n')#从memory中随机抽取batch_size这么多记忆if self.memory_counter > self.memory_size: #说明记忆库已经存满,可以从记忆库任意位置收取sample_index = np.random.choice(self.memory_size, size=self.batch_size)else: #记忆库还没有存满,从现有的存储记忆提取sample_index = np.random.choice(self.memory_counter, size=self.batch_size)batch_memory= self.memory[sample_index, :]# 获取q_next即q现实(target_net产生的q)和q_eval(eval_net产生的q)#q_next和q_eval都是一个向量,包含了对应状态下所有动作的q值#实际上feature为状态的维度,batch_memory[:, -self.n_features:]为s_,即状态s采取动作action后的状态s_, batch_memory[:, :self.n_features]为s# 获取q_next即q现实(target_net产生的q)和q_eval(eval_net产生的q)#q_next和q_eval都是一个向量,包含了对应状态下所有动作的q值#实际上feature为状态的维度,batch_memory[:, -self.n_features:]为s_,即状态s采取动作action后的状态s_, batch_memory[:, :self.n_features]为s#q_next, q_eval的维度为[None,n_actions]q_next, q_eval = self.sess.run([self.q_next, self.q_eval], feed_dict={self.s_: batch_memory[:, -self.n_features:],self.s: batch_memory[:, :self.n_features]})#用t+1的状态带入eval network先选出动作action_value = self.sess.run(self.q_eval, feed_dict={self.s: batch_memory[:, -self.n_features:]})#维度为[batch_size, 1]action = np.argmax(action_value, axis=1)#下面这几步十分重要. q_next, q_eval 包含所有 action 的值, 而我们需要的只是已经选择好的 action 的值, 其他的并不需要.所以我们将其他的 action 值全变成 0, 将用到的 action 误差值 反向传递回去, 作为更新凭据.#这是我们最终要达到的样子, 比如 q_target - q_eval = [1, 0, 0] - [-1, 0, 0] = [2, 0, 0]# q_eval = [-1, 0, 0] 表示这一个记忆中有我选用过 action 0, 而action0带来的 Q(s, a0)=-1,而其他的 Q(s, a1)=Q(s, a2)=0# q_target = [1, 0, 0] 表示这个记忆中的 r+gamma*maxQ(s_) = 1, 而且不管在 s_ 上我们取了哪个 action# 我们都需要对应上 q_eval 中的 action 位置, 所以就将 q_target的1放在了 action0的位置.# 下面也是为了达到上面说的目的, 不过为了更方面让程序运算, 达到目的的过程有点不同.# 是将 q_eval 全部赋值给 q_target, 这时 q_target-q_eval 全为 0,# 不过 我们再根据 batch_memory 当中的 action 这个 column 来给 q_target 中的对应的 memory-action 位置来修改赋值.# 使新的赋值为 reward + gamma * maxQ(s_), 这样 q_target-q_eval 就可以变成我们所需的样子.q_target = q_eval.copy()#每个样本下标batch_index = np.arange(self.batch_size, dtype=np.int32)#记录每个样本执行的动作eval_act_index = batch_memory[:, self.n_features].astype(int)#记录每个样本动作的奖励reward = batch_memory[:, self.n_features + 1]#生成每个样本中q值对应动作的更新,即生成的q现实,q_target[batch_index, eval_act_index]=reward+self.gamma * q_next[batch_index, action]#假如在这个 batch 中, 我们有2个提取的记忆, 根据每个记忆可以生产3个 action 的值:#q_eval =[[1, 2, 3],[4, 5, 6]], 另q_target = q_eval.copy()#然后根据 memory 当中的具体 action 位置来修改 q_target 对应 action 上的值:#比如在:记忆 0 的 q_target 计算值是 -1, 而且我用了 action 0;忆1的 q_target 计算值是-2, 而且我用了 action 2:#q_target =[[-1, 2, 3],[4, 5, -2]]#所以 (q_target - q_eval) 就变成了:[[(-1)-(1), 0, 0],[0, 0, (-2)-(6)]]#最后我们将这个 (q_target - q_eval) 当成误差, 反向传递会神经网络#所有为 0 的 action 值是当时没有选择的 action, 之前有选择的 action 才有不为0的值.#我们只反向传递之前选择的 action 的值,_, self.cost = self.sess.run([self._train_op, self.loss],feed_dict={self.s: batch_memory[:, :self.n_features],self.q_target: q_target})self.cost_his.append(self.cost) # 记录 cost 误差#每调用一次learn,降低一次epsilon,即行为随机性self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_maxself.learn_step_counter += 1def plot_cost(self):import matplotlib.pyplot as pltplt.plot(np.arange(len(self.cost_his)), self.cost_his)plt.ylabel('Cost')plt.xlabel('training steps')plt.show()
三、Why Dueling DQN
DQN的网络结构如下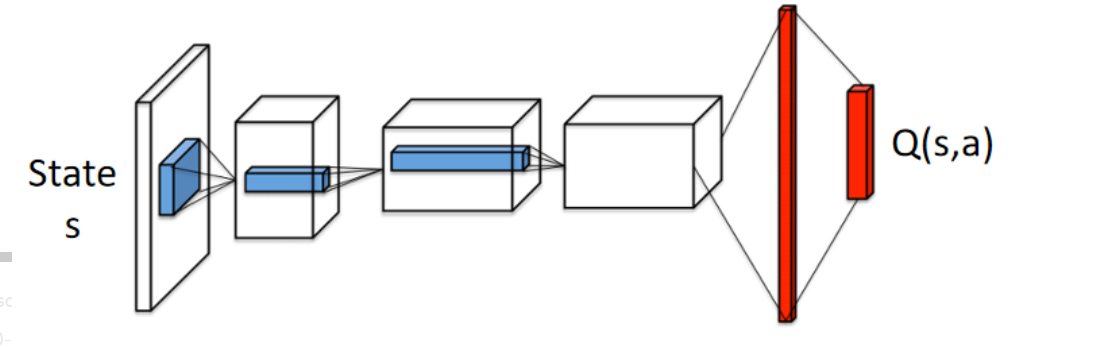
Q ( s , a ) Q(s,a) Q(s,a)表示了状态s下动作a的价值。因为有状态s这个条件, Q ( s , a ) Q(s,a) Q(s,a)并不能完全代表状态a的价值,因为有时候在某种state,无论做什么动作,对下一个state都没有多大的影响,而在一个好的state,无论做什么action,都能得到很高的value;在一个很差的state,无论做什么action,都只会得到一个很低的value。
因此提出了Dueling DQN结构,愿望是衡量状态s的价值 V ( s ) V(s) V(s)和动作a的价值 A ( s , a ) A(s,a) A(s,a)。再讲状态的价值 V ( s ) V(s) V(s)和动作的价值 A ( s , a ) A(s,a) A(s,a)相加得到状态s下动作a的价值 Q ( s , a ) Q(s,a) Q(s,a)。
基于上面思想,Dueling DQN结构设计如下: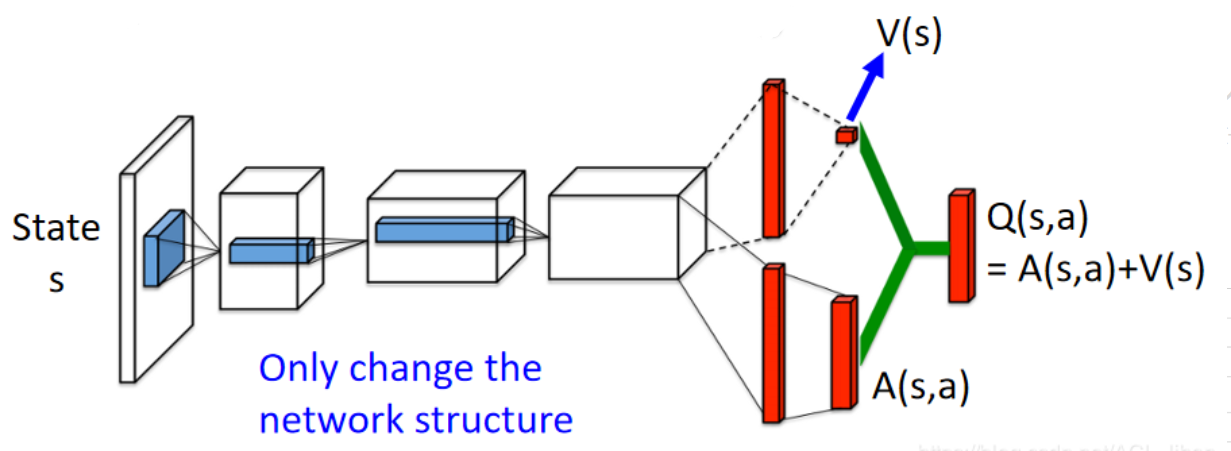
V ( s ) V(s) V(s)是一个标量, A ( s , a ) A(s,a) A(s,a)是一个向量。在相加时 V ( s ) V(s) V(s)会自动复制到与 A ( s , a ) A(s,a) A(s,a)维度一致。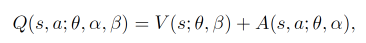
既然是衡量动作动作的价值,为什么不直接 A ( a ) A(a) A(a)去衡量呢?为什么用 A ( s , a ) A(s,a) A(s,a)呢?这个理解是非常直观的。动作本身是没有好坏的,只有在一定状态下,动作才有好坏。比如,下围棋时,再不考虑当前局面是,落子在哪个位置是没有意义的,只有能够适应局面的落子才是有意义的。将 Q ( s , a ) Q(s,a) Q(s,a)分离为 V ( s ) V(s) V(s)和 A ( s , a ) A(s,a) A(s,a)是为了尽可能分离出状态的价值和固定状态下,每个动作的价值。
A ( s , a ) A(s,a) A(s,a)是衡量每个动作的价值,在固定的状态s下,动作是有好有坏的。可以设定好动作的价值大于0,坏动作的价值小于0(这里的好坏是相对的,准确的说不是价值,是Advantage)。并且状态s下,所有动作的价值的和为0,即 ∑ A ( s , _ ) = 0 ∑A(s,\_)=0 ∑A(s,_)=0,在这个基础上进行对 V ( s ) V(s) V(s)和 A ( s , a ) A(s,a) A(s,a)的更新。
从结构可以看出Dueling DQN在直观理解上是非常合理的,但是根据李宏毅老师课上展示的效果来看,效果其实并不理想。
四、 Dueling DQN的Agent编写
Dueling DQN与DQN的网络结构不同,其他过程相似。着重是更改原来DQN Agent的build_net()方法。
之前构建的方式是通过一个隐藏层直接获得q值
with tf.variable_scope('l1'):w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)#求出q估计值,长度为n_actions的向量self.q_eval = tf.matmul(l1, w2) + b2
现在将q_eval 拆分为状态价值v和动作价值a,其中动作价值a的均值为0(q_target需要做同样的改动):
#状态的价值with tf.variable_scope('value'):w21 = tf.get_variable('w21', [n_l1, 1], initializer=w_initializer, collections=c_names)b21 = tf.get_variable('b21', [1], initializer=b_initializer, collections=c_names)vs_out = tf.matmul(l1, w21) + b21#动作的advantagewith tf.variable_scope('advantage'):w22 = tf.get_variable('w22', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b22 = tf.get_variable('b22', [1, self.n_actions], initializer=b_initializer, collections=c_names)aa = tf.matmul(l1, w22) + b22#为了不让A直接学成了Q, 我们减掉了A的均值,此时A的均值始终为0aa_out = aa - tf.reduce_mean(aa, axis=1, keep_dims=True)#合并V和A, 求出q估计值with tf.variable_scope('Q'):self.q_eval = vs_out + aa_out
完整的Dueling DQN的agent代码如下:
class Dueling_DeepQNetwork(object):#replace_target_iter为更新target network的步数,防止target network和eval network差别过大#memory_size为buffer储存记忆上线,方便使用以前记忆学习def __init__(self, n_actions, n_features,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9,replace_target_iter=300,memory_size=500,batch_size=32,e_greedy_increment=None,output_graph=False):self.n_actions = n_actionsself.n_features = n_featuresself.lr = learning_rateself.gamma = reward_decayself.epsilon_max = e_greedy # epsilon后面奖励对前面的递减参数self.replace_target_iter = replace_target_iter # 更换 target_net 的步数self.memory_size = memory_size # 记忆上限self.batch_size = batch_size # 每次更新时从 memory 里面取多少记忆出来self.epsilon_increment = e_greedy_increment # epsilon 的增量#epsilon = 0等于0时,后面的奖励创传不到前面,前面的状态就开启随机探索模式self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max # 是否开启探索模式, 并逐步减少探索次数# 记录学习次数 (用于判断是否更换 target_net 参数)self.learn_step_counter = 0# 初始化全 0 记忆 [s, a, r, s_], 实际上feature为状态的维度,n_features*2分别记录s和s_,+2记录a和rself.memory = np.zeros((self.memory_size, n_features*2+2))self._build_net()#替换 target net 的参数t_params = tf.get_collection('target_net_params') #提取 target_net 的参数e_params = tf.get_collection('eval_net_params') # 提取 eval_net 的参数#将eval_network中每一个variable的值赋值给target network的对应变量self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)] #更新 target_net 参数self.sess = tf.Session()if output_graph:tf.summary.FileWriter("logs/", self.sess.graph)self.sess.run(tf.global_variables_initializer())#用于记录# 记录所有 cost 变化self.cost_his = []#李宏毅老师克重的relpay buffer,通过以往的记忆中不断训练#这是DQN变为off-policy的核心def store_transition(self, s, a, r, s_):#如果DeepQNetwork中定义了memory_counter,进行记忆存储if not hasattr(self, 'memory_counter'):self.memory_counter = 0#记录一条 [s, a, r, s_] 记录transition = np.hstack((s, [a, r], s_))#总 memory 大小是固定的, 如果超出总大小, 旧 memory 就被新 memory 替换index = self.memory_counter % self.memory_size #类似hashmap赋值思想self.memory[index, :] = transition #进行替换self.memory_counter += 1#建立神经网络#此处建立两个申请网络,一个为target network,用于得到q现实。一个为eval_network,用于得到q估计#target network和eval_network结构一样,target network用比较老的参数,eval_network为真正训练的神经网络def _build_net(self):tf.reset_default_graph() #清空计算图#创建eval神经网络,及时提升参数self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # 用来接收 observation,即神经网络的输入self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # q_target的值, 这个之后会通过计算得到,神经网络的输出#eval_net域下的变量with tf.variable_scope('eval_net'):#c_names用于在一定步数之后更新target network#GLOBAL_VARIABLES作用是collection默认加入所有的Variable对象,用于共享c_names = ['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES]n_l1 = 10 #n_l1为network隐藏层神经元的个数w_initializer = tf.random_normal_initializer(0.,0.3)b_initializer = tf.constant_initializer(0.1)#eval_network第一层全连接神经网络with tf.variable_scope('l1'):w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)l1 = tf.nn.relu(tf.matmul(self.s, w1)+b1)#状态的价值with tf.variable_scope('value'):w21 = tf.get_variable('w21', [n_l1, 1], initializer=w_initializer, collections=c_names)b21 = tf.get_variable('b21', [1], initializer=b_initializer, collections=c_names)vs_out = tf.matmul(l1, w21) + b21#动作的advantagewith tf.variable_scope('advantage'):w22 = tf.get_variable('w22', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b22 = tf.get_variable('b22', [1, self.n_actions], initializer=b_initializer, collections=c_names)aa = tf.matmul(l1, w22) + b22#为了不让A直接学成了Q, 我们减掉了A的均值,此时A的均值始终为0aa_out = aa - tf.reduce_mean(aa, axis=1, keep_dims=True)#合并V和A, 求出q估计值with tf.variable_scope('Q'):self.q_eval = vs_out + aa_outwith tf.variable_scope('loss'): # 求误差#使用平方误差self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))with tf.variable_scope('train'): # 梯度下降optimizer = tf.train.RMSPropOptimizer(self.lr)self._train_op = optimizer.minimize(self.loss)#创建target network,输入选择一个action后的状态s_,输出q_targetself.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # 接收下个 observationwith tf.variable_scope('target_net'):c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]# target_net 的第一层fc, collections 是在更新 target_net 参数时会用到with tf.variable_scope('l1'):w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)#状态的价值with tf.variable_scope('value'):w21 = tf.get_variable('w21', [n_l1, 1], initializer=w_initializer, collections=c_names)b21 = tf.get_variable('b21', [1], initializer=b_initializer, collections=c_names)vs_out = tf.matmul(l1, w21) + b21#动作的advantagewith tf.variable_scope('advantage'):w22 = tf.get_variable('w22', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)b22 = tf.get_variable('b22', [1, self.n_actions], initializer=b_initializer, collections=c_names)aa = tf.matmul(l1, w22) + b22#为了不让A直接学成了Q, 我们减掉了A的均值,此时A的均值始终为0aa_out = aa - tf.reduce_mean(aa, axis=1, keep_dims=True)#合并V和A, 求出q估计值with tf.variable_scope('Q'):self.q_next = vs_out + aa_outprint(self.q_next)def choose_action(self, observation):#根据observation(state)选行为#使用eval network选出state下的行为估计#将observation的shape变为(1, size_of_observation),行向量变为列向量才能与NN维度统一observation = observation[np.newaxis, :]if np.random.uniform() < self.epsilon:action_value = self.sess.run(self.q_eval, feed_dict={self.s:observation})action = np.argmax(action_value)else:action = np.random.randint(0, self.n_actions) #随机选择return actiondef learn(self):if self.learn_step_counter % self.replace_target_iter ==0:self.sess.run(self.replace_target_op)print('\ntarget_params_replaced\n')#从memory中随机抽取batch_size这么多记忆if self.memory_counter > self.memory_size: #说明记忆库已经存满,可以从记忆库任意位置收取sample_index = np.random.choice(self.memory_size, size=self.batch_size)else: #记忆库还没有存满,从现有的存储记忆提取sample_index = np.random.choice(self.memory_counter, size=self.batch_size)batch_memory= self.memory[sample_index, :]# 获取q_next即q现实(target_net产生的q)和q_eval(eval_net产生的q)#q_next和q_eval都是一个向量,包含了对应状态下所有动作的q值#实际上feature为状态的维度,batch_memory[:, -self.n_features:]为s_,即状态s采取动作action后的状态s_, batch_memory[:, :self.n_features]为s# 获取q_next即q现实(target_net产生的q)和q_eval(eval_net产生的q)#q_next和q_eval都是一个向量,包含了对应状态下所有动作的q值#实际上feature为状态的维度,batch_memory[:, -self.n_features:]为s_,即状态s采取动作action后的状态s_, batch_memory[:, :self.n_features]为s#q_next, q_eval的维度为[None,n_actions]q_next, q_eval = self.sess.run([self.q_next, self.q_eval], feed_dict={self.s_: batch_memory[:, -self.n_features:],self.s: batch_memory[:, :self.n_features]})#下面这几步十分重要. q_next, q_eval 包含所有 action 的值, 而我们需要的只是已经选择好的 action 的值, 其他的并不需要.所以我们将其他的 action 值全变成 0, 将用到的 action 误差值 反向传递回去, 作为更新凭据.#这是我们最终要达到的样子, 比如 q_target - q_eval = [1, 0, 0] - [-1, 0, 0] = [2, 0, 0]# q_eval = [-1, 0, 0] 表示这一个记忆中有我选用过 action 0, 而action0带来的 Q(s, a0)=-1,而其他的 Q(s, a1)=Q(s, a2)=0# q_target = [1, 0, 0] 表示这个记忆中的 r+gamma*maxQ(s_) = 1, 而且不管在 s_ 上我们取了哪个 action# 我们都需要对应上 q_eval 中的 action 位置, 所以就将 q_target的1放在了 action0的位置.# 下面也是为了达到上面说的目的, 不过为了更方面让程序运算, 达到目的的过程有点不同.# 是将 q_eval 全部赋值给 q_target, 这时 q_target-q_eval 全为 0,# 不过 我们再根据 batch_memory 当中的 action 这个 column 来给 q_target 中的对应的 memory-action 位置来修改赋值.# 使新的赋值为 reward + gamma * maxQ(s_), 这样 q_target-q_eval 就可以变成我们所需的样子.q_target = q_eval.copy()#每个样本下标batch_index = np.arange(self.batch_size, dtype=np.int32)#记录每个样本执行的动作eval_act_index = batch_memory[:, self.n_features].astype(int)#记录每个样本动作的奖励reward = batch_memory[:, self.n_features + 1]#生成每个样本中q值对应动作的更新,即生成的q现实,q_target[batch_index, eval_act_index]=reward+self.gamma * np.max(q_next, axis=1)#假如在这个 batch 中, 我们有2个提取的记忆, 根据每个记忆可以生产3个 action 的值:#q_eval =[[1, 2, 3],[4, 5, 6]], 另q_target = q_eval.copy()#然后根据 memory 当中的具体 action 位置来修改 q_target 对应 action 上的值:#比如在:记忆 0 的 q_target 计算值是 -1, 而且我用了 action 0;忆1的 q_target 计算值是-2, 而且我用了 action 2:#q_target =[[-1, 2, 3],[4, 5, -2]]#所以 (q_target - q_eval) 就变成了:[[(-1)-(1), 0, 0],[0, 0, (-2)-(6)]]#最后我们将这个 (q_target - q_eval) 当成误差, 反向传递会神经网络#所有为 0 的 action 值是当时没有选择的 action, 之前有选择的 action 才有不为0的值.#我们只反向传递之前选择的 action 的值,_, self.cost = self.sess.run([self._train_op, self.loss],feed_dict={self.s: batch_memory[:, :self.n_features],self.q_target: q_target})self.cost_his.append(self.cost) # 记录 cost 误差#每调用一次learn,降低一次epsilon,即行为随机性self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_maxself.learn_step_counter += 1def plot_cost(self):import matplotlib.pyplot as pltplt.plot(np.arange(len(self.cost_his)), self.cost_his)plt.ylabel('Cost')plt.xlabel('training steps')plt.show()
可以看出其实Double DQN和Dueling DQN都是提升DQN效果的技巧。实际上可以将两种技术同时放在DQN中进行使用。




























还没有评论,来说两句吧...