【Python强化学习】时序差分法Sarsa算法和Qlearning算法在冰湖问题中实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~
时序差分算法
时序差分法在一步采样之后就更新动作值函数Q(s,a),而不是等轨迹的采样全部完成后再更新动作值函数。
在时序差分法中,对轨迹中的当前步的(s,a)的累积折扣回报G,用立即回报和下一步的(s^′,a^′)的折扣动作值函数之和r+γQ(s^′,a^′)来计算,即:
G=r+γQ(s^′,a^′)
在递增计算动作值函数时,用一个[0,1]之间的步长α来代替1/N(s,a)。动作值函数Q(s,a)的递增计算式为:
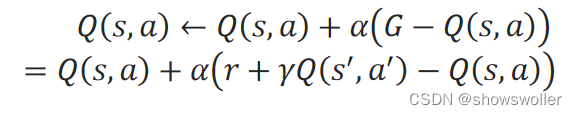
Sarsa算法与Qlearning算法
在蒙特卡罗法中,当前状态s下,对动作的采样是完全依据Q(s,a)来进行的,选中a的概率与对应的Q(s,a)的大小成正比。在时序差分法中,对动作的采样采用ε-贪心策略,Q(s,a)最大的动作被选择的概率为ε/|A|+1−ε,其他动作被选择的概率为ε/|A|,|A|是动作空间的大小。
Sarsa算法的采样和改进都采用了ε-贪心策略,是同策略的算法。
Qlearning算法对动作的采样采用的是ε-贪心策略,而对动作值函数Q(s,a)的更新采用的是贪心策略,因此,它是异策略的算法:
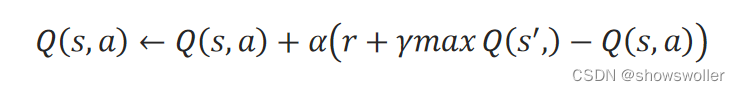
算法流程图如下
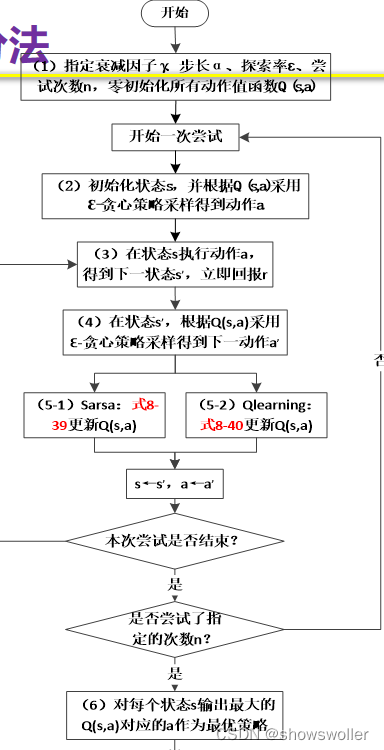
算法在冰湖问题中求解结果如下

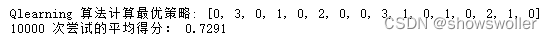
要注意的是,时序差分法也存在方差大,不稳定的问题,每次实验的得分可能会相差较大
部分代码如下
# 基于贪心策略,根据当前状态s的所有动作值函数,采样输出动作值def greedy_sample(Q_s):# Q_s:状态s的所有动作值函数,一维数组max_Q = np.max( Q_s )action_list = np.where( max_Q == Q_s )[0] # 最大动作值函数可能有多个action对应a = np.random.choice( action_list )return a# 基于e-gredy贪心策略,根据当前状态s的所有动作值函数,采样输出动作值def epsilon_greedy_sample(Q_s, n_actions, epsilon):# Q_s:状态s的所有动作值函数,一维数组# <时表示利用,否则为探索if np.random.uniform(0,1) <= 1-epsilon:a = greedy_sample(Q_s)else:a = np.random.choice(n_actions)return a# 时序差分算法def TD(env, gamma=1.0, alpha=0.01, epsilon=0.1, n_episodes=10000, algorithm="Qlearning"):Q = np.zeros([env.observation_space.n, env.action_space.n]) # 用数组来存储动作值函数n_actions = env.action_space.nfor i in range(n_episodes):# 开始一次尝试sum_rewards = 0steps = 0s = env.reset() # 获取初始sa = epsilon_greedy_sample(Q[s], n_actions, epsilon)# 逐步推进while(True):next_s, r, done, _ = env.step(a) # 执行动作a# e-gredy贪心策略得到下一动作a'next_a = epsilon_greedy_sample( Q[next_s], n_actions, epsilon )# 更新动作值函数if(done):Q[s, a] = Q[s, a] + alpha * ( r - Q[s, a] )else:if algorithm == "Qlearning":Q[s, a] = Q[s, a] + alpha * ( r + gamma * np.max(Q[next_s]) - Q[s, a] )else:Q[s, a] = Q[s, a] + alpha * ( r + gamma*Q[next_s, next_a] - Q[s, a] )# 更新当前s,as = next_sa = next_asum_rewards += r * gamma**stepssteps += 1if(done):break#print('尝试次:%s: 共运行步数:%s, 本次累积折扣回报:%.1f' % (i+1, steps, sum_rewards))pi = []for s in range(env.observation_space.n):a = greedy_sample( Q[s] )pi.append(a)return pi
创作不易 觉得有帮助请点赞关注收藏~~~

























(sink端)")
")

使用 Kibana 操作 ES")





还没有评论,来说两句吧...