K-Means、层次聚类算法讲解及对iris数据集聚类实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~
聚类(Clustering) 一个重要的非监督学习方法
聚类-即是将相似的对象组成多个类簇,以此来发现数据之间的关系
聚类(簇):数据对象的集合 在同一个聚类(簇)中的对象彼此相似 不同簇中的对象则相异
聚类是一种无指导的学习:没有预定义的类编号
聚类分析的数据挖掘功能 作为一个独立的工具来获得数据分布的情况
作为其他算法(如:特征和分类)的预处理步骤
聚类的“好坏”没有绝对标准
一、K-Means聚类
- 算法原理
给定一个n个对象或元组的数据库,一个划分方法构建数据的k个划分,每个划分表示一个簇, k<=n,而且满足
1)每个组至少包含一个对象; 2)每个对象属于且仅属于一个组
划分时要求同一个聚类中的对象尽可能的接近或相关,不同聚类中的对象尽可能的原理或不同
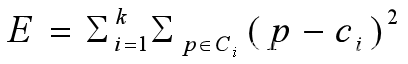
一般,簇的表示有两种方法:
1)k-平均算法,由簇的平均值来代表整个簇;
2)k中心点算法,由处于簇的中心区域的某个值代表整个簇
- K-means算法

用于划分的K-Means算法,其中每个簇的中心都用簇中所有对象的均值来表示
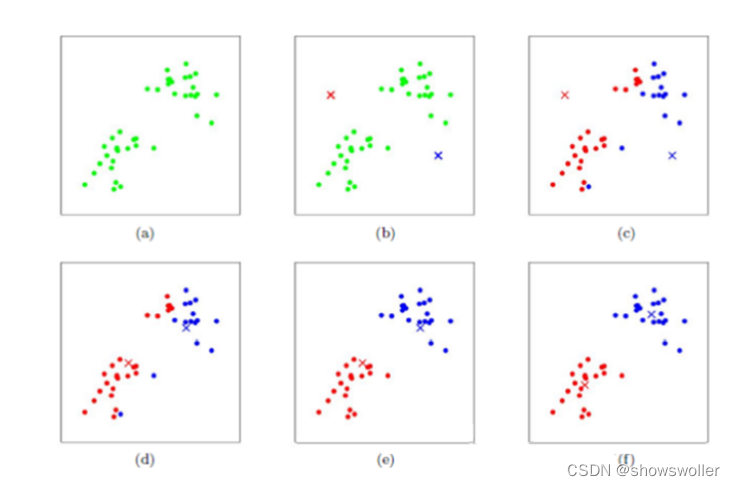
sklearn实现iris数据K-Means聚类

代码如下
from sklearn.datasets import load_irisfrom sklearn.cluster import KMeansiris = load_iris()#加载数据集X = iris.dataestimator = KMeans(n_clusters = 3)#构造K-Means聚类模型estimator.fit(X)#数据导入模型进行训练label_pred = estimator.labels_#获取聚类标签print(label_pred)#显示各个样本所属的类别标签
kmeans算法优点如下
可扩展性较好,算法复杂度为O(nkt),其中n为对象总数,k是簇的个数,t是迭代次数
经常终止于局部最优解
缺点如下
只有当簇均值有定义的情况下,k均值方法才能使用。(某些分类属性的均值可能没有定义)
用户必须首先给定簇数目
不适合发现非凸形状的簇,或者大小差别很大的簇
对噪声和离群点数据敏感
二、层次聚类
算法原理
层次聚类 (Hierarchical Clustering)就是按照某种方法进行层次分类,直到满足某种条件为止。层次聚类主要分成两类
凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者满足某个终结条件
分裂:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终止条件
- 层次聚类算法

- 层次聚类Python实现
Python中层次聚类的函数是A gglomerativeClustering(),最重要的参数有3个:n_clusters为聚类数目,affinity为样本距离定义,linkage是类间距离的定义,有3种取值
ward:组间距离等于两类对象之间的最小距离
average:组间距离等于两组对象之间的平均距离
complete:组间距离等于两组对象之间的最大距离
Python层次聚类实现
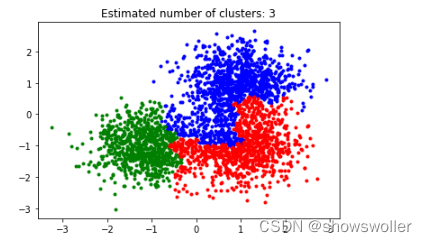
部分代码如下
from sklearn.datasets.samples_generator import make_blobsfrom sklearn.cluster import AgglomerativeClusteringimport numpy as npimport matplotlib.pyplot as pltfrom itertools import cycle #python自带的迭代器模块#产生随机数据的中心centers = [[1, 1], [-1, -1], [1, -1]]#产生的数据个数n_samples = 3000#生产数据X, lables_true = make_blobs(n_samples = n_samples, centers= centers, cluster_std = 0.6,random_state = 0)#设置分层聚类函数linkages = ['ward', 'average', 'complete']n_clusters_ = 3ac = AgglomerativeClustering(linkage = linkages[2],n_clusters = n_clusters_)#训练数据ac.fit(X)#每个数据colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')for k, col in zip(range(n_clusters_), colors):#根据lables中的值是否等于k,重新组成一个True、False的数组my_members = lables == k#X[my_members, 0]取出my_members对应位置为True的值的横坐标plt.plot(X[my_members, 0], X[my_members, 1], col + '.')plt.title('Estimated number of clusters: %d' % n_clusters_)plt.show()
创作不易 觉得有帮助请点赞关注收藏~~~

































还没有评论,来说两句吧...