Spring Boot 整合 kafka
Spring Boot 整合 kafka
文章更新时间:2021/10/29
一、创建Spring boot 工程
创建过程不再描述,创建后的工程结构如下:
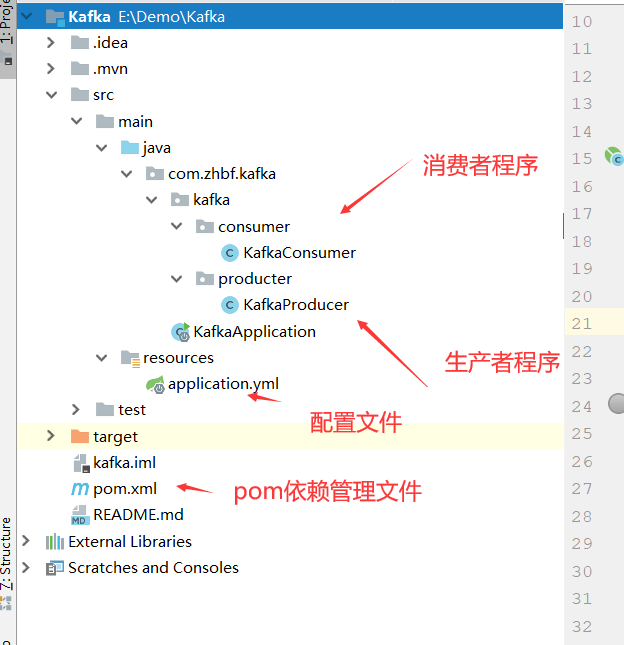
POM文件
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.zhbf</groupId><artifactId>kafka</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka</name><description>kafka示例工程</description><properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><spring-boot.version>2.2.9.RELEASE</spring-boot.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!--引入kafka依赖--><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.4.1.RELEASE</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>${spring-boot.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.3.7.RELEASE</version><configuration><mainClass>com.zhbf.kafka.KafkaApplication</mainClass></configuration><executions><execution><id>repackage</id><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build></project>
application.yml配置文件
server:port: 8080spring:application:name: kafkakafka:bootstrap-servers: 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094 # kafka集群信息producer: # 生产者配置retries: 3 # 设置大于0的值,则客户端会将发送失败的记录重新发送batch-size: 16384 #16Kbuffer-memory: 33554432 #32Macks: 1# 指定消息key和消息体的编解码方式key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: zhTestGroup # 消费者组enable-auto-commit: false # 关闭自动提交auto-offset-reset: earliest # 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerlistener:# 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交# RECORD# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交# BATCH# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交# TIME# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交# COUNT# TIME | COUNT 有一个条件满足时提交# COUNT_TIME# 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交# MANUAL# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种# MANUAL_IMMEDIATEack-mode: manual_immediate
启动ZK、kafka通讯的服务器broker,并启动消费者监听
启动方式参考上一篇文章,戳这里~
启动SpringbootApplication.java
出现下图界面则说明工程创建好了:

二、创建kafka生产者类,并通过控制器调用
kafka生产者类
/*** kafka生产者【实际上就是一个Controller,用来进行消息生产】*/@RestControllerpublic class KafkaProducer {private final static String TOPIC_NAME = "zhTest"; //topic的名称@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@RequestMapping("/send")public void send() {//发送功能就一行代码~kafkaTemplate.send(TOPIC_NAME, "key", "test message send~");}}
三、创建kafka消费者类,并通过@KafkaListener注解消费消息
kafka消费者类
/*** kafka消费者*/@Componentpublic class KafkaConsumer {//kafka的监听器,topic为"zhTest",消费者组为"zhTestGroup"@KafkaListener(topics = "zhTest", groupId = "zhTestGroup")public void listenZhugeGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {String value = record.value();System.out.println(value);System.out.println(record);//手动提交offsetack.acknowledge();}/*//配置多个消费组@KafkaListener(topics = "zhTest",groupId = "zhTestGroup2")public void listenTulingGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {String value = record.value();System.out.println(value);System.out.println(record);ack.acknowledge();}*/}
启动服务并调用


转自:https://www.cnblogs.com/riches/p/11720068.html





























![[C/C++] 详解getline与getchar的一个著名的坑](https://image.dandelioncloud.cn/images/20230531/cb982396fc8f4033b9114f93239b272d.png "[C/C++] 详解getline与getchar的一个著名的坑")




还没有评论,来说两句吧...