hadoop 词频统计
1)先写words文件
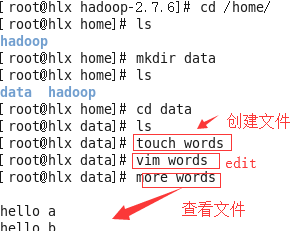
2)再将words上传到hdfs中,可以直接运行
bin/hadoop fs -put /home/data/words指定文件路径 /words目标路


浏览器查看文件 
可以单击Download下载;
必须配置: C:\Windows\System32\drivers\etc\hosts
192.168.X.X hlx
![Image 1][]
2)查看案例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar

运行wordCount
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /words文件源 /out输出路径

查看节点


查看数据
bin/hadoop fs -ls /

bin/hadoop fs -ls /out
![Image 1][]
bin/hadoop fs -cat /out/part-r-00000

![Image 1][]
[Image 1]:




























DAY 2")





还没有评论,来说两句吧...