江湖小白之一起学Python (三)双色球历史数据抓取
温故而知新,前面说了一下抓取信息的基本操作,今天抓取还是非常的简单,我们要抓取红球和蓝球的号码,我们顺道来回味下前面的操作,再了解下html标签,抓取双色球历史数据,首先我们要找到抓取的网址,就拿500彩票的来:http://datachart.500.com/ssq/history/history.shtml
先在浏览器打开这个网址,我们会看到如下,这是最近30期的数据:
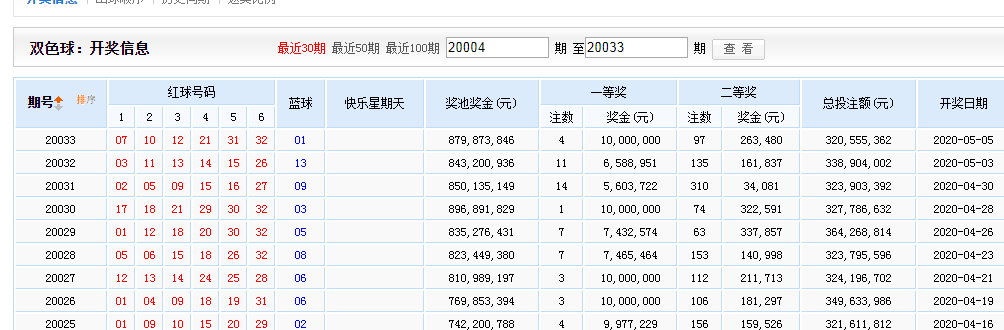
老办法,我们轻轻的按下F12,弹出开发者工具,然后移动到07上,再轻轻点一下,如下:
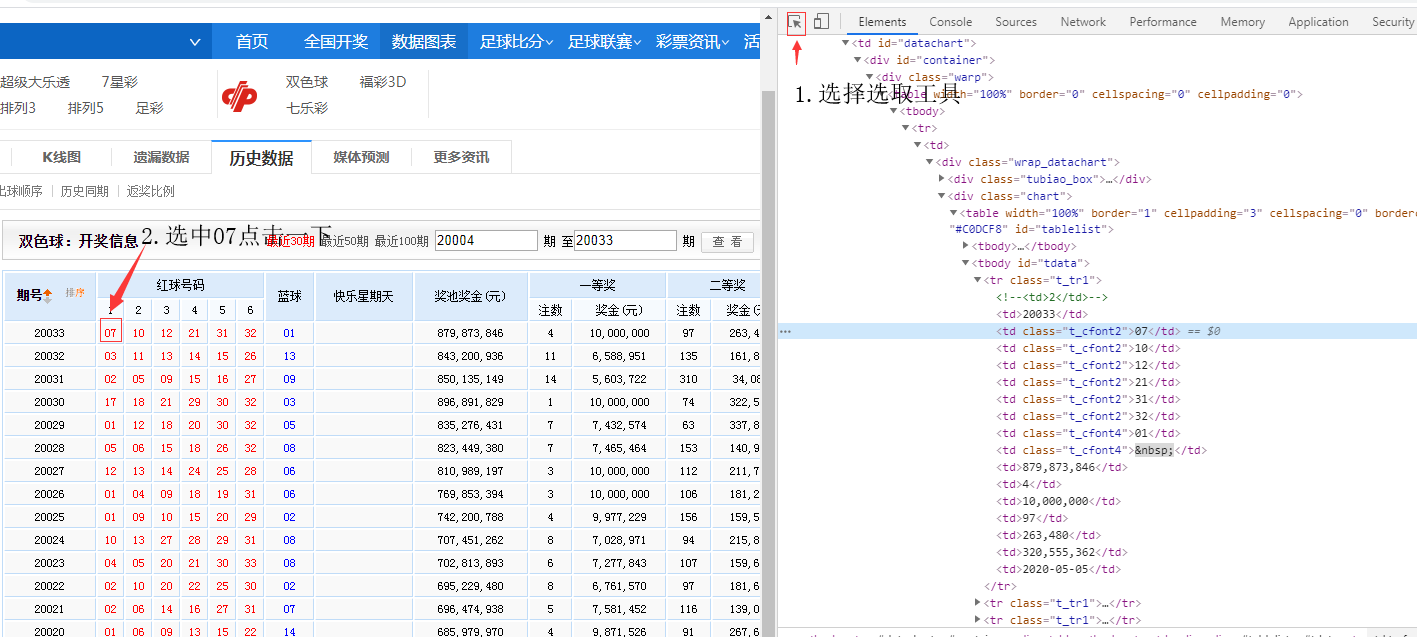
这个时候,有细心的童鞋会问,这个怎么出现在了右边,这是为了方便调试和观察,具体设置在开发工具的右
上角,竖排的3个点里面,请自行研究
这里我也顺道说下,这个页面默认显示最新30条数据,如果我想获取更多的历史数据怎么办,这里有个方法,通过观察,它这里有个搜索的地方 ,我们先选择开发者工具中的
,我们先选择开发者工具中的 ,Network选项再选择XHR,这个表示XMLHttpRequest方法发送的请求,简单的说就是动态网络请求,隐藏很多静态JS,图片的链接,方便查看,然后在点击
,Network选项再选择XHR,这个表示XMLHttpRequest方法发送的请求,简单的说就是动态网络请求,隐藏很多静态JS,图片的链接,方便查看,然后在点击 搜索一下,会出现:
搜索一下,会出现:
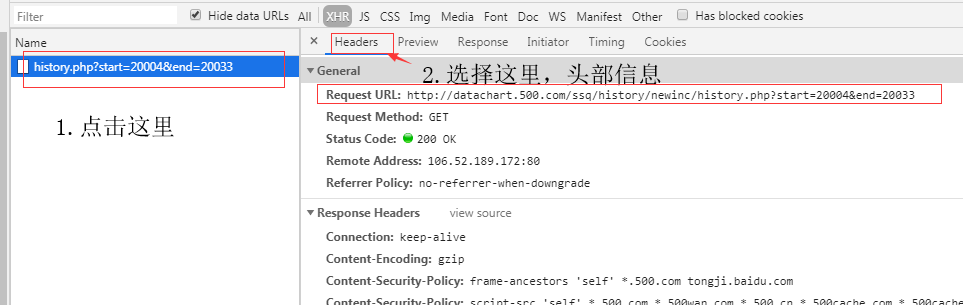
这里我们能获取到查询的get请求地址:http://datachart.500.com/ssq/history/newinc/history.php?start=20001&end=20033,它这里表示的是start是开始的期数,end结束的期数。这样我们就可以根据自己想要查询的期数选择统计,我们单独把这个地址放到浏览器看看,会出现:
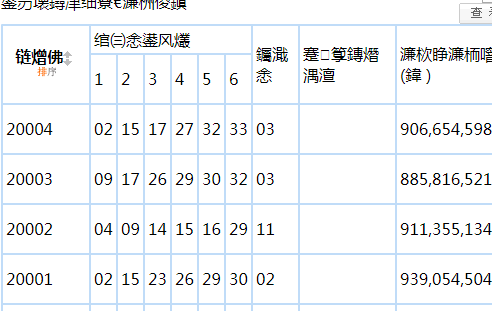
乱码就不管了,这是它页面编码问题,我们只是要获取数字,这里跟历史页的是一样的,以上都是在讲用开发者工具的使用,以及html的追踪观察,上面这些操作是一个写爬虫所必须要掌握的东西,如果不太懂,请自行深入学习,
通过观察,这些数据是以表格的形式展示的,这些数据都是在 id为tdata的tbody标签中,经搜索这个标签是唯一的,那我们怎么获取到这个标签里的内容呢,下面我们一步一步来:
id为tdata的tbody标签中,经搜索这个标签是唯一的,那我们怎么获取到这个标签里的内容呢,下面我们一步一步来:
首先我们要先获取页面的源码内容,还是用requests请求,这里的方法前面已经讲了,这里就不再过多说明,直接上代码。如下:
#coding:utf-8import requestsfrom pyquery import PyQuery as pq#双色球历史数据网址url='http://datachart.500.com/ssq/history/newinc/history.php?start=20001&end=20033'response=requests.get(url=url)response.encoding = response.apparent_encoding#获取到页面源码内容content=response.text#用pyquery格式化一下网页内容,下面就可以通过标签提出信息了soup = pq(content)#获取id=tdata的内容tdata=soup("#tdata")print(tdata)
这里我们就获取到了id为tdata的内容,打印一下:

这里是一行有点长,就截取一部分展示了,来,我们继续,table表单的层级关系,是table>tbody>tr>td,我们要获取到td的文本内容,通过观察源代码,我们想要获取的红球和蓝球的号码在1-7的td里面,

那下面就通过这段代码来获取:
#tdata('tr')是获取到id为tdata标签中所有tr标签for data in tdata('tr'): #循环tr标签trcon=pq(data) #获取到tr的html内容,加上pq就是渲染为html格式#下面的格式一样,trcon("td")表示获取到tr下td的内容,.eq(index)这个表示获取到td的第几个元素,#比如第一个td的index就是0,因为排序是从0开始的,.text()是获取到td的文本内容td1 = trcon("td").eq(0).text() #这个是获取到的第一个TD的内容,例如:20033td2 = trcon("td").eq(1).text()td3 = trcon("td").eq(2).text()td4 = trcon("td").eq(3).text()td5 = trcon("td").eq(4).text()td6 = trcon("td").eq(5).text()td7 = trcon("td").eq(6).text()td8 = trcon("td").eq(7).text()print(td1,td2,td3,td4,td5,td6,td7,td8)
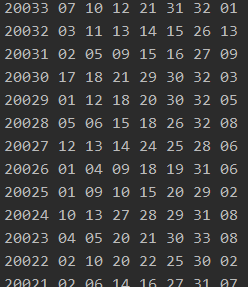
说明在注释上,通过上面的代码我们就获取到了期号,红球和蓝球的号码,打印看下:
到这里有兴趣的童鞋就可以通过这里的数据进行分析,比如,我想获取蓝球在数据中那个号码出现的次数最多,那就可以这样加上,先将蓝球放入到一个数组中:
#定义一个存放蓝球的空数组td_list_blue=[]for data in tdata('tr'):trcon=pq(data)td1 = trcon("td").eq(0).text()td2 = trcon("td").eq(1).text()td3 = trcon("td").eq(2).text()td4 = trcon("td").eq(3).text()td5 = trcon("td").eq(4).text()td6 = trcon("td").eq(5).text()td7 = trcon("td").eq(6).text()td8 = trcon("td").eq(7).text()#print(td1,td2,td3,td4,td5,td6,td7,td8)#td8是蓝球的号码,我们将td8依次放入到数组中td_list_blue.append(td8)#通过下面这句,我们能得到数组出现次数最多的号码,具体可以了解max,set语法result = max(set(td_list_blue), key=td_list_blue.count)print(result)
还可以细一点,就是你想获取蓝球数组前10个号码,你可以这样写:
td_list_blue[:10]
比如要获取第10个到第20个的号码:
td_list_blue[10:20]
以上就是数组的分片,具体可以当知识要点研究下,虽然本人分析了这么久,也没中一张彩票,但还是乐在其中~~!
下面来个完整源码:
#coding:utf-8import requestsfrom pyquery import PyQuery as pqurl='http://datachart.500.com/ssq/history/newinc/history.php?start=20001&end=20033'response=requests.get(url=url)response.encoding = response.apparent_encodingcontent=response.text#用pyquery格式化一下网页内容,下面就可以通过标签提出信息了soup = pq(content)tdata=soup("#tdata")#定义一个存放蓝球的空数组td_list_blue=[]for data in tdata('tr'):trcon=pq(data)td1 = trcon("td").eq(0).text()td2 = trcon("td").eq(1).text()td3 = trcon("td").eq(2).text()td4 = trcon("td").eq(3).text()td5 = trcon("td").eq(4).text()td6 = trcon("td").eq(5).text()td7 = trcon("td").eq(6).text()td8 = trcon("td").eq(7).text()#print(td1,td2,td3,td4,td5,td6,td7,td8)td_list_blue.append(td8)result = max(set(td_list_blue), key=td_list_blue.count)print(td_list_blue[10:len(td_list_blue)])print(td_list_blue)
本篇所讲的其实大部分是在浏览器中开发者工具的基本使用,及requests,pyquery用法的回顾使用,在实际运用中,这些都会经常使用到,所谓工欲善其事,必先利其器,基本的东西常常使用上手了,熟悉了,那接下来就好办了。
好了,这篇就到此结束,下篇可能要讲一些稍微深入点的东西, 江湖不说再见,咱们下篇见!




























:轻松弄懂XHR的使用及如何封装简易axios")





还没有评论,来说两句吧...