江湖小白之一起学Python (四)生成IP池
经过前面反反复复的练习,我觉得基本爬取一些网站是没有什么问题的,今天为什么讲IP池呢,因为很多网站是有反爬虫机制的,如果老是用你的固定Ip去频繁访问的话,会加入它的黑名单,让你一段时间都无法访问,那解决这个问题就是动态改变IP地址去访问,这样基本都不会被封Ip了,比如投票软件,点赞啊,抓下淘宝数据啊什么什么的都会用到动态Ip,问题又来了,从哪里获取到Ip呢,生活比较富裕的童鞋可以弄个http代理,比如站大爷,快代理啊什么的(绝对没有给他们打广告,因为没给我钱~~!),像我这样掉颗饭都要捡起来吃掉的人,这无疑是在我心口插了一把刀,实力不允许啊……容我先喝点西北风压压惊!

那怎么办,当然是自己写个爬虫去爬取免费的http代理,既然是免费,那就说明免费的代理中肯定有很多不能用的,那就要爬来自己过滤一下。
那下面我们快速进入主题,拿站大爷当例子来说,还是比较良心的,每天都有发放免费的http代理,而且是每小时更新一次,感谢有你!
网址是:https://www.zdaye.com/dayProxy.html,打开这个页面我们会看到:

点进去一个看看:
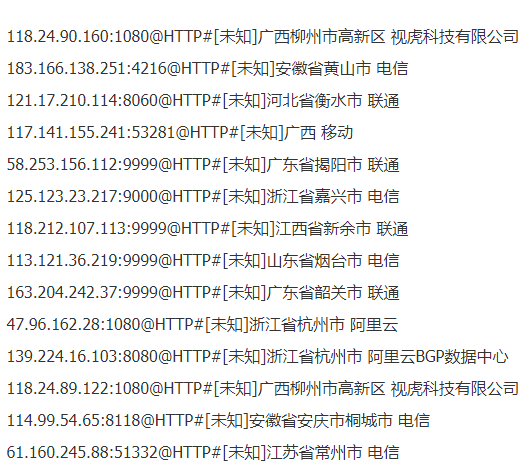
如上图所视,Ip是以文本的形式展示的,那接下来就好办了,我们要抓取这页的IP地址,当前页的网址:https://www.zdaye.com/dayProxy/ip/321046.html
url = 'https://www.zdaye.com/dayProxy/ip/321046.html'response = requests.get(url=url,verify=False)response.encoding = response.apparent_encodingresult=re.findall('<br>(.*?)@HTTP',response.text)print(result)
没看错,就简简单单的这几句就能抓到上面所视的Ip地址,前面3句基本不用说了吧,常规的requests请求,第二句中比以前多了个verify=False,什么意思呢,因为这个网址https的请求的,涉及到SSL证书,加这句就是关闭掉这个认证,但是控制台会出现红色的警告:

如果有强迫症的同学请在上面加上一句:
requests.packages.urllib3.disable_warnings()
第三句不说了,就是编码,第四句这里用到re模块(详细可以去菜鸟教程查看用法:https://www.runoob.com/python/python-reg-expressions.html),这里用到了正则:’
(.*?)@HTTP’,这句什么意思呢,来我们观察下这个网址的源代码,怎么打开前面已经说过了,来,继续看下面:

通过我1000度钛金眼睛的观察发现一个规律,IP地址都在
和@HTTP之间,(.*?)这个就表示获取这两者之间的所有内容,详细了解正则的话,还得另外单独去研究下,这个在爬虫中还是很重要的技能,re.findall表示找到所有复合条件的结果,打印看下:

这里就获取到了ip数组了,接下来我们就要验证这些ip是否可以正常使用,拿淘宝来说,下面我们验证是否能正常访问淘宝网,正常的话就保存到txt文件里
#这里的ips是上面的ip数组,遍历ipfor ip in ips:try:#设置代理ipproxies={'https':ip}#设置头部请求信息,这里封装了浏览器的版本,加入到了请求头User_Agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'headers = {'User-Agent': User_Agent}#开始验证IPr = requests.get(url=url,headers=headers,proxies=proxies,timeout=3)#r.status_code获取访问后状态,200表示请求成功if r.status_code==200:print('成功:',ip)f = open('tbip.txt', 'r+', encoding='utf-8')#先读取txt文件内容tbips = f.read()#txt文件里通过\n换行,通过这个切割成数组tbipstoarray = tbips.split('\n')#判断如果ip不在ip池里则加入if ip not in tbipstoarray:f.write(ip+'\n')f.close()except Exception as e:#打印异常情况print(e)
详细请看注释,基本上应该能看懂吧,不懂的,没关系,咱们继续……,requests.get请求中的timeout=3,表示访问超时时间,一般3秒内请求一个网址成不成功是足够了,不加的会等很长一段时间,这里用到了try ……except ……的方法,目的是防止请求超时或者连接失败异常会阻止程序的运行,Exception是捕获所有异常情况,结果如下:

白嫖兄弟,完整版源码奉上:
#coding:utf-8import requests,rerequests.packages.urllib3.disable_warnings()class IpPool:# 获取ip地址def getip(self):url = 'https://www.zdaye.com/dayProxy/ip/321047.html'response = requests.get(url=url,verify=False)response.encoding = response.apparent_encodingresult=re.findall('<br>(.*?)@HTTP',response.text)print(result)turl='https://www.taobao.com'#调用验证IP方法self.checkip(turl,result)#验证IP并保存def checkip(self,url,ips):for ip in ips:try:proxies={'https':ip}User_Agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'headers = {'User-Agent': User_Agent,}r = requests.get(url=url,headers=headers,proxies=proxies,timeout=3)if r.status_code==200:print('成功:',ip)f = open('tbip.txt', 'r+', encoding='utf-8')tbips = f.read()tbipstoarray = tbips.split('\n')#判断如果ip不在ip池里则加入if ip not in tbipstoarray:f.write(ip+'\n')f.close()except Exception as e:print(e)if __name__ == '__main__':ippool=IpPool()ippool.getip()
这里稍微封装了下,定义了一个class类文件,封装了下方法 ,def就是定义个功能函数,在class内,函数里要加上self表示在这个功能函数里可以调用class内的方法及参数, 这里简单说下,因为这是个class文件,你可以在其它文件里引入这个类文件,if __name__ == ‘__main__‘:就是判断如果是直接运行这个文件,就会调用下面的方法,如果是其它文件引入这个就不会执行,目的是方便调试,平常话不多,一敲代码解释感觉都说不完……

还有关于站大爷,其实它也是有防爬机制的,不要太频繁,有时候会出现通过JS生成cookie后跳转页面,这个就需要访问JS渲染下获取到cookie值,这里只是简单的写了下生成IP池,其实里面扩展下,比如再抓下其它代理的ip地址,多线程操作抓取,多线程验证等等,历经千辛才到达深处,却发现还是看不到尽头,这条路很长……很长……很长…………
好了,这篇基本就到这里, 江湖不说再见,咱们下篇见!


































还没有评论,来说两句吧...