Slipstream中的并行流处理
与[《Kafka中的消费者组》][Kafka]类似,Slipstream中多个流也可以同时接收同一topic的数据进行不同的操作。值得注意的是,Slipstream中的一个Input Stream对应着Kafka中的一个Consumer Group。
1、并行流的建立
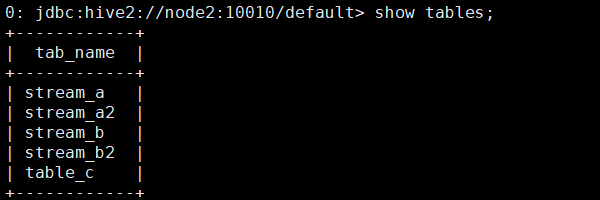
并行流的建立非常简单,在[《Slipstream中的衍生流》][Slipstream]建立的基础上,再建立一个新的输入流和衍生流即可,新建的输入流需与之前的输入流指向同一个topic。为了测试并行,这里指定新建的衍生流增加一个字符串截取的功能,如下:create stream stream_b2 as select id,substr(name||pwd,1,4) as sp from stream_a2;
其中,stream_a2为新建的输入流。
2、并行流处理数据
- 创建Oracle测试表并启动Flume
此操作与《Slipstream中的衍生流》中创建Oracle测试表、启动Flume的操作相同。
- 触发流
创建一个表,用于接收stream_b2传过来的数据,例如:
CREATE TABLE table_c2 (id STRING, sp STRING);
最后,通过下列语句触发流:
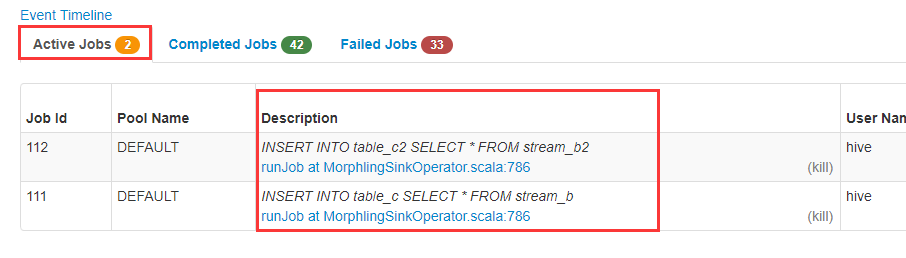
INSERT INTO table_c SELECT * FROM stream_b;INSERT INTO table_c2 SELECT * FROM stream_b2;
通过4044监控界面查看触发是否成功:
- 测试并行流
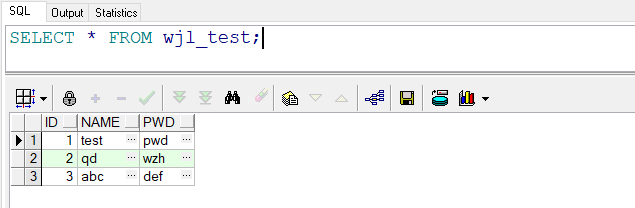
在Oracle中插入几条数据,如下:
查询table_c和table_c2中是否接收到了处理后的全部数据:
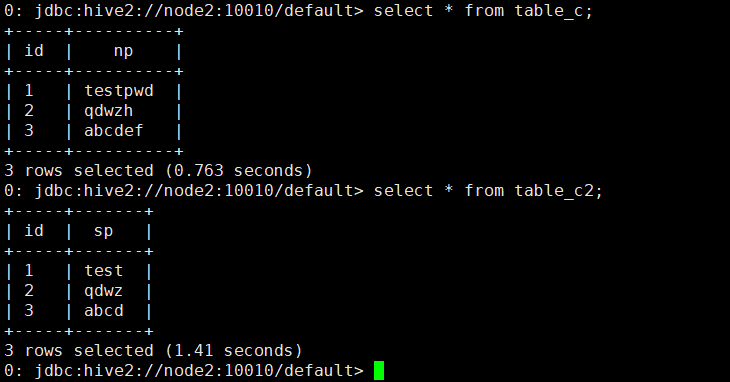
至此,并行流测试成功。


































还没有评论,来说两句吧...