hadoop之wordcount
1、搭建好一个hadoop程序:
hadoop完全伪分布式搭建
2、在myeclipse的安装目录下导入hadoop插件:
效果: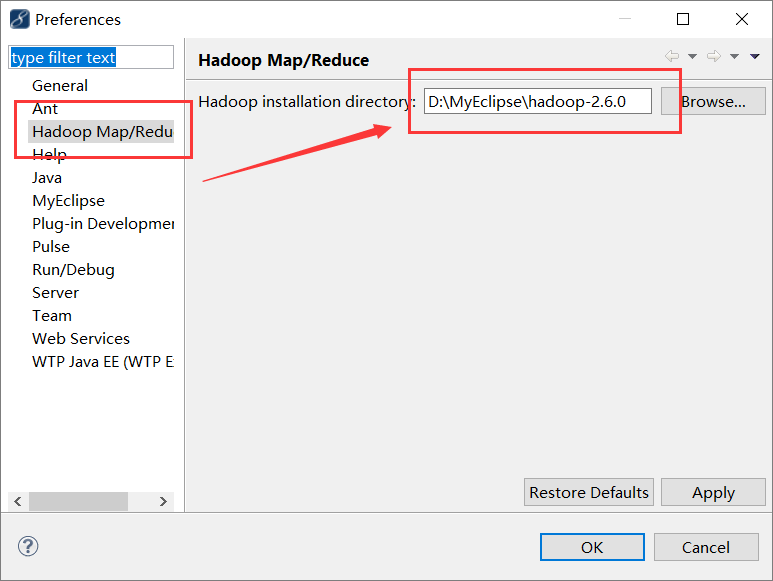
这里我们解压一个hadoop的安装包,箭头指向的位置引入所需依赖包
3、创建一个工程
4、window–>show view –>Map/Reduce Location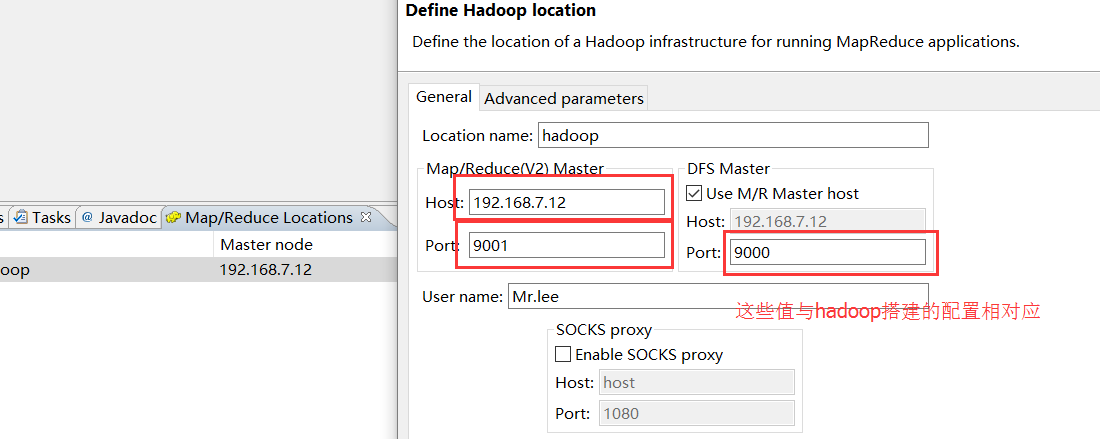
5、编写WordCount程序:
package com.hadoop.hdfs;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {/** * * @author Howie Lee * 继承Mapper<...>四个泛型分别对应输入的key value 和输出的key value * * BooleanWritable:标准布尔型数值 * ByteWritable:单字节数值 * DoubleWritable:双字节数 * FloatWritable:浮点数 * IntWritable:整型数 * LongWritable:长整型数 * Text:使用UTF8格式存储的文本 * NullWritable:当<key,value>中的key或value为空时使用 * * */public static class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{protected void map(LongWritable key, Text value, Context context)throws java.io.IOException ,InterruptedException {//分割每行数据String line = value.toString();String[] words = line.split(" ");for(String word : words){context.write(new Text(word), new LongWritable(1));}};}/** * * @author Howie Lee * 继承Reducer<...>四个泛型分别对应输入的key value 和输出的key value */public static class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{protected void reduce(Text key, Iterable<LongWritable> values, Context context)throws java.io.IOException ,InterruptedException {Long sum = 0L;for(LongWritable value : values ){//这里使用value.get();将LongWritable转换为int类型sum += value.get();}context.write(key, new LongWritable(sum));};}public static void main(String[] args) throws IOException, Exception {Configuration conf = new Configuration();//指定作业执行规范Job job = Job.getInstance(conf);//初始化一个job对象//传入的class 找到job的jar包(这里只是使用这个类去寻找他的包)job.setJarByClass(WordCount.class);job.setMapperClass(WCMapper.class);//指定map函数job.setReducerClass(WCReducer.class);//指定reducer函数job.setOutputKeyClass(Text.class);//输出key格式(如果一样的话,这句话就可以做到输出map和reducer的格式)//如果map/reducer输出不同就单独指定map的job.setMapOutputKeyClass(Text.class);//输出map的key格式job.setOutputValueClass(LongWritable.class);//输出value格式job.setMapOutputValueClass(LongWritable.class);//输出map的value格式FileInputFormat.addInputPath(job, new Path("/word/"));//处理文件路径FileOutputFormat.setOutputPath(job, new Path("/output/"));//结果输出路径job.waitForCompletion(true);}}
6、导出为一个jar包(File–>Export–> Jar file)
7、运行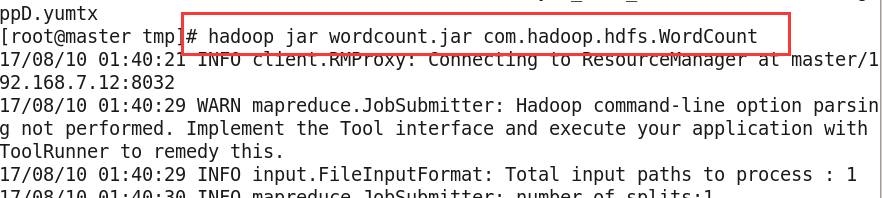
8、查看运行结果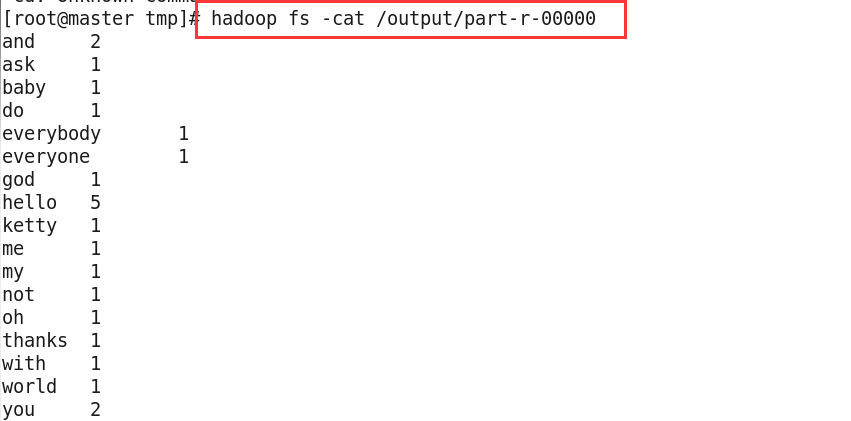


































还没有评论,来说两句吧...