hadoop 实现简单的wordcount实例
前置条件:
在hadoop官网下载某个版本的zip文件,这里下载的版本是2.7.3,将其解压刀你的电脑的某个目录中,这里为:D:\dev\hadoop-2.7.3
下载地址:http://apache.fayea.com/hadoop/common/hadoop-2.7.3/
src的是文件源码,有需要的可以下载下来研究~
配置环境变量:
HADOOP_HOME D:\dev\hadoop-2.7.3
1.使用idea新建一个maven项目
2.修改maven项目中pom文件,加入如下依赖
<dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>2.7.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.3</version></dependency>
3.在java文件新建一个包 com.hadoop.wordcount 名字可以自定义
在包内新建一个类 wordCount
内容如下:
package com.hadoop.wordcount;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;import java.util.StringTokenizer;/** * WordCount * * @author: wychen * @time: 2017/3/20 20:25 */public class WordCount {static class MyMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {//分割字符串StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {//排除字母少于5个的String tmp = itr.nextToken();if (tmp.length() < 5) {continue;}word.set(tmp);context.write(word, one);}}}static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();private Text keyEx = new Text();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {//将map的结果方法,乘以2sum += val.get() + 1;}result.set(sum);keyEx.set("输出:" + key.toString());context.write(keyEx, result);}}public static void main(String[] args) throws Exception {//配置信息Configuration conf = new Configuration();//job名称Job job = Job.getInstance(conf, "mywordcount");job.setJarByClass(WordCount.class);job.setMapperClass(MyMapper.class);job.setReducerClass(MyReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//输入 输出pathFileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));//结束System.exit(job.waitForCompletion(true) ? 0 : 1);}}
4.resources 文件中新建日志配置文件 log4j.properties
log4j.rootLogger=DEBUG, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%c{1} - %m%nlog4j.logger.java.sql.PreparedStatement=DEBUG
接下来就可以直接WordCount类中运行main函数了
首先配置运行前的参数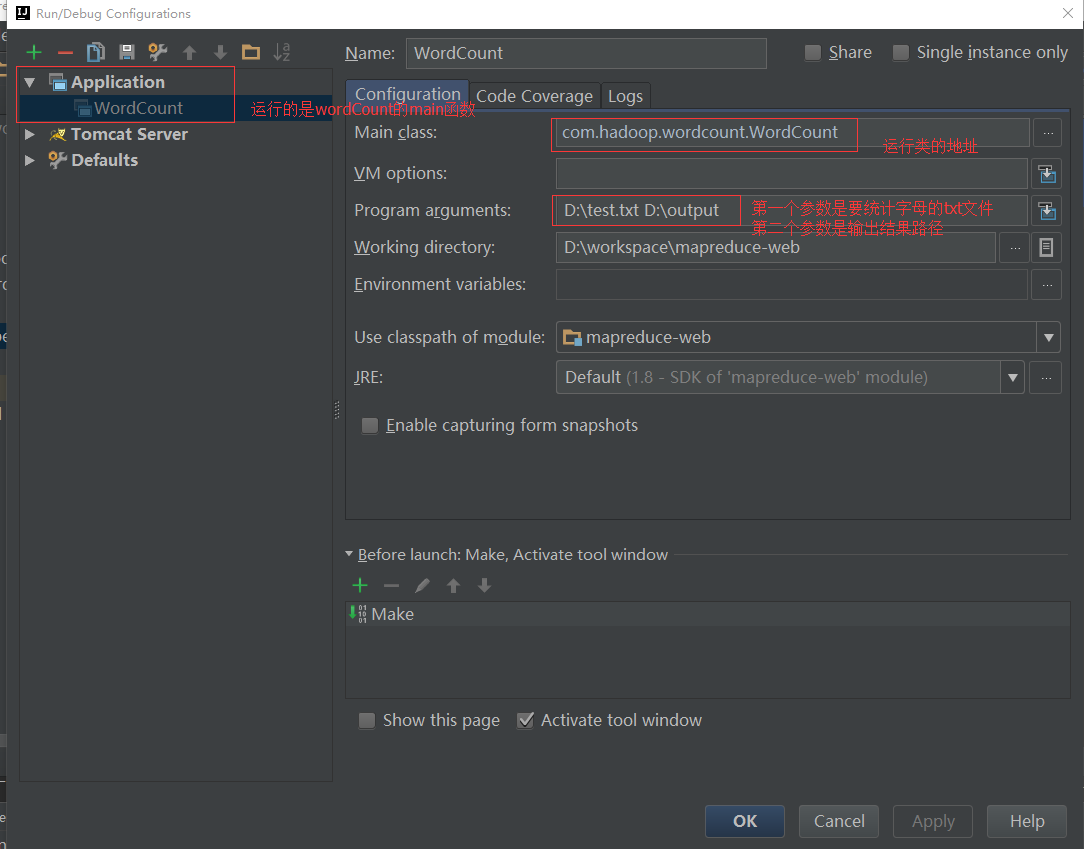
接下来直接在WordCount类中右击鼠标,点击运行即可,可在控制台查看运行过程中输出的结果,以及你填写的文件输出路径的文件中结果
笔者的输出结果如下图所示: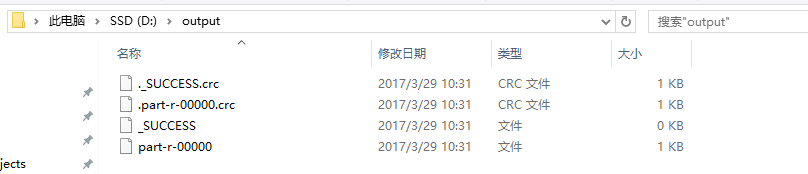
好了,一个简单的MapReduce下的单词统计实例就完成了~

























")

JSON解析和复杂数据模型转换技巧")
分类页_类别信息接口调试")
分类页_左侧类别导航制作")
Provide状态管理基础")



还没有评论,来说两句吧...