【人工智能-深度学习-图像识别】EfficientNet
【人工智能-深度学习-图像识别】EfficientNet入门
- 提特征,backbone
- 计算量
- B0的基础网络架构,调参调出来的:
- 深度可分离卷积
- 代码结构
- SE模块:注意力机制
- 目标检测
- Zylo117完成的pytorch版本
- 配置文件
- 指定版本
- root_dir
- 读入图像
- 读入标注
- 定义前向传播
- 解释网络
提特征,backbone
14年VGG、15年ResNet…EfficientNet提取特征比较好,EfficientNet是当下比较好的backbone。
分类、检测、分割都可以处理的比较好。
网络结构是堆叠的,网络层数可以变多,结构可以变更复杂,如
d:深度 w:每一层得到特征值的个数 r:输入的分辨率的大小
对比了同重量级别的效果,把前几年的效果都优秀,b0-b7是一样的,只不过特征图,层数等发生了变化,有些指定参数是大量实验总结的,可能不具有可解释性: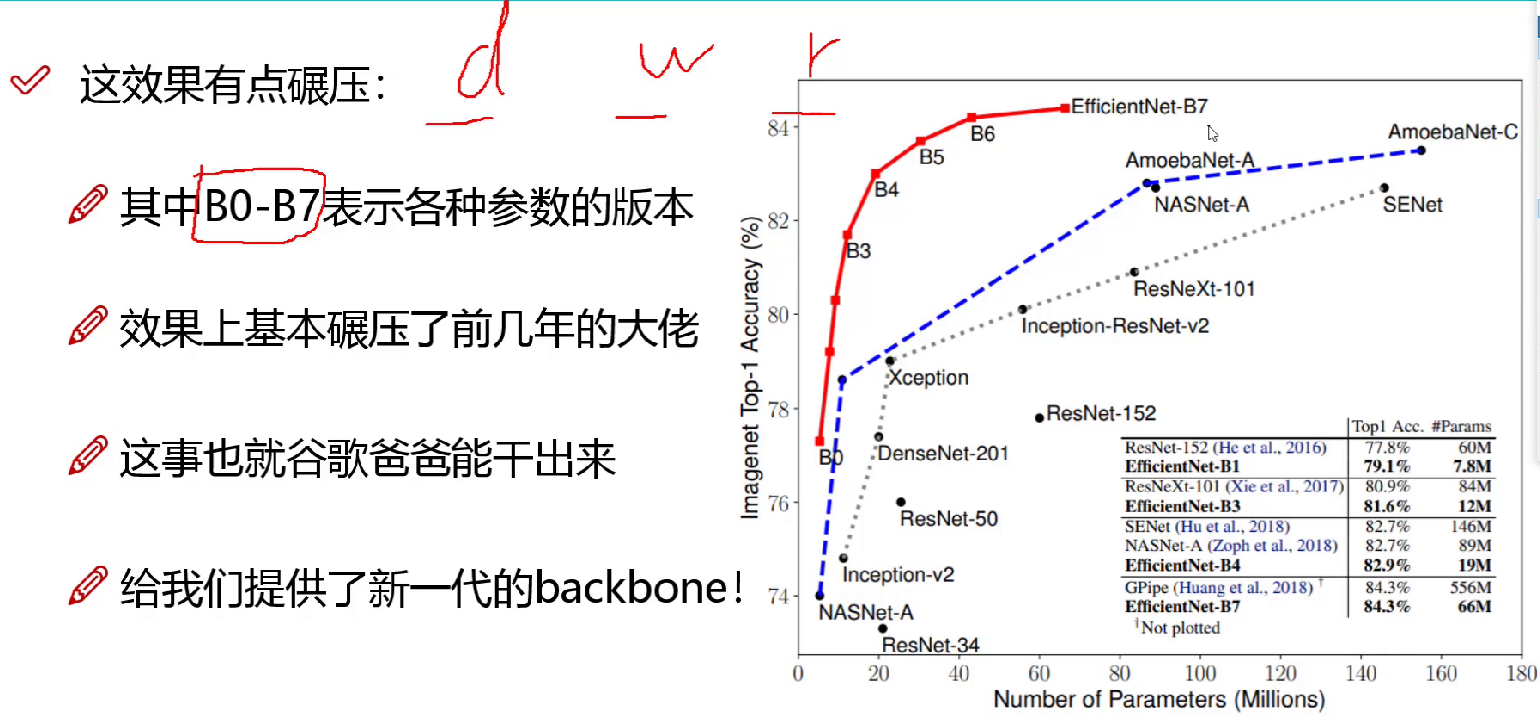

无人驾驶需要强化学习,没有指定的目标,不违规就行。
深度学习中调参数,参数设置用强化学习去设置(一个设想),利用强化学习去调优。
**不建议在EfficientNet上面修改,**很多人尝试改,但没有一个成功的。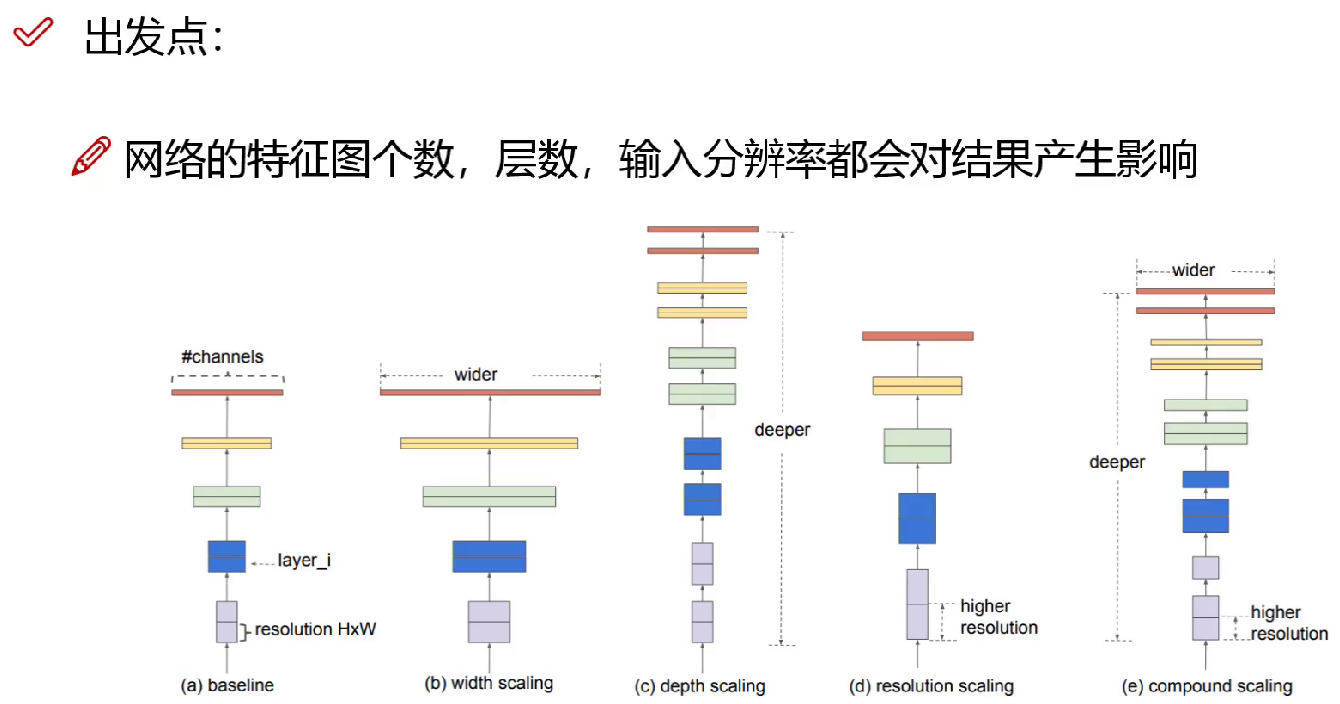
计算量
单一考虑计算量,计算量与精度关系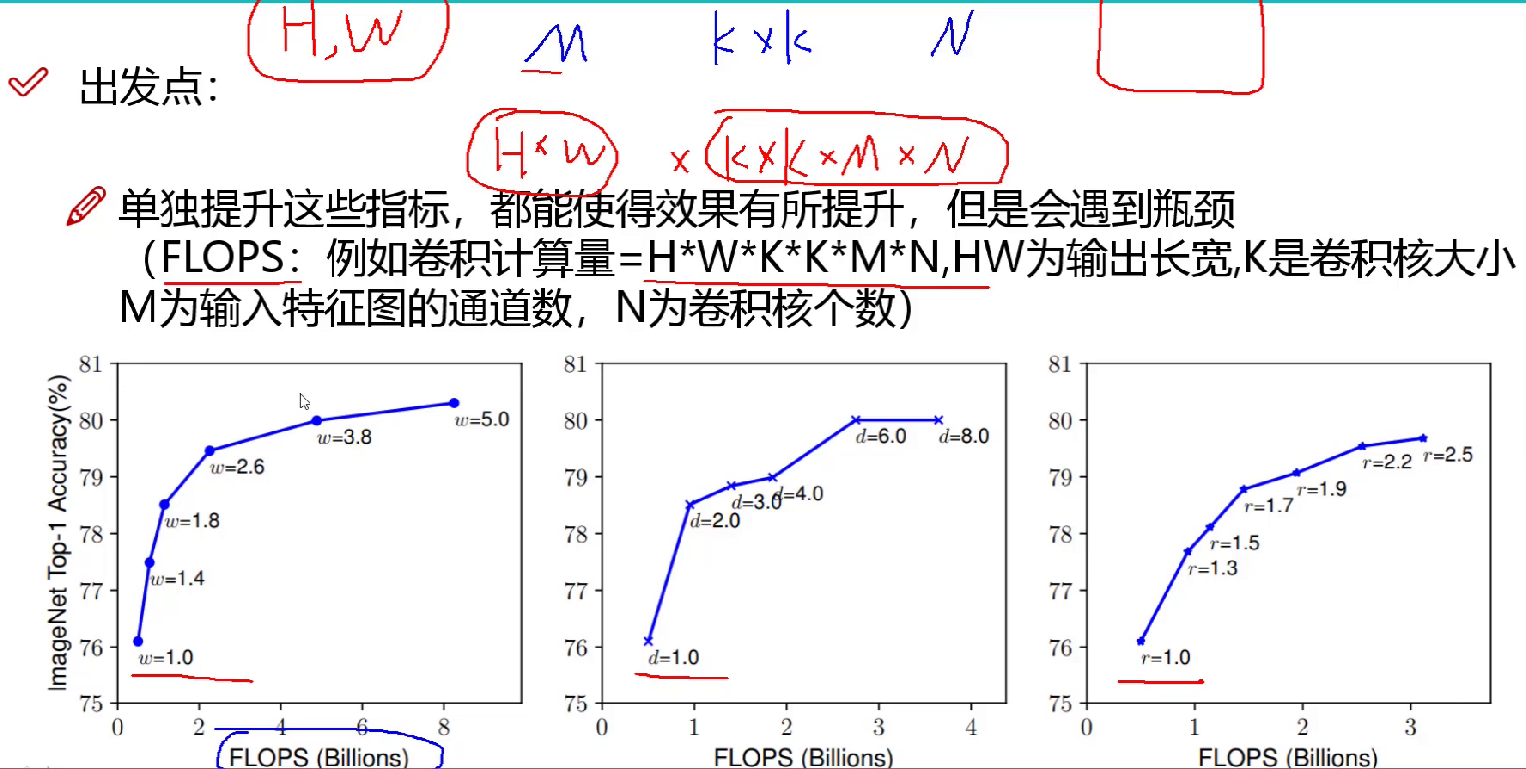
综合考虑参数指标,(谷歌做的)自己是做不了的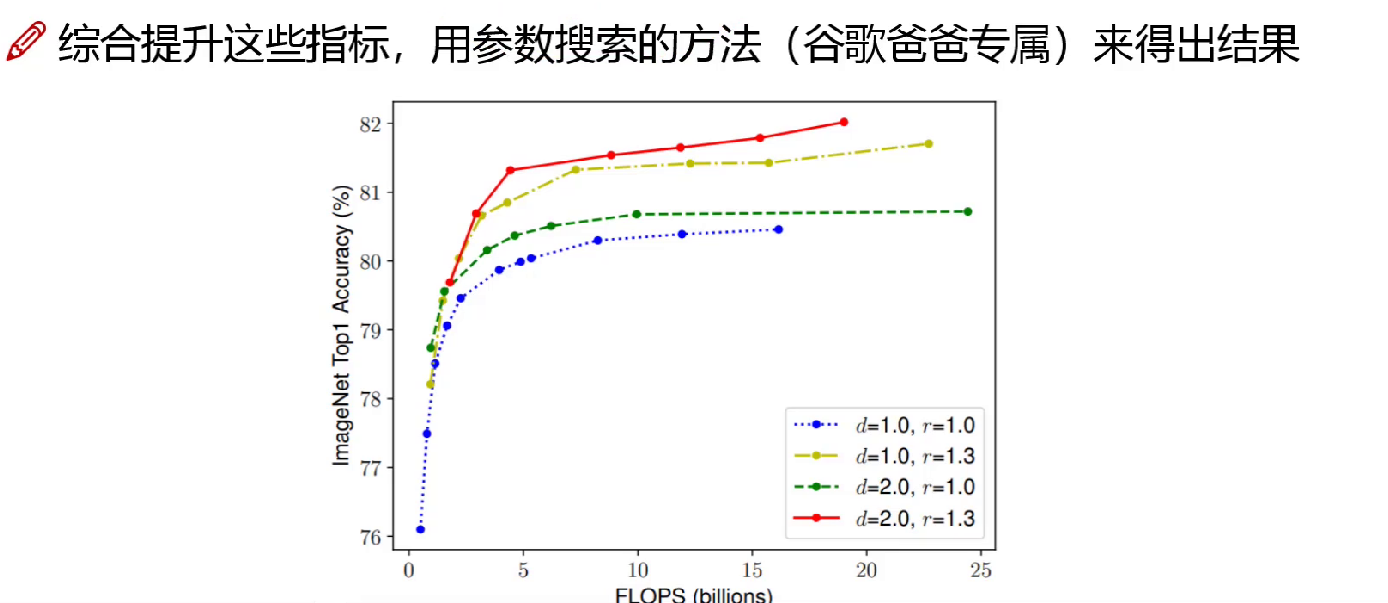
B0的基础网络架构,调参调出来的:
channel是得到的特征图大小(调参调出来的)
layers:当前这一层重复的个数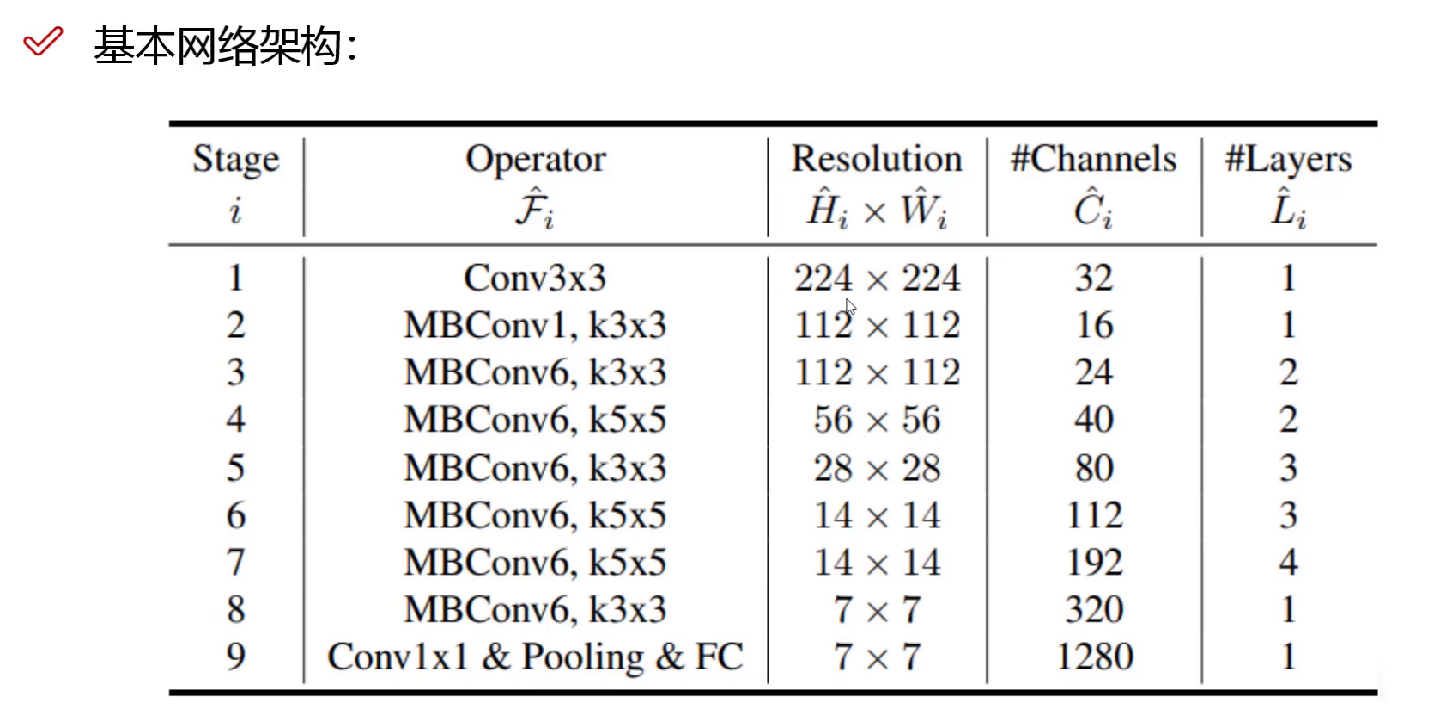
红框为Kernel大小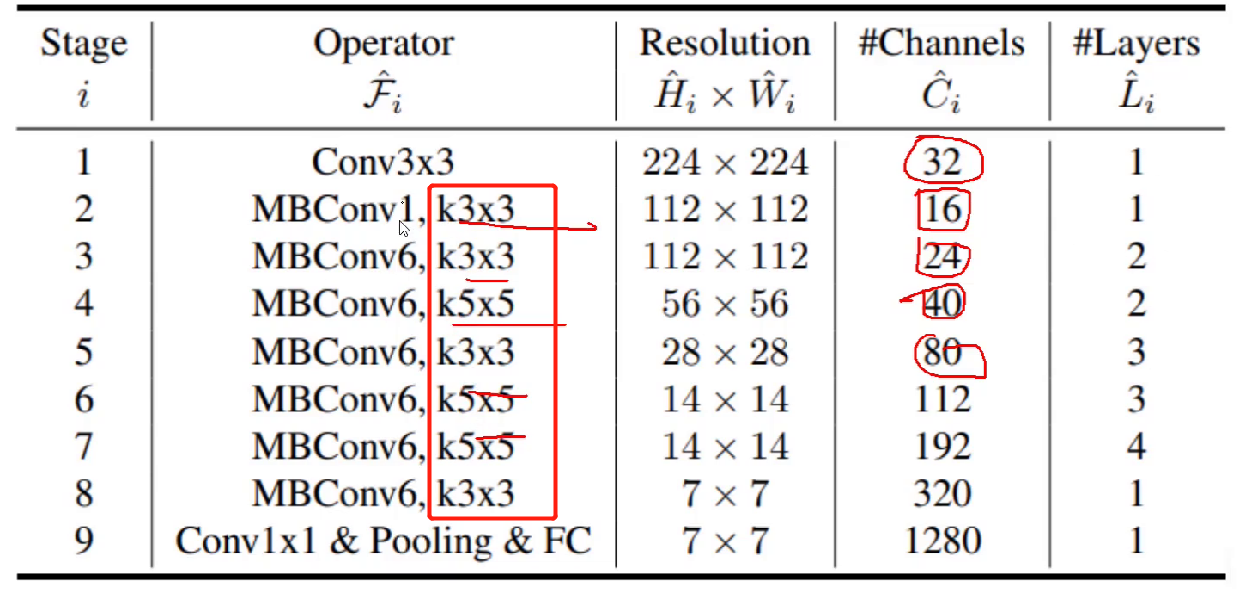
构建权重层时要不要翻倍
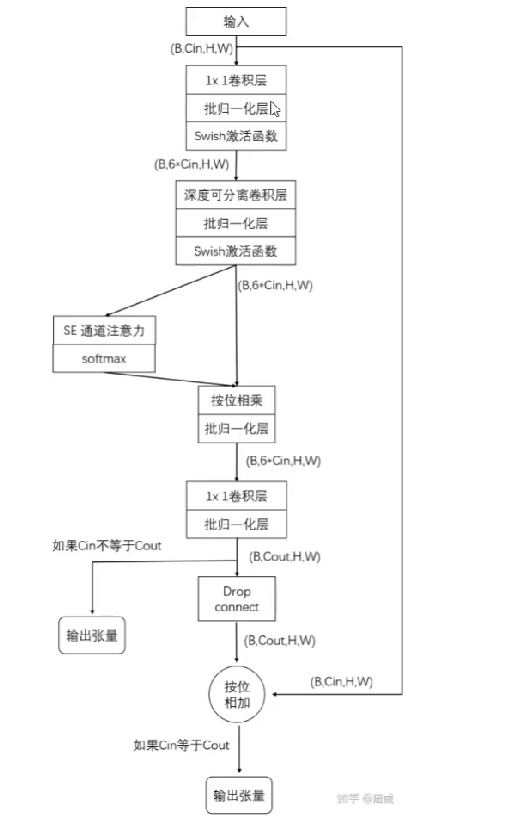
深度可分离卷积
Depthwise:filter计算少一些,特征也少了;参数量省下来了待会再补偿
当从1个filter对n个map变到1个filter对应1个map,卷积失去了能扩充filter的作用;可以再加一个11的卷积。即第一步,一对一的接待,输入多少channel输出多少,再进行11的卷积,生成多个filter,加入groups。
代码结构
SE模块:注意力机制
就是一个权重,比如有的纹理信息重要,有的是轮廓信息重要,重要性需要自己做吗,不需要,我们不需要人为的去干扰这个事,所有的该神经网络都是end to end结构,所有都不需要自己参与。
网络计算这种哪些图重要哪些不重要,最后将这些权重参数加权到网络中。
width:每层特征值个数 depth:需要堆叠多少模块 res:分辨率的大小 dropout:要不要连上dropout这个东西。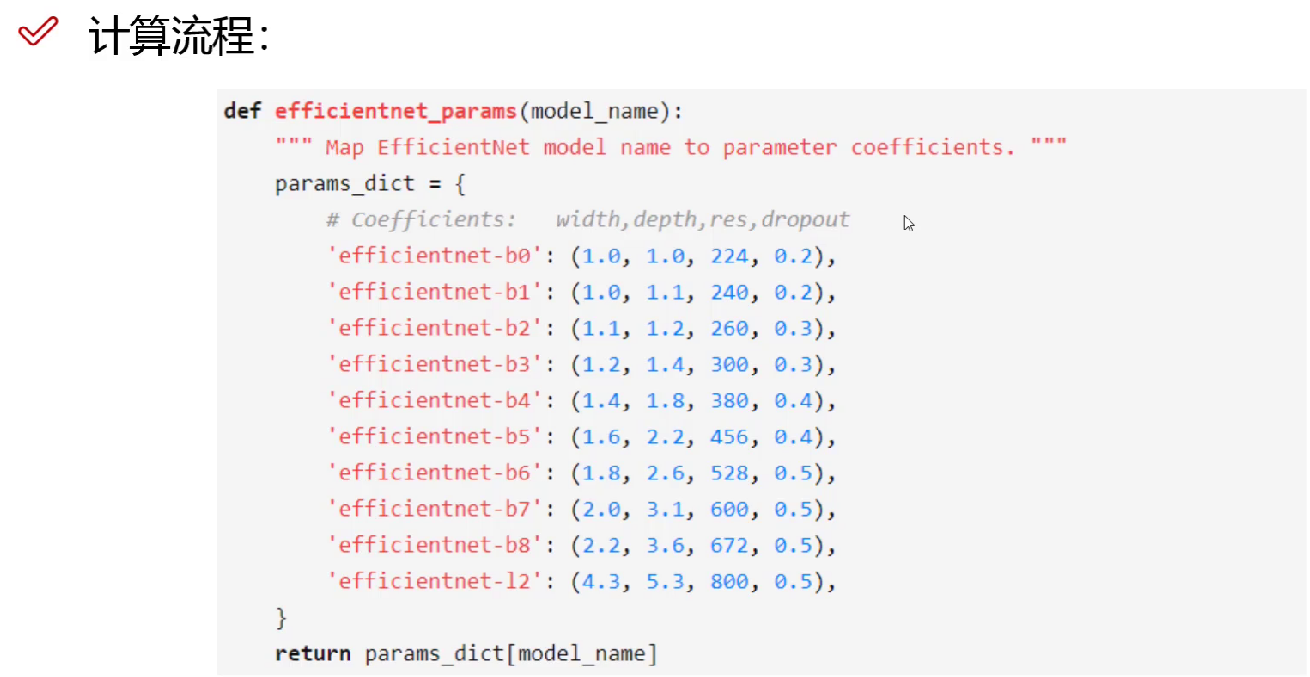
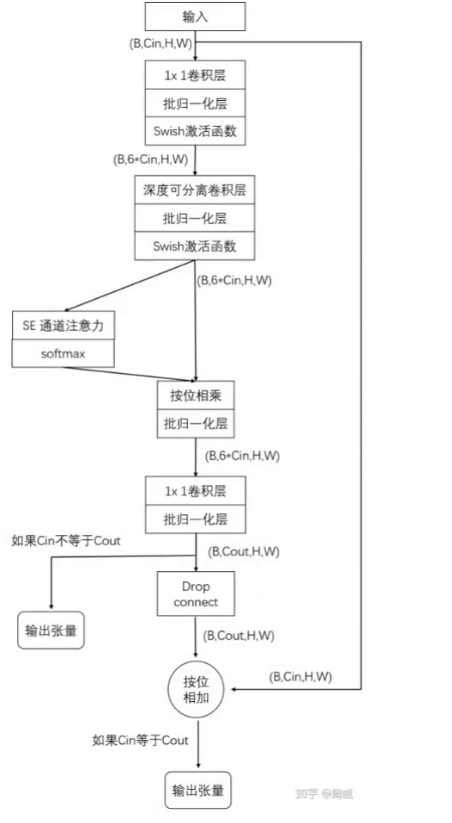
目标检测
EfficientNet作为目标提取的主干网络,再把主干网络应用到其他应用当中
EfficientDet主干网络用的是EfficientNet
打标签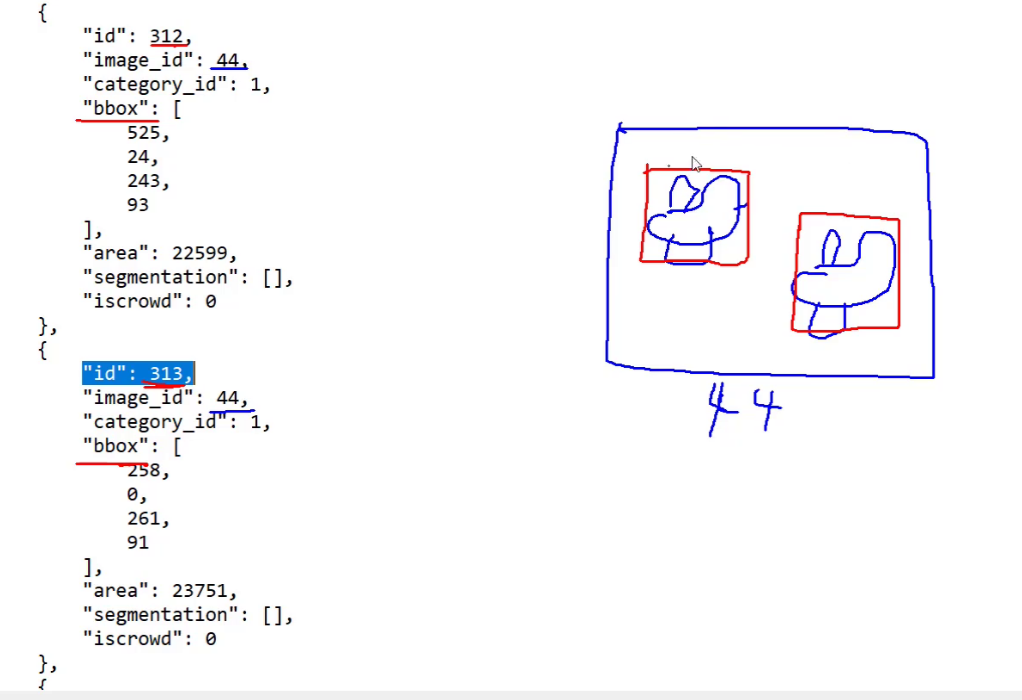
Zylo117完成的pytorch版本

配置文件
换数据集要改的
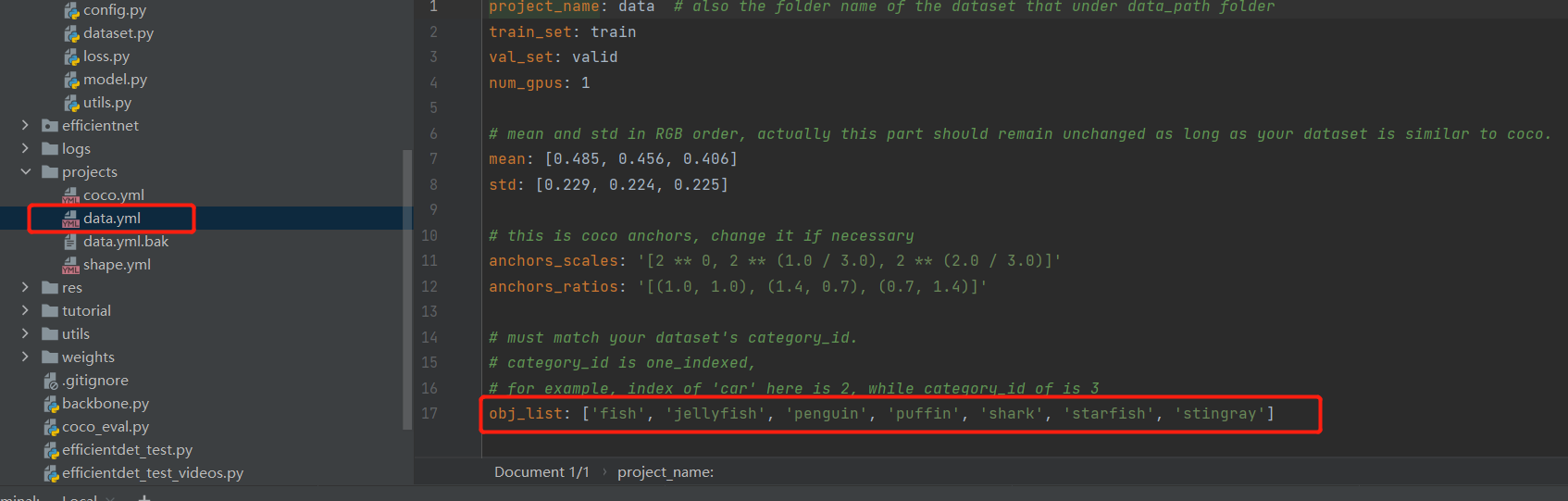
指定版本
-p指定位置
-c是指定版本,先把0跑起来
有条件大,没条件小
读入配置文件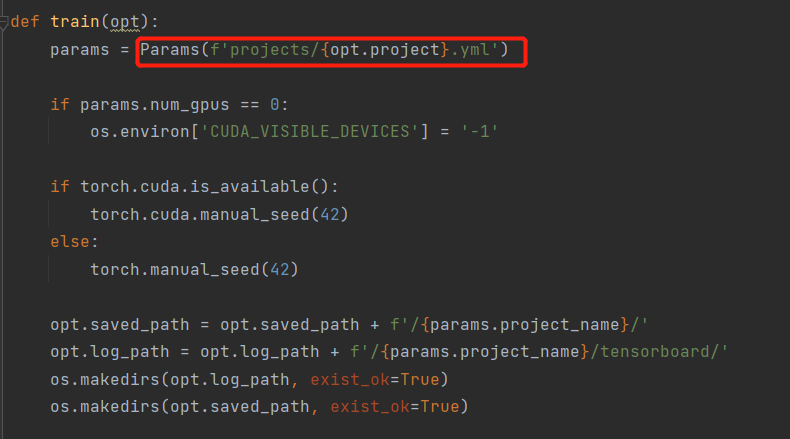
root_dir
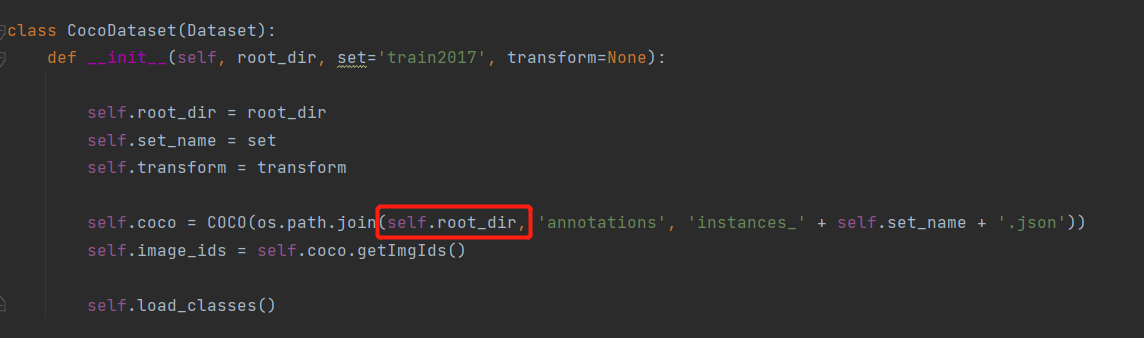
取标签的
取数据的
读入图像
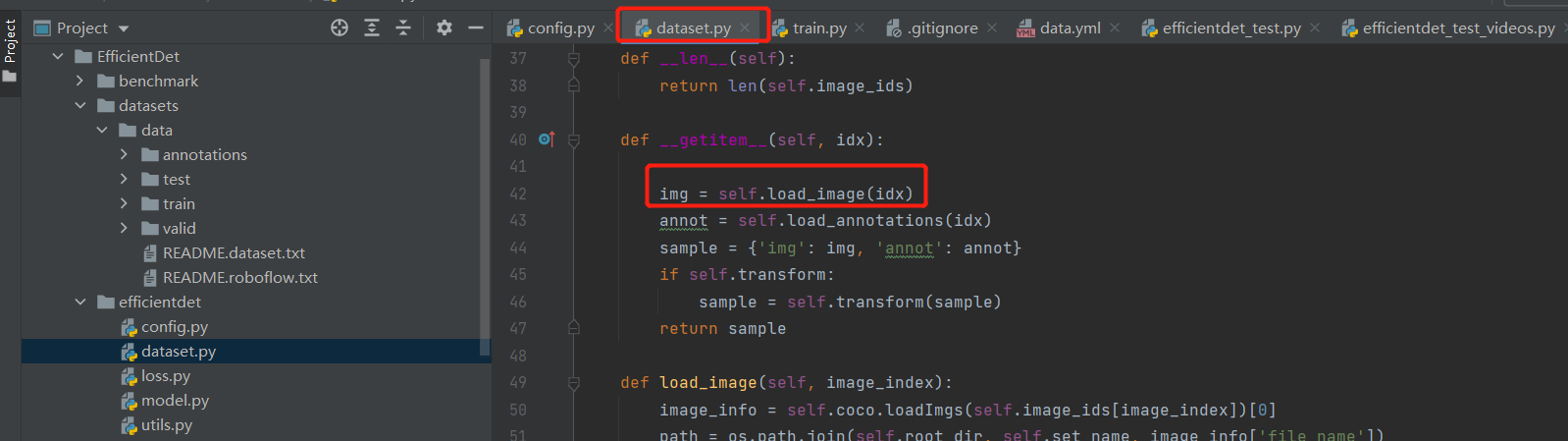
路径,opencv读进来是BGR的,我们需要一个RGB的,转换格式,再进行一个归一化操作

读入标注
拿到对应图像,一个图像可能对应多个标注,一张图像中可能有多个框,每个框对应一个id值。
先初始化成一个list,遍历去取,同时过滤异常现象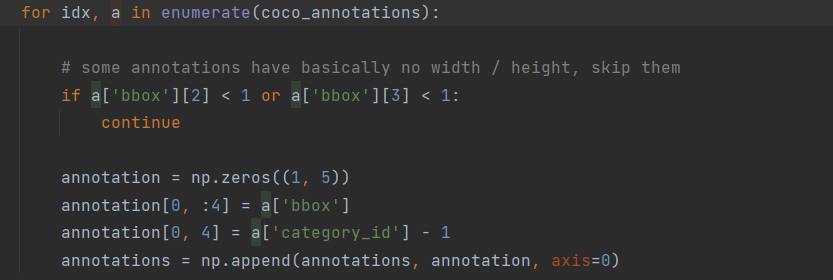
得到一个图像
加载图像,循环多次,构成一个batch
构建完成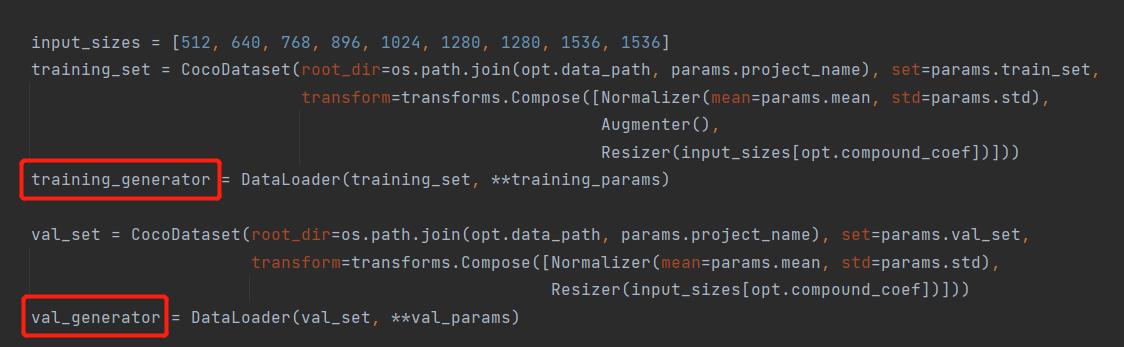
定义前向传播
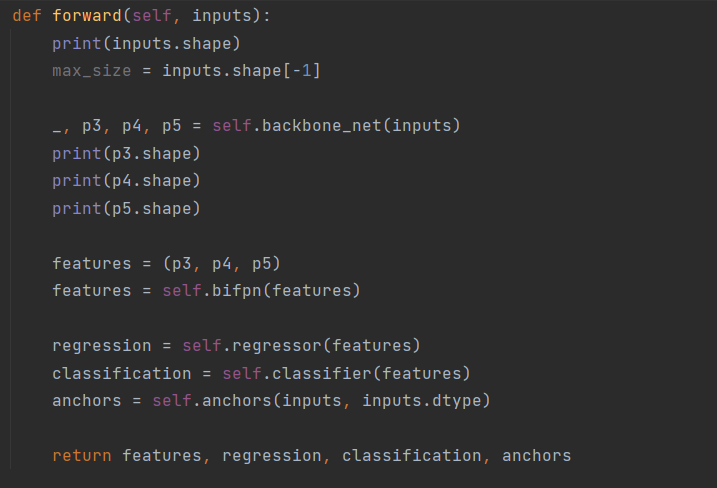
解释网络





























还没有评论,来说两句吧...