线性表的链式表示-单链表、循环链表
一 单链表
与顺序表相同,链表也是一种线性表,它的数据的逻辑组织是一维的。而与顺序表不同的是,链表的物理存储结构是用一组地址任意的存储单元存储数据的。也就是说,它不像顺序表那样占据一段连续的内存空间,而是将存储单元分散在内存的任意地址上。在链表结构中,每一个数据元素都存放在链表的一个结点(Node)中,而每个结点之间是由指针将其连接在一起,这样就形成了一条如同“链子”的结构。
1.1 单链表结点(node)
结点 = 数据域 + 指针域
- 数据域用来存放数据元素本身的信息,指针域用来存放后继结点的地址。
- 链表在逻辑上是连续的,而物理上并不一定是连续的存储结点。
- 只要获得链表的头结点,就可以通过指针遍历整条链表。
1.2 单链表的数据结构定义
typedef int ElemType;//单链表结点类型的描述typedef struct LNode{ElemType data; //数据域struct LNode *next; //指针域} LNode,*LinkList;
<说明> ElemType 可以是C语言的基本数据类型,也可以是结构体类型,当然也可以是其他的构造类型。
1.3 创建一个单链表
可以使用 尾插法(含头结点)创建一个单链表。实现代码如下:
//尾插法(含头结点)创建单链表LinkList createLinkList(int n){int i;LinkList L,tail,p;ElemType e;//动态内存分配L=(LNode*)malloc(sizeof(LNode)); //创建头结点,数据域不使用memset(L, 0, sizeof(LNode));tail=L->next; //tail指针始终指向链表的尾结点for(i=0; i<n; i++){scanf("%d", &e);p=(LNode*)malloc(sizeof(LNode)); //创建数据结点memset(p, 0, sizeof(LNode));p->data=e;tail->next=p;tail=p;}tail->next=NULL; //尾结点的指针域的值为NULLreturn L;}
<说明> 当然也可以使用 头插法 创建一个链表,即将新结点插入到头结点的后面,然后新结点的指针域指向原来的链表。可以自己尝试实现一下。
1.4 向单链表中插入一个结点
在指针q指向的结点后面插入一个新结点,该过程的步骤如下:
(1)首先创建一个新结点,并用指针p指向该新结点。
(2)将q指向的结点的next的值(即q的后继结点的指针)赋值给p指向的结点的next域。
(3)将p的值赋值给q的next域。
通过以上3步,就可以实现在链表中由q指向的结点后面插入p所指向的新结点。如下图所示:
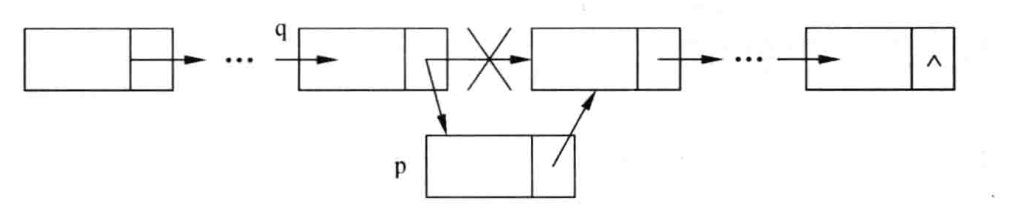 向链表插入结点过程
向链表插入结点过程
具体实现代码如下:
void insertListNode(LinkList L, LinkList q, ElemType e){//向链表中由指针q指向的结点后面插入新结点,结点数据为eLinkList p;p=(LNode*)malloc(sizeof(LNode));p->data = e;if(!L->next) //如果链表的内容为空,表示该链表为空{L->next = p;p->next = NULL; //在头结点后面插入第1个元素}else //如果链表不为空时{p->next = q->next;q->next = p;}}
1.5 从单链表中删除一个结点
从链表中删除一个结点,必须考虑以下3种情况。
- 待删除结点是链表的第1个数据结点。
- 待删除结点的前驱结点的指针已知。
- 待删除结点的前驱结点的指针未知。
对于前面两种情况,可以使用下面这段代码来描述:
void delListNode(LinkList L, LinkList q, LinkList p){//q指针指向待删除结点的前继结点,指针p指向待删除结点if(p == L->next)L->next = p->next;elseq->next = p->next;free(p);}
对于第3种情况,当p所指向的结点的前驱结点的指针未知时,需要先遍历链表,找到p的前驱结点的指针,并将该指针赋值给一个指针变量q,再按照第2种情况的方式去做。具体的代码描述如下:
void delListNode(LinkList L, LinkList p){LinkList q; //指针q指向待删除结点的前驱结点q = L->next; //指针q初始指向链表的第1个数据结点if(q == p) //删除的是第1个数据结点{L->next = p->next;free(p);}else{for(; q->next!=p; q=q->next); //遍历链表,找到p的前驱结点,并使q指向它if(q->next != NULL){q->next = p->next; //从链表中删除p指向的结点free(p); //释放掉p指向的结点空间}}}
1.6 销毁一个单链表
在链表使用完毕后建议销毁它,因为链表本身会占用内存空间。如果一个系统中使用很多的链表,而使用完毕后又不及时地销毁它,那么这些垃圾空间积累过多,最终会导致内存泄漏甚至程序的崩溃。因此应当养成及时销毁不使用的链表的良好编程习惯。销毁一个链表的代码描述如下:
void destroyLinkList(LinkList L){LinkList p,q;p = L->next;while(p){ //删除所有数据结点q = p->next;free(p);p=q;}free(L); //删除头结点}
1.7 输出单链表中所有元素
通过遍历链表,就可以逐个输出链表中数据结点的数据域的值。具体代码描述如下:
//打印输出函数void printLinkList(LinkList L){LinkList p;p=L->next; //p初始指向第一个数据结点while(p){printf("%d ",p->data);p=p->next;}}
测试用例
int main(){int e,i;LinkList L, q;q=L=createLinkList(1);q=L->next; //指针q指向链表的第1个数据结点scanf("%d", &e);while(e){insertListNode(L,q,e);q=q->next;scanf("%d", &e);}printf("The content of the linklist:\n");printLinkList(L);q=L->next;printf("\nDelete the 5th element\n");for(i=0;i<4;i++){if(q == NULL){printf("The length of the linklist is smaller than 5!\n");//getche();return -1;}q = q->next;}delListNode(L, q);printLinkList(L);destroyLinkList(L); //销毁该链表//getche();return 0;}
编译命令:gcc demo.c -std=c99
示例运行结果:
a.exe
1 2 3 4 5 6 7 8 9 10 0
The content of the linklist:
1 2 3 4 5 6 7 8 9 10
Delete the 5th element
1 2 3 4 6 7 8 9 10
1.8 逆置单链表
逆置链表就是将链表的数据结点按逆序的方式重新组装成一条链表。具体代码描述如下:
//逆置一个带头结点的单链表Lvoid reverseLinkList(LinkList L){LinkList p,q; //p用来遍历链表if(L->next && L->next->next){p=q=L->next; //p,q初始指向第一个结点p=p->next; //p指向第二个结点q->next=NULL;while(p){q=p; //q指向待插入的结点p=p->next; //p指向原链表的下一个结点//插入结点q->next=L->next;L->next=q; //两条语句的顺序不能颠倒}}}
测试用例
int main(){int e,i;LinkList L, q;q=L=createLinkList(1);q=L->next; //指针q指向链表的第1个数据结点scanf("%d", &e);while(e){insetListNode(L,q,e);q=q->next;scanf("%d", &e);}printf("The content of the linklist:\n");printLinkList(L);reverseLinkList(L);printf("\nAfter reverse linklist:\n");printLinkList(L);destroyLinkList(L); //销毁该链表//getche();return 0;}
示例运行结果:
a.exe
1 2 3 4 5 6 7 8 9 10 0
The content of the linklist:
1 2 3 4 5 6 7 8 9 10
After reverse linklist:
10 9 8 7 6 5 4 3 2 1
1.9 归并两个有序的单链表
【问题描述】已知单链表 La 和单链表 Lb 的元素按值非递减排列,现要归并 La 和 Lb 得到单链表 Lc。(单链表带头结点)
【问题分析】因为单链表的结点之间的关系是通过指针指向建立起来的,所以用链表进行合并并不需要另外开辟存储空间,可以直接利用原来的两个单链表的存储空间,合并过程中只需要把 La 和 Lb 两个单链表中的结点重新进行链接即可。
【算法步骤】
(1) 设立3个指针 pa、pb 和 pc,其中 pa 和 pb 初始分别指向 La 和 Lb 的第一个数据结点。
(2) 链表Lc 取 La 的头结点作为自己的头结点。
(3) 指针 pc 初始指向 Lc 的头结点。
(4) 当指针 pa 和 pb 均未到达相应的表尾时,则依次比较 pa 和 pb 所指向的元素值,从 La 或 Lb 中“摘取”元素较小的结点插入到 Lc 链表的尾部。
(5) 将非空链表的剩余结点段插入到 pc 所指向的结点之后。
(6) 释放掉 Lb 的头结点存储空间。
【算法描述】C语言实现
//归并两个有序单链表void MergeList_L(LinkList La,LinkList Lb,LinkList Lc){ListList pa,pb,pc;pa=La->next; //pa初始指向La的第一个数据结点pb=Lb->next; //pb初始指向La的第一个数据结点Lc=La; //Lc初始取La的头结点为自己的头结点pc=Lc; //pc初始指向Lc的头结点while(pa && pb){if(pa->data <= pb->data){pc->next=pa; //将pa所指结点链接到pc所指结点之后pc=pa; //pc 指向 pa,亦即pc指向链表Lc的尾结点pa=pa->next; //pa 指向下一个结点}else{pc->next=pb; //将pb所指结点链接到pc所指结点之后pc=pb; //pc 指向 pb,亦即pc指向链表Lc的尾结点pb=pb->next; //pb 指向下一个结点}}pc->next = pa ? pa:pb; //将非空链表的剩余结点段插入到pc所指结点之后free(Lb); //释放Lb的头结点存储空间}
二 循环链表
循环链表(Circular linked list) 是另一种形式的链式存储结构。
它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。由此,从表中任一结点出发均可找到表中其他节点,如下图所示为单链的循环链表。类似地,还可以有多重链的循环链表。
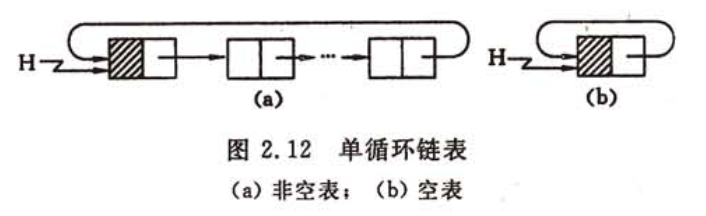
循环链表的操作和线性链表基本一样,差别仅在于:当链表遍历时,判别当前指针 p 是否指向表尾结点的终止条件不同。在单链表中,判别条件为:p != NULL 或 p->next != NULL;而循环单链表的判别条件为:p != L 或 p->next != L。
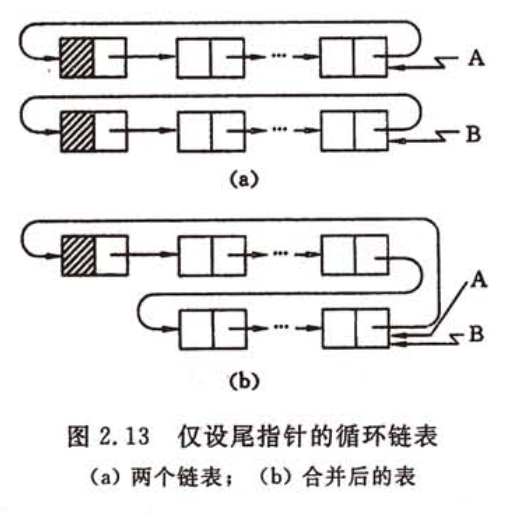
在某些情况下,若在循环链表中设立尾指针而不设头指针(如下图 2.13(a) 所示),可使某些操作简化。例如,将两个线性表合并成一个表时,仅需将第一个表的尾指针指向第二个表的第一个数据结点,第二个表的尾指针指向第一个表的头结点,然后释放第二个表的头结点存储空间。
当线性表以 图 2.13(b) 的循环链表作为存储结构时,这个操作仅需改变两个指针值即可,主要语句段如下:
//指针A,B分别指向循环链表A,B的尾结点p = B->next->next; //指针p指向链表B的第一个数据结点B->next = A->next; //循环链表B的尾结点指针域指向A的头结点A->next = p; //循环链表A的尾结点指针域指向链表B的第一个数据结点
上述操作的时间复杂度为 O(1),合并后的表如图 2.13(b) 所示。
2.0 循环链表的数据结构定义
【代码描述】C语言实现
//相关的头文件#include <stdio.h>#include <string.h>#include <stdlib.h>#include <time.h> //srand((unsigned)time(NULL));//函数结果状态代码#define TRUE 1#define FALSE 0#define OK 1#define ERROR 0#define INFEASIBLE -1#define OVERFLOW -2//Status是函数的类型,其值是函数结果状态代码typedef int Status;//双向链表元素类型定义typedef int ElemType;//循环链表结点的数据结构定义typedef struct LNode {ElemType data; // 数据域struct LNode *next; // 指针域}LNode, *CircleList;
2.1 构造一个空的循环链表(带头结点)
【算法描述】C语言实现
//构造一个空的循环链表(带头结点)Status InitList_CL(CircleList *L){*L = (LNode*)malloc(sizeof(LNode));if(!L) { //存储空间分配失败printf("malloc failed.\n");exit(OVERFLOW); //exit(-2)程序异常退出}memset(*L, 0, sizeof(LNode)); //存储空间初始置零(*L)->next = *L; //先建立一个带头结点的单链表,并使头结点指向链表自身(即头指针L)return OK;}
<Tips> 函数参数 L 是一个二级指针,之所以要使用一个二级指针作为函数形参,是为了将 malloc 动态分配的内存空间的首地址通过这个二级指针传递给调用该函数的实参一级指针。*L 运算就是实参一级指针的值,当然这个值是一个地址。
2.2 置空一个循环链表
【算法描述】C语言实现
//置空一个循环链表//所谓“置空”循环链表,即释放循环链表中所有非头结点的存储空间Status ClearList_CL(CircleList L){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}if(L->next == L){printf("CircleList has been empty.\n");return OK;}CircleList p, q; //指针p为循环链表的工作指针,q为临时指针p = p->next; //p初始指向第1个数据结点while(p != L) //p指向头结点时,while循环结束{q = p->next; //将p当前指向的结点的后继节点的位置指针暂存于指针q中free(p); //释放p当前指向的结点的存储空间p = q; //p访问下一个结点}L->next = L; //头结点指针域指向自身结点return OK;}
2.2 销毁一个循环链表
【算法描述】C语言实现
//销毁一个循环链表Status DestroyList_CL(CircleList L){if(!L){printf("CircleList uninitialized.\n");return ERROR;}ClearList_CL(L); //置空循环链表free(L); //释放头结点return OK;}
2.3 判定一个循环链表是否为空
【算法描述】C语言实现
//判定一个循环链表是否为空//若循环链表为空,则返回TRUE,否则返回FALSEStatus ListIsEmpty_CL(CircleList L){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}else if(L->next == L){printf("CircleList is empty.\n");return TRUE;}else{printf("CircleList is not empty.\n");return FALSE;}}
2.4 计算一个循环链表的长度
【算法描述】C语言实现
//计算一个循环链表中数据结点的个数int ListLength_CL(CircleList L){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}int count = 0;CircleList p = L->next; //p为循环链表的工作指针,初始指向链表的第一个数据结点while(p != L) {count++;p = p->next;}return count;}
2.5 获取循环链表中第 i 个位置的结点元素值
【算法描述】C语言实现
//获取循环链表中第i个位置的结点元素值//用参数e接收循环链表L中第i个结点元素的值Status GetElem_CL(CircleList L, int i, ElemType *e){if(!ListIsEmpty_CL(L) || i<=0)return ERROR;CircleList p = L; //p为循环链表的工作指针,初始指向链表的头结点int j = 0; //j为计数器//查找第i个结点的位置,且该结点不能为表头结点while(p->next!=L && j<i){p = p->next; //p指向下一个结点j++; //计时器j相应加1}//如果遍历到头了,说明没有找到合乎目标的结点if(p==L || j>i)return ERROR;*e = p->data;return OK;}
【算法分析】
该算法的基本操作是比较 j 和 i,并后移指针 p,while 循环体中的语句频度与位置 i 有关。若 ,则频度为 i-1,一定能取值成功;若
,则频度为 n,取值失败。因此该算法的最坏时间复杂度为
,其平均时间复杂度也为
。
2.6 循环链表的按值查找
【算法描述】C语言实现
/** 循环链表的按值查找* 在带头结点循环链表L中查找值为e的结点元素* 若查找成功,则返回结点位置指针,否则返回NULL*/LNode* LocateElem_CL(CircleList L, ElemType e){if(!ListIsEmpty_CL(L)) //循环链表为空,返回NULLreturn NULL;CircleList p = L->next; //p为循环链表的工作指针,初始指向首元结点while(p!=L && p->data!=e)p = p->next;if(p != L) //查找成功则返回结点地址p;查找失败则返回NULLreturn p;elsereturn NULL;}
【算法分析】
该算法的执行时间与待查的值 e 相关,其平均时间复杂度类似于算法 2.5,也为 。
2.7 循环链表的插入操作
【算法描述】C语言实现
/** 循环链表的插入* 在带头结点循环链表L中的第i个位置插入值为e的新结点*/Status ListInsert_CL(CircleList L, int i, ElemType e){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}CircleList p;int j;p = L; //p为循环链表的工作指针,初始指向链表的头结点j = 0; //j为计数器//先查找第i-1个位置的结点,并使p指向该结点while(p->next!=L && j<i-1){p = p->next;j++;}if(p==L || j>i-1)return ERROR;CircleList s = (CircleList)malloc(sizeof(LNode));//将新结点s插入循环链表L中s->data = e;s->next = p->next; //新结点的指针域指向原链表的第i个结点p->next = s; //p此时是指向第i-1个结点的,将该结点指针域指向新结点sreturn OK;}
【算法分析】
该算法的平均时间复杂度也为 。这是因为,为了在第 i 个结点之前插入一个新结点,必须首先找到第 i-1 个结点的位置,其时间复杂度与算法 2.6相同,为
。
2.8 循环链表的删除操作
【算法描述】C语言实现
/** 循环链表的删除操作* 在带头结点循环链表L中,删除第i个结点元素*/Status ListDelete_CL(CircleList L, int i){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}CircleList p, q;int j;p = L; //p为循环链表的工作指针,初始指向链表的头结点j = 0; //j为计数器while(p->next!=L && j<i-1) //查找第i-1个结点的位置,并使p指向该结点{p = p->next;j++;}if(p->next==L || i<1 || j>i-1)return ERROR;q = p->next; //q临时保存被删结点的位置地址p->next = q->next; //改变被删结点的前驱结点的指针域free(q); //释放被删结点的空间return OK;}
【算法分析】
删除操作类似于插入操作,删除操作的算法时间复杂度亦为 。
2.9 遍历循环链表
【算法描述】C语言实现
/* 遍历循环链表* 遍历带头结点的循环链表L,并输出所有数据结点的值*/Status ListTraverse_CL(CircleList L){if(!L){printf("CircleList uninitialized.\n");return INFEASIBLE;}if(L->next == L){printf("CircleList is empty.\n");return ERROR;}CircleList p = L->next; //p为循环链表的工作指针,初始指向链表的第1个数据结点while(p != L){printf("%d->", p->data);p = p->next;}return OK;}
【算法分析】
对于一个有 n 个结点元素的循环链表,该算法的时间复杂度为 。
2.10 创建循环链表(带头结点)
方式1 - 头插法创建循环链表
【算法描述】C语言实现
/** 头插法创建循环链表* 逆位序输入(随机产生)n个元素的值,建立带头结点的循环链表L*/void CreateList_CL_Head(CircleList *L, int n){srand((size_t)time(NULL)); //初始化随机种子//先建立一个带头结点的空循环链表*L = (CircleList)malloc(sizeof(LNode));if(!(*L))exit(OVERFLOW);(*L)->next = *L; //初始头结点指针域指向自身for(int i=0; i<n; i++){CircleList s = (CircleList)malloc(sizeof(LNode)); //生产新结点s//scanf("%d", &s->data); //手动输入元素值s->data = rand()%100; //随机生成100以内的数字,将生成的元素值赋给新生成结点的数据域//将新结点插入到表头结点之后s->next = *L->next;*L->next = s;}}
方式2 - 尾插法创建循环链表
【算法描述】C语言实现
/** 尾插法创建循环链表* 正位序输入(随机产生)n个元素的值,建立带头结点的循环链表L*/void CreateList_CL_Tail(CircleList *L, int n){srand((size_t)time(NULL)); //初始化随机种子//先建立一个带头结点的空循环链表*L = (CircleList)malloc(sizeof(LNode));if(!(*L))exit(OVERFLOW);(*L)->next = *L; //初始头结点指针域指向自身CircleList r = *L; //指针r初始指向头结点,作用是指向尾结点for(int i=0; i<n; i++){CircleList s = (CircleList)malloc(sizeof(LNode)); //生产新结点s//scanf("%d", &s->data); //手动输入元素值s->data = rand()%100; //随机生成100以内的数字,将生成的元素值赋给新生成结点的数据域//将新结点插入到表头结点之后s->next = L; //新结点s的指针域指向头结点Lr->next = s; //当前链表尾结点指针域指向新结点sr = s; //r指向链表新的尾结点s}}
三 算法设计题
Q1:将两个递增的有序链表合并为一个递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中不允许有重复的数据。
【问题分析】要求利用现有的表中结点空间建立新链表,可通过更改结点的指针域来重新建立新的元素之间的线性关系。为保证新表和原来的表一样递增有序,可以利用 尾插法 建立新的单链表。
【算法思路】假设待合并的两个递增有序的单链表分别为 La 和 Lb,合并后的新表使用头指针 Lc(Lc的头结点使用La的头结点)指向。
(1)指针 pa 和 pb 分别为链表 La 和 Lb 的工作指针,初始化时分别指向链表的元结点(即第一个数据结点)。
(2)从元结点开始进行大小比较,当两个链表 La 和 Lb 均为到达表尾结点时,依次摘取其中较小者重新链接到 Lc 表的最后。
(3)如果两个表中的元素相等,只摘取 La 表中的元素。删除 Lb 表中的元素,这样确保合并后的表中无重复的元素。
(4)当一个表到达表尾结点为空时,将非空表的剩余结点段直接链接在 Lc 表的最后。
(5)最后释放掉链表 Lb 的头结点存储空间。
【算法描述】C语言实现
//将两个递增的有序链表La和Lb合并为一个递增的有序链表Lcvoid MergeList(LinkList La, LinkList Lb, LinkList Lc){LinkList pa, pb, pc;LinkList ps;pa = La->next; //pa是链表La的工作指针,初始指向La的元结点pb = Lb->next; //pb是链表Lb的工作指针,初始指向Lb的元结点Lc = La; //用La的头结点作为Lc的头结点Lc = pc; //pc是链表Lc的工作指针,初始指向Lc的头结点while(pa && pb) //链表La和Lb均未达到尾结点时{if(pa->data < pb->data){//取较小者La中的元素,将pa指向的结点链接在pc指向的结点之后,pa指针后移pc->next = pa;pc = pa;pa = pa->next;}else if(pa->data > pb->data){//取较小者Lb中的元素,将pb指向的结点链接在pc指向的结点之后,pb指针后移pc->next = pb;pc = pb;pb = pb->next;}else{//相等时取La中的元素,删除Lb中的元素pc->next = pa;pc = pa;pa = pa->next;ps = pb->next; //将待删除结点的后继结点地址临时存放在ps指针中free(pb);pb = ps; //pb指向下一个结点}}pc->next = pa ? pa:pb;free(Lb);}
Q2:将两个非递减的有序链表合并为一个非递增的有序链表。
要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中允许有重复的数据。
【问题分析】这道题与 Q1 是类似的思路,从原有的两个有序链表中依次摘取结点,通过更改结点的指针域来重新建立新的元素之间的线性关系,得到一个新的链表。与 Q1 不同的关键点有两个:(1) 为保证新表与原表顺序相反,需要利用头插法建立单链表,而不是利用尾插法。(2)当一个表到达表尾时,另一个非空表的剩余元素应该依次摘取,逐个依次链接在 Lc 表的表头结点之后,而不能一次性全部链接在 Lc 表的最后。
【算法思路】假设待合并的两个递增有序的单链表分别为 La 和 Lb,合并后的新表使用头指针 Lc(Lc的头结点使用La的头结点)指向。
(1)指针 pa 和 pb 分别为链表 La 和 Lb 的工作指针,初始化时分别指向链表的元结点(即第一个数据结点)。
(2)从元结点开始进行大小比较,当两个链表 La 和 Lb 均为到达表尾结点时,依次摘取其中较小者重新链接到 Lc 表的表头结点之后。
(3)如果两个表中的元素相等,只摘取 La 表中的元素,同时保留 Lb 表中的元素。
(4)当一个表到达表尾结点为空时,将非空表的剩余结点依次摘取,链接在 Lc 表的表头结点之后。
(5)最后释放掉链表 Lb 的头结点存储空间。
【算法描述】C语言实现
//将两个非递减的有序链表La和Lb合并为一个非递增的有序链表Lcvoid MergeList(LinkList La, LinkList Lb, LinkList Lc){LinkList pa, pb;LinkList ps;pa = La->next; //pa是链表La的工作指针,初始指向La的元结点pb = Lb->next; //pb是链表Lb的工作指针,初始指向Lb的元结点Lc = La; //用La的头结点作为Lc的头结点Lc = ps; //ps是临时指针,指向待摘取的元素,初始指向Lc的头结点Lc->next = NULL; //将Lc表的尾结点的指针域设置为空while(pa || pb) //只要有一个链表未达到表尾结点{if(!pa) //如果La表遍历完,则将Lb表的剩余结点逐个插入到Lc表的表头结点{ps = pb;pb = pb->next;}else if(!pb) //如果Lb表遍历完,则将La表的剩余结点逐个插入到Lc表的表头结点{ps = pa;pa = pa->next;}else if(pa->data <= pb->data) //取较小者La中的元素{ps = pa;pa = pa->next;}else //取较小者Lb中的元素{ps = pb;pb = pb->next;}//将ps指向的待插结点插在Lc的表头结点之后(头插法)ps->next = Lc->next;Lc->next = ps;}free(Lb); //释放Lb的头结点}
参考
《数据结构(C语言版)》严蔚敏,吴伟民 (编著)
《数据结构题集(C语言版)》严蔚敏,吴伟民,米宁 (编著)
《数据结构(C语言版-第2版)》严蔚敏 , 李冬梅 , 吴伟民 (编著)
《数据结构习题解析与实验指导》李冬梅 张琪 (编著)
第2章 线性表 - 单链表链式存储
《数据结构(C语言版)》- 循环链表

























C语言 之 十六进制数与十进制数的相互转换。十六进制数的加减法")


还没有评论,来说两句吧...