Flume-实时监控目录下新文件(Spool Source + HDFS Sink)
实时监控目录下新文件
分析:使用Flume监控整个目录的文件,并上传到HDFS
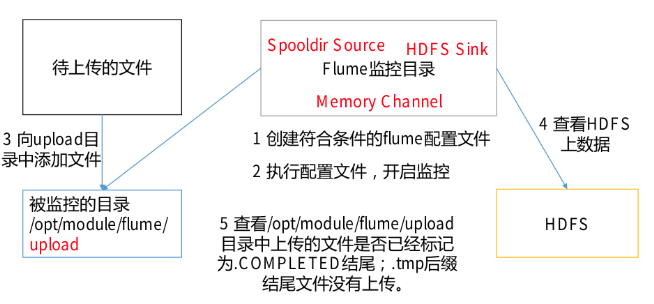
spooldir source常用配置如下:
| Property Name | Default | Description |
|---|---|---|
| fileSuffix | .COMPLETED | Suffix to append to completely ingested files |
| includePattern | ^.*$ | 指定要包含哪些文件的正则表达式。 它可以与ignorePattern一起使用。 |
| ignorePattern | ^$ | 指定要忽略(跳过)哪些文件的正则表达式。 它可以与 includePattern 一起使用。 如果文件同时匹配 ignorePattern 和 includePattern 正则表达式,则该文件将被忽略。 |
配置文件内容如下:
# Name the components on this agenta2.sources = r2a2.sinks = k2a2.channels = c2# Describe/configure the sourcea2.sources.r2.type = spooldira2.sources.r2.spoolDir = /home/bd/tmp/spoolTest# Describe the sinka2.sinks.k2.type = hdfsa2.sinks.k2.hdfs.path = hdfs://hadoop113:9000/flume/%Y%m%d/%H#上传文件的前缀a2.sinks.k2.hdfs.filePrefix = logs-#是否按照时间滚动文件夹a2.sinks.k2.hdfs.round = true#多少时间单位创建一个新的文件夹a2.sinks.k2.hdfs.roundValue = 1#重新定义时间单位a2.sinks.k2.hdfs.roundUnit = hour#是否使用本地时间戳a2.sinks.k2.hdfs.useLocalTimeStamp = true#积攒多少个 Event 才 flush 到 HDFS 一次,到了一定时间了也会去flusha2.sinks.k2.hdfs.batchSize = 1000#设置文件类型,可支持压缩a2.sinks.k2.hdfs.fileType = DataStream#多久生成一个新的文件,60sa2.sinks.k2.hdfs.rollInterval = 60#设置每个文件的滚动大小a2.sinks.k2.hdfs.rollSize = 134217700#文件的滚动与 Event 数量无关a2.sinks.k2.hdfs.rollCount = 0# Use a channel which buffers events in memorya2.channels.c2.type = memorya2.channels.c2.capacity = 1000a2.channels.c2.transactionCapacity = 100# Bind the source and sink to the channela2.sources.r2.channels = c2a2.sinks.k2.channel = c2
准备几个文件,在flume程序启动之后,放置到指定的目录下,因为配置了roll的原因,在a2.sinks.k2.hdfs.rollInterval的时间内上传的文件会被合并成一个文件。
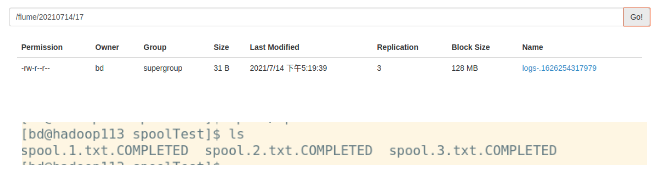
flume在检查是默认500ms检查一次目录中是否有新(即后缀非.COMPLETED)的文件,有则将其上传并合并到当前的tmp文件中。
只要是以.COMPLETED作为后缀的文件,就算其真的名字是.COMPLETED后缀或者是文件内容有修改,均不会再次被上传。
上传的操作是先上传后改文件名的。
如果再次复制文件名相同的文件(如spool.1.txt)到指定目录中的话,那么它将会被上传到HDFS,但是因为已经有了同名的.COMPLETED文件,那么这个文件改名将会失败且会有报错,并导致之后的flume操作全部失败;恢复的操作是将其删除,并重启flume任务。这个很关键,如果出现同名文件的话,会导致整个flume无法正常工作。




























还没有评论,来说两句吧...