kafka集群搭建
kafka集群搭建
一、Kafka 拓扑结构

一个典型的Kafka 集群中包含若干Producer(可以是web 前端产生的Page View,或者是服务器日志,系统 CPU、Memory 等),
若干broker(Kafka 支持水平扩展,一般broker 数量越多,集群吞吐率越高),
若干Consumer Group,以及一个Zookeeper 集群。
Kafka 通过Zookeeper 管理集群配置,选举leader,以及在Consumer Group 发生变化时进行rebalance。
Producer 使用push 模式将消息发布到broker,Consumer 使用pull 模式从broker 订阅并消费消息
二、kafka集群关键要素
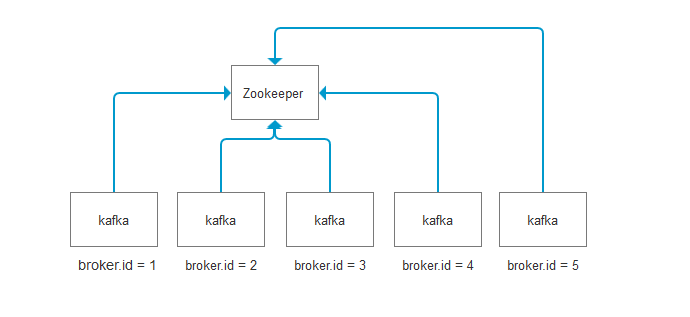
看上面一张图,要想做kafka集群,有几个关键点
所有kafka节点,必须连接到同一个Zookeeper(可以是单机,也可以是Zookeeper集群)
kafka节点配置文件中的broker.id必须唯一,如上图
kafka节点的数量,必须是奇数,比如1,3,5…
三、正式搭建
环境介绍
| 操作系统 | docker镜像 | docker ip | 部署软件以及版本 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.2 | zookeeper-3.4.13 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.3 | zookeeper-3.4.13 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.4 | zookeeper-3.4.13 |
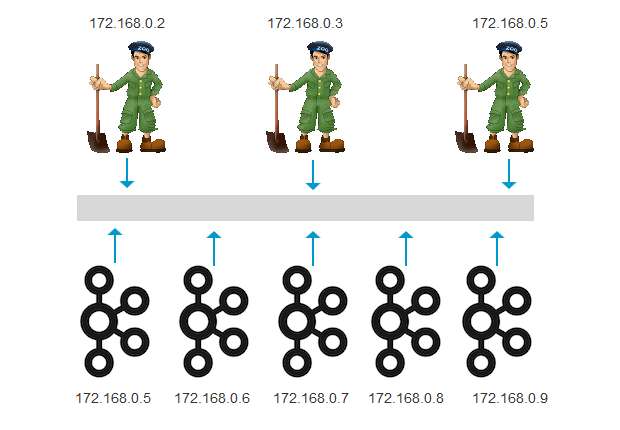
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.5 | kafka_2.12-2.1.0 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.6 | kafka_2.12-2.1.0 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.7 | kafka_2.12-2.1.0 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.8 | kafka_2.12-2.1.0 |
| ubuntu-16.04.5-server-amd64 | ubuntu:16.04 | 172.168.0.9 | kafka_2.12-2.1.0 |
本文的zookeeper,使用3个节点构建的集群。关于zookeeper集群的搭建,请参考链接:
https://www.cnblogs.com/xiao987334176/p/10103619.html
本文使用5个kafka节点,构造kafka集群。
拓扑图
基于docker安装
创建空目录
mkdir /opt/kafka_cluster
dockerfile
FROM ubuntu:16.04# 修改更新源为阿里云ADD sources.list /etc/apt/sources.listADD kafka_2.12-2.1.0.tgz /# 安装jdkRUN apt-get update && apt-get install -y openjdk-8-jdk --allow-unauthenticated && apt-get clean allEXPOSE 9092# 添加启动脚本ADD run.sh .RUN chmod 755 run.shENTRYPOINT [ "/run.sh"]
run.sh
#!/bin/bashif [ -z $broker_id ];thenecho "broker_id变量不能为空"exit 1fiif [ -z $zookeeper ];thenecho "zookeeper变量不能为空"exit 2ficd /kafka_2.12-2.1.0# 设置唯一idsed -i "21s/0/$broker_id/" /kafka_2.12-2.1.0/config/server.properties# 设置zookeeper连接地址sed -i "123s/localhost/$zookeeper/" /kafka_2.12-2.1.0/config/server.properties# 启动kafkabin/kafka-server-start.sh config/server.properties
sources.list
deb http://mirrors.aliyun.com/ubuntu/ xenial maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial maindeb http://mirrors.aliyun.com/ubuntu/ xenial-updates maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates maindeb http://mirrors.aliyun.com/ubuntu/ xenial universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial universedeb http://mirrors.aliyun.com/ubuntu/ xenial-updates universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universedeb http://mirrors.aliyun.com/ubuntu/ xenial-security maindeb-src http://mirrors.aliyun.com/ubuntu/ xenial-security maindeb http://mirrors.aliyun.com/ubuntu/ xenial-security universedeb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
此时目录结构如下:
./├── dockerfile├── kafka_2.12-2.1.0.tgz├── run.sh└── sources.list
生成镜像
docker build -t kafka_cluster /opt/kafka_cluster
启动kafka集群
在启动kafka之前,请确保已经启动了3台zk服务器。
启动第一个kafka节点
docker run -it -p 9092:9092 -e broker_id=1 -e zookeeper=172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --network br1 --ip=172.168.0.5 kafka_cluster
启动第二个kafka节点
docker run -it -p 9093:9092 -e broker_id=2 -e zookeeper=172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --network br1 --ip=172.168.0.6 kafka_cluster
启动第三个kafka节点
docker run -it -p 9094:9092 -e broker_id=3 -e zookeeper=172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --network br1 --ip=172.168.0.7 kafka_cluster
启动第四个kafka节点
docker run -it -p 9095:9092 -e broker_id=4 -e zookeeper=172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --network br1 --ip=172.168.0.8 kafka_cluster
启动第五个kafka节点
docker run -it -p 9096:9092 -e broker_id=5 -e zookeeper=172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --network br1 --ip=172.168.0.9 kafka_cluster
注意:红色部分的参数需要修改一下,不能重复!
查看集群状态
先来查看一下docker进程
root@jqb-node128:~# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESbd22fb6cafbb kafka_cluster "/run.sh" 2 minutes ago Up 2 minutes 0.0.0.0:9096->9092/tcp amazing_pared874f6d1ef6c kafka_cluster "/run.sh" 2 minutes ago Up 2 minutes 0.0.0.0:9095->9092/tcp agitated_pike3543cdda7e68 kafka_cluster "/run.sh" 27 minutes ago Up 27 minutes 0.0.0.0:9094->9092/tcp stupefied_bhaskara8bd899ba33ba kafka_cluster "/run.sh" 27 minutes ago Up 27 minutes 0.0.0.0:9093->9092/tcp hopeful_ride529b0b031949 kafka_cluster "/run.sh" 27 minutes ago Up 27 minutes 0.0.0.0:9092->9092/tcp upbeat_golick217e012c9566 3f3a8090dcb6 "/run.sh" 21 hours ago Up 21 hours 0.0.0.0:2183->2181/tcp gallant_golick3b4861d2fef9 3f3a8090dcb6 "/run.sh" 21 hours ago Up 21 hours 0.0.0.0:2182->2181/tcp jovial_murdocked91c1f973d2 3f3a8090dcb6 "/run.sh" 21 hours ago Up 21 hours 0.0.0.0:2181->2181/tcp dazzling_hamilton
随意进入一个kafka容器
root@jqb-node128:~# docker exec -it bd22fb6cafbb /bin/bashroot@bd22fb6cafbb:/# cd /kafka_2.12-2.1.0/root@bd22fb6cafbb:/kafka_2.12-2.1.0#
查看topic
bin/kafka-topics.sh --describe --zookeeper 172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181
执行之后,没有任何输出。是因为此时还没有创建topic
创建topic,因为有三个kafka服务,所以这里replication-factor设为3
bin/kafka-topics.sh --create --zookeeper 172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181 --replication-factor 3 -partitions 1 --topic 3test
执行输出:
Created topic “3test”.
再次查看topic
root@bd22fb6cafbb:/kafka_2.12-2.1.0# bin/kafka-topics.sh --describe --zookeeper 172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181Topic:3test PartitionCount:1 ReplicationFactor:3 Configs:Topic: 3test Partition: 0 Leader: 3 Replicas: 3,4,5 Isr: 3,4,5
此时的leader kafka为3,也就是broker_id参数为3个kafka服务器。
开启一个producer,往172.168.0.5发送kafka消息,也就是第一个kafka节点
root@bd22fb6cafbb:/kafka_2.12-2.1.0# bin/kafka-console-producer.sh --broker-list 172.168.0.5:9092 --topic 3test>fdsa>
再开一个窗口进入172.168.0.5这台节点,消费一下,指定节点为第二台kafka。
等待10秒,就会收到fdsa了。
root@jqb-node128:~# docker exec -it 529b0b031949 /bin/bashroot@529b0b031949:/# cd /kafka_2.12-2.1.0/root@529b0b031949:/kafka_2.12-2.1.0# bin/kafka-console-consumer.sh --bootstrap-server 172.168.0.6:9092 --topic 3test --from-beginningfdsa
停止leader
停掉172.168.0.7的kafka,它是leader。先确保它的配置文件broker.id=3
先查看ip地址
root@jqb-node128:~# docker exec -it 3543cdda7e68 /bin/bashroot@3543cdda7e68:/# cat /etc/hosts127.0.0.1 localhost::1 localhost ip6-localhost ip6-loopbackfe00::0 ip6-localnetff00::0 ip6-mcastprefixff02::1 ip6-allnodesff02::2 ip6-allrouters172.168.0.7 3543cdda7e68
在查看配置文件
root@3543cdda7e68:/# cat /kafka_2.12-2.1.0/config/server.properties | head -21 | tail -1broker.id=3
删除docker
docker rm 3543cdda7e68 -f
在其他容器,再次查看topics
root@529b0b031949:/kafka_2.12-2.1.0# bin/kafka-topics.sh --describe --zookeeper 172.168.0.2:2181,172.168.0.3:2181,172.168.0.4:2181Topic:3test PartitionCount:1 ReplicationFactor:3 Configs:Topic: 3test Partition: 0 Leader: 4 Replicas: 3,4,5 Isr: 4,5Topic:__consumer_offsets PartitionCount:50 ReplicationFactor:1 Configs:segment.bytes=104857600,cleanup.policy=compact,compression.type=producerTopic: __consumer_offsets Partition: 0 Leader: 4 Replicas: 4 Isr: 4...
可以发现此时的Leader的broker.id为4,也就是第4个kafka节点。
再次消费,也是正常的
root@529b0b031949:/kafka_2.12-2.1.0# bin/kafka-console-consumer.sh --bootstrap-server 172.168.0.6:9092 --topic 3test --from-beginningfdsa
本文参考链接:
https://www.cnblogs.com/younldeace/p/3796580.html
posted @ 2018-12-09 17:50 肖祥 阅读( …) 评论( …) 编辑 收藏


























")
")






还没有评论,来说两句吧...